1, Questions for each course
Use an SQL statement to query the student table and the names of students with more than 80 points in each course.
Solution 1: having
Idea: if the minimum course score is greater than 80 points, then all his course scores must be greater than 80 points!
code implementation
SELECT name FROM xuesheng GROUP BY name HAVING MIN(score)> 80
Solution 2: not in
You can use reverse thinking, first query the name s with less than 80 points in the table, and then remove them with not in
code implementation
SELECT DISTINCT name
FROM xuesheng
WHERE name NOT IN
(SELECT DISTINCT name
FROM xuesheng
WHERE score <=80);2, topN problem
Case: query the records of the top two in each subject
code implementation
row_number() over( partition by curriculum order by achievement desc) as rank ... where rank <= 2 -- Top two
3, Continuous problems (7-day continuous login)
Realization idea:
Because users may log in more than once a day, you need to reset the user's daily login date first.
Then row_number() over(partition by _ order by _) The function groups the user IDs and sorts them according to the login time.
Calculate the result value obtained by subtracting the login date from the second step. When the user logs in continuously, the subtraction result is the same every time.
Group and sum according to id and date, and filter users greater than or equal to 7, that is, users logged in for 7 consecutive days.
code implementation
SELECT user_id, MAX(count_val) AS max_count -- Found the largest continuous landing, where>=7,That is, 7 consecutive days
FROM (
-- group by Same date
SELECT user_id, symbol_date, COUNT(*) AS count_val
FROM (
-- Date minus rank,If you log in continuously, you will get the same date
SELECT user_id, log_date, date_sub(log_date, CAST(rn AS INT)) AS symbol_date
FROM (
-- start to fight rank identification
SELECT user_id, log_date, ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY log_date) AS rn
FROM user_logging_format
) c
) d
GROUP BY user_id, symbol_date
) e
GROUP BY user_id;4, Row to column problem
Row to column conversion is a classic among the classics, which must be mastered!
6 rows to 2 rows, 2 columns to 3 columns
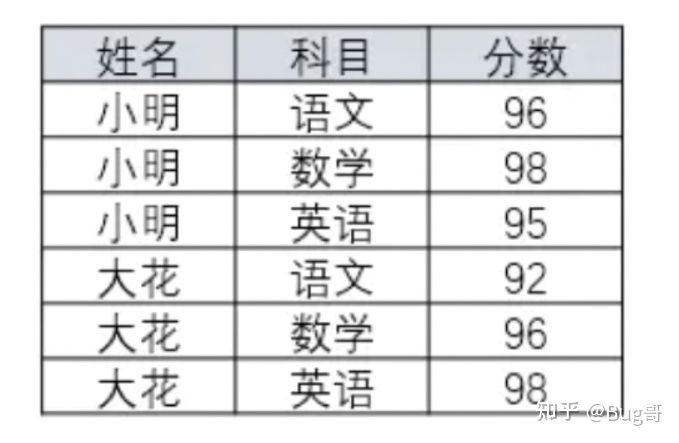

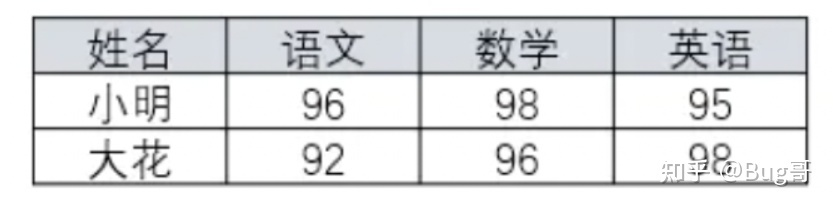
code implementation
SELECT SID, MAX(case CID when '01' then score else 0 end) '01', MAX(case CID when '02' then score else 0 end)'02', MAX(case CID when '03' then score else 0 end)'03' FROM SC GROUP BY SID
5, Retention issues
Retention rate is one of the most important indicators to measure user quality, so calculating user retention rate is one of the skills that users must master in data analysis. It has also become one of the classic interview sql.
In the retention rate index, we usually need to pay attention to the next day's retention, the third day's retention, the seventh day's retention and the month's retention. For new users, we need to pay attention to finer granularity data, that is, the daily retention rate within 7 days.
code implementation
select dd , count( if(id=lead_id and datediff(dd,lead_dd)=1 ,id, null ) ) as '1 Daily retention' , count( if(id=lead_id7 and datediff(dd,lead_dd7)=7 ,id, null ) ) as '7 Daily retention' from ( select id, dd , lead(dd,1) over(partition by id order by dd asc ) as lead_dd , lead(id,1) over(partition by id order by dd asc ) as lead_id , lead(dd,7) over(partition by id order by dd asc ) as lead_dd7 , lead(id,7) over(partition by id order by dd asc ) as lead_id7 from ( select 'slm' as id, '2018-12-26' as dd union all select 'slm' as id, '2018-12-27' as dd union all select 'slm' as id, '2018-12-28' as dd union all select 'hh ' as id, '2018-12-26' as dd union all select 'hh ' as id, '2018-12-28' as dd ) aa
Hard core data: private letter or( Click Get )You can get PDF of industry classic books.
Technical assistance: the leader of the technology group points out the maze. Your problem may not be a problem. Seek resources( Technology Group )Shout inside.
Interview question bank: jointly contributed by P8 bosses, the hot real interview questions of big factories are constantly updated. ( Click Get)
Knowledge system: including programming language, algorithm, big data ecosystem components (Mysql, Hive, Spark, Flink) and data warehouse