Recently, I'm learning node.js. It's like playing with something, so this simple reptile is born.
Preparation
- node.js crawler must be installed first node.js Environmental Science
- Create a folder
- Open the command line in the folder and execute the npm init initialization project
Begin formally
Installation dependency
- express is used to build a simple http server, or use the node native api
- cheerio is equivalent to the node version of jQuery, which is used to parse pages
- SUPERGEN is used to request the target page
- Event proxy solves the problem of dealing with multiple pages at the same time
Use NPM install express cheerio super event proxy directly to install dependency packages. Of course, you can use other methods.
Create a directory
node-spider-csdn ├─ .gitignore ├─ node_modules ├─ README.md ├─ index.js Project entry ├─ package-lock.json ├─ package.json └─ routes └─ csdn.js Crawler main code
Create an Http server
In the index.js file, instantiate an express object and start an Http service
const express = require('express');
const app = express();
app.listen(3000, function() {
console.log('running in http://127.0.0.1:3000');
});In this way, a simple Http local service is started. After node index.js is executed, the server can be accessed through http://127.0.0.1:3000. For more information about Express, please refer to Official documents.
Write csdn.js module
First, introduce csdn.js file and add route
const express = require('express');
const csdn = require('./routes/csdn.js');
const app = express();
app.use(csdn);
app.listen(3000, function() {
console.log('running in http://127.0.0.1:3000');
});Then start writing csdn.js
Overall structure
// Introduce the required third-party package
const cheerio = require('cheerio');
const superagent = require('superagent');
const express = require('express');
const eventproxy = require('eventproxy');
const router = express.Router(); // Mount routing
const ep = new eventproxy();
router.get('/csdn/:name', function(req, res) {
const name = req.params.name; // User id
// Specific implementation
});
// Expose router
module.exports = router;Analysis page
After the overall structure is written, we will start to analyze the HTML of CSDN user article page.
Find a blog of any one person and find out through observation:
- Full URL of original article: https://blog.csdn.net/l1028386804/article/list/2? T = 1
- The list of CSDN articles is 40 one page
- Paging controls are dynamically generated, so they cannot be directly obtained through HTML parsing
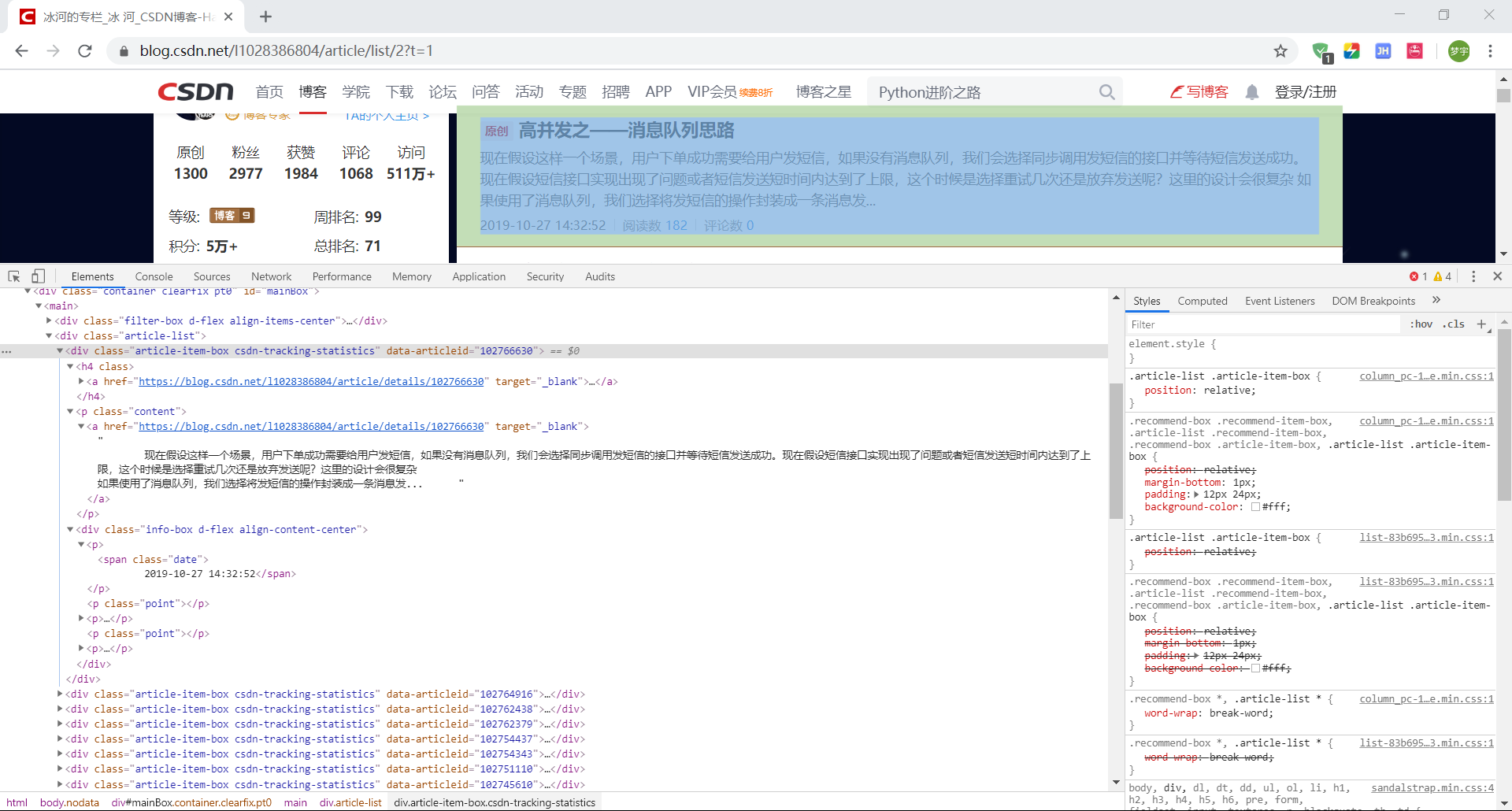
Then we can view the article list structure through the developer tool and find:
- Article information is in the box named article item box
- The id information is in the data articleid attribute of the box
There are also some other information that can be easily found, such as the total value of original articles of bloggers, etc., which can be checked later when necessary.
Get all article pages
Because we can't get paging information directly, we get all pages by the total number of articles / articles per page.
Get the total number of articles first:
/**
* Get total number of articles
* @param {String} url Page path
* @param {Function} callback Callback
*/
let getArticleNum = function (url, callback) {
superagent.get(url).end(function (err, html) {
if (err) {
console.log(`err = ${err}`);
}
let $ = cheerio.load(html.text);
let num = parseInt($('.data-info dl').first().attr('title'));
callback(num);
});
};Then use a simple loop to get all the article pages:
// ...
router.get('/csdn/:name', function(req, res) {
const name = req.params.name;
getArticleNum(`https://blog.csdn.net/${name}`, function (num) {
let pages = []; // Save pages to grab
let pageNum = Math.ceil(num / 40); // Calculate how many pages there are
for (let i = 1; i <= pageNum; i++) {
pages.push(`https://blog.csdn.net/${name}/article/list/${i}?t=1`);
}
// ...
});
});
// ...We can use console.log() or res.send() to check whether the URL obtained is correct
Traverse to get HTML for all pages
// ...
router.get('/csdn/:name', function (req, res) {
const name = req.params.name;
getArticleNum(`https://blog.csdn.net/${name}`, function (num) {
let pages = [];
let articleData = []; // Save all article data
let pageNum = Math.ceil(num / 40); // Calculate how many pages there are
for (let i = 1; i <= pageNum; i++) {
pages.push(`https://blog.csdn.net/${name}/article/list/${i}?t=1`);
}
// Get article information for all pages
pages.forEach(function (targetUrl) {
superagent.get(targetUrl).end(function (err, html) {
if (err) {
console.log(`err ${err}`);
}
let $ = cheerio.load(html.text);
// List of articles on the current page
let articlesHtml = $('.article-list .article-item-box');
// Traverse the list of articles on the current page
for (let i = 0; i < articlesHtml.length; i++) {
// Analyze and get article information
// push to articleData
// ...
}
});
});
});
});
// ...Analyze article information
Because there are too many spaces in some texts, regular expressions are needed to remove the extra spaces.
cheerio's operation on Document is basically the same as jQuery's, so those with front-end foundation can easily get started.
/**
* Parsing html string to get article information
* @param {String} html html with article information
* @param {Number} index Article index
*/
let analysisHtml = function (html, index) {
return {
id: html.eq(index).attr('data-articleid'),
title: html.eq(index).find('h4 a').text().replace(/\s+/g, '').slice(2),
link: html.eq(index).find('a').attr('href'),
abstract: html.eq(index).find('.content a').text().replace(/\s+/g, ''),
shared_time: html.eq(index).find('.info-box .date').text().replace(/\s+/, ''),
read_count: html.eq(index).find('.info-box .read-num .num').first().text().replace(/\s+/, ''),
comment_count: html.eq(index).find('.info-box .read-num .num').last().text().replace(/\s+/, '')
};
};// ...
// Traverse the list of articles on the current page
for (let i = 0; i < articlesHtml.length; i++) {
let article = analysisHtml(articlesHtml, i);
articleData.push(article);
// ...
}
// ...We have obtained the information data of all articles, but because the articles of each page are obtained synchronously and asynchronously, we need to take advantage of these special methods of data at the same time.
Handle concurrent asynchronous operations
I use the "counter" eventproxy here, and there are many other ways to solve this problem.
// ...
pages.forEach(function (targetUrl) {
superagent.get(targetUrl).end(function (err, html) {
if (err) {
console.log(`err ${err}`);
}
let $ = cheerio.load(html.text);
let articlesHtml = $('.article-list .article-item-box');
for (let i = 0; i < articlesHtml.length; i++) {
let article = analysisHtml(articlesHtml, i);
articleData.push(article);
ep.emit('blogArtc', article); // Counter
}
});
});
// When all 'blogartcs' are completed, a callback is triggered
ep.after('blogArtc', num, function (data) {
res.json({
status_code: 0,
data: data
});
});
// ...In this way, a simple node crawler is written. After the node index.js service is started, you can enter http://127.0.0.1:3000/csdn/xxxx in the browser to get all the articles of xxxx (this is id).