summary
From today on, we will start a journey of natural language processing (NLP). NLP can let us process, understand and use human language to realize the communication bridge between machine language and human language

key word
Keywords, i.e. key words, can describe the essence of an article and have important applications in document retrieval, automatic summarization, text clustering / classification and so on

Keyword extraction method
- Keyword extraction: for a new document, extract some words in the document as the keyword of the document through algorithm analysis
- Keyword allocation: given the existing key thesaurus, for a new document, several words are allocated from the thesaurus as the keywords of the document
TF-IDF keyword extraction
TF-IDF (term frequency inverse document frequency) is a commonly used weighting technique for information retrieval and data mining. TF-IDF can help us mine keywords in articles. Through numerical statistics, it reflects the importance of a word to an article in the corpus
TF
TF (Term Frequency), i.e. word frequency, indicates the frequency of words in the text
Formula:
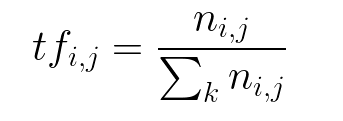
IDF
IDF (Inverse Document Frequency), i.e. inverse document frequency, represents the reciprocal of the number of documents containing words in the corpus
Formula:
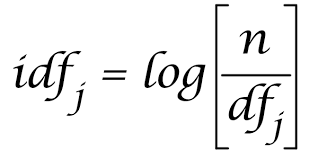
TF-IDF
Formula:
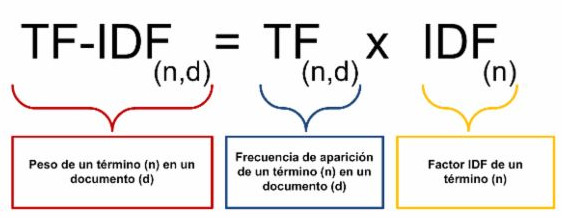
TF-IDF = (frequency of words / total words of sentences) × ( Total documents / documents containing the word)
If a word is very common, the IDF will be very low, otherwise it will be very high. TF-IDF can help us filter common words and extract keywords
Jieba TF IDF keyword extraction
Format:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
Parameters:
- sentence: text corpus to be extracted
- topK: the number of returned keywords. The default value is 20
- withWeight: whether to return keyword weight. The default value is False
- allowPOS: only the words with the specified part of speech are included. It is empty by default, that is, it is not filtered
jieba part of speech
| number | Part of speech | describe |
|---|---|---|
| Ag | Morphological morpheme | Adjective morpheme. The adjective code is a, and the morpheme code G is preceded by A. |
| a | adjective | Take the first letter of the English adjective addictive. |
| ad | Adverbial words | Adjectives that act directly as adverbials. Adjective code a and adverb code d are combined. |
| an | Noun form words | Adjectives with noun function. Adjective code a and noun code n are combined. |
| b | Distinguishing words | Take the initial consonant of the Chinese character "BIE". |
| c | conjunction | Take the first letter of the English conjunction conjunction conjunction. |
| dg | Paramorpheme | Adverbial morpheme. The adverb code is D, and the morpheme code G is preceded by D. |
| d | adverb | Take the second letter of adverb because its first letter has been used as an adjective. |
| e | interjection | Take the first letter of the English exclamation. |
| f | Location word | Take the Chinese character "Fang" |
| g | morpheme | Most morphemes can be used as the "root" of synthetic words and take the initial consonant of Chinese character "root". |
| h | Anterior component | Take the first letter of English head. |
| i | idiom | Take the first letter of the English idiom idiom. |
| j | Abbreviation | Take the initial consonant of the Chinese character "Jian". |
| k | Subsequent component | |
| l | idiom | Idioms have not yet become idioms. They are a little "temporary" and take the initial consonant of "pro". |
| m | numeral | Take the third letter of English numerical, n, u, which has been used by others. |
| Ng | Nominal morpheme | Nominal morpheme. The noun code is N, and the morpheme code G is preceded by N. |
| n | noun | Take the first letter of the English noun noun noun. |
| nr | name | The noun code n is combined with the initials of "Ren". |
| ns | place name | Noun code n is combined with locative code s. |
| nt | Institutional groups | The initial consonant of "Tuan" is t, and the noun codes n and T are combined. |
| nz | Other proper names | The first letter of the initial consonant of "Zhuan" is z, and the noun codes n and z are combined together. |
| o | an onomatopoeia | Take the first letter of the English onomatopoeia. |
| p | preposition | Take the first letter of the English preposition prepositional. |
| q | classifier | Take the first letter of English quantity. |
| r | pronoun | Take the second letter of the English pronoun pronoun because p has been used in the preposition. |
| s | place | Take the first letter of English space. |
| tg | Tense morpheme | Time morpheme. The time word code is T, and T is placed in front of the morpheme code g. |
| t | Time word | Take the first letter of English time. |
| u | auxiliary word | Take the English auxiliary word auxiliary |
| vg | Verb morpheme | Verb morpheme. The verb code is v. Precede the morpheme code g with V. |
| v | verb | Take the first letter of the English verb verb verb verb. |
| vd | coverb | A verb used directly as an adverbial. The codes of verbs and adverbs are combined. |
| vn | Noun verb | A verb that has the function of a noun. The codes of verbs and nouns are combined. |
| w | punctuation | |
| x | Non morpheme words | A non morpheme word is just a symbol. The letter x is usually used to represent unknown numbers and symbols. |
| y | statement label designator | Take the initial consonant of the Chinese character "Yu". |
| z | State word | Take the first letter of the initial consonant of the Chinese character "shape". |
| un | Unknown word |
Without keyword weight
example:
import jieba.analyse
# Define text
text = "Natural language processing is an important direction in the field of computer science and artificial intelligence." \
"It studies various theories and methods that can realize effective communication between human and computer with natural language." \
"Natural language processing is a science integrating linguistics, computer science and mathematics." \
"Therefore, the research in this field will involve natural language, that is, people's daily language," \
"Therefore, it is closely related to the study of linguistics, but there are important differences." \
"Natural language processing is not a general study of natural language," \
"It is to develop a computer system that can effectively realize natural language communication, especially the software system." \
"So it is a part of computer science"
# Extract keywords
keywords = jieba.analyse.extract_tags(text, topK=20, withWeight=False)
# Debug output
print([i for i in keywords])
Output results:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache Loading model cost 0.890 seconds. Prefix dict has been built successfully. ['natural language', 'computer science', 'linguistics', 'Research', 'field', 'handle', 'signal communication', 'Effective', 'software system', 'artificial intelligence', 'realization', 'computer system', 'important', 'one', 'One door', 'daily', 'computer', 'close', 'mathematics', 'development']
With keyword weight
import jieba.analyse
# Define text
content = "Natural language processing is a branch of artificial intelligence and linguistics. This field discusses how to deal with and use natural language; Natural language processing includes many aspects and steps, including cognition, understanding, generation and so on."
# Define text
text = "Natural language processing is an important direction in the field of computer science and artificial intelligence." \
"It studies various theories and methods that can realize effective communication between human and computer with natural language." \
"Natural language processing is a science integrating linguistics, computer science and mathematics." \
"Therefore, the research in this field will involve natural language, that is, people's daily language," \
"Therefore, it is closely related to the study of linguistics, but there are important differences." \
"Natural language processing is not a general study of natural language," \
"It is to develop a computer system that can effectively realize natural language communication, especially the software system." \
"So it is a part of computer science"
# Extract keywords (with weight)
keywords = jieba.analyse.extract_tags(text, topK=20, withWeight=True)
# Debug output
print([i for i in keywords])
Output results:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
Loading model cost 1.110 seconds.
Prefix dict has been built successfully.
[('natural language', 1.1237629576061539), ('computer science', 0.4503481350267692), ('linguistics', 0.27566262244215384), ('Research', 0.2660770221507693), ('field', 0.24979825580353845), ('handle', 0.24973179957046154), ('signal communication', 0.2043557391963077), ('Effective', 0.16296019853692306), ('software system', 0.16102600688461538), ('artificial intelligence', 0.14550809839215384), ('realization', 0.14389939312584615), ('computer system', 0.1402028601413846), ('important', 0.12347581087876922), ('one', 0.11349408224353846), ('One door', 0.11300493477184616), ('daily', 0.10913612756276922), ('computer', 0.1046889912443077), ('close', 0.10181409957492307), ('mathematics', 0.10166677655076924), ('development', 0.09868653898630769)]
TextRank
TextRank builds a network through the adjacent relationship between words, and then uses PageRank to iteratively calculate the rank value of each node. The keywords can be obtained by sorting the rank values
import jieba.analyse
# Define text
content = "Natural language processing is a branch of artificial intelligence and linguistics. This field discusses how to deal with and use natural language; Natural language processing includes many aspects and steps, including cognition, understanding, generation and so on."
# Define text
text = "Natural language processing is an important direction in the field of computer science and artificial intelligence." \
"It studies various theories and methods that can realize effective communication between human and computer with natural language." \
"Natural language processing is a science integrating linguistics, computer science and mathematics." \
"Therefore, the research in this field will involve natural language, that is, people's daily language," \
"Therefore, it is closely related to the study of linguistics, but there are important differences." \
"Natural language processing is not a general study of natural language," \
"It is to develop a computer system that can effectively realize natural language communication, especially the software system." \
"So it is a part of computer science"
# TextRank keyword extraction
keywords = jieba.analyse.textrank(text, topK=20, withWeight=False)
# Debug output
print([i for i in keywords])
Commissioning output:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache ['Research', 'field', 'computer science', 'realization', 'handle', 'linguistics', 'mathematics', 'people', 'computer', 'involve', 'Have', 'one', 'method', 'language', 'development', 'use', 'artificial intelligence', 'lie in', 'contact', 'science'] Loading model cost 1.062 seconds. Prefix dict has been built successfully.
