Article catalog
Collection optimizes the storage of objects, while flow is related to the processing of objects.
A stream is a series of elements that have nothing to do with a specific storage mechanism -- in fact, a stream has no "storage".
With flow, you can extract and manipulate elements in a collection without iterating over them. These pipes are usually combined to form an operation pipe on the flow.
In most cases, objects are stored in collections to handle them, so you will find that the programming focus shifts from collections to streams. A core benefit of streaming is that it makes the program shorter and easier to understand. When Lambda expressions and method references are used with streams, they feel self-contained. Streaming makes Java 8 more attractive.
If you want to randomly display non repeating integers between 5 and 20 and sort them. In fact, your first concern is to create an ordered collection. Follow up operations around this collection. But with streaming programming, you can simply state what you want to do:
// streams/Randoms.java
import java.util.*;
public class Randoms {
public static void main(String[] args) {
new Random(47)
.ints(5, 20)
.distinct()
.limit(7)
.sorted()
.forEach(System.out::println);
}
}Output results:
6 10 13 16 17 18 19
First, we give the Random object a seed (so that when the program runs again, it produces the same output). The ints() method generates a stream, and the ints() method is overloaded in many ways - two parameters define the boundary of numerical generation. This generates an integer stream. We can use intermediate stream operation distinct() to get their non repeating values, and then use the limit() method to get the first seven elements. Next, we use the sorted() method to sort. Finally, the forEach() method is used to traverse the output, which performs operations on each flow object according to the function passed to it. Here, we pass a method reference that can display each element on the console. System.out::println .
Note that there are no variables declared in Randoms.java. Flows are useful for modeling stateful systems without using assignment or variable data.
Declarative programming is a programming style that declares what to do, not how to do it. As we can see in functional programming. Note that the form of imperative programming is more difficult to understand. Code example:
// streams/ImperativeRandoms.java
import java.util.*;
public class ImperativeRandoms {
public static void main(String[] args) {
Random rand = new Random(47);
SortedSet<Integer> rints = new TreeSet<>();
while(rints.size() < 7) {
int r = rand.nextInt(20);
if(r < 5) continue;
rints.add(r);
}
System.out.println(rints);
}
}Output results:
[7, 8, 9, 11, 13, 15, 18]
In Randoms.java, we don't need to define any variables, but here we define three variables: rand, rints and r. Because the nextInt() method has no lower limit (its built-in lower limit is always 0), the implementation of this code is more complex. So we need to generate additional values to filter results less than 5.
Note that you have to study the real intention of the program, and in Randoms.java, the code just tells you what it is doing. This semantic clarity is also an important reason why Java 8's streaming programming is more respected.
Explicitly writing an iteration mechanism in imperativeandoms. Java is called external iteration. In Randoms.java, flow programming adopts internal iteration, which is one of the core features of flow programming. This mechanism makes the code more readable and makes better use of the advantages of multi-core processors. By giving up control over the iterative process, we give control to the parallelization mechanism. We will Concurrent programming Learn this part in the chapter.
Another important aspect is that streams are lazy loaded. This means that it is calculated only when absolutely necessary. You can think of a stream as a "delay list". Due to computational latency, streams enable us to represent very large (or even infinite) sequences without considering memory problems.
Stream support
Java designers are faced with such a problem: a large number of existing class libraries are not only used by Java, but also applied in millions of lines of code in the whole Java ecosystem. How to integrate a new concept of flow into the existing class library?
For example, add more methods to Random. As long as the original method is not changed, the existing code will not be disturbed.
The question is, how to transform the interface part? In particular, the part involving the collection class interface. If you want to convert a collection into a stream, adding new methods directly to the interface will destroy all old interface implementation classes.
The solution adopted by Java 8 is: Interface Add a method decorated with default. Through this scheme, designers can smoothly embed stream methods into existing classes. The preset operation of flow method has met almost all our usual needs. There are three types of flow operations: create flow, modify flow elements (Intermediate Operations), and consume flow elements (Terminal Operations). The last type usually means collecting stream elements (usually into collections).
Let's look at each type of flow operation.
Stream creation
You can easily convert a set of elements into a stream through Stream.of() (Bubble class is defined later in this chapter):
// streams/StreamOf.java
import java.util.stream.*;
public class StreamOf {
public static void main(String[] args) {
Stream.of(new Bubble(1), new Bubble(2), new Bubble(3))
.forEach(System.out::println);
Stream.of("It's ", "a ", "wonderful ", "day ", "for ", "pie!")
.forEach(System.out::print);
System.out.println();
Stream.of(3.14159, 2.718, 1.618)
.forEach(System.out::println);
}
}Output results:
Bubble(1) Bubble(2) Bubble(3) It's a wonderful day for pie! 3.14159 2.718 1.618
Each collection can generate a stream through stream(). Example:
import java.util.*;
import java.util.stream.*;
public class CollectionToStream {
public static void main(String[] args) {
List<Bubble> bubbles = Arrays.asList(new Bubble(1), new Bubble(2), new Bubble(3));
System.out.println(bubbles.stream()
.mapToInt(b -> b.i)
.sum());
Set<String> w = new HashSet<>(Arrays.asList("It's a wonderful day for pie!".split(" ")));
w.stream()
.map(x -> x + " ")
.forEach(System.out::print);
System.out.println();
Map<String, Double> m = new HashMap<>();
m.put("pi", 3.14159);
m.put("e", 2.718);
m.put("phi", 1.618);
m.entrySet().stream()
.map(e -> e.getKey() + ": " + e.getValue())
.forEach(System.out::println);
}
}Output results:
6 a pie! It's for wonderful day phi: 1.618 e: 2.718 pi: 3.14159
- Once the List object is created, simply call the stream() that exists in all collections.
- The intermediate operation map() will get all the elements in the stream, and apply operations to the elements in the stream to generate new elements and pass them to subsequent streams. Usually, map() gets the object and generates a new object, but here a special stream for numeric types is generated. For example, the mapToInt() method converts an object stream into an IntStream containing integer numbers.
- Get the element used to define the variable w by calling split() of the string.
- In order to generate stream data from the Map collection, we first call entrySet() to generate an object stream. Each object contains a key key and its associated value value. Then call getKey() and getValue() respectively to get the value.
Random number stream
The Random class is enhanced by a set of methods that generate streams. Code example:
// streams/RandomGenerators.java
import java.util.*;
import java.util.stream.*;
public class RandomGenerators {
public static <T> void show(Stream<T> stream) {
stream
.limit(4)
.forEach(System.out::println);
System.out.println("++++++++");
}
public static void main(String[] args) {
Random rand = new Random(47);
show(rand.ints().boxed());
show(rand.longs().boxed());
show(rand.doubles().boxed());
// Upper and lower control limits:
show(rand.ints(10, 20).boxed());
show(rand.longs(50, 100).boxed());
show(rand.doubles(20, 30).boxed());
// Control flow size:
show(rand.ints(2).boxed());
show(rand.longs(2).boxed());
show(rand.doubles(2).boxed());
// Control the size and boundaries of the flow
show(rand.ints(3, 3, 9).boxed());
show(rand.longs(3, 12, 22).boxed());
show(rand.doubles(3, 11.5, 12.3).boxed());
}
}Output results:
-1172028779 1717241110 -2014573909 229403722 ++++++++ 2955289354441303771 3476817843704654257 -8917117694134521474 4941259272818818752 ++++++++ 0.2613610344283964 0.0508673570556899 0.8037155449603999 0.7620665811558285 ++++++++ 16 10 11 12 ++++++++ 65 99 54 58 ++++++++ 29.86777681078574 24.83968447804611 20.09247112332014 24.046793846338723 ++++++++ 1169976606 1947946283 ++++++++ 2970202997824602425 -2325326920272830366 ++++++++ 0.7024254510631527 0.6648552384607359 ++++++++ 6 7 7 ++++++++ 17 12 20 ++++++++ 12.27872414236691 11.732085449736195 12.196509449817267 ++++++++
In order to eliminate redundant code, I created a generic method show(Stream stream) (using this feature before explaining generics is a bit cheating, but the reward is worth it). The type parameter T can be any type, so this method works for Integer, long, and double types. However, the Random class can only generate streams of basic types int, long and double. Fortunately, the boxed() stream operation will automatically wrap the base type into the corresponding boxing type, so that show() can accept the stream.
We can use Random to create suppliers for any collection of objects. The following is an example of a string object provided by a text file.
Contents of Cheese.dat file:
// streams/Cheese.dat Not much of a cheese shop really, is it? Finest in the district, sir. And what leads you to that conclusion? Well, it's so clean. It's certainly uncontaminated by cheese.
We read all the lines of the Cheese.dat File into the List through the File class. Code example:
// streams/RandomWords.java
import java.util.*;
import java.util.stream.*;
import java.util.function.*;
import java.io.*;
import java.nio.file.*;
public class RandomWords implements Supplier<String> {
List<String> words = new ArrayList<>();
Random rand = new Random(47);
RandomWords(String fname) throws IOException {
List<String> lines = Files.readAllLines(Paths.get(fname));
// Skip the first line
for (String line : lines.subList(1, lines.size())) {
for (String word : line.split("[ .?,]+"))
words.add(word.toLowerCase());
}
}
public String get() {
return words.get(rand.nextInt(words.size()));
}
@Override
public String toString() {
return words.stream()
.collect(Collectors.joining(" "));
}
public static void main(String[] args) throws Exception {
System.out.println(
Stream.generate(new RandomWords("Cheese.dat"))
.limit(10)
.collect(Collectors.joining(" ")));
}
}Output results:
it shop sir the much cheese by conclusion district is
Here you can see the more complex use of split(). In the constructor, each line is split() by spaces or any punctuation wrapped in square brackets. The + after the closing square bracket represents the things in front of + can appear one or more times.
We notice that the loop body uses imperative programming (external iteration) in the constructor. In future examples, you will even see how we can eliminate this. This old form is not particularly bad, but using streams makes people feel better.
In toString() and the main method, you see the collect() collection operation, which combines all the elements in the flow according to the parameters.
When you use Collectors.joining(), you will get a String type result, and each element is divided according to the parameters of joining(). There are many different Collectors used to produce different results.
In the main method, we saw the usage of Stream.generate() in advance, which can use any Supplier to generate T-type streams.
Range of int type
The IntStream class provides a range() method to generate a stream of integer sequences. This method is more convenient when writing loops:
// streams/Ranges.java
import static java.util.stream.IntStream.*;
public class Ranges {
public static void main(String[] args) {
// Traditional methods:
int result = 0;
for (int i = 10; i < 20; i++)
result += i;
System.out.println(result);
// For in loop:
result = 0;
for (int i : range(10, 20).toArray())
result += i;
System.out.println(result);
// Use stream:
System.out.println(range(10, 20).sum());
}
}Output results:
145 145 145
The first way in the main method is our traditional way of writing for loops; In the second way, we use range() to create a stream, convert it into an array, and then use it in the for in code block. However, it is better if you can use the flow all the way like the third method. We sum the numbers in the range. The sum() operation can be easily used to sum in the stream.
Note that IntStream.range() has more restrictions than onjava.Range.range(). This is due to its optional third parameter, which allows the step size to be greater than 1 and can be generated from large to small.
The utility gadget repeat() can be used to replace a simple for loop. Code example:
// onjava/Repeat.java
package onjava;
import static java.util.stream.IntStream.*;
public class Repeat {
public static void repeat(int n, Runnable action) {
range(0, n).forEach(i -> action.run());
}
}The resulting cycle is clearer:
// streams/Looping.java
import static onjava.Repeat.*;
public class Looping {
static void hi() {
System.out.println("Hi!");
}
public static void main(String[] args) {
repeat(3, () -> System.out.println("Looping!"));
repeat(2, Looping::hi);
}
}Output results:
Looping! Looping! Looping! Hi! Hi!
In principle, it's not worth including and interpreting repeat() in your code. Admittedly, it is a fairly transparent tool, but the result depends on how your team and company operate.
generate()
Refer to the example of using Stream.generate() with Supplier in RandomWords.java. Code example:
// streams/Generator.java
import java.util.*;
import java.util.function.*;
import java.util.stream.*;
public class Generator implements Supplier<String> {
Random rand = new Random(47);
char[] letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
public String get() {
return "" + letters[rand.nextInt(letters.length)];
}
public static void main(String[] args) {
String word = Stream.generate(new Generator())
.limit(30)
.collect(Collectors.joining());
System.out.println(word);
}
}Output results:
YNZBRNYGCFOWZNTCQRGSEGZMMJMROE
Use the Random.nextInt() method to pick the uppercase letters in the alphabet. The parameter of Random.nextInt() represents the maximum range of random numbers that can be accepted, so it is considered to use array boundaries.
If you want to create a stream containing the same objects, you only need to pass a lambda that generates those objects to generate():
// streams/Duplicator.java
import java.util.stream.*;
public class Duplicator {
public static void main(String[] args) {
Stream.generate(() -> "duplicate")
.limit(3)
.forEach(System.out::println);
}
}Output results:
duplicate duplicate duplicate
The following is the Bubble class used in previous examples in this chapter. Note that it contains its own Static generator method.
// streams/Bubble.java
import java.util.function.*;
public class Bubble {
public final int i;
public Bubble(int n) {
i = n;
}
@Override
public String toString() {
return "Bubble(" + i + ")";
}
private static int count = 0;
public static Bubble bubbler() {
return new Bubble(count++);
}
}Since bubbler() is interface compatible with Supplier, we can pass its method reference directly to Stream.generate():
// streams/Bubbles.java
import java.util.stream.*;
public class Bubbles {
public static void main(String[] args) {
Stream.generate(Bubble::bubbler)
.limit(5)
.forEach(System.out::println);
}
}Output results:
Bubble(0) Bubble(1) Bubble(2) Bubble(3) Bubble(4)
This is another way to create separate factory classes. It's cleaner in many ways, but it's a matter of code organization and taste - you can always create a completely different factory class.
iterate()
Stream.iterate() starts with a seed (first parameter) and passes it to the method (second parameter). The result of the method is added to the stream and stored as the first parameter for the next call to iterate(), and so on. We can use iterate() to generate a Fibonacci sequence. Code example:
// streams/Fibonacci.java
import java.util.stream.*;
public class Fibonacci {
int x = 1;
Stream<Integer> numbers() {
return Stream.iterate(0, i -> {
int result = x + i;
x = i;
return result;
});
}
public static void main(String[] args) {
new Fibonacci().numbers()
.skip(20) // Top 20 filters
.limit(10) // Then take 10
.forEach(System.out::println);
}
}Output results:
6765 10946 17711 28657 46368 75025 121393 196418 317811 514229
Fibonacci sequence sums the last two elements in the sequence to produce the next element. iterate() can only remember the result, so we need to use a variable x to track another element.
In the main method, we use a skip() operation that we haven't seen before. It discards the specified number of stream elements according to the parameters. Here, we discard the first 20 elements.
Flow builder mode
In the Builder design pattern (also known as constructor pattern), first create a Builder object, pass it multiple constructor information, and finally execute "construction". The Stream library provides such a Builder. Here, we re-examine the process of reading files and converting them into word streams. Code example:
// streams/FileToWordsBuilder.java
import java.io.*;
import java.nio.file.*;
import java.util.stream.*;
public class FileToWordsBuilder {
Stream.Builder<String> builder = Stream.builder();
public FileToWordsBuilder(String filePath) throws Exception {
Files.lines(Paths.get(filePath))
.skip(1) // Skip the first comment line
.forEach(line -> {
for (String w : line.split("[ .?,]+"))
builder.add(w);
});
}
Stream<String> stream() {
return builder.build();
}
public static void main(String[] args) throws Exception {
new FileToWordsBuilder("Cheese.dat")
.stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
}
}Output results:
Not much of a cheese shop really
Note that the constructor adds all the words in the file (except the first line, which is a comment containing the file path information), but it does not call build(). As long as you don't call the stream() method, you can continue to add words to the builder object.
In a more complete form of this class, you can add a flag bit to see if build() is called and, if possible, a method that can add more words. Continuing to try to add words after the Stream.Builder calls the build() method will result in an exception.
Arrays
The Arrays class contains a static method called stream() to convert an array into a stream. We can override the main method in interfaces/Machine.java to create a stream and apply execute() to each element. Code example:
// streams/Machine2.java
import java.util.*;
import onjava.Operations;
public class Machine2 {
public static void main(String[] args) {
Arrays.stream(new Operations[] {
() -> Operations.show("Bing"),
() -> Operations.show("Crack"),
() -> Operations.show("Twist"),
() -> Operations.show("Pop")
}).forEach(Operations::execute);
}
}Output results:
Bing Crack Twist Pop
The new Operations [] expression dynamically creates an array of Operations objects.
stream() can also generate IntStream, LongStream and DoubleStream.
// streams/ArrayStreams.java
import java.util.*;
import java.util.stream.*;
public class ArrayStreams {
public static void main(String[] args) {
Arrays.stream(new double[] { 3.14159, 2.718, 1.618 })
.forEach(n -> System.out.format("%f ", n));
System.out.println();
Arrays.stream(new int[] { 1, 3, 5 })
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Arrays.stream(new long[] { 11, 22, 44, 66 })
.forEach(n -> System.out.format("%d ", n));
System.out.println();
// Select a subdomain:
Arrays.stream(new int[] { 1, 3, 5, 7, 15, 28, 37 }, 3, 6)
.forEach(n -> System.out.format("%d ", n));
}
}Output results:
3.141590 2.718000 1.618000 1 3 5 11 22 44 66 7 15 28
The last call to stream() has two additional parameters. The first parameter tells stream() where to start selecting elements in the array, and the second parameter tells where to stop. Each different type of stream() has a similar operation.
regular expression
Java regular expressions will be character string This chapter describes in detail. Java 8 adds a new method splitasstream () in java.util.regex.Pattern. This method can convert the character sequence into a stream according to the incoming formula. However, there is a limitation that the input can only be CharSequence, so the stream cannot be used as a parameter of splitAsStream().
Let's look again at the process of processing files into word streams. This time, we use a stream to split the file into separate strings, and then use regular expressions to convert the strings into word streams.
// streams/FileToWordsRegexp.java
import java.io.*;
import java.nio.file.*;
import java.util.stream.*;
import java.util.regex.Pattern;
public class FileToWordsRegexp {
private String all;
public FileToWordsRegexp(String filePath) throws Exception {
all = Files.lines(Paths.get(filePath))
.skip(1) // First (comment) line
.collect(Collectors.joining(" "));
}
public Stream<String> stream() {
return Pattern
.compile("[ .,?]+").splitAsStream(all);
}
public static void
main(String[] args) throws Exception {
FileToWordsRegexp fw = new FileToWordsRegexp("Cheese.dat");
fw.stream()
.limit(7)
.map(w -> w + " ")
.forEach(System.out::print);
fw.stream()
.skip(7)
.limit(2)
.map(w -> w + " ")
.forEach(System.out::print);
}
}Output results:
Not much of a cheese shop really is it
In the constructor, we read everything in the file (skip the first line of comment and convert it to a single line string). Now, when you call stream(), you can get a stream as usual, but this time you can call stream() multiple times to create a new stream in the stored string. There is a limitation that the entire file must be stored in memory; In most cases, this is not a problem, but it loses the very important advantages of flow operation:
- Stream "no storage required". Of course, they need some internal storage, but this is only a small part of the sequence, which is not the same as holding the whole sequence.
- They are lazy load calculations.
Fortunately, we will know how to solve this problem later.
Intermediate operation
Intermediate operations are used to get objects from one stream and output them from the back end as another stream to connect to other operations.
Tracking and debugging
The peek() operation is intended to help debug. It allows you to view the elements in the stream without modification. Code example:
// streams/Peeking.java
class Peeking {
public static void main(String[] args) throws Exception {
FileToWords.stream("Cheese.dat")
.skip(21)
.limit(4)
.map(w -> w + " ")
.peek(System.out::print)
.map(String::toUpperCase)
.peek(System.out::print)
.map(String::toLowerCase)
.forEach(System.out::print);
}
}Output results:
Well WELL well it IT it s S s so SO so
FileToWords is defined later, but its functional implementation seems to be similar to what we saw before: generating a stream of string objects. peek() is then called to handle it as it passes through the pipe.
Because peek() conforms to the Consumer functional interface with no return value, we can only observe that we cannot replace objects in the stream with different elements.
Stream element sorting
In Randoms.java, we are familiar with the default Comparator implementation of sorted(). In fact, it has another form of implementation: passing in a Comparator parameter. Code example:
// streams/SortedComparator.java
import java.util.*;
public class SortedComparator {
public static void main(String[] args) throws Exception {
FileToWords.stream("Cheese.dat")
.skip(10)
.limit(10)
.sorted(Comparator.reverseOrder())
.map(w -> w + " ")
.forEach(System.out::print);
}
}Output results:
you what to the that sir leads in district And
sorted() presets some default comparators. Here we use reverse "natural sorting". Of course, you can also pass the Lambda function as a parameter to sorted().
Removing Elements
- distinct(): distinct() in the Randoms.java class can be used to eliminate duplicate elements in the stream. This method requires much less work than creating a Set collection.
- Filter (predict): the filter operation will retain the element with the calculation result of the passed filter function as true.
In the following example, isPrime() is used as a filter function to detect prime numbers.
import java.util.stream.*;
import static java.util.stream.LongStream.*;
public class Prime {
public static Boolean isPrime(long n) {
return rangeClosed(2, (long)Math.sqrt(n))
.noneMatch(i -> n % i == 0);
}
public LongStream numbers() {
return iterate(2, i -> i + 1)
.filter(Prime::isPrime);
}
public static void main(String[] args) {
new Prime().numbers()
.limit(10)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
new Prime().numbers()
.skip(90)
.limit(10)
.forEach(n -> System.out.format("%d ", n));
}
}Output results:
2 3 5 7 11 13 17 19 23 29 467 479 487 491 499 503 509 521 523 541
rangeClosed() contains the upper limit value. If it cannot be divided, that is, the remainder is not equal to 0, the noneMatch() operation returns true. If there is any result equal to 0, it returns false. If the noneMatch() operation fails, it will exit.
Apply function to element
- map(Function): apply the function operation to the elements of the input stream and pass the return value to the output stream.
- mapToInt(ToIntFunction): the operation is the same as above, but the result is IntStream.
- mapToLong(ToLongFunction): the operation is the same as above, but the result is LongStream.
- mapToDouble(ToDoubleFunction): the operation is the same as above, but the result is DoubleStream.
Here, we use map() to map multiple functions into a string stream. Code example:
// streams/FunctionMap.java
import java.util.*;
import java.util.stream.*;
import java.util.function.*;
class FunctionMap {
static String[] elements = { "12", "", "23", "45" };
static Stream<String>
testStream() {
return Arrays.stream(elements);
}
static void test(String descr, Function<String, String> func) {
System.out.println(" ---( " + descr + " )---");
testStream()
.map(func)
.forEach(System.out::println);
}
public static void main(String[] args) {
test("add brackets", s -> "[" + s + "]");
test("Increment", s -> {
try {
return Integer.parseInt(s) + 1 + "";
}
catch(NumberFormatException e) {
return s;
}
}
);
test("Replace", s -> s.replace("2", "9"));
test("Take last digit", s -> s.length() > 0 ?
s.charAt(s.length() - 1) + "" : s);
}
}Output results:
---( add brackets )--- [12] [] [23] [45] ---( Increment )--- 13 24 46 ---( Replace )--- 19 93 45 ---( Take last digit )--- 2 3 5
In the autoincrement example above, we use Integer.parseInt() to try to convert a string to an integer. If the string cannot be converted to an integer, a NumberFormatException exception will be thrown. We just need to go back and put the original string back into the output stream.
In the above example, map() maps one string to another, but we can generate a type completely different from the received type, thus changing the data type of the stream. The following code example:
// streams/FunctionMap2.java
// Different input and output types
import java.util.*;
import java.util.stream.*;
class Numbered {
final int n;
Numbered(int n) {
this.n = n;
}
@Override
public String toString() {
return "Numbered(" + n + ")";
}
}
class FunctionMap2 {
public static void main(String[] args) {
Stream.of(1, 5, 7, 9, 11, 13)
.map(Numbered::new)
.forEach(System.out::println);
}
}Output results:
Numbered(1) Numbered(5) Numbered(7) Numbered(9) Numbered(11) Numbered(13)
We convert the obtained integer into the Numbered type through the constructor Numbered::new.
If the result returned by Function is one of the numeric types, we must replace it with the appropriate mapTo numeric type. Code example:
// streams/FunctionMap3.java
// Producing numerical output streams
import java.util.*;
import java.util.stream.*;
class FunctionMap3 {
public static void main(String[] args) {
Stream.of("5", "7", "9")
.mapToInt(Integer::parseInt)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Stream.of("17", "19", "23")
.mapToLong(Long::parseLong)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
Stream.of("17", "1.9", ".23")
.mapToDouble(Double::parseDouble)
.forEach(n -> System.out.format("%f ", n));
}
}Output results:
5 7 9 17 19 23 17.000000 1.900000 0.230000
Unfortunately, Java designers did not do their best to eliminate basic types.
Combine flows in map()
Suppose there is an incoming element stream and you intend to use the map() function to stream elements. Now you have found some lovely and unique function functions, but the problem is: this function function produces a stream. We want to generate an element flow, but we actually generate a flow of element flow.
flatMap() does two things:
- Apply the stream generating function to each element (as map() does)
- Each stream is then flattened into elements
Therefore, only elements are produced in the end.
flatMap(Function): used when a Function generates a stream.
flatMapToInt(Function): used when Function generates IntStream.
flatMapToLong(Function): used when a Function generates a LongStream.
flatMapToDouble(Function): used when a Function generates a DoubleStream.
To understand how it works, we start by passing in a deliberately designed function to map(). This function accepts an integer and generates a character stream:

We naively hope to get the character stream, but we actually get the stream of "Head" stream. You can use flatMap() to solve the following problems:
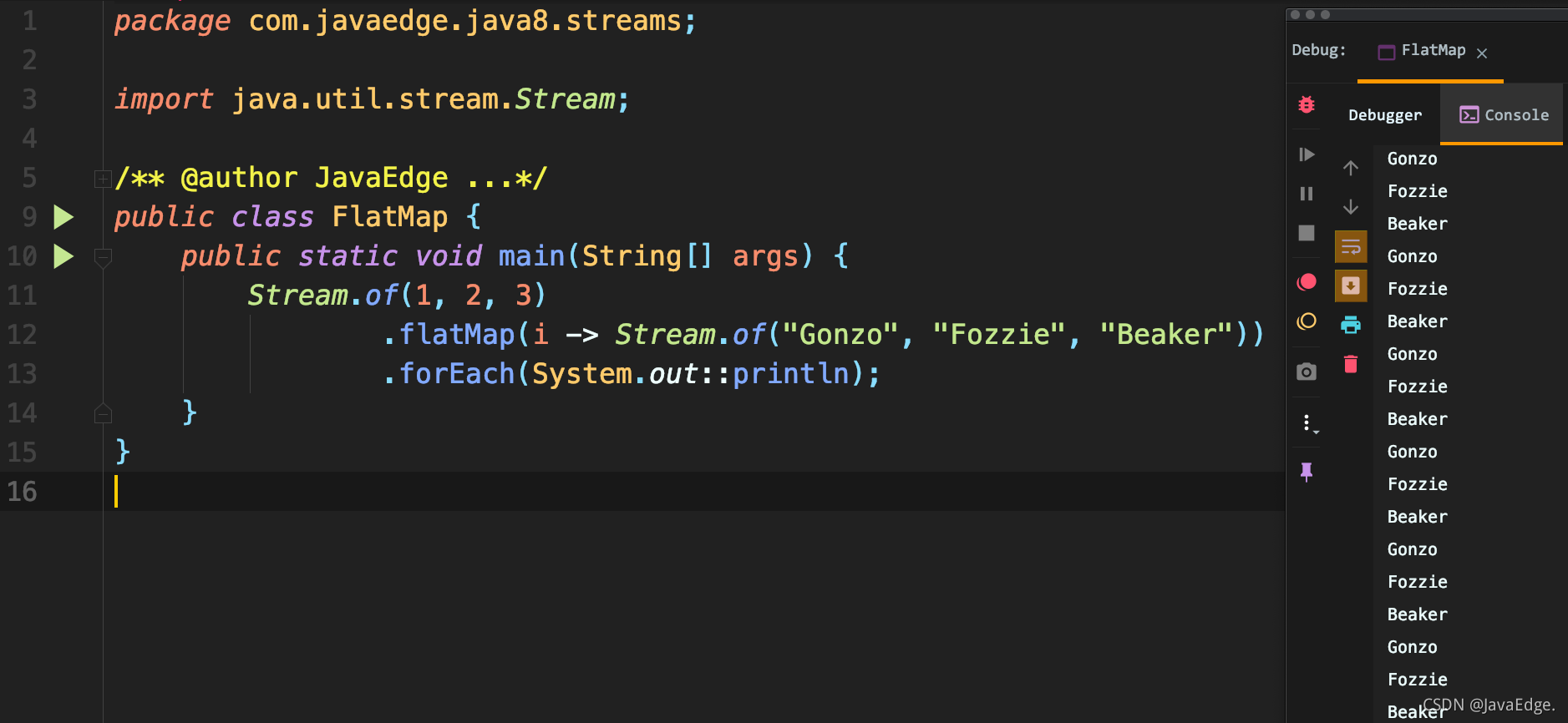
Each stream returned from the map is automatically flattened into the strings that make up it.
Now start with a stream of integers, and then use each integer to create more random numbers.
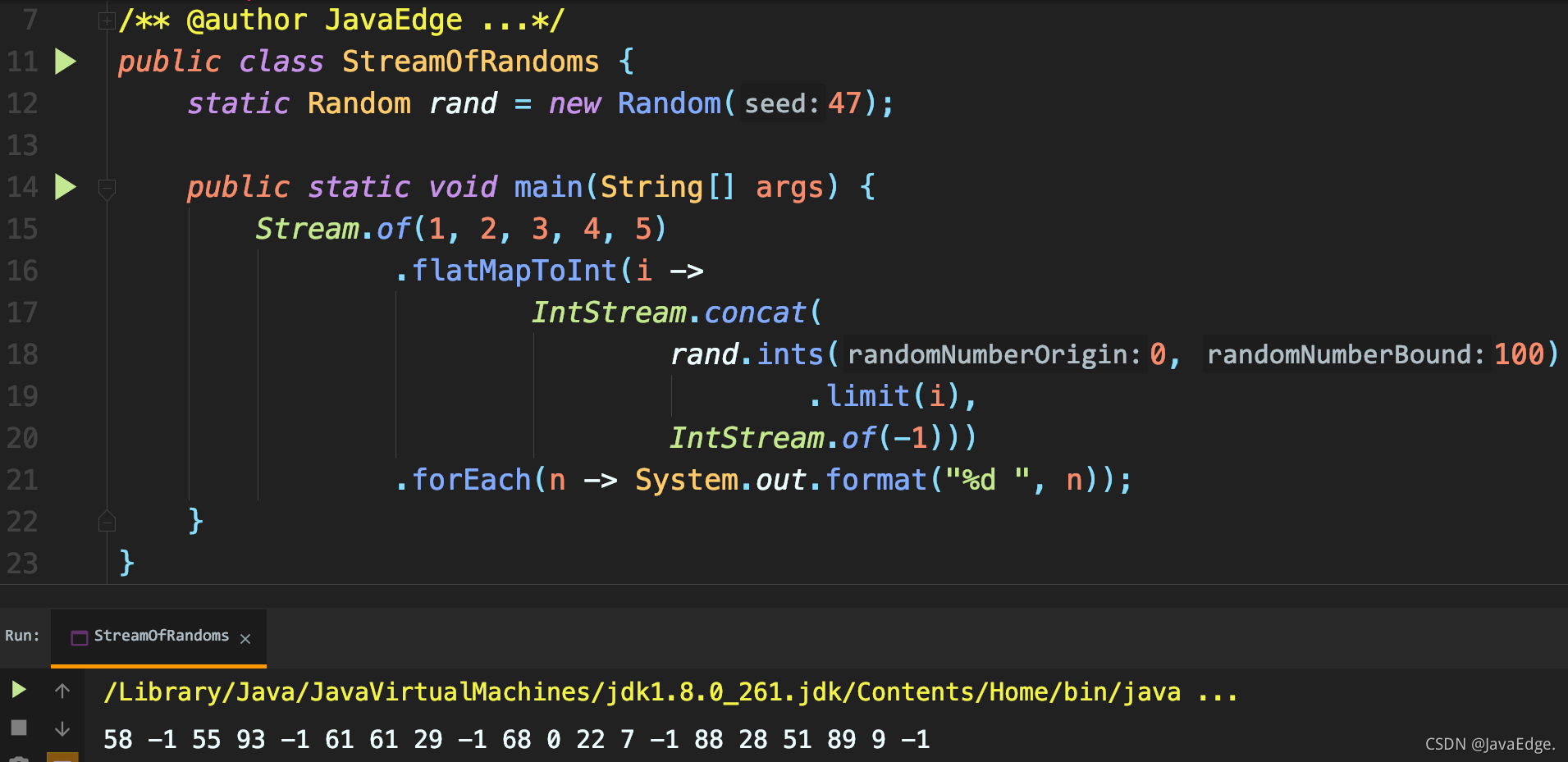
concat() combines the two streams in parameter order. Thus, we add a - 1 tag at the end of each random Integer stream. You can see that the final flow is indeed created from a set of flat flows.
Because rand.ints() produces an IntStream, you must use the specific integer forms of flatMap(), concat(), and of().
Divide the file into word streams. Finally, FileToWordsRegexp.java is used. The problem is that the whole file needs to be read into the line list -- obviously, the list needs to be stored. What we really want is to create a word stream that doesn't need an intermediate storage layer.
Next, we will use flatMap() to solve this problem:
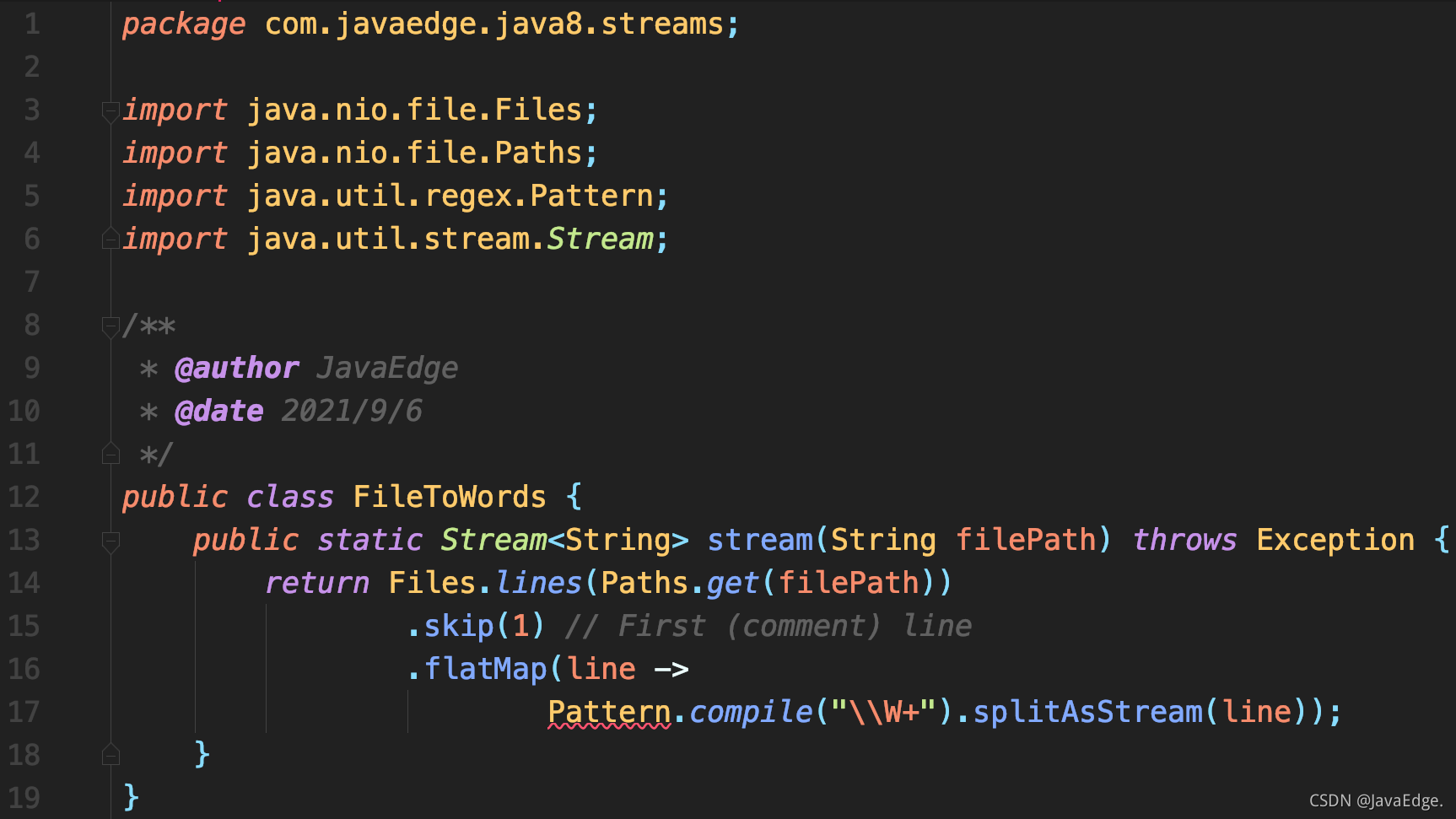
stream() is now a static method because it can complete the entire flow creation process itself.
Note: \ \ W + is a regular expression that represents non word characters, + represents one or more occurrences. Lowercase \ \ w stands for "word character".
The problem encountered before is that the result generated by Pattern.compile().splitAsStream() is a stream, which means that when you only want a simple word stream, calling map() in the incoming stream of lines will generate a stream of word streams. Fortunately, flatMap() can flatten the flow of element flow into a simple element flow. Alternatively, you can use String.split() to generate an array, which can be converted into a stream by Arrays.stream():
.flatMap(line -> Arrays.stream(line.split("\\W+"))))With the real stream instead of the collection storage based stream in FileToWordsRegexp.java, we must create it from scratch every time we use it, because the stream cannot be reused:
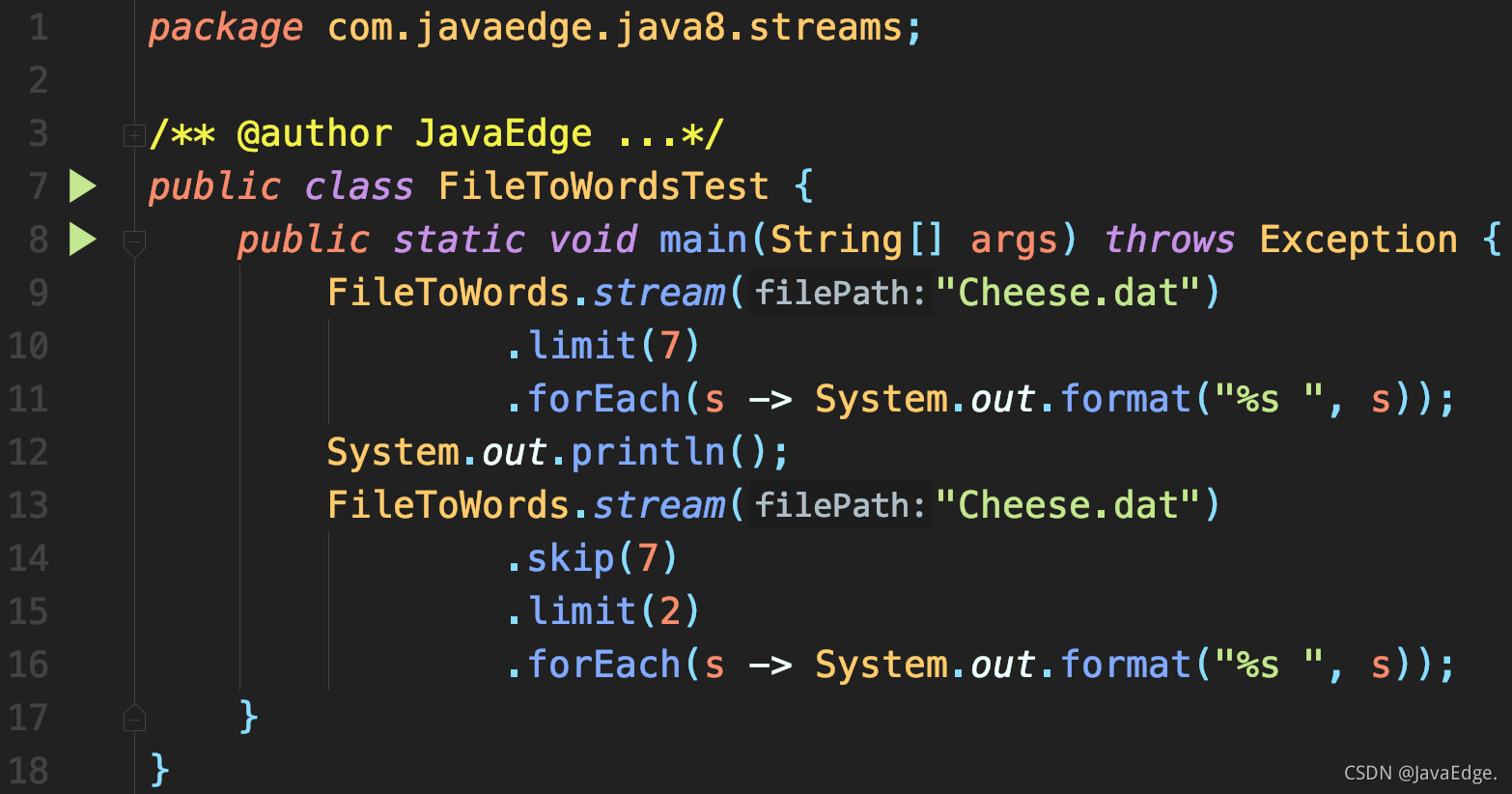
% s in System.out.format() indicates that the parameter is of type String.
Optional class
What happens if an element is fetched in an empty stream? We like to connect streams for "happy path" and assume that the stream will not be interrupted. Placing null in the stream is a good way to interrupt. So is there an object that can be the holder of the flow element and can kindly prompt us (that is, it won't throw exceptions roughly) even if the viewed element doesn't exist?
Optional is OK. Some standard stream operations return optional objects because they do not guarantee that the expected results will exist:
- findFirst() Returns an Optional object containing the first element. If the stream is empty, it returns Optional.empty
- findAny() Returns an Optional object containing any element. If the stream is empty, it returns Optional.empty
- max() and min() Returns an Optional object containing the maximum or minimum value. If the stream is empty, it returns Optional.empty
reduce() no longer starts with the form of identity, but wraps its return value in Optional. (the identity object becomes the default result of other forms of reduce(), so there is no risk of empty results)
For digital streams IntStream, LongStream, and DoubleStream, average() wraps the results in Optional to prevent the stream from being empty.
The following is a simple test of all these operations on an empty flow:
class OptionalsFromEmptyStreams {
public static void main(String[] args) {
System.out.println(Stream.<String>empty()
.findFirst());
System.out.println(Stream.<String>empty()
.findAny());
System.out.println(Stream.<String>empty()
.max(String.CASE_INSENSITIVE_ORDER));
System.out.println(Stream.<String>empty()
.min(String.CASE_INSENSITIVE_ORDER));
System.out.println(Stream.<String>empty()
.reduce((s1, s2) -> s1 + s2));
System.out.println(IntStream.empty()
.average());
}
}
Optional.empty
Optional.empty
Optional.empty
Optional.empty
Optional.empty
OptionalDouble.emptyWhen the stream is empty, you will get an Optional.empty object instead of throwing an exception. Optional's toString() method can be used to present useful information.
An empty stream is created through Stream.empty(). If you call Stream.empty() without any context, Java does not know its data type; This grammar solves this problem. If the compiler has enough context information, such as:
Stream<String> s = Stream.empty();
You can infer the type when you call empty().
Two basic uses of Optional:
class OptionalBasics {
static void test(Optional<String> optString) {
if(optString.isPresent())
System.out.println(optString.get());
else
System.out.println("Nothing inside!");
}
public static void main(String[] args) {
test(Stream.of("Epithets").findFirst());
test(Stream.<String>empty().findFirst());
}
}
Epithets
Nothing inside!When you receive an Optional object, you should first call isPresent() to check whether it contains elements. If it exists, you can get it using get().
Convenience function
There are many convenience functions that can unpack Optional, which simplifies the above process of "checking and performing operations on contained objects":
- ifPresent(Consumer): call Consumer when the value exists, otherwise nothing will be done.
- orElse(otherObject): if the value exists, it will be returned directly; otherwise, an otherObject will be generated.
- orElseGet(Supplier): if the value exists, it will be returned directly. Otherwise, use the supplier function to generate an alternative object.
- Orelsethlow (Supplier): if the value exists, return it directly; otherwise, use the supplier function to generate an exception.
The following is a simple demonstration of different convenience functions:
public class Optionals {
static void basics(Optional<String> optString) {
if(optString.isPresent())
System.out.println(optString.get());
else
System.out.println("Nothing inside!");
}
static void ifPresent(Optional<String> optString) {
optString.ifPresent(System.out::println);
}
static void orElse(Optional<String> optString) {
System.out.println(optString.orElse("Nada"));
}
static void orElseGet(Optional<String> optString) {
System.out.println(
optString.orElseGet(() -> "Generated"));
}
static void orElseThrow(Optional<String> optString) {
try {
System.out.println(optString.orElseThrow(
() -> new Exception("Supplied")));
} catch(Exception e) {
System.out.println("Caught " + e);
}
}
static void test(String testName, Consumer<Optional<String>> cos) {
System.out.println(" === " + testName + " === ");
cos.accept(Stream.of("Epithets").findFirst());
cos.accept(Stream.<String>empty().findFirst());
}
public static void main(String[] args) {
test("basics", Optionals::basics);
test("ifPresent", Optionals::ifPresent);
test("orElse", Optionals::orElse);
test("orElseGet", Optionals::orElseGet);
test("orElseThrow", Optionals::orElseThrow);
}
}
=== basics ===
Epithets
Nothing inside!
=== ifPresent ===
Epithets
=== orElse ===
Epithets
Nada
=== orElseGet ===
Epithets
Generated
=== orElseThrow ===
Epithets
Caught java.lang.Exception: Suppliedtest() avoids duplicate code by passing in a Consumer that applies to all methods.
orElseThrow() uses the catch keyword to catch the thrown exception.
Create Optional
When we add Optional to our code, we can use the following three static methods:
- empty(): generate an empty option.
- of(value): wrap a non null value in Optional.
- ofNullable(value): for a value that may be empty, Optional.empty is automatically generated when it is empty. Otherwise, the value is wrapped in Optional.
Code example:
class CreatingOptionals {
static void test(String testName, Optional<String> opt) {
System.out.println(" === " + testName + " === ");
System.out.println(opt.orElse("Null"));
}
public static void main(String[] args) {
test("empty", Optional.empty());
test("of", Optional.of("Howdy"));
try {
test("of", Optional.of(null));
} catch(Exception e) {
System.out.println(e);
}
test("ofNullable", Optional.ofNullable("Hi"));
test("ofNullable", Optional.ofNullable(null));
}
}
=== empty ===
Null
=== of ===
Howdy
java.lang.NullPointerException
=== ofNullable ===
Hi
=== ofNullable ===
NullWe cannot create an Optional object by passing null to of(). The safest way is to use ofNullable() to handle nulls gracefully.
Optional object operation
When our flow pipeline generates an Optional object, the following methods can enable the subsequent operations of Optional:
- filter(Predicate): apply Predicate to the content in Optional and return the result. Returns null when Optional does not satisfy Predicate. If Optional is empty, it will be returned directly.
- map(Function): if Optional is not empty, the Function is applied to the contents of Optional and the result is returned. Otherwise, it directly returns Optional.empty.
- flatMap(Function): the same as map(), but the provided mapping function wraps the result in an Optional object, so flatMap() will not wrap at the end.
None of the above methods is applicable to numerical option. Generally speaking, the filter() of the stream will remove the stream element when the Predicate returns false. The Optional.filter() does not delete the Optional when it fails, but keeps it and converts it to null.
class OptionalFilter {
static String[] elements = {
"Foo", "", "Bar", "Baz", "Bingo"
};
static Stream<String> testStream() {
return Arrays.stream(elements);
}
static void test(String descr, Predicate<String> pred) {
System.out.println(" ---( " + descr + " )---");
for(int i = 0; i <= elements.length; i++) {
System.out.println(
testStream()
.skip(i)
.findFirst()
.filter(pred));
}
}
public static void main(String[] args) {
test("true", str -> true);
test("false", str -> false);
test("str != \"\"", str -> str != "");
test("str.length() == 3", str -> str.length() == 3);
test("startsWith(\"B\")",
str -> str.startsWith("B"));
}
}Even if the output looks like a stream, especially the for loop in test(). Each time the for loop restarts the flow, and then skips the specified number of elements according to the index of the for loop. This is its final result on each successive element in the flow. Next, call findFirst() to get the first of the remaining elements, and the result will be wrapped in Optional.
Note that unlike ordinary for loops, the index value range here is not I < elements.length, but I < = elements.length. So the last element actually goes beyond the stream. Conveniently, this will automatically become Optional.empty.
As with map(), Optional.map() applies to functions. It applies the mapping function only when option is not empty and extracts the contents of option into the mapping function. Code example:
class OptionalMap {
static String[] elements = {"12", "", "23", "45"};
static Stream<String> testStream() {
return Arrays.stream(elements);
}
static void test(String descr, Function<String, String> func) {
System.out.println(" ---( " + descr + " )---");
for (int i = 0; i <= elements.length; i++) {
System.out.println(
testStream()
.skip(i)
.findFirst() // Produces an Optional
.map(func));
}
}
public static void main(String[] args) {
// If Optional is not empty, map() first extracts
// the contents which it then passes
// to the function:
test("Add brackets", s -> "[" + s + "]");
test("Increment", s -> {
try {
return Integer.parseInt(s) + 1 + "";
} catch (NumberFormatException e) {
return s;
}
});
test("Replace", s -> s.replace("2", "9"));
test("Take last digit", s -> s.length() > 0 ?
s.charAt(s.length() - 1) + "" : s);
}
// After the function is finished, map() wraps the
// result in an Optional before returning it:
}The return result of the mapping function is automatically wrapped as optional. Optional.empty will be skipped directly.
Optional's flatMap() is applied to the mapping function that has generated optional, so flatMap() does not encapsulate the results in optional like map(). Code example:
// streams/OptionalFlatMap.java
import java.util.Arrays;
import java.util.Optional;
import java.util.function.Function;
import java.util.stream.Stream;
class OptionalFlatMap {
static String[] elements = {"12", "", "23", "45"};
static Stream<String> testStream() {
return Arrays.stream(elements);
}
static void test(String descr,
Function<String, Optional<String>> func) {
System.out.println(" ---( " + descr + " )---");
for (int i = 0; i <= elements.length; i++) {
System.out.println(
testStream()
.skip(i)
.findFirst()
.flatMap(func));
}
}
public static void main(String[] args) {
test("Add brackets",
s -> Optional.of("[" + s + "]"));
test("Increment", s -> {
try {
return Optional.of(
Integer.parseInt(s) + 1 + "");
} catch (NumberFormatException e) {
return Optional.of(s);
}
});
test("Replace",
s -> Optional.of(s.replace("2", "9")));
test("Take last digit",
s -> Optional.of(s.length() > 0 ?
s.charAt(s.length() - 1) + ""
: s));
}
}The same as map(), flatMap() will extract the content of non empty Optional and apply it to the mapping function. The only difference is that flatmap () does not wrap the result in Optional because the mapping function has been wrapped. In the above example, we have explicitly wrapped each mapping function, but it is obvious that Optional.flatMap() is designed for those functions that have generated Optional themselves.
Optional stream
Assuming that your generator may generate null values, when using it to create a stream, you will think of wrapping elements with Optional:
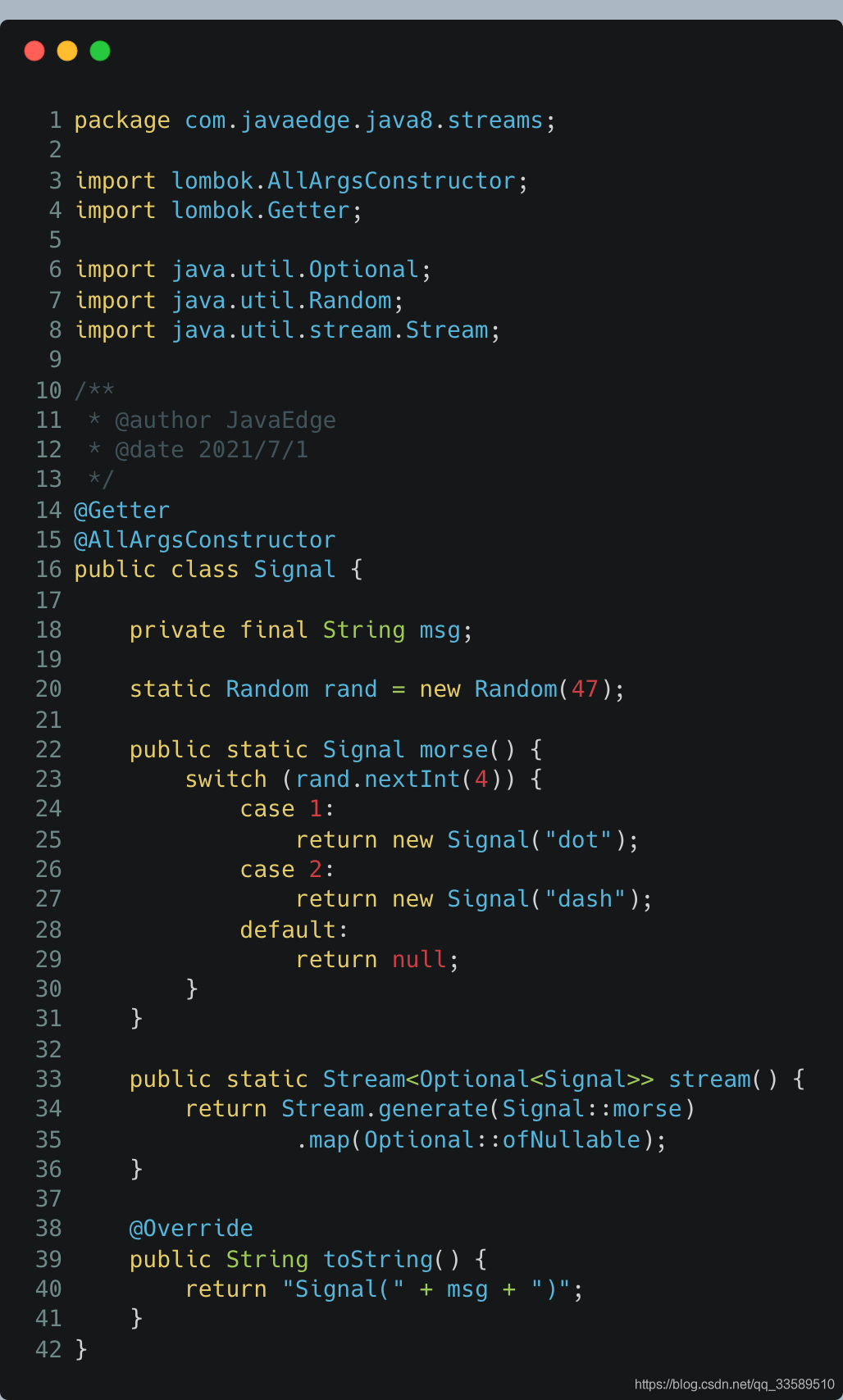
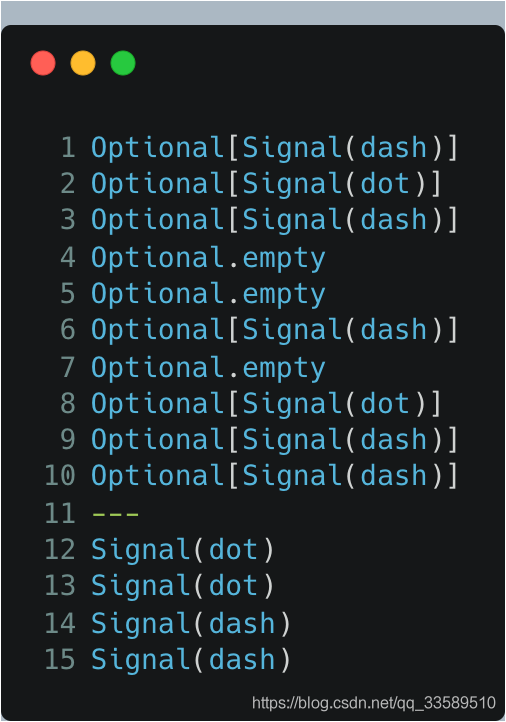
When using this stream, you must know how to unpack Optional:
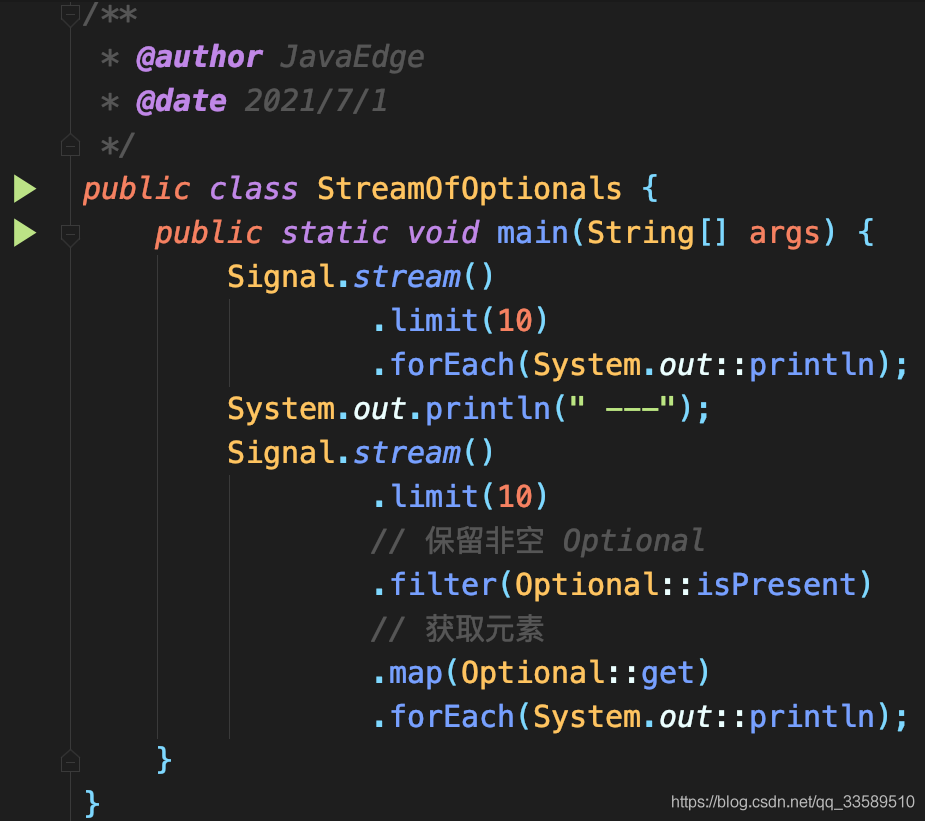
Output results:
Since the meaning of "null value" needs to be defined in each case, we usually adopt different methods for each application.
Terminal operation
The following operation will get the final result of the stream. At this point, we can no longer continue to pass the stream back. It can be said that terminal operation is always the last thing we do in the flow pipeline.
array
- toArray(): convert the stream to an array of the appropriate type
- toArray(generator): in special cases, generate arrays of custom types
Assume that the random number generated by the stream to be multiplexed:
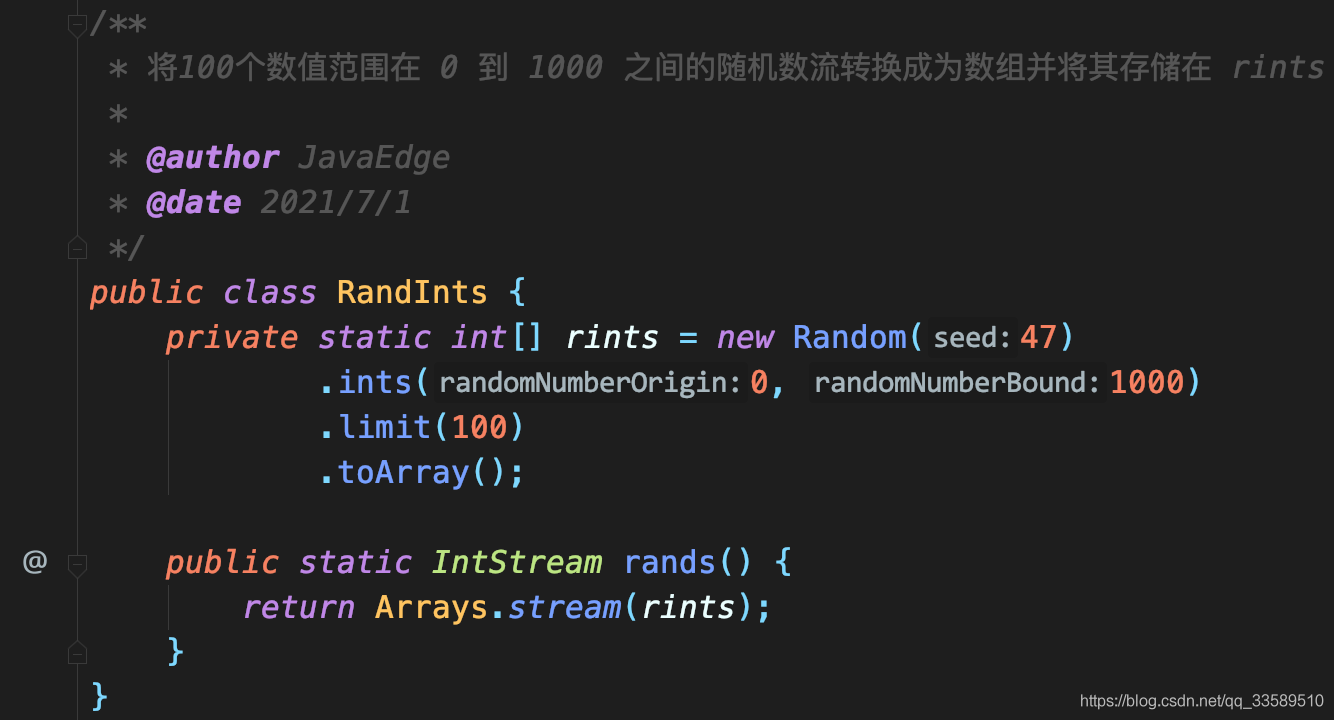
In this way, the same integer stream can be obtained repeatedly each time rands() is called.
loop
- forEach(Consumer) is common, such as System.out::println as the Consumer function.
- forEach ordered (consumer): ensure that forEach operates in the original flow order.
The first form: unordered operation, which is meaningful only when parallel flow is introduced. parallel(): it can realize multi processor parallel operation. The implementation principle is to divide the stream into multiple (usually the number of CPU cores) and perform operations on different processors. This is possible because we use internal iterations rather than external iterations.
The following example introduces parallel() to help understand the role and usage scenario of forEachOrdered(Consumer):
// streams/ForEach.java
import java.util.*;
import java.util.stream.*;
import static streams.RandInts.*;
public class ForEach {
static final int SZ = 14;
public static void main(String[] args) {
rands().limit(SZ)
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEach(n -> System.out.format("%d ", n));
System.out.println();
rands().limit(SZ)
.parallel()
.forEachOrdered(n -> System.out.format("%d ", n));
}
}In order to test arrays of different sizes, we extract SZ variables. The results are interesting: in the first stream, parallel() is not used, so rands() displays the results in the order in which the element iterations appear; In the second stream, parallel() is introduced. Even if the stream is small, the output order is different from the previous one. This is due to the parallel operation of multiprocessors. Run the test several times and the results are different. This result is caused by the non deterministic factors brought by multiprocessor parallel operation.
In the last flow, both parallel() and forEachOrdered() are used to force the original flow order to be maintained. Therefore, using forEachOrdered() for non parallel flows has no impact.
aggregate
- collect(Collector): use the Collector to collect stream elements into the result collection.
- collect(Supplier, BiConsumer, BiConsumer): as above, the first parameter Supplier creates a new result set, the second parameter BiConsumer contains the next element into the result, and the third parameter BiConsumer is used to combine the two values.
Suppose we now store the elements in TreeSet to ensure their order. Collectors do not have a specific toTreeSet(), but you can build any type of collection by passing the constructor reference of the collection to Collectors.toCollection().
For example, collect words in a file into TreeSet:
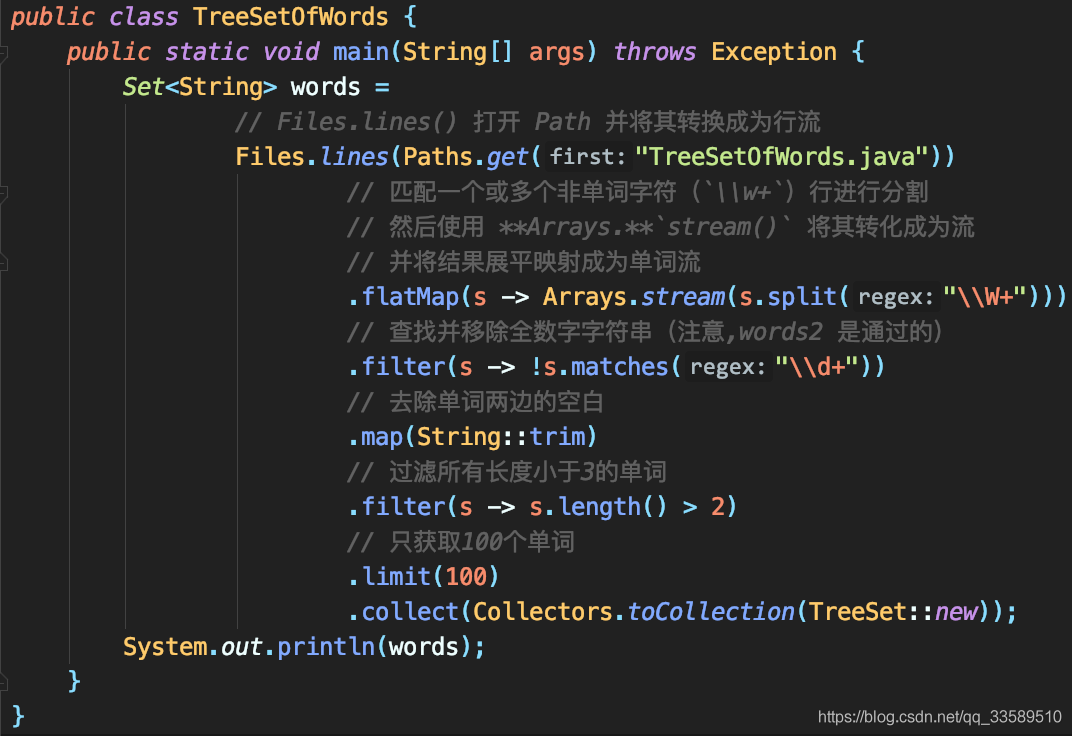
We can also generate a Map in the stream. Code example:
// streams/MapCollector.java
import java.util.*;
import java.util.stream.*;
class Pair {
public final Character c;
public final Integer i;
Pair(Character c, Integer i) {
this.c = c;
this.i = i;
}
public Character getC() { return c; }
public Integer getI() { return i; }
@Override
public String toString() {
return "Pair(" + c + ", " + i + ")";
}
}
class RandomPair {
Random rand = new Random(47);
// An infinite iterator of random capital letters:
Iterator<Character> capChars = rand.ints(65,91)
.mapToObj(i -> (char)i)
.iterator();
public Stream<Pair> stream() {
return rand.ints(100, 1000).distinct()
.mapToObj(i -> new Pair(capChars.next(), i));
}
}
public class MapCollector {
public static void main(String[] args) {
Map<Integer, Character> map =
new RandomPair().stream()
.limit(8)
.collect(
Collectors.toMap(Pair::getI, Pair::getC));
System.out.println(map);
}
}Output results:
{688=W, 309=C, 293=B, 761=N, 858=N, 668=G, 622=F, 751=N}Pair is just a basic data object. RandomPair creates a randomly generated pair object stream. In Java, we can't combine two streams directly in some way. So here we create an integer stream and use mapToObj() to convert it into a pair stream. capChars randomly generated uppercase iterators start with the stream, and then iterator() allows us to use it in stream(). As far as I know, this is the only way to combine multiple streams to generate a new object stream.
Here, we only use the simplest form of Collectors.toMap(), which requires a function that can get key value pairs from the stream. There are other overloaded forms, one of which is that a function is needed to deal with key value conflicts.
In most cases, the preset Collector in java.util.stream.Collectors can meet our requirements. You can also use the second form of collect().
// streams/SpecialCollector.java
import java.util.*;
import java.util.stream.*;
public class SpecialCollector {
public static void main(String[] args) throws Exception {
ArrayList<String> words =
FileToWords.stream("Cheese.dat")
.collect(ArrayList::new,
ArrayList::add,
ArrayList::addAll);
words.stream()
.filter(s -> s.equals("cheese"))
.forEach(System.out::println);
}
}Output results:
cheese cheese
Here, the ArrayList method has performed the operations you need, but it seems more likely that if you must use this form of collect(), you must create a special definition yourself.
Group lists according to one or more fields
In the project, there is a scenario where the list needs to be grouped. Group according to a field or multiple fields of entity in the list to form a map, and then carry out relevant business operations according to the map.
Group by one field
public class ListGroupBy {<!-- -->
public static void main(String[] args) {<!-- -->
List<Score> scoreList = new ArrayList<>();
scoreList.add(new Score().setStudentId("001").setScoreYear("2018").setScore(100.0));
scoreList.add(new Score().setStudentId("001").setScoreYear("2019").setScore(59.5));
scoreList.add(new Score().setStudentId("001").setScoreYear("2019").setScore(99.0));
scoreList.add(new Score().setStudentId("002").setScoreYear("2018").setScore(99.6));
//Group by scoreYear field
Map<String, List<Score>> map = scoreList.stream().collect(
Collectors.groupingBy(
score -> score.getScoreYear()
));
System.out.println(JSONUtil.toJsonPrettyStr(map));
}
}result:
{<!-- -->
"2019": [
{<!-- -->
"studentId": "001",
"score": 59.5,
"scoreYear": "2019"
},
{<!-- -->
"studentId": "001",
"score": 99,
"scoreYear": "2019"
}
],
"2018": [
{<!-- -->
"studentId": "001",
"score": 100,
"scoreYear": "2018"
},
{<!-- -->
"studentId": "002",
"score": 99.6,
"scoreYear": "2018"
}
]
}Group by multiple fields
take
//Group by scoreYear field
Map<String, List<Score>> map = scoreList.stream().collect(
Collectors.groupingBy(
score -> score.getScoreYear()
));Change to
//Group by scoreYear and studentId fields
Map<String, List<Score>> map = scoreList.stream().collect(
Collectors.groupingBy(
score -> score.getScoreYear()+'-'+score.getStudentId()
));result:
{<!-- -->
"2019-001": [
{<!-- -->
"studentId": "001",
"score": 59.5,
"scoreYear": "2019"
},
{<!-- -->
"studentId": "001",
"score": 99,
"scoreYear": "2019"
}
],
"2018-001": [
{<!-- -->
"studentId": "001",
"score": 100,
"scoreYear": "2018"
}
],
"2018-002": [
{<!-- -->
"studentId": "002",
"score": 99.6,
"scoreYear": "2018"
}
]
}combination
- reduce(BinaryOperator): use BinaryOperator to combine elements in all streams. Because the stream may be empty, its return value is Optional.
- Reduce (identity, binary operator): the function is the same as above, but identity is used as the initial value of its combination. Therefore, if the stream is empty, identity is the result.
- reduce(identity, BiFunction, BinaryOperator): a more complex form of use (not introduced temporarily), which is included here because it can improve efficiency. In general, we can explicitly combine map() and reduce() to express it more simply.
Let's take a look at the code example of reduce:
// streams/Reduce.java
import java.util.*;
import java.util.stream.*;
class Frobnitz {
int size;
Frobnitz(int sz) { size = sz; }
@Override
public String toString() {
return "Frobnitz(" + size + ")";
}
// Generator:
static Random rand = new Random(47);
static final int BOUND = 100;
static Frobnitz supply() {
return new Frobnitz(rand.nextInt(BOUND));
}
}
public class Reduce {
public static void main(String[] args) {
Stream.generate(Frobnitz::supply)
.limit(10)
.peek(System.out::println)
.reduce((fr0, fr1) -> fr0.size < 50 ? fr0 : fr1)
.ifPresent(System.out::println);
}
}Output results:
Frobnitz(58) Frobnitz(55) Frobnitz(93) Frobnitz(61) Frobnitz(61) Frobnitz(29) Frobnitz(68) Frobnitz(0) Frobnitz(22) Frobnitz(7) Frobnitz(29)
Frobnitz contains a generator called supply(); Because this method is signature compatible with the Supplier, we can pass its method reference to Stream.generate() (this signature compatibility is called structural consistency). The return value of the reduce() method without "initial value" is of type optional. Optional.ifPresent() calls Consumer only when the result is not empty (the println method can be called because frobnitz can be converted to String through the toString() method).
The first parameter fr0 in the Lambda expression is the result of the last call to reduce(). The second parameter fr1 is the value passed from the stream.
The Lambda expression in reduce() uses a ternary expression to obtain the result. When its length is less than 50, get fr0, otherwise get the next value fr1 in the sequence. When the first Frobnitz with a length less than 50 is obtained, the others will be ignored as long as the result is obtained. This is a very strange constraint, and it really gives us a better understanding of reduce().
matching
- allMatch(Predicate): if each element of the stream returns true according to the provided Predicate, the result is returned as true. At the first false, the calculation stops.
- anyMatch(Predicate): if any element in the stream returns true according to the provided Predicate, the result returns true. The first false is to stop the calculation.
- noneMatch(Predicate): if each element of the stream returns false according to the provided Predicate, the result is returned as true. Stops the calculation at the first true.
We have seen an example of noneMatch() in Prime.java; The usage of allMatch() and anyMatch() is basically the same. Let's explore the short circuit behavior. To eliminate redundant code, we created show(). First, we must know how to uniformly describe the operations of the three matchers, and then convert them into Matcher interfaces. Code example:
// streams/Matching.java
// Demonstrates short-circuiting of *Match() operations
import java.util.stream.*;
import java.util.function.*;
import static streams.RandInts.*;
interface Matcher extends BiPredicate<Stream<Integer>, Predicate<Integer>> {}
public class Matching {
static void show(Matcher match, int val) {
System.out.println(
match.test(
IntStream.rangeClosed(1, 9)
.boxed()
.peek(n -> System.out.format("%d ", n)),
n -> n < val));
}
public static void main(String[] args) {
show(Stream::allMatch, 10);
show(Stream::allMatch, 4);
show(Stream::anyMatch, 2);
show(Stream::anyMatch, 0);
show(Stream::noneMatch, 5);
show(Stream::noneMatch, 0);
}
}Output results:
1 2 3 4 5 6 7 8 9 true 1 2 3 4 false 1 true 1 2 3 4 5 6 7 8 9 false 1 false 1 2 3 4 5 6 7 8 9 true
BiPredicate is a binary Predicate that accepts only two parameters and returns only true or false. Its first parameter is the stream we want to test, and its second parameter is a Predicate. Matcher is applicable to all Stream::*Match methods, so we can pass each to show(). The call of match.test() will be converted into the call of Stream::*Match function.
show() gets two parameters, the Matcher matcher and the Val used to represent the maximum value in the predicate test n < val. This method generates an integer stream between 1 and 9. peek() is used to show us the test before the short circuit. It can be seen from the output that a short circuit has occurred each time.
lookup
- findFirst(): returns the option of the first stream element. If the stream is empty, it returns option.empty.
- findAny(): returns Optional with any stream element. If the stream is empty, it returns Optional.empty.
Code example:
// streams/SelectElement.java
import java.util.*;
import java.util.stream.*;
import static streams.RandInts.*;
public class SelectElement {
public static void main(String[] args) {
System.out.println(rands().findFirst().getAsInt());
System.out.println(
rands().parallel().findFirst().getAsInt());
System.out.println(rands().findAny().getAsInt());
System.out.println(
rands().parallel().findAny().getAsInt());
}
}Output results:
258 258 258 242
findFirst() will always select the first element in the stream regardless of whether the stream is parallelized or not. For non parallel streams, findAny() will select the first element in the stream (even if any element is selected by definition). In this example, we use parallel() to parallel streams, thus introducing the possibility of findAny() selecting non first stream elements.
If you must select the last element in the stream, use reduce(). Code example:
// streams/LastElement.java
import java.util.*;
import java.util.stream.*;
public class LastElement {
public static void main(String[] args) {
OptionalInt last = IntStream.range(10, 20)
.reduce((n1, n2) -> n2);
System.out.println(last.orElse(-1));
// Non-numeric object:
Optional<String> lastobj =
Stream.of("one", "two", "three")
.reduce((n1, n2) -> n2);
System.out.println(
lastobj.orElse("Nothing there!"));
}
}Output results:
19 three
The parameter of reduce() only replaces the last two elements with the last element, and only the last element is generated in the end. If it is a digital stream, you must use a similar numeric optional type, otherwise use an Optional type, just like the option in the above example.
information
- count(): the number of elements in the stream.
- max(Comparator): the "maximum" element determined according to the passed in Comparator.
- min(Comparator): the "minimum" element determined according to the passed in Comparator.
The String type has a preset Comparator implementation. Code example:
// streams/Informational.java
import java.util.stream.*;
import java.util.function.*;
public class Informational {
public static void
main(String[] args) throws Exception {
System.out.println(
FileToWords.stream("Cheese.dat").count());
System.out.println(
FileToWords.stream("Cheese.dat")
.min(String.CASE_INSENSITIVE_ORDER)
.orElse("NONE"));
System.out.println(
FileToWords.stream("Cheese.dat")
.max(String.CASE_INSENSITIVE_ORDER)
.orElse("NONE"));
}
}Output results:
32 a you
The return types of min() and max() are Optional, which requires us to unpack using orElse().
Digital stream information
- average(): get the average value of stream elements.
- max() and min(): Comparator is not required for numerical flow operation.
- sum(): sum all flow elements.
- summaryStatistics(): generate potentially useful data. At present, it is not clear that this method is necessary, because we can actually use a more direct method to obtain the required data.
// streams/NumericStreamInfo.java
import java.util.stream.*;
import static streams.RandInts.*;
public class NumericStreamInfo {
public static void main(String[] args) {
System.out.println(rands().average().getAsDouble());
System.out.println(rands().max().getAsInt());
System.out.println(rands().min().getAsInt());
System.out.println(rands().sum());
System.out.println(rands().summaryStatistics());
}
}Output results:
507.94
998
8
50794
IntSummaryStatistics{count=100, sum=50794, min=8, average=507.940000, max=998}The above example is also applicable to LongStream and DoubleStream.