Automatic text classification technology liberates human beings from tedious manual classification, makes the classification task more efficient, and lays the foundation for further data mining and analysis. For news, short news introduction is a high summary of news content. The research on short text classification has always been a research hotspot of automatic text classification technology. Based on the data in CCTV web pages, this paper uses the combination of TF-IDF and naive Bayesian classification algorithm to capture the semantics of short text expression, intelligently realize the automatic text classification of short text, provide reference for the implementation of news classification of news websites, and finally evaluate the prediction results according to kappa coefficient.
Keywords: TF-IDF; Naive Bayes Journalism; Text classification;
kappa coefficient
1 background introduction
News is an important way for people to obtain information and understand the hot spots of current affairs. Especially in recent years, the digitization of the news industry has developed rapidly and the popularity of news network platform has greatly met people's wish to "know the world without leaving home". Text data such as news reports, news comments and netizens' voice on the network platform are increasing rapidly. Correctly classifying these text data can better organize and make use of these information. Therefore, it is of great significance to complete the task of news classification quickly and accurately.
Facing the huge and growing text information, it is unrealistic to rely on manual classification of massive text information. In recent years, it has become the mainstream to complete the classification task with the help of machine learning technology. Computers can obtain experience and skills through continuous learning, and can give a correct classification label for unknown problems. Therefore, through machine learning, we can automatically classify a large number of data on the news platform, help users improve retrieval efficiency and improve users' reading experience. At the same time, we can analyze and mine useful information on the basis of classification, help website operators understand users' needs and make more effective use of information, which is also the significance of this paper.
2 data analysis
Generally speaking, the text classification model needs to label the corpus of categories in advance as the training set, which belongs to supervised learning. The core problem is to select the appropriate classification algorithm and construct the classification model. In this paper, TF-IDF is used to extract the features of short text data and naive Bayesian algorithm is used to classify the data, so as to integrate the model. The specific text classification steps are as follows:
1) Preprocessing: fill in missing values in the text and delete duplicate values
2) Chinese word segmentation: use the jieba Library in python to segment text words and remove stop words.
3) Construct word vector space: count the word frequency of the text and generate the word vector space of the text.
4) Weight strategy - TF-IDF method: use TF-IDF to find feature words and extract them as features reflecting document topics.
5) Classifier: use naive Bayesian algorithm to train classifier.
6) Evaluation classification results: use
kappa coefficient pair
The test results of the classifier are evaluated and analyzed.
2.1 distribution characteristics
Firstly, the descriptive distribution analysis of the data as a whole is carried out, and the statistics of the number distribution of news categories and the distribution of posting time are carried out on the data set of this paper. The results are shown in the figure.
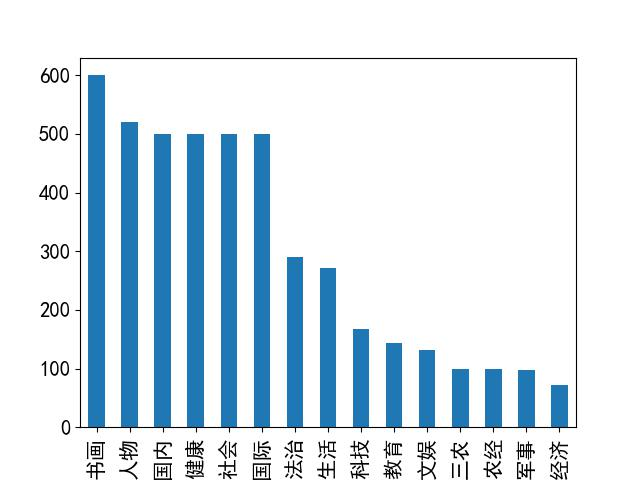
Figure 2.1 distribution of news categories
As can be seen from the above figure, the overall distribution of data is uneven and the polarization is serious. Among them, calligraphy and painting, figures, domestic, health, social and international distribution are generally consistent, which is the main part of the data; Rule of law and life are second; The distribution of science and technology, education, entertainment, agriculture, rural areas and farmers, agricultural economy, military and economy is consistent, but the proportion of data is very low. Combined with real life, people tend to pay more attention to the news on health, people, society and other topics, so the corresponding news reports will be more.
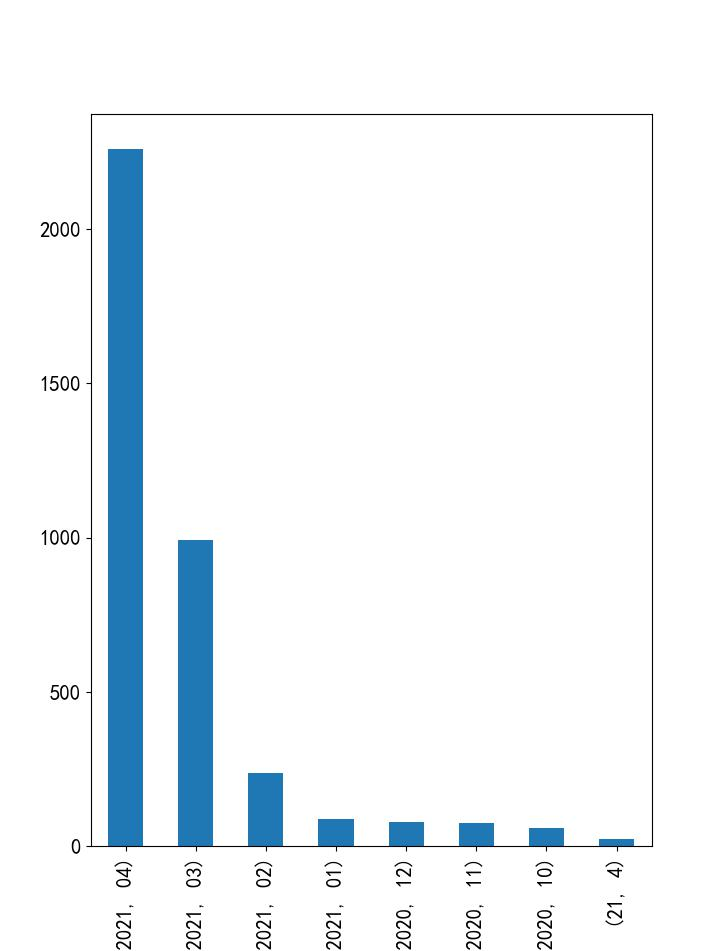
Figure 2.2 news time distribution
As can be seen from the above figure, the news data crawled in this paper is from December 2020 to April 2021. Among them, the data in April of this year accounts for the most, while the data in other months are evenly distributed. It can be seen that the news has strong timeliness. The system will give priority to automatically recommending news in the near time to users, followed by historical data.
2.2 data preprocessing
The data source of this paper is the news data of CCTV channel. Text preprocessing is a common and necessary step in text classification. By removing inconsistent or non entity semantic characters and filtering stop words after word segmentation, text can be reduced as much as possible
The impact of noise on classification performance. And it can effectively reduce the memory occupied by the model and improve the generalization ability of the model. This paper mainly adopts character cleaning, word segmentation and de stop word in text data preprocessing. At present, the common word segmentation tools in the industry include jieba word segmentation, Tsinghua word segmentation tool and Stanford word segmentation package. jieba word segmentation is relatively good in part of speech tagging, word segmentation accuracy, word segmentation granularity and performance. Therefore, jieba is mainly used for text word segmentation in this paper. Because the data length of news headlines is short and the semantic expression is concise, all jieba stop words can not be used. This paper only filters some very common stop words, such as "ne", "Ma" and "de", which not only ensures the semantic integrity to the greatest extent, but also removes the stop words as much as possible.
2.3 TF-IDF mining text features
Text data belongs to unstructured data, which is generally converted into structured data, generally converting text into "document"
-Word frequency matrix ", the elements in the matrix use word frequency or TF-IDF. The main idea of TF-IDF is that if a word or phrase appears frequently in one article and rarely in other articles, it is considered that this word or phrase has good classification ability and is suitable for classification.
TF − IDF = TF ∗ IDF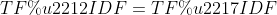
Main idea of IDF: if there are fewer documents containing entry T, that is, the smaller n, the larger IDF, it indicates that entry t has good discrimination ability.
TF refers to the frequency of a given word in the file, which is the normalization of the number of words. IDF is a measure of the importance of a word, IDF=log (D/Dn), where the logarithm is based on 2, D is the total number of text, and Dn is the number of times the word has appeared in n web pages.
2.4 naive Bayesian classifier
Bayesian classification is the general name of a class of classification algorithms. These algorithms are based on Bayesian theorem, so they are collectively referred to as Bayesian classification. Naive Bayes algorithm is one of the most widely used classification algorithms. Naive Bayesian classifier is a series of simple probability classifiers based on Bayesian theorem that assumes strong (naive) independence between features. It is based on a simple assumption that attributes are conditionally independent of each other when the target value is determined. One advantage of naive Bayesian classifier is that it only needs to estimate the necessary parameters (mean and variance of variables) according to a small amount of training data.
Bayesian theorem is A theorem related to the edge probability of random events A and B. Where P(AIB) occurs at B
The possibility of occurrence of A.
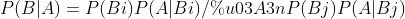
The idea of naive Bayes is basically: for the item to be classified, solve the probability of each category when the item appears, and the category of the item to be classified is the classification of the maximum probability. The advantages of naive Bayesian classification model are:
1) Low time complexity and space complexity;
2) The logic of the algorithm is clear and simple, easy to understand and convert into specific programs;
3) The effect of the algorithm is not easily disturbed by other factors, and the model has good robustness.
Based on the conditional independence assumption, the naive Bayesian classifier assumes that the influence of one attribute on the specified category is independent of other attributes, and the minimum misclassification rate of the naive Bayesian classification algorithm is the same when the conditional independence assumption takes effect. However, the naive Bayesian hypothesis is often not tenable in practice, which affects the classification effect of naive Bayesian classifier.
2.5 Kappa coefficient
kappa coefficient is a method used to evaluate consistency in statistics. The value range is [- 1,1]. In practical application, it is generally [0,1], which is similar to the principle that there is generally no lower convex curve in ROC curve. The higher the value of this coefficient, the higher the classification accuracy of the model.
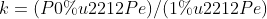
Among them,
ܲ
0
Indicates the overall classification accuracy,
ܲ
݁
Represents SUM (number of real samples of class i * number of predicted samples of class i) / square of total number of samples.
| coefficient | 0-0.2 | 0.2-0.4 | 0.4-0.6 | 0.6-0.8 | 0.8-1 |
| Consistency coefficient | Very low | commonly | secondary | height | Almost identical |
Table 2.5 advantages and disadvantages of evaluation indicators
3 classification results
According to the above classification principle, firstly, the training data is used for model training, and then the trained model is used to predict the validation data, so as to verify the generalization ability of the trained model. The predicted classification results are as follows: (calligraphy and painting: 0, character: 1, international: 2, domestic: 3, health: 4, society: 5, rule of law: 6, life: 7, science and technology: 8, education: 9, entertainment: 10, agricultural economy: 11, agriculture, rural areas and farmers: 12, military: 13, economy: 14)
Classification accuracy: 0.6059661620658949
| precision | recall | f1-score | support | |
| 0 | 0.57 | 0.95 | 0.71 | 298 |
| 1 | 0.47 | 0.76 | 0.58 | 241 |
| 2 | 0.66 | 0.91 | 0.77 | 236 |
| 3 | 0.59 | 0.61 | 0.60 | 259 |
| 4 | 0.81 | 0.86 | 0.83 | 264 |
| 5 | 0.50 | 0.62 | 0.55 | 259 |
| 6 | 0.83 | 0.42 | 0.56 | 146 |
| 7 | 0.69 | 0.15 | 0.25 | 133 |
| 8 | 1.00 | 0.02 | 0.04 | 92 |
| 9 | 0.75 | 0.04 | 0.08 | 68 |
| 10 | 0.00 | 0.00 | 0.00 | 66 |
| 11 | 0.00 | 0.00 | 0.00 | 48 |
| 12 | 1.00 | 1.00 | 1.00 | 47 |
| 13 | 0.00 | 0.00 | 0.00 | 50 |
| 14 | 0.00 | 0.00 | 0.00 | 39 |
| precision | recall | f1-score | support | |
| accuracy | 0.61 | 2246 | ||
| macro avg | 0.52 | 0.42 | 0.40 | 2246 |
| weighted avg 0.59 0.61 0.54 2246 Kappa:0.5562815523035762 | ||||
It can be seen from the above results that the classification accuracy of the model trained based on TF-IDF and naive Bayesian algorithm on the test set is 0.61, and the classification results are more accurate. For each topic in the news, we can clearly see the accuracy, recall, F1 value and the number of accurate predictions of the model for each category. It can be found that the index coefficients of agriculture, rural areas and farmers numbered "12" have reached 1, which shows that the model trained in this paper can perfectly identify the news of this kind of topic; For "10, 11, 13 and 14", that is, the index coefficients of entertainment, agricultural economy, military and economy are all 0. It can be seen that the model in this paper does not extract the characteristics of the news of these four types of topics in place, and further attention needs to be paid to these aspects to optimize the model; The remaining topics are above the medium level. The final Kappa coefficient is a comprehensive evaluation index for multi classification indexes, and its value is 0.56, close to 0.6. Therefore, the classification accuracy of this model is high.
4 Conclusion
According to the characteristics of Chinese short text, this paper takes news headlines as experimental data, uses TF-IDF to effectively extract the semantic information in news headlines, constructs a classification model based on Naive Bayes, and realizes the automatic classification of news headlines on the network news platform, which has certain promoting significance for the construction of news websites and further information mining. In the future, based on this, we can analyze users' preferences for reading news, realize personalized news recommendation, and bring users better experience and service.
5 future outlook
This paper mainly introduces the necessity and requirements of automatic news text classification in today's society, focusing on the main process, basic principles and methods of text classification. Although Chinese news text classification technology has made some progress under the research of previous scholars, there are still many aspects that need further research and efforts.
enclosure:
import pandas as pd
import matplotlib.pyplot as plt
import warnings
plt.rcParams["font.family"] = "SimHei"
plt.rcParams["axes.unicode_minus"] = False
plt.rcParams["font.size"] = 15
warnings.filterwarnings("ignore")
#Read data
news = pd.read_csv("news (1).csv", encoding="gbk")
print(news.head())
###Missing value processing
news.info()
##Fill in the missing news title with a news introduction
index = news[news.title.isnull()].index
news["title"][index]=news["brief"][index]
##Fill in the missing news profile with news headlines
index = news[news.brief.isnull()].index
news["brief"][index]=news["title"][index]
news.isnull().sum()
#Duplicate value processing
print(news[news.duplicated()])
news.drop_duplicates(inplace=True)
#News category distribution
###Data exploration descriptive analysis
t = news["News category"].value_counts()
print(t)
t.plot(kind="bar")
#Time of occurrence
t = news["Release time"].str.split("-", expand=True)
t2 = t[[0,1]].value_counts()
t2.plot(kind="bar")
#Text content cleaning
import re ####Text processing sub calls the compiled regular object to process the text
re_obj = re.compile(r"['~`!#$%^&*()_+-=|\';:/.,?><~·!@#¥%......&*()-+-=": ';,. ,?><{}': []<>''""\s]+")
def clear(text):
return re_obj.sub("", text)
news["brief"] = news["brief"].apply(clear)
news.sample(10)
#participle
import jieba
def cut_word(text): ###Word segmentation: use jieba's lcut method to segment words and generate a list,
####cut() generates a generator that takes no or very little space. It can be converted into a list using list()
return jieba.lcut(text)
news["brief"] = news["brief"].apply(cut_word)
news.sample(5)
print(news["brief"].head())
#Stop word processing
def get_stopword(): ####Deleting stop words means that a large number of words appear in the text, which are useless for classification, reduce storage and computing time
s = set() ###The key mapping data list processed by hash stores the mapping data in the order of subscripts
with open("Chinese stop list.txt", encoding="gbk") as f:
for line in f:
s.add(line.strip())
return s
def remove_stopword(words):
return [word for word in words if word not in stopword]
stopword = get_stopword()
news["brief"] = news["brief"].apply(remove_stopword)
news.sample(5)
print(news["brief"].head())
#Label conversion
label_mappping = {"Painting and Calligraphy": 0, "character": 1, "international":2,"domestic": 3,"healthy": 4,"Sociology": 5,"rule by law": 6,"life": 7,"science and technology": 8,"education": 9,"Entertainment": 10,
"rural economy": 11,"Agriculture, rural areas and farmers": 12,"military": 13,"Economics": 14}
news["News category"] = news["News category"].map(label_mappping)
print(news.head())
print("--------------------------------------3------------------------------------------")
#Segmentation data
from sklearn.model_selection import train_test_split
x =news["brief"]
y = news["News category"]
x_train, x_test, y_train, y_test = train_test_split(x.values, y.values, test_size=0.5)
def format_transform(X): #x is the data set (training set or test set)
words =[]
for line_index in range(len(X)):
try:
words.append(" ".join(X[line_index]))
except:
print("There is a problem with the data format")
return words
#train
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
words_train = format_transform(x_train)
vectorizer = TfidfVectorizer(analyzer='word', max_features=4000,ngram_range=(1, 3),lowercase = False)
vectorizer.fit(words_train)#Convert to vector format
classifier = MultinomialNB()
classifier.fit(vectorizer.transform(words_train), y_train)
#Test and inspection related results
from sklearn.metrics import classification_report
words_test = format_transform(x_test)
score = classifier.score(vectorizer.transform(words_test), y_test)
print("----------------------------------Classification result report-----------------------------------------")
print("Classification accuracy:" + str(score))
y_predict = classifier.predict(vectorizer.transform(words_test))
print(classification_report(y_test, y_predict))
#evaluating indicator
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y_test, y_predict)
print(kappa)