The plug-in involves knowledge points: traversing all files in the directory, customizing attribute text format, customizing exception error reporting, converting any string into random number seeds, replacing random results every day, converting text into pictures and sending them
Plug in collection: nonebot2 chat robot plug-in
This series is a nonebot2 related plug-in for QQ group chat robot. It is not guaranteed to fully comply with the writing method of standard specifications. If there are errors and room for improvement, you are welcome to give advice and correction.
Front end: nonebot2
Back end: go cqhttp
Language of plug-in: Python 3
Recommended reference for installation process of front-end environment Zero foundation 2 minutes to teach you to build a QQ robot -- Based on nonebot2 However, please note that the back-end version in this tutorial is too old, which leads to abnormal private chat posting. You need to manually update the go cqhttp version.
1. Purpose of plug-in
Generate persona cards randomly based on the written attribute generation interval.
In order to prevent too many queries, it is limited that the role card generated on the same day of each QQ number is fixed, and the role card will be replaced every day, that is, the QQ number and the date of the day are used as random number seeds at the same time.
Because the plug-in is used to generate the random species role card in the hedgehog cat novel astral consciousness, the plug-in name also comes from the main planet in the novel: haze star, that is, Mist Star.
2. Directory structure
Create a new folder mist in the plugins folder_ Star, the directory structure in the folder is as follows:
|-mist_star
|-racials
|-All dataset files are placed in any folder
|-temp
|-Temporary picture storage location
|-__init__.py
|-mist_star.py
|-config.py
|-read_data.py
|-custom_exceptions.py
Where temp is the folder used to store the sent temporary pictures, racials is the folder used to store the dataset files, and mist_star.py is the location of the main code of the program. config.py is used to store configuration items. read_data.py is used to encapsulate functions for reading data sets and generating role cards, custom_exceptions.py is a custom exception, which is used to detect whether the writing format of the data file is correct__ init__.py is the program start location.
3. Implementation difficulties and Solutions
3.1 traverse all files in the directory
The data files stored in the racials folder are txt text files written in advance, but in order to facilitate retrieval, these files need to be allowed to be placed in multiple files with any file name. At the same time, these files can also be stored in any folder path, as long as they are located in the path of the racials folder.
The code for reading all data files into memory and connecting them is as follows:
# Store data for all files
racial_lines = []
# Read all data files under the folder
for path, dirs, files in os.walk(racial_data_path, topdown=False):
for name in files:
with open(os.path.join(path, name), encoding='utf-8') as data_file:
racial_lines += data_file.readlines()
3.2 custom attribute text format
In order to facilitate the expansion of the data set, a set of syntax of the role card is designed by ourselves. Even those who can't program can participate in the preparation of the document [the workload of the text is really heavy!]. Finally, it is handed over to the reader program to process the data in the memory.
The preparation specifications are as follows:
# with#The first line is skipped as a comment # The use of English symbols: - (), and the use of Chinese symbols will be regarded as the same attribute entry connected together # The first row is the species name, followed by the attribute name, and the races are separated by the END line # Each species can set any non duplicate attribute name and related content # Add a line END at the END of each race as the END sign # Before the colon is the property name, and after the colon is the property value configuration # If there are multiple optional attribute values, as a split, the spaces before and after the attribute values are ignored # In each attribute value, if - is used as the division, it is a continuous value, and an integer in the corresponding interval is randomly generated # Followed by / indicates how much the final value needs to be divided. It is used to generate decimals. Optional. The maximum precision should not exceed five decimal places # The unit contained in () at the end of the attribute value is the unit used by the attribute. Optional # Multiple generation intervals are allowed to exist at the same time. You only need to add units after the last interval!!! # If you want to add an attribute but have only one value, you can write a value directly # It is recommended to leave a blank line at the end of each race # Two species name cards as like as two peas are not allowed to be added. # In order to prevent excessive attribute differences, such as 0-year-old and 2-meter-high, a species can be divided into races at different stages # For example, "Xihai people" are divided into "Xihai people (young)", "Xihai people (adult)" and "Xihai people (old)" # Each race should have the attributes of "intelligent creature" and "description" # The description attribute must be before the last attribute, END, and can be written in multiple lines.
Therefore, the preparation example of species data file is as follows:
# This is a lovely note that is harmless to people and animals Shamian Intelligent creature:no living environment:Shallow sea, beach type:Carbon based scavenger origin:Lanxing times:Marine period,Spark age,Longhunji,Neoproterozoic,Dawn period,Divine grace period,Voyage period,Zhanhuan period,Dome period,Emptiness period Gender:asexual Age:1-20(month) colour:Yellowish brown,Grayish white,wathet,Black and white spots height:5-25/10(centimeter) length:5-30(centimeter) weight:5-30(gram) Physical state:healthy,Chronic hunger,Breeding preparation,Laceration,Bite describe:Shamian is one of the oldest amphibians in the history of Lanxing. They have a flat pastry body. Shamian usually appears in shallow water or beach after ebb tide, looking for small organisms or carcasses as scavengers. Although the nervous system was mentally retarded, Shamian unexpectedly had the most advanced visual nerve center at that time. They have a circle of dimples on the top of their bodies, have basic optical perception, and move very slowly. The original body structure makes Shamian vigorous and can take the initiative to disconnect part of the body for escape. Unfortunately, the relatively comfortable life made this creature almost completely stop evolving in hundreds of millions of years. END # Notes passing quietly again Tidal Limulus Intelligent creature:no living environment:Shallow sea, beach type:Carbon based carnivores origin:Lanxing times:Marine period,Spark age,Longhunji,Neoproterozoic Gender:male,female Age:1-10(month) colour:black,grey,white,brown height:5-15/10(centimeter) length:10-20(centimeter) weight:15-40(gram) Physical state:healthy,Chronic hunger,Breeding preparation,Laceration,be senile,Shell change describe:Tidal Limulus is one of the oldest crustaceans in the history of Lanxing, and it is also one of the oldest amphibians. This creature has an oval shell and crab like sharp pliers. It initially preyed on Shamian as its main food source. The fluff on the side of the body is a keen vibration sensor, which can capture the movement of slight water flow to prey and escape attack. Fierce and aggressive, he was once one of the most ferocious predators on land in the marine period. END
3.3 custom exception error reporting
Before generating the random role card, each time the program is started, when loading the data file, it should first check whether all the data files are written in a legal way. When a problem is found, throw a user-defined exception to help locate the problem, and confirm that all the data are written normally before starting to work.
The custom exceptions used are written in custom_exceptions.py file.
3.4 convert any string to a random number seed
For specific users, we need a scheme that can convert strings of any length into random number seeds. For stability, we use the hash method of md5.
Convert the string to md5 encoding, output it in hexadecimal, and then convert it to hexadecimal number.
Because the seed number input is limited by digits, the last 16 digits are intercepted as the random seed number.
seed_str = input_string
# Convert string to seed
# text to md5
md5_str = md5(seed_str.encode('utf-8'))
# md5 to int
seed_int = int(str(str(int('0x' + md5_str.hexdigest(), 0)))[-16:])
3.5 daily replacement random results
Ensure that the results obtained by each user on the same day are fixed, but different results can be obtained every day.
A simple method is to get the date of the day, and then add it with the user's QQ number to convert it into a random seed number as a string.
from time import localtime, time
# get date
local = localtime(time())
today = f"{local[0]}-{local[1]}-{local[2]}"
# Combine seed strings
seed_str = character_name + today
3.6 converting text into pictures and sending
If many group members frequently query, sending a large number of long text continuously is easy to cause the account to be risk controlled, and it will also have the effect of swiping the screen in the group.
The solution is to convert long text into pictures and save them locally, then send them out, and then delete the local pictures, so as to avoid risk control and screen brushing.
Try to use the pygame library, but find that the line feed operation is troublesome, so finally use the PIL library to convert text to pictures.
The PIL library needs to define the image size. Considering the large text differences, try to calculate the number of lines and the maximum length of a single line, and then realize adaptive image length and width scaling.
Due to the text arrangement characteristics, the scaling adjustment is not perfect, but it can basically meet the use requirements.
The way to convert text to pictures is as follows:
from PIL import Image, ImageFont, ImageDraw
# Convert text to picture save
def text_to_image(text, img_path):
lines = text.splitlines()
# Adaptive adjustment of picture length and width
width = len(max(lines, key=len)) * 20
height = len(lines) * 22
img = Image.new("RGB", (width, height), (255, 255, 255))
dr = ImageDraw.Draw(img)
# Song typeface
font = ImageFont.truetype(os.path.join("fonts", "simsun.ttc"), 18)
dr.text((10, 5), text, font=font, fill="#000000")
# preservation
img.save(img_path)
4. Code implementation
__init__.py
from .mist_star import *
config.py
class Config:
# In which groups are records used
used_in_group = ["131551175"]
# Plug in execution priority
priority = 10
# Robot QQ number
bot_id = "123456789"
# Administrator QQ number, administrator QQ number
super_uid = ["673321342"]
# The call receiving cooling time (seconds), during which two consecutive calls will not be received
cd = 10
custom_exceptions.py
# END exception not found
class NoEndExceptin(Exception):
def __init__(self):
pass
def __str__(self):
print("Error, reached the end of the file, but could not be found END. ")
# Race name duplication exception
class DuplicateRacialExceptin(Exception):
def __init__(self, racial):
self.racial = racial
def __str__(self):
print(f"Malformed attribute rows found\n Race Name:{self.racial}")
# Property name exception
class AttributesExceptin(Exception):
def __init__(self, racial, attr):
self.racial = racial
self.attr = attr
def __str__(self):
print(f"Malformed attribute rows found\n Race Name:{self.racial}\n Properties:{self.attr}")
read_data.py
import random
import time
import copy
from .custom_exceptions import *
# Enter a list of all text lines
# If it is correct, the dictionary is returned. key contains all race names, and value is a list composed of all attribute lines
def create_racial_data(racial_lines):
# A dictionary that records race data
racial_data = {}
# Take out the next race
while len(racial_lines) > 0:
# Take out the first line and remove the spaces and newlines at the beginning and end of the line
racial_name = racial_lines.pop(0).strip()
# If the line is not empty and is not a comment line
if racial_name and not racial_name.startswith('#'):
# If the race name already exists
if racial_name in racial_data:
raise DuplicateRacialExceptin(racial_name)
# Record all attribute lines under the name of the race
racial_attributes = []
# Take out all attribute lines under the name of the race
while True:
if len(racial_lines) == 0:
# Error, END of file reached but END not found
raise NoEndExceptin()
else:
attr_line = racial_lines.pop(0).strip()
# Ignore all comment lines
if attr_line and not attr_line.startswith('#'):
# If it is the end line
if attr_line == 'END':
racial_data[racial_name] = racial_attributes
break
# If it is an attribute line, put it into the attribute list
else:
#print(attr_line, len(attr_line))
attr_parts = attr_line.split(':')
# If it's not a colon line
if len(attr_parts) != 2:
# The colon in the property line is not a
raise AttributesExceptin(racial_name, attr_line)
# If it is a colon line and not a description line
elif attr_parts[0] != "describe":
# Save (attribute name, attribute value condition) into the list
racial_attributes.append((attr_parts[0].strip(), attr_parts[1].strip()))
# If it is a description line
else:
describe = attr_parts[1].strip()
# Take out all description lines until you reach END
while racial_lines[0].strip() != 'END':
describe_line = racial_lines.pop(0).strip()
if describe_line and not describe_line.startswith('#'):
describe += '\n' + describe_line
racial_attributes.append((attr_parts[0].strip(), describe))
# All lines of the file are processed, and each race has the correct termination flag
return racial_data
# Generate random attribute values
# Input the data dictionary to generate a random value for each attribute
# Check whether the generation is successful. If an exception is found, report the specific location of the error
# Duplicate attribute, wrong data type
# If it is correct, a string is returned. The string is the integration information
def create_new_role(seed, racial_data):
# Fixed random number seed
random.seed(seed)
# Deep copy to prevent changes to original data
racial_data = copy.deepcopy(racial_data)
# Randomly obtain a species name and the corresponding attribute list
racial, attributes = random.sample(racial_data.items(), k=1)[0]
# For each attribute
for i in range(len(attributes)):
att_name = attributes[i][0]
att_vals = attributes[i][1]
# If you want to find out whether a company exists
# Are there any extra parentheses
if att_vals.count('(') > 1 or att_vals.count(')') > 1:
# There are extra parentheses
raise AttributesExceptin(racial, attributes[i])
# If there is no unit
if att_vals[-1] != ')':
unit = ''
else:
try:
start_index = att_vals.index('(')
except:
# There is no corresponding left parenthesis
raise AttributesExceptin(racial, attributes[i])
unit = att_vals[start_index+1:-1]
att_vals = att_vals[:start_index]
# Randomly select an attribute generation interval
attribute_range = random.choice(att_vals.split(','))
attribute_range = attribute_range.strip()
# If this is not an interval but a single attribute value, assign the attribute value directly to the attribute
if '-' not in attribute_range:
attributes[i] = (att_name, attribute_range, unit)
# If random number generation is required
else:
# Check whether divisor is required
temp_count = attribute_range.count('/')
if temp_count == 0:
div_val = 1
elif temp_count == 1:
div_val = attribute_range[attribute_range.index('/')+1:]
try:
div_val = int(div_val)
except:
# Incorrect divisor
raise AttributesExceptin(racial, attributes[i])
# Check whether the start and stop intervals are normal
start, end = attribute_range.split('/')[0].split('-')
try:
start, end = int(start), int(end)
random_att = random.randint(start, end)
if div_val != 1:
random_att = random_att / div_val
except:
# Random number interval anomaly
raise AttributesExceptin(racial, attributes[i])
attributes[i] = (att_name, random_att, unit)
# At this time, all values in attributes are (attribute name, random attribute value, attribute unit)
# print(racial, attributes)
# Start assembling string
final_str = "Race Name:"+racial+"\n"
for attribute in attributes:
final_str += f"{attribute[0]}: {attribute[1]}{attribute[2]}\n"
return final_str
# Test function
# Conduct attribute generation test for each race one by one, and report any abnormality
# It should be run once after each database creation to detect exceptions. Each attribute interval needs to be detected
def check_all_data(racial_data):
# Deep copy to prevent changes to original data
racial_data = copy.deepcopy(racial_data)
# Detect each species name and the corresponding attribute list
for racial, attributes in racial_data.items():
# For each attribute
for i in range(len(attributes)):
att_name = attributes[i][0]
att_vals = attributes[i][1]
# If you want to find out whether a company exists
# Are there any extra parentheses
if att_vals.count('(') > 1 or att_vals.count(')') > 1:
# There are extra parentheses
raise AttributesExceptin(racial, attributes[i])
# If there is no unit
if att_vals[-1] != ')':
unit = ''
else:
try:
start_index = att_vals.index('(')
except:
# There is no corresponding left parenthesis
raise AttributesExceptin(racial, attributes[i])
unit = att_vals[start_index + 1:-1]
att_vals = att_vals[:start_index]
# Detect each attribute generation interval
for attribute_range in att_vals.split(','):
attribute_range = attribute_range.strip()
# If this is not an interval but a single attribute value, assign the attribute value directly to the attribute
if '-' not in attribute_range:
attributes[i] = (att_name, attribute_range, unit)
# If random number generation is required
else:
# Check whether divisor is required
temp_count = attribute_range.count('/')
if temp_count == 0:
div_val = 1
elif temp_count == 1:
div_val = attribute_range[attribute_range.index('/') + 1:]
try:
div_val = int(div_val)
except:
# Incorrect divisor
raise AttributesExceptin(racial, attributes[i])
# Check whether the start and stop intervals are normal
start, end = attribute_range.split('/')[0].split('-')
try:
start, end = int(start), int(end)
random_att = random.randint(start, end)
if div_val != 1:
random_att = random_att / div_val
except:
# Random number interval anomaly
raise AttributesExceptin(racial, attributes[i])
attributes[i] = (att_name, random_att, unit)
# Pass the inspection
return "All data format detection is completed."
mist_star.py
from nonebot import on_message, on_command
from nonebot.typing import T_State
from nonebot.adapters import Bot, Event
from nonebot.permission import SUPERUSER
from nonebot.adapters.cqhttp import MessageSegment
import re
import os
from .config import Config
import json
from random import randint
from .read_data import *
import os
from hashlib import md5
from time import localtime
from time import time
from PIL import Image, ImageFont, ImageDraw
# Record last response time
last_response = {}
# Judge whether the function responding to cd has passed. The cd in the configuration file is used by default
# Returns True if the minimum response interval has been exceeded
def cool_down(group_id, cd = Config.cd):
global last_response
if group_id not in last_response:
return True
else:
return time() - last_response[group_id] > cd
# Temporary picture storage path
temp_img_path = dir_path = os.path.split(os.path.realpath(__file__))[0] + '/temp/temp.png'
# Species data storage path
racial_data_path = dir_path = os.path.split(os.path.realpath(__file__))[0] + '/racials'
# Store data for all files
racial_lines = []
# Read all data files under the folder
for path, dirs, files in os.walk(racial_data_path, topdown=False):
for name in files:
with open(os.path.join(path, name), encoding='utf-8') as data_file:
racial_lines += data_file.readlines()
# Convert text to picture save
def text_to_image(text, img_path):
lines = text.splitlines()
# Adaptive adjustment of picture length and width
width = len(max(lines, key=len)) * 20
height = len(lines) * 22
img = Image.new("RGB", (width, height), (255, 255, 255))
dr = ImageDraw.Draw(img)
# Song typeface
font = ImageFont.truetype(os.path.join("fonts", "simsun.ttc"), 18)
dr.text((10, 5), text, font=font, fill="#000000")
# preservation
img.save(img_path)
# Create dataset
racial_data = create_racial_data(racial_lines)
# Check whether all species attribute formats are legal
check = check_all_data(racial_data)
# Create racial role cards
def get_role(character_name):
# get date
local = localtime(time())
today = f"{local[0]}-{local[1]}-{local[2]}"
# Combine seed strings
seed_str = character_name + today
# Convert string to seed
# text to md5
md5_str = md5(seed_str.encode('utf-8'))
# md5 to int
seed_int = int(str(str(int('0x' + md5_str.hexdigest(), 0)))[-16:])
# Generate random role cards
new_role = create_new_role(seed_int, racial_data)
# Return to role card
return character_name + "\n" + new_role
# Create random astral characters
mist_star_role = on_command("Astral character", priority=Config.priority)
@mist_star_role.handle()
async def handle_first_receive(bot: Bot, event: Event, state: T_State):
ids = event.get_session_id()
allow_use = True
# If this is a group chat message
if ids.startswith("group"):
_, group_id, user_id = event.get_session_id().split("_")
if group_id not in Config.used_in_group:
allow_use = False
else:
user_id = ids
group_id = 'private_'+ids
# If allowed
if allow_use:
# If the cooling down time has passed, or if the user is an administrator
if cool_down(group_id) or user_id in Config.super_uid:
infos = str(await bot.get_stranger_info(user_id=user_id))
nickname = json.loads(infos.replace("'", '"'))['nickname']
response = nickname + get_role('(' + str(user_id) + ')')
warning = f"Warning: this function is in the testing stage. At present, there is only ethnic minority data.\n Dialogue cooling cd by{Config.cd}Seconds.\n The random results are changed every day, and the results of the day are fixed (unless the original data set changes).\n\n"
response = warning + response
text_to_image(response, temp_img_path)
if user_id not in Config.super_uid:
last_response[group_id] = time()
await mist_star_role.send(MessageSegment.image('file:///' + temp_img_path))
# Delete pictures from temporary folders
os.remove(temp_img_path)
5. Plug in diagram
The plug-in has no attached drawing
6. Actual effect

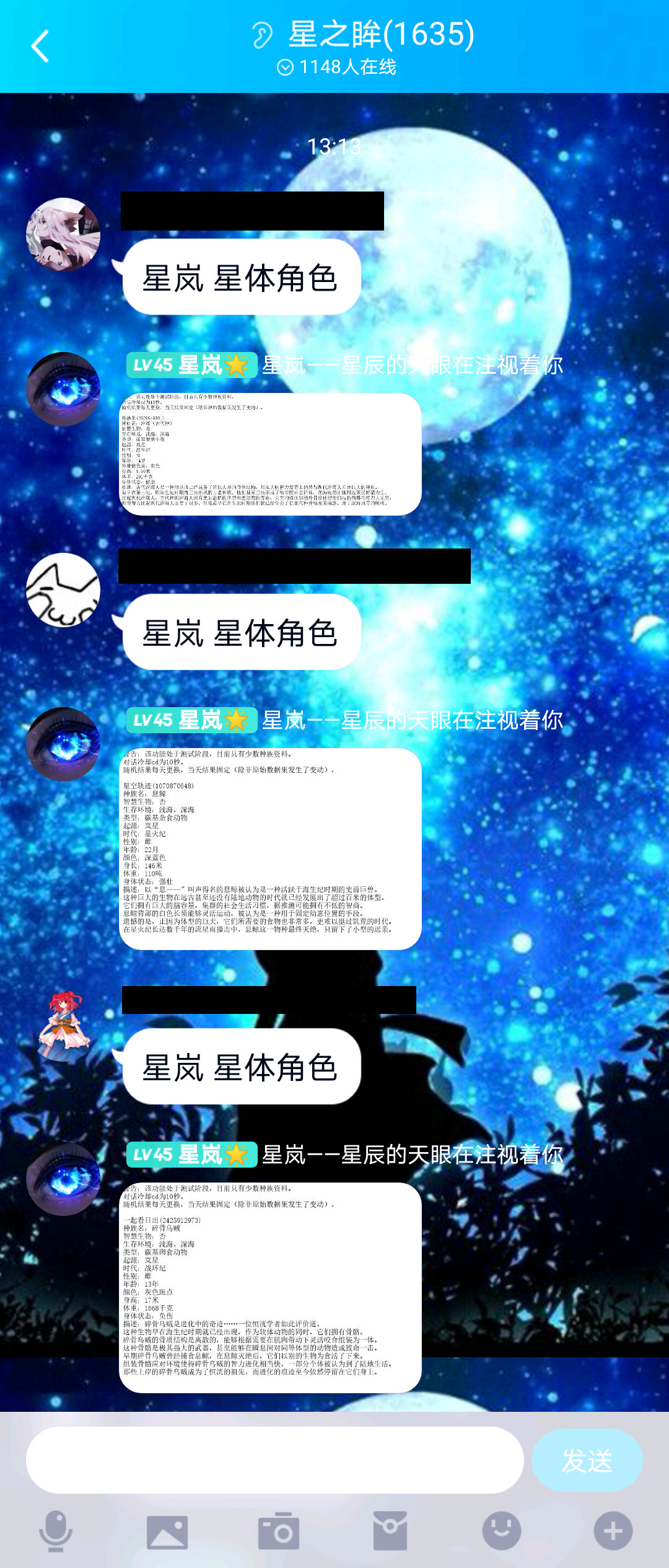
7. Next plug-in
GAN based daily random planet image generation (blog post not completed)