In the previous section, the hook function processes messages with the rules in the table to realize the firewall function. This section describes the initialization process of the table. In order to maintain the continuity with the previous chapter, we return to the initialization entry of the filter table hook function:
File: net/ipv4/netfilter/iptable_filter.c
static int __init iptable_filter_init(void)
{
int ret;
ret = register_pernet_subsys(&iptable_filter_net_ops);
if (ret < 0)
return ret;
/* Register hooks */
filter_ops = xt_hook_link(&packet_filter, iptable_filter_hook);
if (IS_ERR(filter_ops)) {
ret = PTR_ERR(filter_ops);
unregister_pernet_subsys(&iptable_filter_net_ops);
}
return ret;
}The previous section talked about the function XT_ hook_ link(&packet_filter, iptable_filter_hook); The hook function IPtable_ filter_ Hook registers to the mount point, where packet_ Filter is the table corresponding to filter.
The table structure is defined as follows:
File include/linux/netfilter/x_tables.h
struct xt_table {
struct list_head list;
/* What hooks you will enter on */
unsigned int valid_hooks;
/* Man behind the curtain... */
struct xt_table_info *private; //The rule information in the final storage table
/* Set this to THIS_MODULE if you are a module, otherwise NULL */
struct module *me;
u_int8_t af; /* address/protocol family */
int priority; /* hook order */
/* A unique name... */
const char name[XT_TABLE_MAXNAMELEN];
};
State as follows:
static const struct xt_table packet_filter = {
.name = "filter",
.valid_hooks = FILTER_VALID_HOOKS,
.me = THIS_MODULE,
.af = NFPROTO_IPV4,
.priority = NF_IP_PRI_FILTER,
};In the previous section, the initialization object declared above will be used in the hook function initialization process. How to initialize other parameters in the table?
Like the hook function initialization process, the table also has an initialization entry function, which will be called automatically when the kernel module is loaded. The definition is as follows:
File: net/ipv4/netfilter/iptable_filter.c
static int __net_init iptable_filter_net_init(struct net *net)
{
struct ipt_replace *repl;
repl = ipt_alloc_initial_table(&packet_filter);
if (repl == NULL)
return -ENOMEM;
/* Entry 1 is the FORWARD hook */
((struct ipt_standard *)repl->entries)[1].target.verdict =
forward ? -NF_ACCEPT - 1 : -NF_DROP - 1;
net->ipv4.iptable_filter =
ipt_register_table(net, &packet_filter, repl);
kfree(repl);
return PTR_ERR_OR_ZERO(net->ipv4.iptable_filter);
}Through ipt_alloc_initial_table initializes an ipt_replace is defined in the file Include/uapi/linux/netfilter_ipv4/ip_tables.h, as follows:
struct ipt_replace {
/* Which table. */
char name[XT_TABLE_MAXNAMELEN];
/* Which hook entry points are valid: bitmask. You can't
change this. */
unsigned int valid_hooks;
/* Number of entries */
unsigned int num_entries;
/* Total size of new entries */
unsigned int size;
/* Hook entry points. */
/*The offset of the first rule of each rule chain in the storage table relative to the entry entries*/
unsigned int hook_entry[NF_INET_NUMHOOKS];
/* Underflow points. */
/*The offset of the last rule of each rule chain in the storage table relative to the entry entries*/
unsigned int underflow[NF_INET_NUMHOOKS];
/* Information about old entries: */
/* Number of counters (must be equal to current number of entries). */
unsigned int num_counters;
/* The old entries' counters. */
struct xt_counters __user *counters;
/* The entries (hang off end: not really an array). */
struct ipt_entry entries[0];
};This structure temporarily stores the rule information to be registered in the table.
In the file net / IPv4 / Netfilter / IP_ tables. IPT in C_ alloc_ initial_ Table is defined as follows:
void *ipt_alloc_initial_table(const struct xt_table *info)
{
return xt_alloc_initial_table(ipt, IPT);
}xt_alloc_initial_table is a macro defined in the file net/netfilter/xt_repldata.h, as follows:
#define xt_alloc_initial_table(type, typ2) ({ \
unsigned int hook_mask = info->valid_hooks; \
unsigned int nhooks = hweight32(hook_mask); \
unsigned int bytes = 0, hooknum = 0, i = 0; \
struct { \
struct type##_replace repl; \
struct type##_standard entries[]; \
} *tbl; \
struct type##_error *term; \
size_t term_offset = (offsetof(typeof(*tbl), entries[nhooks]) + \
__alignof__(*term) - 1) & ~(__alignof__(*term) - 1); \
tbl = kzalloc(term_offset + sizeof(*term), GFP_KERNEL); \
if (tbl == NULL) \
return NULL; \
term = (struct type##_error *)&(((char *)tbl)[term_offset]); \
strncpy(tbl->repl.name, info->name, sizeof(tbl->repl.name)); \
*term = (struct type##_error)typ2##_ERROR_INIT; \
tbl->repl.valid_hooks = hook_mask; \
tbl->repl.num_entries = nhooks + 1; \
tbl->repl.size = nhooks * sizeof(struct type##_standard) + \
sizeof(struct type##_error); \
for (; hook_mask != 0; hook_mask >>= 1, ++hooknum) { \
if (!(hook_mask & 1)) \
continue; \
tbl->repl.hook_entry[hooknum] = bytes; \
tbl->repl.underflow[hooknum] = bytes; \
tbl->entries[i++] = (struct type##_standard) \
typ2##_STANDARD_INIT(NF_ACCEPT); \
bytes += sizeof(struct type##_standard); \
} \
tbl; \
})
It may be a little difficult to read this code at first. As long as the board type is replaced with IPT and type2 is replaced with IPT, you will understand a lot. In fact, you have applied for one
struct {
struct ipt_replace repl;
struct ipt_standard entries[nhooks + 1]; // nhooks= hweight32(hook_mask)
} *tbl; Structure space and initialize it, where nhooks=3.
The tbl table structure returned after the macro initialization is as follows:
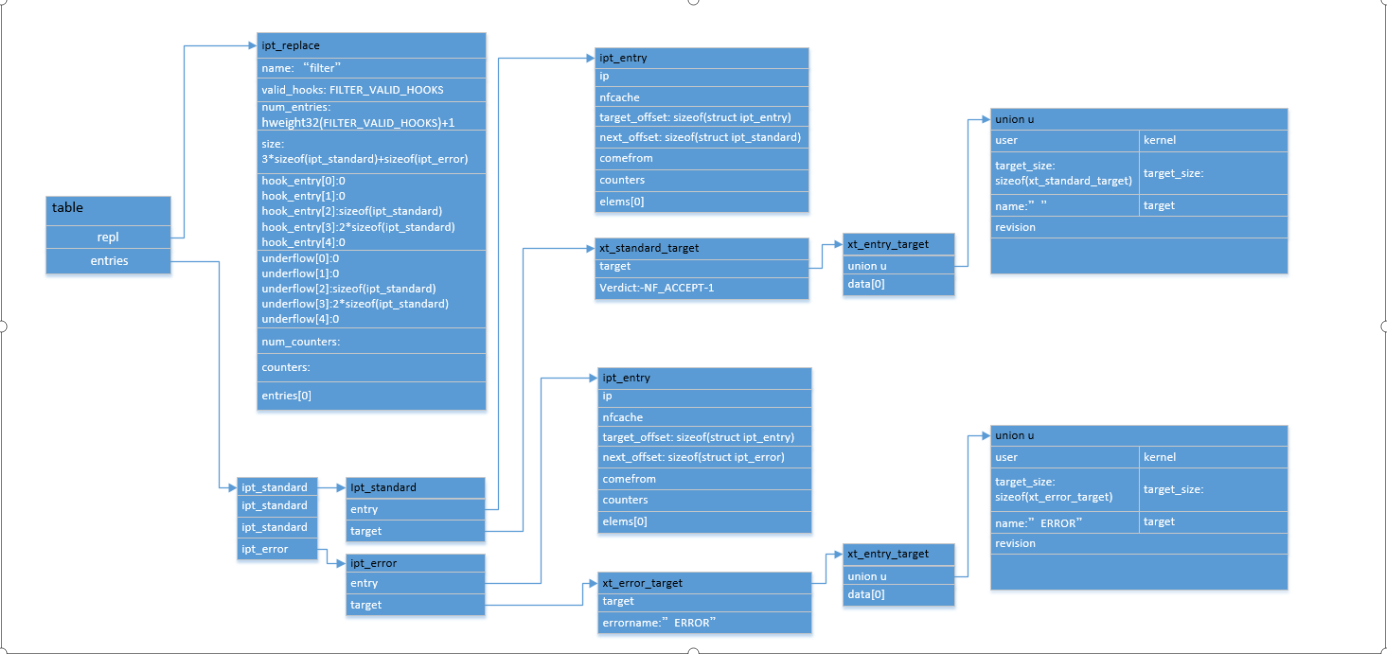
ipt_replace is initialized through ipt_register_table registers the table with the kernel. The function is defined in the file
net/ipv4/netfilter/ip_tables.c, as defined below:
struct xt_table *ipt_register_table(struct net *net,
const struct xt_table *table,
const struct ipt_replace *repl)
{
int ret;
struct xt_table_info *newinfo; //This structure stores the rule information in the table
struct xt_table_info bootstrap = {0};
void *loc_cpu_entry;
struct xt_table *new_table;
/*Application xt_table_info structure space and rule storage space. The rule storage space is repl - > size. From the above table, we can see that the rule size is 3*sizeof(ipt_standard)+sizeof(ipt_error)*/
newinfo = xt_alloc_table_info(repl->size);
if (!newinfo) {
ret = -ENOMEM;
goto out;
}
//Set IPT_ The rules in replace are stored in xt_table_info
loc_cpu_entry = newinfo->entries;
memcpy(loc_cpu_entry, repl->entries, repl->size);
/*Initialize newinfo to detect the legitimacy of rules, mainly to detect the target in each rule (ipt_entry)_ offset,next_offset, legitimacy, etc */
ret = translate_table(net, newinfo, loc_cpu_entry, repl);
if (ret != 0)
goto out_free;
/*Register the newinfo information in the private of table */
new_table = xt_register_table(net, table, &bootstrap, newinfo);
if (IS_ERR(new_table)) {
ret = PTR_ERR(new_table);
goto out_free;
}
return new_table;
out_free:
xt_free_table_info(newinfo);
out:
return ERR_PTR(ret);
}translate_ The table function is still a little complex. Let's focus on the analysis. The definition of the function is as follows:
static int
translate_table(struct net *net, struct xt_table_info *newinfo, void *entry0,
const struct ipt_replace *repl)
{
struct ipt_entry *iter;
unsigned int i;
int ret = 0;
newinfo->size = repl->size;
newinfo->number = repl->num_entries;
/* Init all hooks to impossible value. */
/*Initializes the rule chain offset address to an invalid value*/
for (i = 0; i < NF_INET_NUMHOOKS; i++) {
newinfo->hook_entry[i] = 0xFFFFFFFF;
newinfo->underflow[i] = 0xFFFFFFFF;
}
duprintf("translate_table: size %u\n", newinfo->size);
i = 0;
/* Walk through entries, checking offsets. */
/*Detect the target of each rule in the table_ offset,next_ Whether the offset is correct is relatively simple. It is not analyzed*/
xt_entry_foreach(iter, entry0, newinfo->size) {
ret = check_entry_size_and_hooks(iter, newinfo, entry0,
entry0 + repl->size,
repl->hook_entry,
repl->underflow,
repl->valid_hooks);
if (ret != 0)
return ret;
++i;
if (strcmp(ipt_get_target(iter)->u.user.name,
XT_ERROR_TARGET) == 0)
++newinfo->stacksize;
}
if (i != repl->num_entries) {
duprintf("translate_table: %u not %u entries\n",
i, repl->num_entries);
return -EINVAL;
}
/* Check hooks all assigned */
for (i = 0; i < NF_INET_NUMHOOKS; i++) {
/* Only hooks which are valid */
if (!(repl->valid_hooks & (1 << i)))
continue;
if (newinfo->hook_entry[i] == 0xFFFFFFFF) {
duprintf("Invalid hook entry %u %u\n",
i, repl->hook_entry[i]);
return -EINVAL;
}
if (newinfo->underflow[i] == 0xFFFFFFFF) {
duprintf("Invalid underflow %u %u\n",
i, repl->underflow[i]);
return -EINVAL;
}
}
/*The function of detecting whether the rules in the rule chain are looped is a little complex, which we will focus on later*/
if (!mark_source_chains(newinfo, repl->valid_hooks, entry0))
return -ELOOP;
/* Finally, each sanity check must pass */
/*Further check whether match and target are legal*/
i = 0;
xt_entry_foreach(iter, entry0, newinfo->size) {
ret = find_check_entry(iter, net, repl->name, repl->size);
if (ret != 0)
break;
++i;
}
if (ret != 0) {
xt_entry_foreach(iter, entry0, newinfo->size) {
if (i-- == 0)
break;
cleanup_entry(iter, net);
}
return ret;
}
return ret;
}Analyzing mark_ source_ Before chains, in order to be more intuitive, we first list the linked list structure saved by rules as follows:

The relationship between the rule and the first rule address record member (hook_entry []) of each rule chain is as follows:

XT in Table 3_ table_ Info is the "table table" in the linux firewall architecture_ Entry [] is the so-called "chain", ipt_entry is the so-called "rule rule".
Now we have a certain understanding of tables, chains and rules before we talk about mark_ source_ It will be much easier to continue to analyze the chains function. It will not be easy to get lost with a map. The function is defined as follows:
static int
mark_source_chains(const struct xt_table_info *newinfo,
unsigned int valid_hooks, void *entry0)
{
unsigned int hook;
/* No recursion; use packet counter to save back ptrs (reset
to 0 as we leave), and comefrom to save source hook bitmask */
/*Traverse each rule chain in the table*/
for (hook = 0; hook < NF_INET_NUMHOOKS; hook++) {
/*Find the first address of the rule chain by offsetting the first rule of the rule chain from the rule base address (entry0), that is, the address of the first rule in the rule chain*/
unsigned int pos = newinfo->hook_entry[hook];
struct ipt_entry *e = (struct ipt_entry *)(entry0 + pos);
/*If the current rule chain is invalid in the table, the next rule chain is traversed*/
if (!(valid_hooks & (1 << hook)))
continue;
/* Set initial back pointer. */
/*Use regular counters The pcnt # member stores the offset of the previous rule from the rule base address. We know the next of the current rule_ Offset can find the next rule through counters Pcnt to find the previous rule. Since this is the first rule in the rule chain, it is called "counters" Pcnt # records the offset of the first rule in the rule chain, followed by comparing the counters of the current rule Whether pcnt # is equal to the offset of the current rule itself determines whether to traverse the first rule in the rule chain through counters After pcnt is used to record the offset of the previous rule, each rule chain actually forms a two-way linked list*/
e->counters.pcnt = pos;
/*Each rule in the rule chain is traversed through the for loop*/
for (;;) {
/*Gets the target address in the rule*/
const struct xt_standard_target *t
= (void *)ipt_get_target_c(e);
/*Record whether the rule has been traversed by visited, and judge whether the hook bit in E - > comefrom is set to 1 to judge whether the rule has been traversed*/
int visited = e->comefrom & (1 << hook);
/*By judging the NF of E - > comefrom_ INET_ Whether the numbooks bit is set to 1 to judge whether the rule chain has a ring*/
if (e->comefrom & (1 << NF_INET_NUMHOOKS)) {
pr_err("iptables: loop hook %u pos %u %08X.\n",
hook, pos, e->comefrom);
return 0;
}
/*NF of E - > comefrom_ INET_ Both numbooks bit and hook bit are set to 1*/
e->comefrom |= ((1 << hook) | (1 << NF_INET_NUMHOOKS));
/* Unconditional return/END. */
/*Judge whether the last rule has been traversed. If the current rule is the standard default internal rule, it is considered to be the last rule in the current rule chain*/
if ((unconditional(e) &&
(strcmp(t->target.u.user.name,
XT_STANDARD_TARGET) == 0) &&
t->verdict < 0) || visited) {
unsigned int oldpos, size;
/*Judge whether the convert member of target in the standard default rule is legal*/
if ((strcmp(t->target.u.user.name,
XT_STANDARD_TARGET) == 0) &&
t->verdict < -NF_MAX_VERDICT - 1) {
duprintf("mark_source_chains: bad "
"negative verdict (%i)\n",
t->verdict);
return 0;
}
/* Return: backtrack through the last
big jump. */
/*Reverse traversal of rule chain */
do {
/*Clear the NF of E - > comefrom ^ of each rule in the rule chain_ INET_ Numbooks bit*/
e->comefrom ^= (1<<NF_INET_NUMHOOKS);
#ifdef DEBUG_IP_FIREWALL_USER
if (e->comefrom
& (1 << NF_INET_NUMHOOKS)) {
duprintf("Back unset "
"on hook %u "
"rule %u\n",
hook, pos);
}
#endif
/*Offset of the current rule*/
oldpos = pos;
/*Offset of previous rule*/
pos = e->counters.pcnt;
/*Clear e - > counters in the rule pcnt */
e->counters.pcnt = 0;
/* We're at the start. */
/*To determine whether to traverse the first rule in the rule chain in reverse, use the method mentioned earlier: if counters If pcnt is equal to the current rule offset, it is the first rule. If the current rule is the first rule, it exits, and then traverses the next rule chain*/
if (pos == oldpos)
goto next;
e = (struct ipt_entry *)
(entry0 + pos);
} while (oldpos == pos + e->next_offset);
/* Move along one */
/*If the current rule offset is not equal to the previous rule offset plus the next of the rule_ Offset, move back one rule before traversing*/
size = e->next_offset;
e = (struct ipt_entry *)
(entry0 + pos + size);
if (pos + size >= newinfo->size)
return 0;
e->counters.pcnt = pos;
pos += size;
} else {/*Traverse the rules in the rule chain in turn*/
int newpos = t->verdict;
/*Determine whether it is a user-defined jump rule*/
if (strcmp(t->target.u.user.name,
XT_STANDARD_TARGET) == 0 &&
newpos >= 0) {
/*The convert of custom rule target is greater than 0*/
if (newpos > newinfo->size -
sizeof(struct ipt_entry)) {
duprintf("mark_source_chains: "
"bad verdict (%i)\n",
newpos);
return 0;
}
/* This a jump; chase it. */
duprintf("Jump rule %u -> %u\n",
pos, newpos);
e = (struct ipt_entry *)
(entry0 + newpos);
/*Judge whether the custom jump rule is legal*/
if (!find_jump_target(newinfo, e))
return 0;
} else {
/* ... this is a fallthru */
/*Standard rules*/
newpos = pos + e->next_offset;
if (newpos >= newinfo->size)
return 0;
}
/*Get next rule*/
e = (struct ipt_entry *)
(entry0 + newpos);
/*e->counters.pcn Store the offset of the previous rule for reverse traversal*/
e->counters.pcnt = pos;
/* pos Record the offset of the current rule*/
pos = newpos;
}
}
next:
duprintf("Finished chain %u\n", hook);
}
return 1;
}Rule passed next_offset and counters Pcnt records the offsets of the next rule and the previous rule respectively to form a two-way linked list, as shown below:

This is mark_ source_ The chains function is finished. Although the implementation of this function is somewhat complex, its main function is actually very simple, that is, to judge whether a ring is formed by traversing each rule chain in the table.
xt_ table_ When the info object is ready, call XT_ register_ Register the function in the linked list except net XT to the table_ replace_ The table function is not easy to understand. Other parts are very simple.
The function is defined in the file
net/ netfilter/x_tables.c, as defined below:
struct xt_table *xt_register_table(struct net *net,
const struct xt_table *input_table,
struct xt_table_info *bootstrap,
struct xt_table_info *newinfo)
{
int ret;
struct xt_table_info *private;
struct xt_table *t, *table;
/* Don't add one object to multiple lists. */
/*Application xt_table table space and input_ Copy table content to new space */
table = kmemdup(input_table, sizeof(struct xt_table), GFP_KERNEL);
if (!table) {
ret = -ENOMEM;
goto out;
}
/*Lock before registration*/
mutex_lock(&xt[table->af].mutex);
/* Don't autoload: we'd eat our tail... */
/*Judge whether the table has been registered. If it has been registered, the corresponding error will be returned*/
list_for_each_entry(t, &net->xt.tables[table->af], list) {
if (strcmp(t->name, table->name) == 0) {
ret = -EEXIST;
goto unlock;
}
}
/* Simplifies replace_table code. */
/*Point table - > private to a XT with an initial value of 0_ table_ Info variable. The meaning of this variable is to implement XT_ replace_ The reuse of table in multi-core CPU is later called initialization reference quantity for convenience of description */
table->private = bootstrap;
/*The function of this function is to point the table - > private pointer to newinfo. The function is very simple, but the function implementation is not well understood. Let's analyze it again*/
if (!xt_replace_table(table, 0, newinfo, &ret))
goto unlock;
/*Number of print rules*/
private = table->private;
pr_debug("table->private->number = %u\n", private->number);
/* save number of initial entries */
/*The number of rules initialized in the record table*/
private->initial_entries = private->number;
/*Register the package to net - > XT tables */
list_add(&table->list, &net->xt.tables[table->af]);
/*Unlock after registration*/
mutex_unlock(&xt[table->af].mutex);
return table;
unlock:
mutex_unlock(&xt[table->af].mutex);
kfree(table);
out:
return ERR_PTR(ret);
}It says XT_ replace_ The table function may be called in multi-core CPU s at the same time. Now let's look at the specific implementation. The function is also in net / Netfilter / X_ tables. The functions defined in C are defined as follows:
struct xt_table_info *
xt_replace_table(struct xt_table *table,
unsigned int num_counters,
struct xt_table_info *newinfo,
int *error)
{
struct xt_table_info *private;
int ret;
/*Apply for jumpstack space. The function of this space will not be analyzed here for the time being*/
ret = xt_jumpstack_alloc(newinfo);
if (ret < 0) {
*error = ret;
return NULL;
}
/* Do the substitution. */
/*Turn off lower interrupt processing*/
local_bh_disable();
/*Get initialization reference bootstrap */
private = table->private;
/* Check inside lock: is the old number correct? */
/*Check whether private - > number is equal to the number value of the initialization reference bootstrap. If not, exit*/
if (num_counters != private->number) {
pr_debug("num_counters != table->private->number (%u/%u)\n",
num_counters, private->number);
local_bh_enable();
*error = -EAGAIN;
return NULL;
}
/*The number of initialization rules is set to the value of bootstrap. This code doesn't work personally, because it is later through private - > initial_entries = private - > number will set the initial value of the table_ Entries is assigned again. If there is something wrong, I hope the master will give me advice*/
newinfo->initial_entries = private->initial_entries;
/*
* Ensure contents of newinfo are visible before assigning to
* private.
*/
/*Open the memory barrier to ensure that variables are not optimized*/
smp_wmb();
/* table->private Point to newinfo */
table->private = newinfo;
/*
* Even though table entries have now been swapped, other CPU's
* may still be using the old entries. This is okay, because
* resynchronization happens because of the locking done
* during the get_counters() routine.
*/
/*Re enable interrupt lower processing*/
local_bh_enable();
#ifdef CONFIG_AUDIT
if (audit_enabled) {
struct audit_buffer *ab;
ab = audit_log_start(current->audit_context, GFP_KERNEL,
AUDIT_NETFILTER_CFG);
if (ab) {
audit_log_format(ab, "table=%s family=%u entries=%u",
table->name, table->af,
private->number);
audit_log_end(ab);
}
}
#endif
return private;
}Here, the initialization process of the filter table is over.
Finally, it explains that the most important thing to analyze the complex code of the kernel is the mentality. First understand the function to be realized by the code, then understand the architecture, and finally analyze the details with a peaceful mentality. Don't try to read everything quickly when analyzing the details of the code. When you look at complex code more quickly.