@[TOC] (non negative matrix factorization practice)
1. Application Overview
NMF can be applied in a wide range of fields because it has a good explanation of the local characteristics of things.
- In many applications, NMF can be used to discover image features in database, which is convenient for rapid and automatic recognition;
- It can discover the semantic relevance of documents for automatic information indexing and extraction;
- Be able to identify genes in DNA array analysis, etc.
Among them, the most effective is the field of image processing, which is an effective method of data dimensionality reduction and feature extraction in image processing.
1.1 feature learning
It is similar to Principal Component Analysis, but it is better than PCA in actual engineering environment. The idea is as follows:
- Test data are learned on NMF algorithm V t r a i n → d i c t i o n a r y W V_{train} \rightarrow dictionaryW Vtrain→dictionaryW
- Use the base matrix W to decompose the new test example
V
n
V_n
Vn:
v n ≈ ∑ n = 1 K h k n w k , his in k n > = 0 v_n\approx \sum_{n=1}^{K}h_{kn}w_k. Where k_ n>=0 vn ≈ n=1 Σ K hkn wk, where kn > = 0 - hold
h
n
h_n
hn is the eigenvector of example n.
For example, the following is the result of NMF feature learning on human face:

1.2 image analysis
One of the most successful applications of NMF is in the field of image analysis and processing. The image itself contains a large amount of data. The computer generally stores the image information in the form of matrix. The image recognition, analysis and processing are also carried out on the basis of matrix. These characteristics make NMF method well combined with image analysis and processing.
- NMF algorithm has been used to process the images sent back by satellites to automatically identify garbage fragments in space;
- NMF algorithm is used to analyze the images taken by astronomical telescopes, which is helpful for astronomers to identify stars;
- The United States has also tried to install a recognition system driven by NMF algorithm at the airport to automatically identify suspicious terrorists entering and leaving the airport according to the characteristic image database of terrorists input into the computer in advance.
In academia:
(1) NMF was first used by Professor Lee for face recognition.
(2) LNMF was proposed by Professor Song later to extract human face subspace, project the face image on the feature space, and obtain the projection coefficient as the feature vector of face recognition for face recognition. The recognition rate is improved to a certain extent.
(3) GNMF was proposed by Professor Yang. The algorithm constructs the feature subspace based on the NMF of gamma distribution, and uses the minimum distance classification to recognize some images of ORL face database.
For face recognition, LNMF is the most effective and prominent, which is more efficient and accurate than ordinary NMF.
1.3 topic identification
Text occupies a large part in the information that human beings contact daily. In order to obtain the required information from a large number of text data faster and more accurately, the research on text information processing has not stopped. Text data is not only informative, but also generally unstructured. In addition, typical text data is usually processed by computer in the form of matrix. At this time, the data matrix has the characteristics of high-dimensional sparse. Therefore, another obstacle to the processing and analysis of large-scale text information is how to reduce the dimension of the original data. NMF algorithm is a new way to solve this problem.
NMF has successful application examples in mining user required data and text clustering research. Due to the high efficiency of NMF algorithm in processing text data, the famous commercial database software Oracle specially uses NMF algorithm to extract and classify text features in its 10th edition.
Why does NMF extract text information well? The reason is that the core problem of intelligent text processing is to represent the text in a way that can capture semantic or related information, but the traditional common analysis method is only to count words without considering other information. Unlike NMF, it can often achieve the effect of representing the correlation between parts of information, so as to obtain better processing results.
The Topic of Topic recognition is similar to probabilistic late semantic analysis:
- First assume V = [ v f n ] V=[v_{fn}] V=[vfn] is a word text matrix, v f n v_{fn} vfn is a word m f m_f mf in text d n d_n Frequency of occurrence of dn.
- hypothesis
w
f
k
=
P
(
t
k
)
P
(
m
f
∣
t
k
)
w_{fk}=P(t_k)P(m_f|t_k)
wfk = P(tk) P(mf ∣ tk) and
h
k
n
=
P
(
d
n
∣
t
k
)
h_{kn}=P(d_n|t_k)
hkn = P(dn ∣ tk), then the model can be written as:
[ P ( m f , d n ) ] = [ v f n ] = W H [P(m_f,d_n)]=[v_{fn}]=WH [P(mf,dn)]=[vfn]=WH
here, w k w_k wk , can be interpreted as related to data h k h_k Topic relevance of hk #

1.4 voice processing
Automatic speech recognition has always been the direction of computer scientists, and it is also the basic technology of intelligent application in the future. Speech also contains a large amount of data information. The process of speech recognition is also the process of processing these information.
NMF algorithm also provides us with a new method in this regard. In the existing applications, NMF algorithm successfully realizes effective speech feature extraction, and because of the rapidity of NMF algorithm, it is of great significance to realize the real-time speech recognition of the machine. There are also applications of music analysis using NMF method. The recognition of polyphonic music is a very difficult problem. Mitsubishi Research Institute and MIT (Massachusetts Institute of Technology) scientists cooperate to use NMF to recognize each tone from the polyphonic music playing and record them separately. The experimental results show that this method using NMF algorithm is not only simple, but also does not need to be based on knowledge base.
Example of local feature data generated by NMF processing audio:
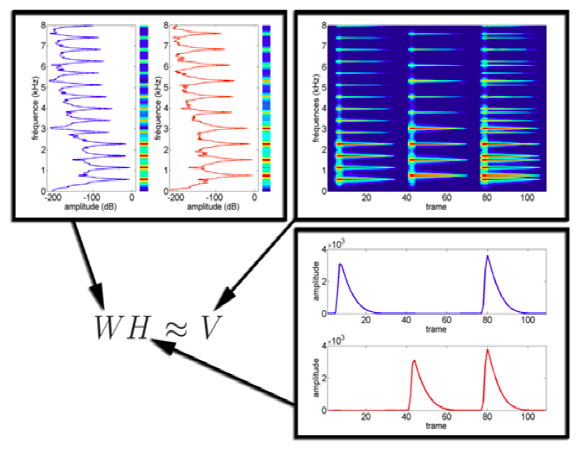
1.5 temporal segmentation
hidden markov models HMM is used to process time series data, such as audio and video:

NMF can segment file sequence data into different interest topics through threshold setting. The following is an example of mining movie clip structure:
 Similarly, based on the idea of temporal segmentation, there is such a speech processing project to segment the speech features of a paragraph spoken by many people and identify which person said each paragraph:
Similarly, based on the idea of temporal segmentation, there is such a speech processing project to segment the speech features of a paragraph spoken by many people and identify which person said each paragraph:

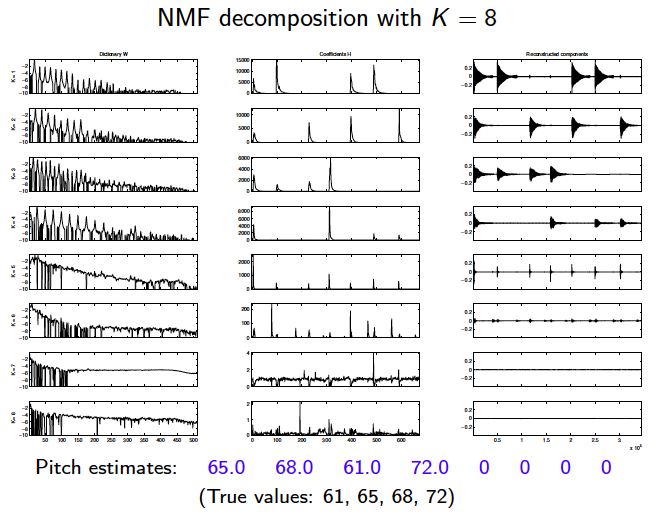
1.6 clustering
The most commonly used clustering method is K-means, commonly known as k-means algorithm. NMF algorithm is better than k-means algorithm because it is a soft clustering method (that is, an element can be divided into multiple types, not K-means, or that). NMF is simple and efficient for clustering methods that may be repeated.
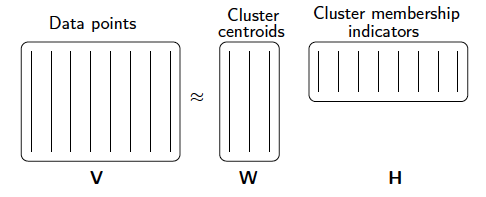
1.7 robot control
How to make the robot recognize the surrounding objects quickly and accurately is of great significance for robot research, because it is the basis for the robot to respond and act quickly. The robot obtains the image information of the surrounding environment through the sensor, which is also stored in the form of matrix. Some researchers have used NMF algorithm to realize the robot's rapid recognition of surrounding objects. According to the existing research data, the recognition accuracy has reached more than 80%.
1.8 biomedical engineering and chemical engineering
In biomedical and chemical research, it is often necessary to analyze and process the experimental data with the help of computers. Often some complicated data will consume too much energy of researchers. NMF algorithm also provides a new efficient and fast way for the processing of these data.
- Scientists use NMF method to process dynamic continuous images of electron emission process in nuclear medicine, and effectively extract the required features from these dynamic images.
- NMF can also be applied to genetics and drug discovery. Because there is no negative value in the decomposition of NMF, using NMF to analyze the molecular sequence of gene DNA can make the analysis results more reliable.
- Similarly, using NMF to select drug components can also obtain the most effective and least negative new drugs.
1.9 filtering and source separation
Refer to independent component analysis (ICA):
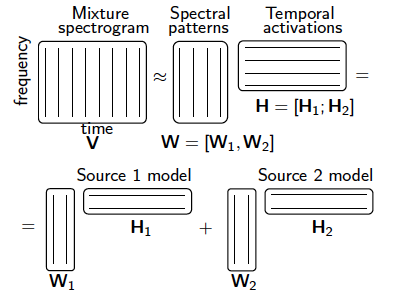
In the filtering, one SCI uses an example, that is, action recognition using depth contours, NMF algorithm as the feature learning algorithm. Finally, the paper uses the bone feature, PCA algorithm and NMF algorithm of Microsoft open source Kinect to compare the contour feature learning. It is found that the accuracy of NMF is the highest 91%, while the bone feature recognition of Microsoft open source is only 78%.
Application case of NMF in film recommendation system
There are two collections: users and movies. Give each user's score on some movies, and hope to predict the user's score on other movies he hasn't seen, so that he can make recommendations according to the score. The relationship between users and movies can be represented by a matrix. Each column represents users, each row represents movies, and the value of each element represents the user's rating of movies that have been seen.
Related packages: from sklearn decomposition import NMF
The following is a brief introduction to the NMF based recommendation algorithm:
data
The name of the movie, using 10 movies:
# Movie list
item = ['Avatar', 'Unforgiven', 'Leon: The Professional', 'The Hurt Locker', 'Back to the Future',
'The Dark Knight', 'Brave heart', 'The Notebook', 'Princess Bride', 'The Iron Giant']
Name of the user, using 15 users:
# User list
user = ['Rose', 'Lily', 'Daisy', 'Bond', 'Mask',
'Poppy', 'Violet', 'Kong', 'Oli', 'Daffodil',
'Camellia', 'Rust', 'Rosemary', 'Aron', 'Chen']
User's scoring matrix:
# User rating matrix
RATE_MATRIX = np.array(
[[5, 5, 3, 0, 5, 5, 4, 3, 2, 1, 4, 1, 3, 4, 5],
[5, 0, 4, 0, 4, 4, 3, 2, 1, 2, 4, 4, 3, 4, 0],
[0, 3, 0, 5, 4, 5, 0, 4, 4, 5, 3, 0, 0, 0, 0],
[5, 4, 3, 3, 5, 5, 0, 1, 1, 3, 4, 5, 0, 2, 4],
[5, 4, 3, 3, 5, 5, 3, 3, 3, 4, 5, 0, 5, 2, 4],
[5, 4, 2, 2, 0, 5, 3, 3, 3, 4, 4, 4, 5, 2, 5],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0],
[5, 4, 3, 3, 2, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 2, 2],
[5, 4, 3, 3, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1]]
)
NMF decomposition matrix of users and movies, where nmf_model is the NMF class, user_dis is the W matrix, item_dis is the H matrix and R is set to 2:
# NMF decomposition of users and movies, where nmf_model is the NMF class, user_dis is the W matrix, item_dis is the H matrix and R is set to 2:
nmf_model = NMF(n_components=2, init='nndsvd') # There are 2 themes
item_dis = nmf_model.fit_transform(RATE_MATRIX)
user_dis = nmf_model.components_
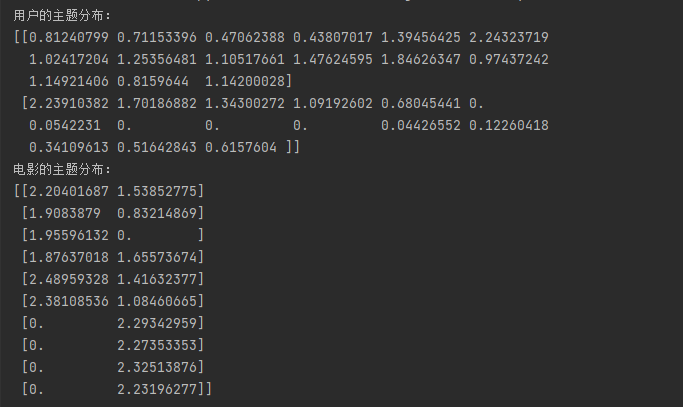
print('Topic distribution of users:')
print(user_dis)
print('Theme distribution of the film:')
print(item_dis)
 The movie theme distribution matrix and user distribution matrix can be drawn:
The movie theme distribution matrix and user distribution matrix can be drawn:
# Draw the movie theme distribution matrix and user distribution matrix
plt1 = plt
plt1.plot(item_dis[:, 0], item_dis[:, 1], 'ro')
plt1.draw() # Directly draw the matrix and only dot it. Next, make some settings for figure plt1
plt1.xlim((-1, 3))
plt1.ylim((-1, 3))
plt1.title(u'the distribution of items (NMF)') # Set the title of the diagram
count = 1
zipitem = zip(item, item_dis) # Link the movie title with the movie coordinates
for item in zipitem:
item_name = item[0]
data = item[1]
plt1.text(data[0], data[1], item_name,
fontproperties='SimHei',
horizontalalignment='center',
verticalalignment='top')
plt1.show()
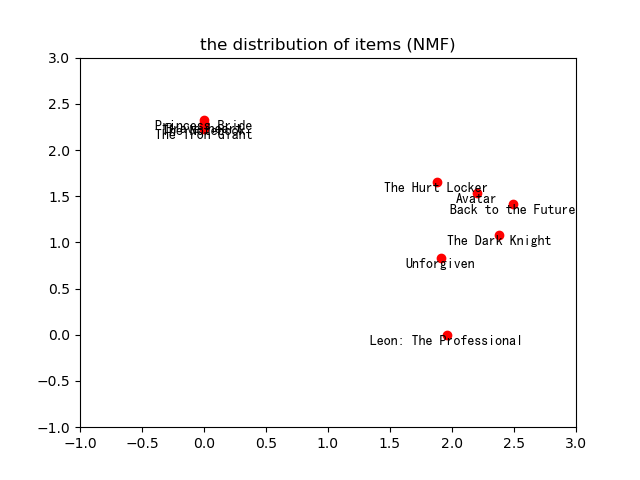
It can be seen from the above figure that the movie theme is divided. Movies can be divided into two categories by using KNN or other distance measurement algorithms, that is, n set according to the previous NMF matrix decomposition_ Components = 2. Back to this n_ The value of components is interpreted.
Let's look at the topic division of users:
# Subject division of users
user_dis = user_dis.T # Transpose the user distribution matrix
plt2 = plt
plt2.plot(user_dis[:, 0], user_dis[:, 1], 'ro')
plt2.xlim((-1, 3))
plt2.ylim((-1, 3))
plt2.title(u'the distribution of user (NMF)') # Set the title of the diagram
zip_user = zip(user, user_dis) # Link the movie title with the movie coordinates
for user in zip_user:
user_name = user[0]
data = user[1]
plt2.text(data[0], data[1], user_name,
fontproperties='SimHei',
horizontalalignment='center',
verticalalignment='top')
# Directly draw the matrix, only dot, and set figure plt2 below
plt2.show()
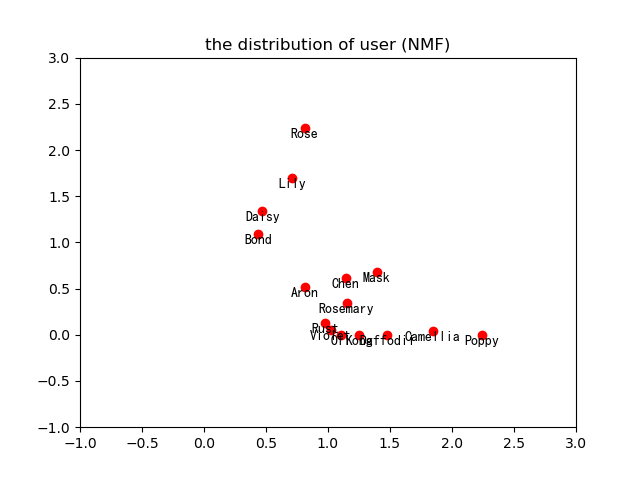
As can be seen from the above figure, users' Rose ',' Lily ',' Daisy 'and' Bond 'have similar distance metric similarity, and the other 11 users have similar distance metric similarity.
recommend
The NMF recommendation is simple, and the specific process is as follows:
- Find out the movie that the user does not score, because 8 decimal places are reserved in the numpy matrix to judge whether it is zero. Use 1e-8 (it is convenient to adjust the parameters later). Of course, if it is not so rigorous, you can use = 0.
- The new matrix of filtering score is obtained, and the user feature matrix decomposed by NMF and the movie feature matrix are dot multiplied.
- Find out the list of movies that the user does not score and arrange it according to the size, which is the movie ID to be recommended to the user.
filter_matrix = RATE_MATRIX < 1e-8
rec_mat = np.dot(item_dis, user_dis)
print('Rebuild the matrix and filter out the items that have been scored:')
rec_filter_mat = (filter_matrix * rec_mat).T
print(rec_filter_mat)
# Users who need to be recommended
rec_user = 'Camellia'
# Recommended user ID
rec_userid = user.index(rec_user)
# Recommended user's movie list
rec_list = rec_filter_mat[rec_userid, :]
print('Recommended user movies:')
print(np.nonzero(rec_list))
The results are as follows:
Rebuild the matrix and filter out the items that have been scored:
[[0. 0. 1.5890386 0. 0. 0.
0. 0. 0. 0. ]
[0. 2.7740907 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 0.92052211 0. 0. 0.
0. 0. 0. 0. ]
[2.64547255 1.74465262 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 4.0586019
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 2.0032409 2.01150506 0. 0.
0.12435687 0.12327804 0.12607624 0.12102394]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0. 0. 0. 0. ]
[0. 0. 0. 0. 0. 0.
0.10151985 0.10063914 0.10292348 0.09879899]
[0. 0. 1.90583476 0. 2.59943825 0.
0.28118406 0.27874473 0.28507174 0.27364798]
[0. 0. 2.24781825 2.72111639 0. 0.
0. 0. 0.79309584 0.76131387]
[0. 0. 1.59599481 0. 0. 0.
0. 1.17411736 0. 0. ]
[0. 2.69178372 2.23370837 0. 0. 0.
1.41220313 0. 0. 0. ]]
Recommended user movies:
(array([6, 7, 8, 9], dtype=int64),)
It can be seen from the above results that the movies recommended to the user 'Camellia' can include 'The Dark Knight', 'brake heart', 'The Notebook', 'Princess Bride'.
error
View the error after decomposition:
a = NMF(n_components=2) # There are 2 themes W = a.fit_transform(RATE_MATRIX) H = a.components_ print(a.reconstruction_err_) b = NMF(n_components=3) # There are 3 themes W = b.fit_transform(RATE_MATRIX) H = b.components_ print(b.reconstruction_err_) c = NMF(n_components=4) # There are 4 themes W = c.fit_transform(RATE_MATRIX) H = c.components_ print(c.reconstruction_err_) d = NMF(n_components=5) # There are 5 themes W = d.fit_transform(RATE_MATRIX) H = d.components_ print(d.reconstruction_err_)
The above errors are
13.823891101850649 10.478754611794432 8.223787135382624 6.120880939704367
It is necessary to tolerate errors in matrix decomposition, but for the number of errors, we don't think the errors calculated by NMF are too obsessed. What's more, it depends on how many topics you set. Obviously, the more topics, the closer to the original matrix, the less error, so first determine the business requirements, and then define the number of topics that should be clustered.
summary
Although NMF is used to implement the recommendation algorithm above, according to the CTO of Netfix, NMF is rarely used for recommendation, and SVD is used more. The recommended algorithms for matrix decomposition are SVD, ALS and NMF. For which is better and for the text recommendation system, it is important to understand the internal meaning of various methods.
In addition, the differences of SVD, ALS and NMF algorithms in practical engineering application are supplemented.
- Use SVD for some explicit data (such as the user's score on item)
- For implicit data, use ALS (such as purchase history, purchase history, watching habits, browsing interest and browsing activity active records, etc.)
- NMF is used for clustering and feature extraction of clustering results.
In the above practice, clustering is used to extract the features of different users and items. The features can be regarded as the similarity of recommendations, so they can be used as recommendation algorithms. However, this is not recommended because the accuracy and recall of NMF are not significant compared with SVD.
reference material
- https://blog.csdn.net/qq_26225295/article/details/51211529
- https://blog.csdn.net/qq_26225295/article/details/51165858