***
(1) Learn how to build the portraits of [material] and [user] in the form of automation when the news recommendation system is offline:
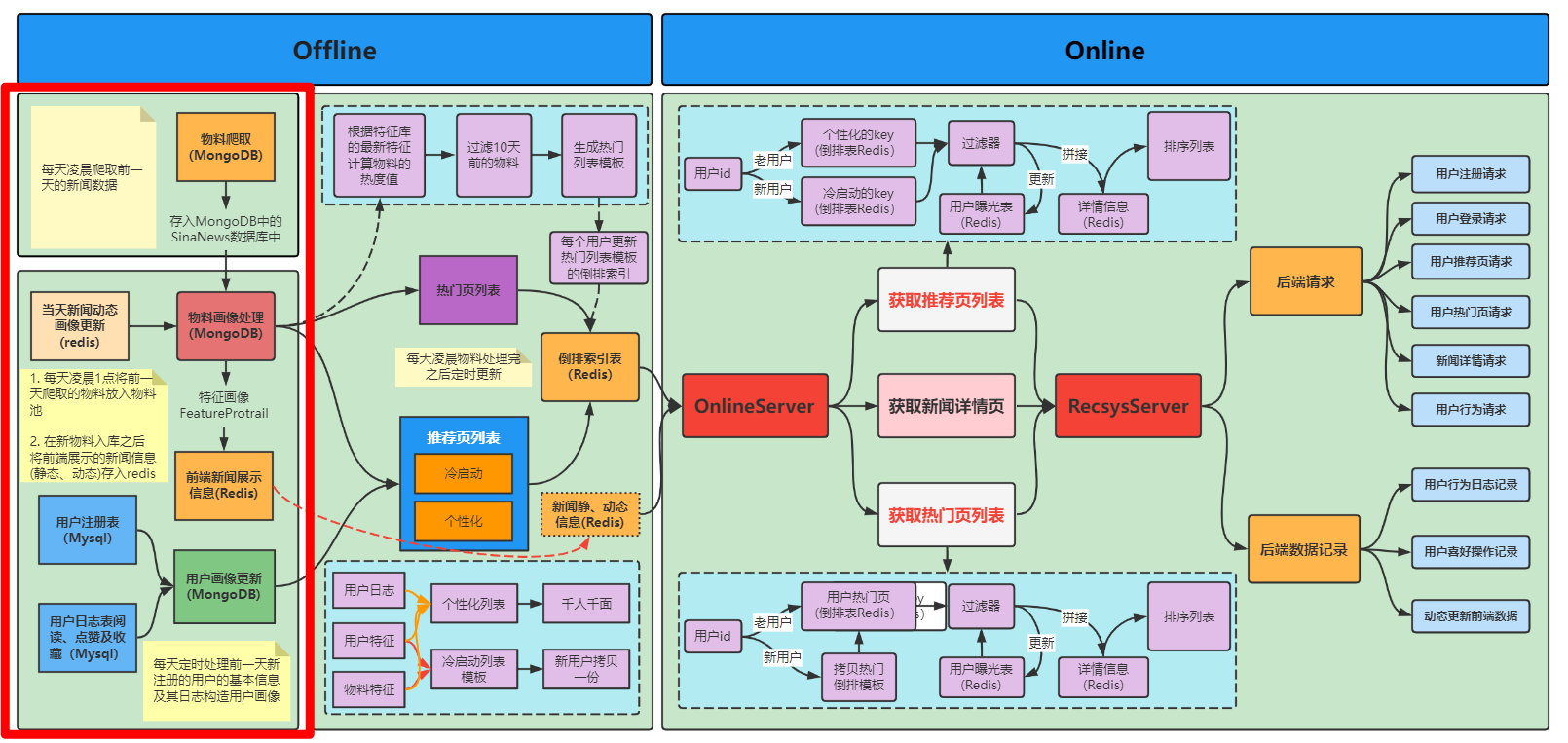
(2)\fun-rec-master\codes\news_recsys\news_rec_server\materials\material_process
- log processing
- News portrait processing
- News portrait saved in redis
(3) User portrait processing
\fun-rec-master\codes\news_recsys\news_rec_server\materials\user_process
Note: after Redis's value is stored in Chinese, the hexadecimal string "\ xe4\xb8\xad\xe5\x9b\xbd" is displayed after get. How to solve it?
When redis cli is started, add – raw after it, and Chinese characters will display normally, as shown above.
(1) Construct news portrait: obtain materials through crawlers and process the crawled data, that is, construct news portrait.
(2) For the user side portrait, we need to add newly registered users to the user portrait library every day. For users who have generated behavior in the system, we also need to update the user's portrait regularly (long and short term).
1, Construction of material side portrait
1.1 new material source
Material source: obtained from the scratch crawler of the previous task.
be careful:
(1) News crawling is to crawl the news of the previous day every morning. The reason for this is that you can climb more materials;
(2) The disadvantage is that the timeliness of materials will be delayed by one day, and the newly crawled materials will be stored in MongoDB.
1.2 update of material image
The update of material image mainly includes the following aspects:
(1) Add new material to material library
(2) Old material portraits are updated through user interaction records
Logic for adding new materials to the material library:
(1) After the news sweep crawler crawls, new materials are added to the material warehouse;
(2) After simple image processing (stored in mongodb) for new materials, the currently defined image fields are as follows:
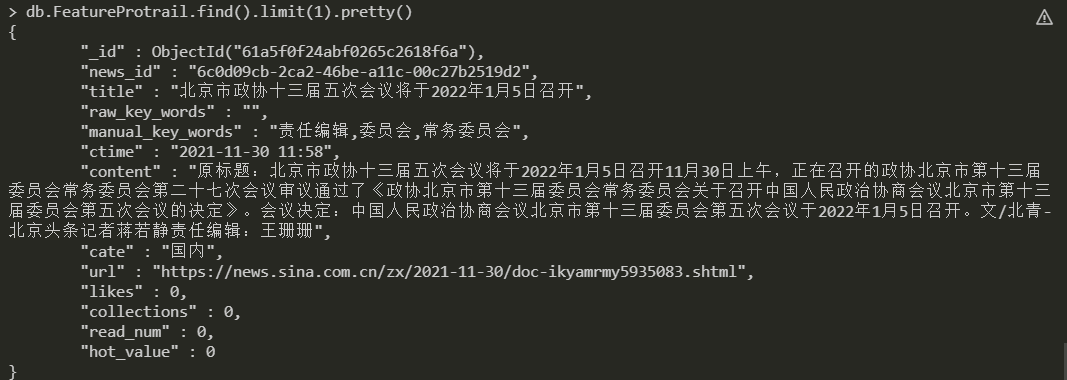
(1) Specific logic for adding new materials to the material warehouse
(1) Traverse all articles crawled today;
(2) Judge whether the article is repeated in the material warehouse through the article title. If it is repeated, it will be de duplicated (that is, the title will be saved in advance for de duplication);
(3) Initialize the fields corresponding to the portrait according to the defined fields;
(4) Stored in the portrait material pool.
For updating the old material image, you need to know which fields of the old material will be updated by the user's behavior. The following is the news list display page. We will find that the front end will display the reading, favorite and collection times of news. User interactions (reading, compliments, and favorites) change these values.

In order to display the dynamic behavior information of news on the front end in real time, we store the dynamic information of news in redis in advance. When online, we directly obtain the news data from redis. If users interact with the news, these dynamic information will be updated, and we also directly update the value in redis, This is mainly to enable the front end to obtain the latest dynamic portrait information of the news in real time.
The dynamic portrait of news is updated in redis, which is a memory database, and the resources are very valuable. We can't store the news information in it all the time, but update it once a day, Update only the news that may be displayed today (some news may have been published for too long, so it is not necessary to show it again due to the timeliness of the news). Therefore, in order to save the dynamic information of news history, the system also needs to update the dynamic news information in redis to the news portrait database stored in mongodb every day. The logic here will be triggered regularly every day, and the logic here will be placed in the updated new material Of course, the sequence of the two here has no impact. You only need to pay attention to updating the material dynamic portrait before the redis data is cleared.
(2) 2 news portrait Libraries
The portrait Library of news actually has two:
- One is called the feature library featureprotrack, which stores all the fields of the material.
- There is also RedisProtrail, a portrait library that stores the front-end display content. The materials in this portrait library are the same, but the content stored in each material is different. The content of this feature library is updated every day as a backup of the news content stored in redis.
Therefore, after updating the portraits of new and old materials, we need to write a copy of the news information in the latest material library to the redistrail material library, and remove some unnecessary fields in the front-end display.
(3) Updated core code of material
1. Material update
File path: D: \ desktop file \ fun rec master \ codes \ news_ recsys\news_ rec_ server\materials\material_ process\news_ protrait. py
# -*- coding: utf-8 -*-
from re import S
import sys
import json
sys.path.append("../")
from material_process.utils import get_key_words
from dao.mongo_server import MongoServer
from dao.redis_server import RedisServer
"""
Fields included in the news portrait:
0. news_id journalistic id
1. title title
2. raw_key_words (The key words that climb down may be missing)
3. manual_key_words (Keywords generated from content)
4. ctime time
5. content Specific news content
6. cate News category
7. likes Number of news likes
8. collections Number of news collections
9. read_nums Reading times
10. url Original news link
"""
class NewsProtraitServer:
def __init__(self):
"""Initialization related parameters
"""
self.mongo_server = MongoServer()
self.sina_collection = self.mongo_server.get_sina_news_collection()
self.material_collection = self.mongo_server.get_feature_protrail_collection()
self.redis_mongo_collection = self.mongo_server.get_redis_mongo_collection()
self.news_dynamic_feature_redis = RedisServer().get_dynamic_news_info_redis()
def _find_by_title(self, collection, title):
"""Search the database for news data with the same title
Data return of current title in database True, Conversely, return Flase
"""
# The find method returns an iterator
find_res = collection.find({"title": title})
if len(list(find_res)) != 0:
return True
return False
def _generate_feature_protrail_item(self, item):
"""Generate feature portrait data and return a new dictionary
"""
news_item = dict()
news_item['news_id'] = item['news_id']
news_item['title'] = item['title']
# The keywords extracted from the news content are not as accurate as those in the original news crawling, so the keywords extracted manually
# Just as a supplement, it can be used when there are no keywords in the original news
news_item['raw_key_words'] = item['raw_key_words']
key_words_list = get_key_words(item['content'])
news_item['manual_key_words'] = ",".join(key_words_list)
news_item['ctime'] = item['ctime']
news_item['content'] = item['content']
news_item['cate'] = item['cate']
news_item['url'] = item['url']
news_item['likes'] = 0
news_item['collections'] = 0
news_item['read_num'] = 0
# Initializing a relatively large heat value will decay over time
news_item['hot_value'] = 1000
return news_item
def update_new_items(self):
"""
Store the data crawled today into the portrait database
"""
# Traverse all the data crawled today
for item in self.sina_collection.find():
# De duplication according to the title
if self._find_by_title(self.material_collection, item["title"]):
continue
news_item = self._generate_feature_protrail_item(item)
# Insert material pool
self.material_collection.insert_one(news_item)
print("run update_new_items success.")
def update_redis_mongo_protrail_data(self):
"""
News details need to be updated to redis And the previous day's redis Data deletion
"""
# Delete the redis display data of the previous day every day, and then write it again
self.redis_mongo_collection.drop()
print("delete RedisProtrail ...")
# Traversal feature library
for item in self.material_collection.find():
news_item = dict()
news_item['news_id'] = item['news_id']
news_item['title'] = item['title']
news_item['ctime'] = item['ctime']
news_item['content'] = item['content']
news_item['cate'] = item['cate']
news_item['url'] = item['url']
news_item['likes'] = 0
news_item['collections'] = 0
news_item['read_num'] = 0
self.redis_mongo_collection.insert_one(news_item)
print("run update_redis_mongo_protrail_data success.")
def update_dynamic_feature_protrail(self):
"""
use redis Dynamic portrait update mongodb Portrait of
"""
# Traverse the dynamic portrait of redis and update the corresponding dynamic portrait in mongodb
news_list = self.news_dynamic_feature_redis.keys()
for news_key in news_list:
news_dynamic_info_str = self.news_dynamic_feature_redis.get(news_key)
news_dynamic_info_str = news_dynamic_info_str.replace("'", '"' ) # Replace single quotation marks with double quotation marks
news_dynamic_info_dict = json.loads(news_dynamic_info_str)
# Query the corresponding data in mongodb and modify the corresponding image
news_id = news_key.split(":")[1]
mongo_info = self.material_collection.find_one({"news_id": news_id})
new_mongo_info = mongo_info.copy()
new_mongo_info['likes'] = news_dynamic_info_dict["likes"]
new_mongo_info['collections'] = news_dynamic_info_dict["collections"]
new_mongo_info['read_num'] = news_dynamic_info_dict["read_num"]
self.material_collection.replace_one(mongo_info, new_mongo_info, upsert=True) # If upsert is True, insert without
print("update_dynamic_feature_protrail success.")
# The script is not executed by the system. The following code is used for testing
if __name__ == "__main__":
news_protrait = NewsProtraitServer()
# Update of new material
news_protrait.update_new_items()
# Update dynamic features
news_protrait.update_dynamic_feature_protrail()
# redis shows the backup of news content
news_protrait.update_redis_mongo_protrail_data()
2. How to add materials to redis database
After the above content has finished updating the materials, let's introduce how to add the updated materials to the redis database. For the storage of news content in redis, we split the news information into two parts, One part is the attributes of the news that will not change (for example, creation time, title, news content, etc.), and the other part is the dynamic attributes of the material. The identifiers of the key s stored in redis are: static_news_detail:news_id and dynamic_news_detail:news_id. the following is the real content stored in redis
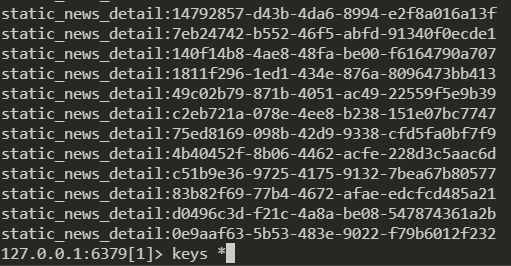
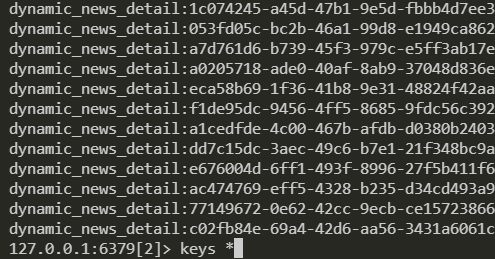
The purpose of this is to be more efficient when changing material dynamic information online in real time. When you need to obtain the detailed information of a news, you need to check the two data and put them together before sending them to the front end for display. The code logic of this part is as follows:
import sys
sys.path.append("../../")
from dao.mongo_server import MongoServer
from dao.redis_server import RedisServer
class NewsRedisServer(object):
def __init__(self):
self.rec_list_redis = RedisServer().get_reclist_redis()
self.static_news_info_redis = RedisServer().get_static_news_info_redis()
self.dynamic_news_info_redis = RedisServer().get_dynamic_news_info_redis()
self.redis_mongo_collection = MongoServer().get_redis_mongo_collection()
# Delete the content in redis of the previous day
self._flush_redis_db()
def _flush_redis_db(self):
"""It needs to be deleted every day redis Update the new content of the day
"""
try:
self.rec_list_redis.flushall()
except Exception:
print("flush redis fail ... ")
def _get_news_id_list(self):
"""Get all the news in the material library id
"""
# Get news of all data_ id,
# Violent access, directly traverse the entire database to get the id of all news
# TODO should have an optimization method that can only return new through query_ ID field
news_id_list = []
for item in self.redis_mongo_collection.find():
news_id_list.append(item["news_id"])
return news_id_list
def _set_info_to_redis(self, redisdb, content):
"""take content Add to specified redis
"""
try:
redisdb.set(*content)
except Exception:
print("set content fail".format(content))
def news_detail_to_redis(self):
"""Store the portrait content to be displayed in redis
Static invariant features are saved to static_news_info_db_num
Dynamically changing features are stored in the dynamic_news_info_db_num
"""
news_id_list = self._get_news_id_list()
for news_id in news_id_list:
news_item_dict = self.redis_mongo_collection.find_one({"news_id": news_id}) # The returned is a list with a dictionary
news_item_dict.pop("_id")
# Separating dynamic and static attributes
static_news_info_dict = dict()
static_news_info_dict['news_id'] = news_item_dict['news_id']
static_news_info_dict['title'] = news_item_dict['title']
static_news_info_dict['ctime'] = news_item_dict['ctime']
static_news_info_dict['content'] = news_item_dict['content']
static_news_info_dict['cate'] = news_item_dict['cate']
static_news_info_dict['url'] = news_item_dict['url']
static_content_tuple = "static_news_detail:" + str(news_id), str(static_news_info_dict)
self._set_info_to_redis(self.static_news_info_redis, static_content_tuple)
dynamic_news_info_dict = dict()
dynamic_news_info_dict['likes'] = news_item_dict['likes']
dynamic_news_info_dict['collections'] = news_item_dict['collections']
dynamic_news_info_dict['read_num'] = news_item_dict['read_num']
dynamic_content_tuple = "dynamic_news_detail:" + str(news_id), str(dynamic_news_info_dict)
self._set_info_to_redis(self.dynamic_news_info_redis, dynamic_content_tuple)
print("news detail info are saved in redis db.")
if __name__ == "__main__":
# Every time this object is created, the previous contents in the database will be deleted
news_redis_server = NewsRedisServer()
# Send the latest front-end portrait to redis
news_redis_server.news_detail_to_redis()
At this position, the update logic of offline material portrait is introduced. Finally, if all the above logic are concatenated with codes, the following codes will be run regularly every day, so that the portrait construction logic on the material side can be worn
from material_process.news_protrait import NewsProtraitServer
from material_process.news_to_redis import NewsRedisServer
def process_material():
"""Material handling function
"""
# Portrait processing
protrail_server = NewsProtraitServer()
# Process the portraits of the latest crawling news and store them in the feature library
protrail_server.update_new_items()
# Updating the news dynamic portrait needs to be performed before the content of redis database is cleared
protrail_server.update_dynamic_feature_protrail()
# Generate a news portrait displayed on the front end and backup it in mongodb
protrail_server.update_redis_mongo_protrail_data()
# The news data is written to redis. Note that when redis data is processed here, all the data of the previous day will be cleared
news_redis_server = NewsRedisServer()
# Send the latest front-end portrait to redis
news_redis_server.news_detail_to_redis()
if __name__ == "__main__":
process_material()
2, Construction of user side portrait
2.1 classification of user portrait updates
The update of user portrait is mainly divided into two aspects:
- Update of newly registered user profile
- Update of old user portrait
2.2 fields of user portrait
Since all registered users are placed in one table (new and old users) in our system, we only need to traverse all users in the registry every time we update the portrait. Before we talk about the specific portrait construction logic, we must first understand the fields contained in the user portrait. The following is directly found from mongo:
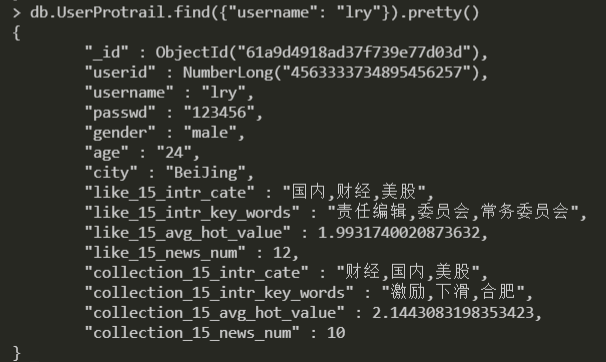
As can be seen from the above, it is mainly some tags related to the user's basic information and user history information. For the user's basic attribute characteristics, they can be obtained directly from the registry. For the information related to the user's history reading, it is necessary to count all the news details read, liked and collected in the user's history. In order to get the information related to users' historical interests, we need to save the historical records of users' historical reading, likes and collections. In fact, these information can be obtained from the log information, but here is an engineering matter that needs to be explained first. First look at the figure below, and click the details page of a news for each user.
There is a favorite and favorite at the bottom. The result of this front-end display is the data obtained from the back-end, which means that the back-end needs to maintain a list of user historical clicks and favorite articles. Here we use mysql to store them, mainly for fear that redis is not enough. In fact, these two tables can be used not only for front-end display, but also for analyzing the user's portrait, which has sorted out the user's history and collection for us.
2.3 mysql table of user history reading articles
In addition, as mentioned earlier, we can use articles read by users' history as user portraits for better processing and understanding, We also maintain a mysql table of all articles read by users in history (the core logic of maintaining the table is to run the user log every day and update the user's Historical Reading Records). At this time, we actually have three user behavior tables: user reading, praise and collection. Next, we can directly make specific portraits related to user interests through these three tables. The specific logic is as follows:
import sys
import datetime
from collections import Counter, defaultdict
from sqlalchemy.sql.expression import table
sys.path.append("../../")
from dao.mongo_server import MongoServer
from dao.mysql_server import MysqlServer
from dao.entity.register_user import RegisterUser
from dao.entity.user_read import UserRead
from dao.entity.user_likes import UserLikes
from dao.entity.user_collections import UserCollections
class UserProtrail(object):
def __init__(self):
self.user_protrail_collection = MongoServer().get_user_protrail_collection()
self.material_collection = MongoServer().get_feature_protrail_collection()
self.register_user_sess = MysqlServer().get_register_user_session()
self.user_collection_sess = MysqlServer().get_user_collection_session()
self.user_like_sess = MysqlServer().get_user_like_session()
self.user_read_sess = MysqlServer().get_user_read_session()
def _user_info_to_dict(self, user):
"""
take mysql The query results are converted into dictionary storage
"""
info_dict = dict()
# Basic attribute characteristics
info_dict["userid"] = user.userid
info_dict["username"] = user.username
info_dict["passwd"] = user.passwd
info_dict["gender"] = user.gender
info_dict["age"] = user.age
info_dict["city"] = user.city
# hobby
behaviors=["like","collection"]
time_range = 15
_, feature_dict = self.get_statistical_feature_from_history_behavior(user.userid,time_range,behavior_types=behaviors)
for type in feature_dict.keys():
if feature_dict[type]:
info_dict["{}_{}_intr_cate".format(type,time_range)] = feature_dict[type]["intr_cate"] # Top 3 news categories most popular in history
info_dict["{}_{}_intr_key_words".format(type,time_range)] = feature_dict[type]["intr_key_words"] # History likes the top 3 keywords of news
info_dict["{}_{}_avg_hot_value".format(type,time_range)] = feature_dict[type]["avg_hot_value"] # Average popularity of news users like
info_dict["{}_{}_news_num".format(type,time_range)] = feature_dict[type]["news_num"] # Number of news users like in 15 days
else:
info_dict["{}_{}_intr_cate".format(type,time_range)] = "" # Top 3 news categories most popular in history
info_dict["{}_{}_intr_key_words".format(type,time_range)] = "" # History likes the top 3 keywords of news
info_dict["{}_{}_avg_hot_value".format(type,time_range)] = 0 # Average popularity of news users like
info_dict["{}_{}_news_num".format(type,time_range)] = 0 # Number of news users like in 15 days
return info_dict
def update_user_protrail_from_register_table(self):
"""
Users registered on that day need to be added to the user portrait pool every day
"""
# Traverse the registered user table
for user in self.register_user_sess.query(RegisterUser).all():
user_info_dict = self._user_info_to_dict(user)
old_user_protrail_dict = self.user_protrail_collection.find_one({"username": user.username})
if old_user_protrail_dict is None:
self.user_protrail_collection.insert_one(user_info_dict)
else:
# Use the parameter upsert to set to true. For those without, a
# replace_ If you encounter the same_ The id will be updated
self.user_protrail_collection.replace_one(old_user_protrail_dict, user_info_dict, upsert=True)
def get_statistical_feature_from_history_behavior(self, user_id, time_range, behavior_types):
"""Get the statistical characteristics of user's historical behavior ["read","like","collection"] """
fail_type = []
sess, table_obj, history = None, None, None
feature_dict = defaultdict(dict)
end = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
start = (datetime.datetime.now()+datetime.timedelta(days=-time_range)).strftime("%Y-%m-%d %H:%M:%S")
for type in behavior_types:
if type == "read":
sess = getattr(self,"user_{}_sess".format(type))
table_obj = UserRead
elif type == "like":
sess = getattr(self,"user_{}_sess".format(type))
table_obj = UserLikes
elif type == "collection":
sess = getattr(self,"user_{}_sess".format(type))
table_obj = UserCollections
try:
history = sess.query(table_obj).filter(table_obj.userid==user_id).filter(table_obj.curtime>=start).filter(table_obj.curtime<=end).all()
except Exception as e:
print(str(e))
fail_type.append(type)
continue
feature_dict[type] = self._gen_statistical_feature(history)
return fail_type, feature_dict
def _gen_statistical_feature(self,history):
""""""
# Get features for history
if not len(history): return None
history_new_id = []
history_hot_value = []
history_new_cate = []
history_key_word = []
for h in history:
news_id = h.newid
newsquery = {"news_id":news_id}
result = self.material_collection.find_one(newsquery)
history_new_id.append(result["news_id"])
history_hot_value.append(result["hot_value"])
history_new_cate.append(result["cate"])
history_key_word += result["manual_key_words"].split(",")
feature_dict = dict()
# Calculate average heat
feature_dict["avg_hot_value"] = 0 if sum(history_hot_value) < 0.001 else sum(history_hot_value) / len(history_hot_value)
# Calculate top 3 categories
cate_dict = Counter(history_new_cate)
cate_list= sorted(cate_dict.items(),key = lambda d: d[1], reverse=True)
cate_str = ",".join([item[0] for item in cate_list[:3]] if len(cate_list)>=3 else [item[0] for item in cate_list] )
feature_dict["intr_cate"] = cate_str
# Calculate the keywords of Top3
word_dict = Counter(history_key_word)
word_list= sorted(word_dict.items(),key = lambda d: d[1], reverse=True)
# TODO keyword belongs to the long tail. If the number of keywords is once, how to go to the top 3
word_str = ",".join([item[0] for item in word_list[:3]] if len(cate_list)>=3 else [item[0] for item in word_list] )
feature_dict["intr_key_words"] = word_str
# Number of news
feature_dict["news_num"] = len(history_new_id)
return feature_dict
if __name__ == "__main__":
user_protrail = UserProtrail().update_user_protrail_from_register_table()
Here is the basic logic of user portrait. The following is the overall logic code of user portrait update:
from user_process.user_to_mysql import UserMysqlServer
from user_process.user_protrail import UserProtrail
"""
1. Convert the user's exposure data from redis Fall mysql Yes.
2. Update user portrait
"""
def process_users():
"""Drop user data Mysql
"""
# User mysql storage
user_mysql_server = UserMysqlServer()
# User exposure data falls into mysql
user_mysql_server.user_exposure_to_mysql()
# Update user portrait
user_protrail = UserProtrail()
user_protrail.update_user_protrail_from_register_table()
if __name__ == "__main__":
process_users()
3, Automatic construction of portrait
For the construction of user side portrait and material side portrait in (I) and (II) above, I have a basic understanding of the material folder, combined with the following mind map of automatic construction of portrait:
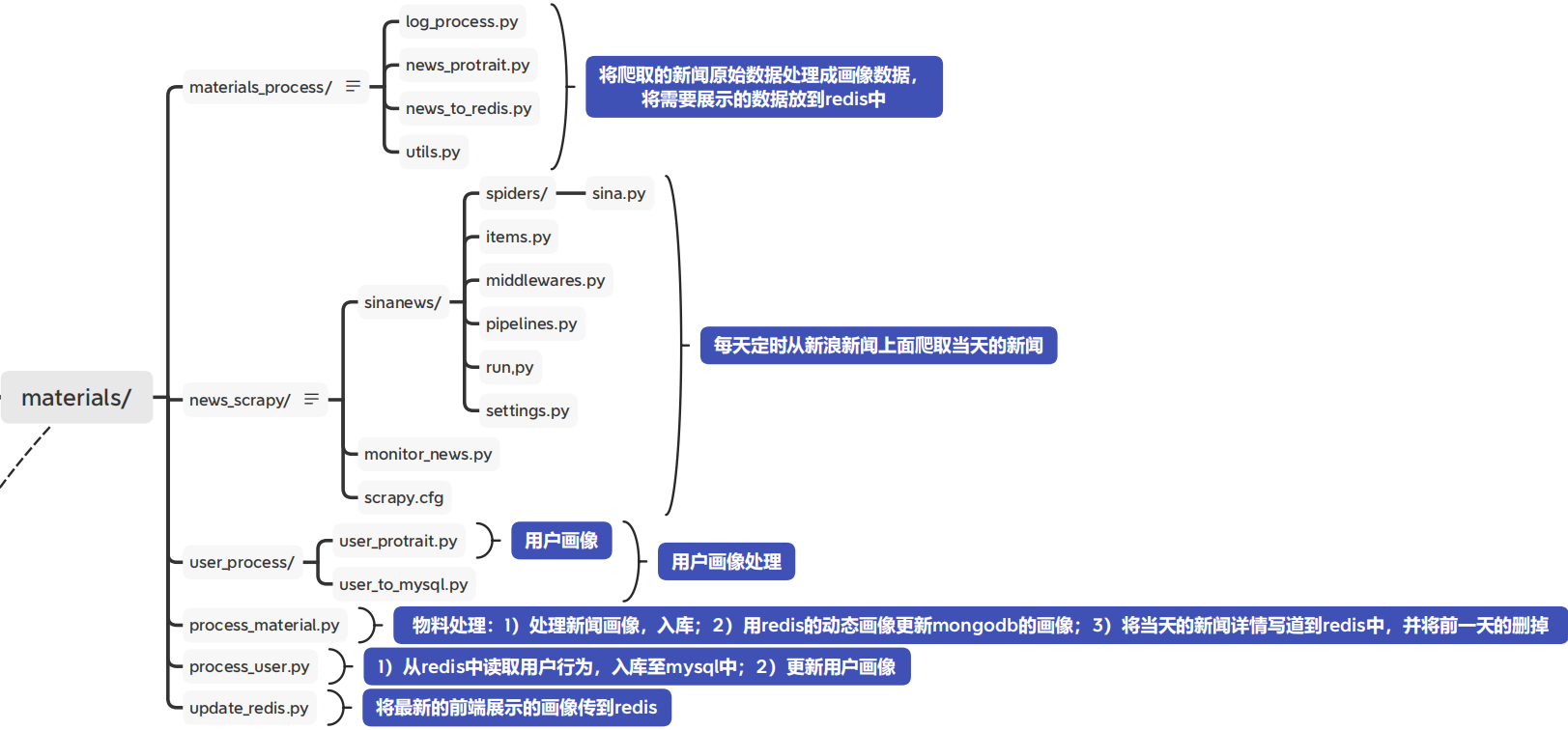
The above describes the user side and material side image construction respectively. The next step is to automate all the above processes and set scheduled tasks. In fact, the most core point is to complete the construction of user and material images before clearing redis data. The following is the whole automated process.
3.1 material update script: process_material.py
from material_process.news_protrait import NewsProtraitServer
from material_process.news_to_redis import NewsRedisServer
def process_material():
"""Material handling function
"""
# Portrait processing
protrail_server = NewsProtraitServer()
# Process the portraits of the latest crawling news and store them in the feature library
protrail_server.update_new_items()
# Updating the news dynamic portrait needs to be performed before the content of redis database is cleared
protrail_server.update_dynamic_feature_protrail()
# Generate a news portrait displayed on the front end and backup it in mongodb
protrail_server.update_redis_mongo_protrail_data()
if __name__ == "__main__":
process_material()
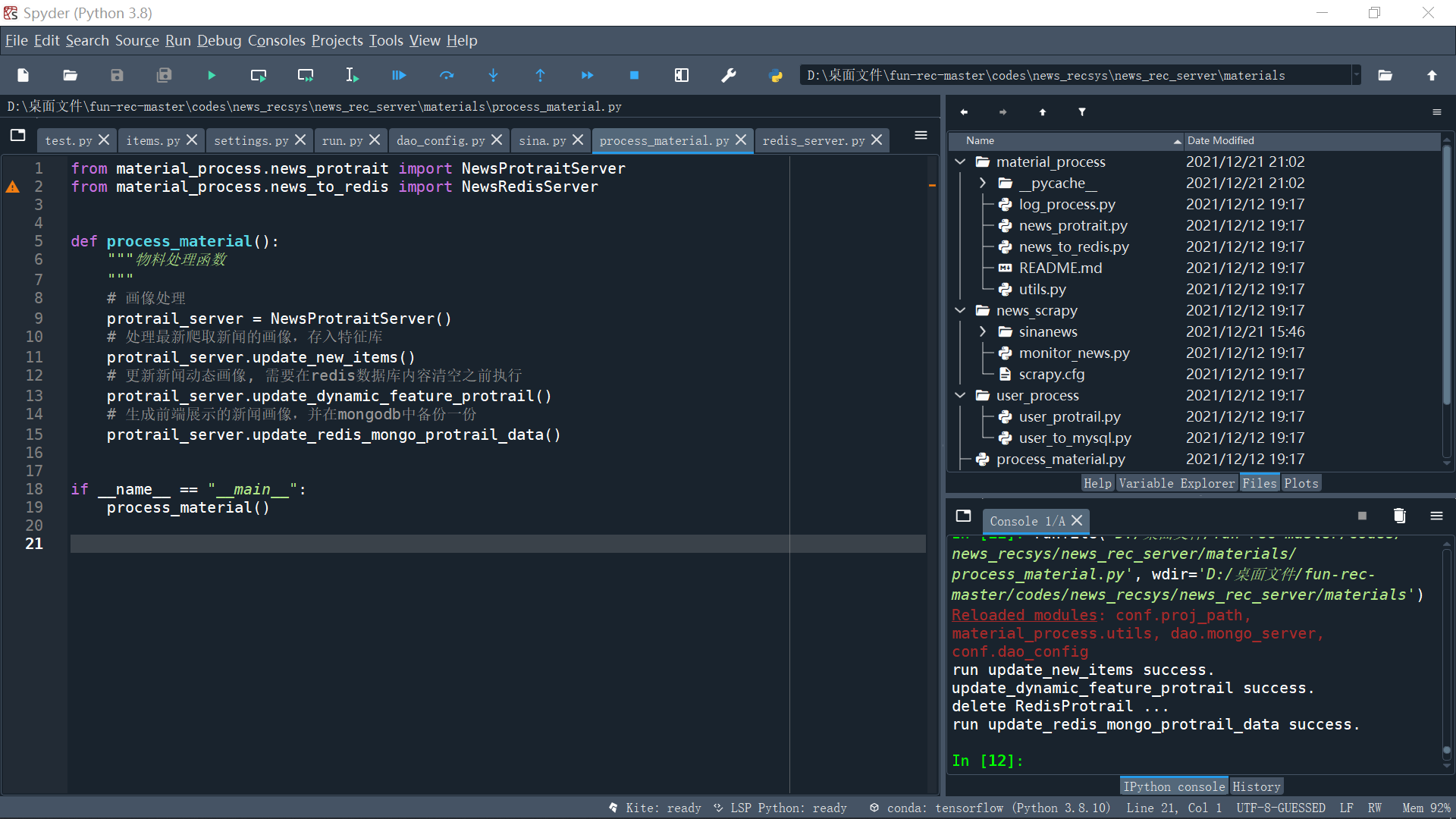
Successfully updated material profile:
run update_new_items success. update_dynamic_feature_protrail success. delete RedisProtrail ... run update_redis_mongo_protrail_data success.
[reminder]
Update the \ fun rec master \ codes \ news in the run_ recsys\news_ rec_ server\materials\process_ material. Py, if redis has a password set, it needs to be in \ fun rec master \ codes \ news_ recsys\news_ rec_ server\dao\redis_ server. Py RedisServer class__ init__ And_ redis_db plus password parameters.
Corresponding Dao_ config. password should also be added to the redis part of py.
3.2 user portrait update script: process_user.py
from user_process.user_to_mysql import UserMysqlServer
from user_process.user_protrail import UserProtrail
"""
1. Convert the user's exposure data from redis Fall mysql Yes.
2. Update user portrait
"""
def process_users():
"""Drop user data Mysql
"""
# User mysql storage
user_mysql_server = UserMysqlServer()
# User exposure data falls into mysql
user_mysql_server.user_exposure_to_mysql()
# Update user portrait
user_protrail = UserProtrail()
user_protrail.update_user_protrail_from_register_table()
if __name__ == "__main__":
process_users()
Note: the userinfo library needs to be built manually, and the table does not need to be built manually (create_all in the code will automatically build the table structure).
PS: if an error is reported: No module named 'sqlalchemy', because it is in news_rec_server\dao\mysql_server.py needs sqlalchemy (which seems to be a component of flash), so you need to download install flash sqlalchemy. You can first test whether sqlalchemy can normally create a table and insert a row of data in the environment (the basic usage of sqlalchemy will be introduced in the [front and back interaction] of the next task).
3.3 redis data update script: update_redis.py
from material_process.news_protrait import NewsProtraitServer
from material_process.news_to_redis import NewsRedisServer
def update():
"""
Material handling function
"""
# The news data is written to redis. Note that when redis data is processed here, all the data of the previous day will be cleared
news_redis_server = NewsRedisServer()
# Send the latest front-end portrait to redis
news_redis_server.news_detail_to_redis()
if __name__ == "__main__":
update()
3.4 shell script: connect the above three scripts in series
Finally, the shell script offline that puts the above three scripts together_ material_ and_ user_ process. sh:
#!/bin/bash
python=/home/recsys/miniconda3/envs/news_rec_py3/bin/python
news_recsys_path="/home/recsys/news_rec_server"
echo "$(date -d today +%Y-%m-%d-%H-%M-%S)"
# In order to handle the path problem more conveniently, you can directly cd to the directory where we want to run
cd ${news_recsys_path}/materials
# Update material portrait
${python} process_material.py
if [ $? -eq 0 ]; then
echo "process_material success."
else
echo "process_material fail."
fi
# Update user portrait
${python} process_user.py
if [ $? -eq 0 ]; then
echo "process_user.py success."
else
echo "process_user.py fail."
fi
# Clear the data in redis of the previous day and update the latest data of today
${python} update_redis.py
if [ $? -eq 0 ]; then
echo "update_redis success."
else
echo "update_redis fail."
fi
echo " "
crontab scheduled tasks:

Disassemble the scheduled task:
0 0 * * * /home/recsys/news_rec_server/scheduler/crawl_news.sh >> /home/recsys/news_rec_server/logs/offline_material_process.log && /home/recsys/news_rec_server/scheduler/offline_material_and_user_process.sh >> /home/recsys/news_rec_server/logs/material_and_user_process.log && /home/recsys/news_rec_server/scheduler/run_offline.sh >> /home/recsys/news_rec_server/logs/offline_rec_list_to_redis.log
The crontab syntax above means that the following scripts are run at 0:00 every day. The & & in the above command means that the contents in front of the symbol are run first and then the following commands are run. Therefore, & & here is to connect the above three tasks in series. The general execution logic is as follows:
- First crawl the news data. It should be noted here that although it is today's zero point crawl data, it is actually the news of the previous day
- After the data is crawled, the user portrait is updated offline, and the material portrait and online portrait are stored in redis
- Finally, it's actually an offline recommendation process. You can save the user's sorted list in redis offline and get it online directly
Reference
(1)datawhale notebook
(2) Notes of leader sharp: https://relph1119.github.io/my-team-learning/#/recommender_system32/task03
(3)Classmate Jun's notes