stypora-copy-images-to: img
typora-root-url: ./
Spark Day07: Spark SQL

01 - [understand] - yesterday's course content review
It mainly explains two aspects: Spark scheduling kernel and spark SQL fast experience.
1,Spark Kernel scheduling
explain Spark How does the framework apply to 1 Job The job is scheduled for execution, and 1 Job How to split into Task Task, put Executor Execute on.
[Take the classic case of big data: word frequency statistics WordCount]
- each Job yes RDD Action Function trigger, such as foreachPartition,saveAsTextFile,count wait
- Preliminary knowledge:
RDD Dependency, wide dependency (1 pair) N,Also known as Shuffle Dependence) and narrow dependence (1 to 1)
DAG Figure, each Job Trigger by Job implement RDD,Backtracking method is used to deduce the whole Job All in RDD And dependencies, building DAG chart
Stage Stage, using backtracking method, from back to front, according to RDD If it is a wide dependency, divide one Stage
each Stage All of them are a group Task task
RDD 1 partition data in 1 Task Processing, 1 Task Run 1 Core CPU And run as a thread
Stage Each Task Task to pipeline Pipeline calculation mode processing data
- comprehensive Job dispatch
- DAGScheduler,take DAG The figure is divided into Stage,according to RDD The dependency is wide
Stage Level scheduling
- TaskScheduler,Will each Stage in Task Package tasks as TaskSet Send queue, waiting Executor function Task
Task Level scheduling
2,SparkSQL Quick experience
- SparkSession Program entry
from Spark 2.0 Provide classes, load data, or SparkContext
spark.read.textFile("datas/wordcount.data")
DataFrame and Dataset = RDD + Schema(Field name and field type)
- Achieve word frequency statistics WordCount
- be based on DSL programming
Encapsulate data into DataFrame or Dataset,call API realization
val resultDS: DataFrame = inputDS
// Hadoop spark - > split words and flatten them
.select(explode(split(trim($"value"), "\\s+")).as("word"))
.groupBy("word").count()
- be based on SQL programming
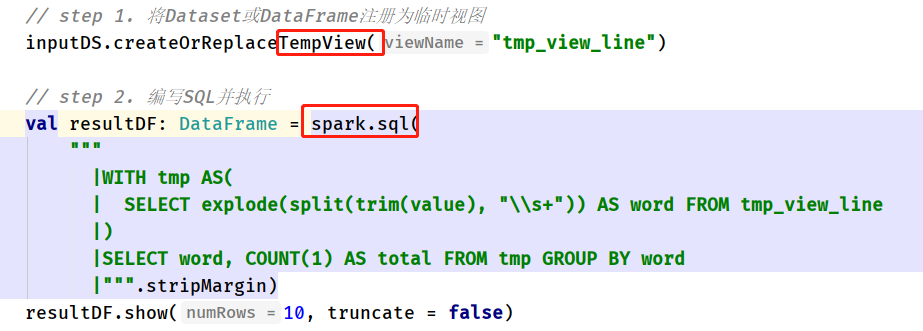
Encapsulate data into DataFrame or Dataset,Register as a temporary view, write SQL analysis
inputDS.createOrReplaceTempView("tmp_view_line")
val resultDF: DataFrame = spark.sql(
"""
|WITH tmp AS(
| SELECT explode(split(trim(value), "\\s+")) AS word FROM tmp_view_line
|)
|SELECT word, COUNT(1) AS total FROM tmp GROUP BY word
|""".stripMargin)
resultDF.show(10, truncate = false)
02 - [understand] - outline of today's course content
There are two main aspects: what is DataFrame and data analysis (case explanation)
1,DataFrame What is it? SparkSQL Module past and present lives, official definitions and features DataFrame What is it? DataFrame = RDD[Row] + Schema,Row Represents each row of data, abstract, and does not know each row Row How many columns of data, weak type Case demonstration, spark-shell command line Row Represents how to obtain the value of each column for each row of data RDD How to convert to DataFrame - Reflection inference - custom Schema call toDF Functions, creating DataFrame 2,Data analysis (case explanation) to write DSL,call DataFrame API(similar RDD Functions in, such as flatMap And similar SQL Keyword functions in, such as select) to write SQL sentence register DataFrame Is a temporary view to write SQL Statement, similar Hive in SQL sentence Use function: org.apache.spark.sql.functions._ Analysis of film scoring data Use separately DSL and SQL
03 - [understand] - SparkSQL overview of past and present lives
The SparkSQL module is not really stable until spark version 2.0. It plays its great function. Its development has gone through the following stages.
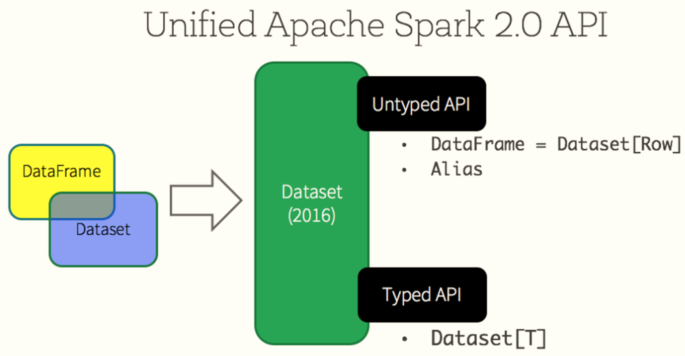
1,Spark 1.0 before Shark = Hive + Spark take Hive Framework source code, modify the transformation SQL by MapReduce,Change to conversion RDD Operation, called Shark Question: The maintenance cost is too high and there is no more energy to improve the performance of the framework 2,Spark 1.0 Start proposing SparkSQL modular Rewrite engine Catalyst,take SQL Resolve to optimized logical plan Logical Plan Data structure: SchemaRDD The test development version cannot be used in the production environment 3,Spark 1.3 edition, SparkSQL become Release edition data structure DataFrame,Reference and Python and R in dataframe Provide external data source interface Easy to load from any external data source load And save save data 4,Spark 1.6 edition, SparkSQL data structure Dataset It is circulated in the market for reference Flink in DataSet From data structure Dataset = RDD + schema 5,Spark 2.0 edition, DataFrame and Dataset What is one Dataset = RDD + schema DataFrame = Dataset[Row]
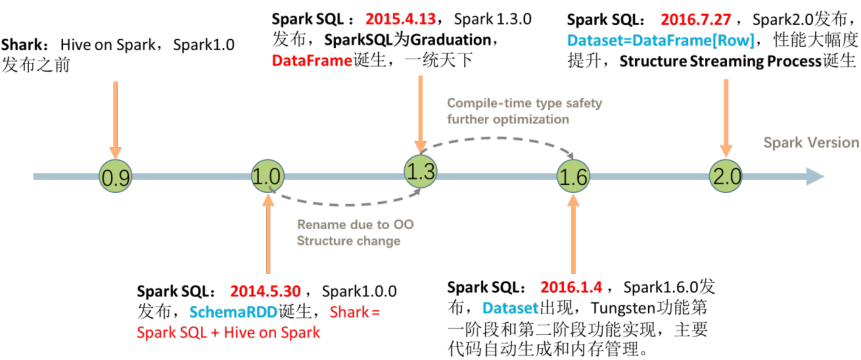
Spark 2. When x is published, Dataset and DataFrame are unified into a set of API s, mainly based on Dataset data structure (Dataset= RDD + Schema), where DataFrame = Dataset[Row].
04 - [understand] - official definitions and features of SparkSQL overview
Official definition of SparkSQL module: Spark Module for structured data processing.

It mainly includes three meanings:
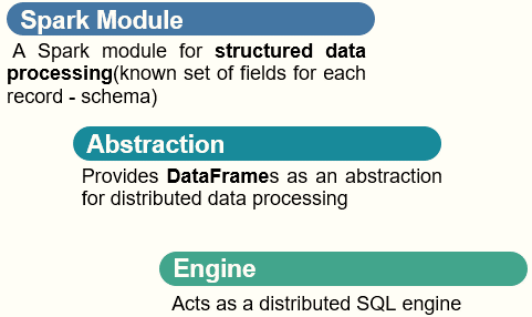
- First, for structured data processing, it belongs to Spark framework
- Second, abstract data structure: DataFrame
DataFrame = RDD[Row] + Schema Information;
- Third, distributed SQL Engine, similar to Hive framework
Inherited from Hive framework, Hive provides bin/hive interactive SQL command line and HiveServer2 services, and SparkSQL can be used;
The architecture diagram of Spark SQL module is as follows:
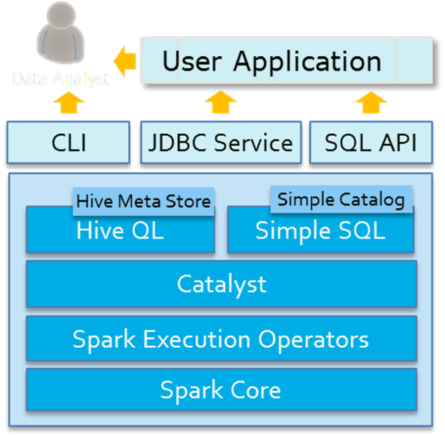
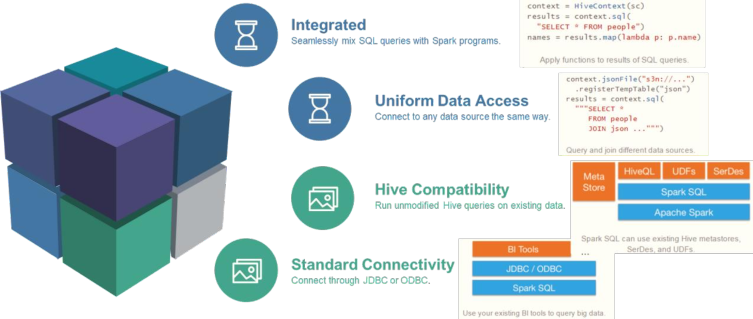
Spark SQL is a module used by spark to process structured data. It has four main features:
Official documents: http://spark.apache.org/docs/2.4.5/sql-distributed-sql-engine.html
05 - [Master] - what is DataFrame and case demonstration
In Spark, DataFrame is a distributed data set based on RDD, which is similar to two-dimensional tables in traditional databases.
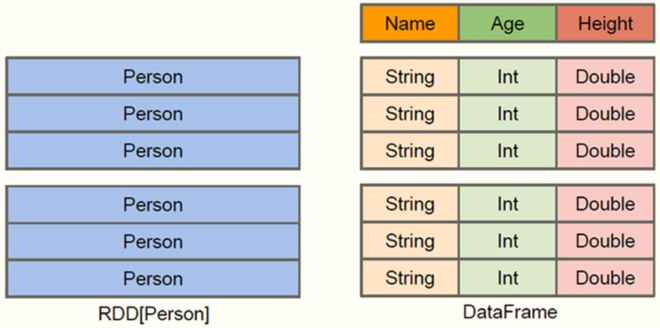
Spark SQL can gain insight into more structural information, so as to optimize the data sources hidden behind the DataFrame and the transformations acting on the DataFrame, and finally greatly improve the runtime efficiency

DataFrame has the following features:

Example demonstration: loading json format data
[root@node1 spark]# bin/spark-shell --master local[2]
21/04/26 09:26:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619400386041).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val empDF = spark.read.json("/datas/resources/employees.json")
empDF: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
scala> empDF.printSchema()
root
|-- name: string (nullable = true)
|-- salary: long (nullable = true)
scala>
scala> empDF.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
scala>
scala> empDF.rdd
res2: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[12] at rdd at <console>:26
Therefore, it can be seen that DataFrame = RDD[Row] + Schema information
06 - [Master] - Schema and Row in DataFrame
To view the Schema in the DataFrame, execute the following command:
scala> empDF.schema

You can find the Schema encapsulation class: StructType, structured type. The encapsulated type of each field stored in it: StructField, structured field.
- First, the StructType definition is a sample class with an array of StructField attributes

- Second, the StructField definition is also a sample class with four attributes, of which the field name and type are required

Customize the Schema structure, and provide the official example code:

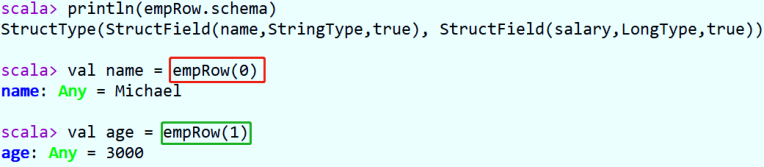
Each data in the DataFrame is encapsulated in a row. Row represents each row of data, which field positions are specific, and the first data in the DataFrame is obtained.

How to get the value of each field in Row????
- Method 1: subscript acquisition, starting from 0, similar to array subscript acquisition
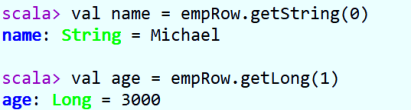
- Method 2: specify the subscript and know the type
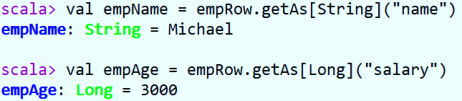
- Method 3: convert types through As, which is most used in development
How to create a Row object??? Either pass value or Seq

07 - [Master] - reflection type inference of RDD conversion DataFrame
In actual project development, it is often necessary to convert RDD data sets into dataframes. In essence, it is to add Schema information to RDD. There are two official methods: type inference and user-defined Schema.
file: http://spark.apache.org/docs/2.4.5/sql-getting-started.html#interoperating-with-rdds

Example demonstration: use the classic data set [movie scoring data u.data], first read it as RDD, and then convert it into DataFrame.
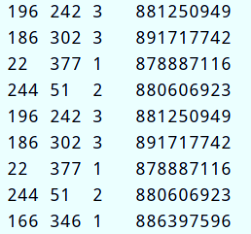
Field information: user id , item id, rating , timestamp.
When the data type CaseClass in RDD is a sample class, get the attribute name and type through reflection, build a Schema, apply it to the RDD dataset, and convert it to DataFrame.
package cn.itcast.spark.convert
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* RDD is converted into DataFrame and Dataset by reflection
*/
object _01SparkRDDInferring {
def main(args: Array[String]): Unit = {
// Build the SparkSession instance object and set the application name and master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. Load movie scoring data and encapsulate the data structure RDD
val rawRatingRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data")
// 2. Convert RDD data type to movierrating
/*
Encapsulate each row of data (movie scoring data) in the original RDD into the CaseClass sample class
*/
val ratingRDD: RDD[MovieRating] = rawRatingRDD.mapPartitions { iter =>
iter.map { line =>
// Split by tab
val arr: Array[String] = line.trim.split("\\t")
// Encapsulate sample objects
MovieRating(
arr(0), arr(1), arr(2).toDouble, arr(3).toLong
)
}
}
// 3. Directly convert CaseClass type RDD to DataFrame through implicit conversion
val ratingDF: DataFrame = ratingRDD.toDF()
//ratingDF.printSchema()
//ratingDF.show(10, truncate = false)
/*
Dataset From spark1 6 proposed
Dataset = RDD + Schema
DataFrame = RDD[Row] + Schema
Dataset[Row] = DataFrame
*/
// To convert a DataFrame to a Dataset, you only need to add the CaseClass strong type
val ratingDS: Dataset[MovieRating] = ratingDF.as[MovieRating]
ratingDS.printSchema()
ratingDS.show(10, truncate = false)
// TODO: RDD can be converted to Dataset by implicit conversion. The RDD data type must be CaseClass
val dataset: Dataset[MovieRating] = ratingRDD.toDS()
dataset.printSchema()
dataset.show(10, truncate = false)
// Convert Dataset directly to DataFrame
val dataframe = dataset.toDF()
dataframe.printSchema()
dataframe.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}
08 - [Master] - RDD transforms the custom Schema of DataFrame
Customize the Schema according to the data in RDD. The type is StructType. The constraints of each field are defined by StructField. The specific steps are as follows:

package cn.itcast.spark.convert
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, LongType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* Convert RDD to DataFrame in custom Schema mode
*/
object _02SparkRDDSchema {
def main(args: Array[String]): Unit = {
// Build the SparkSession instance object and set the application name and master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. Load movie scoring data and encapsulate the data structure RDD
val rawRatingsRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data", minPartitions = 2)
// 2. TODO: step1. The data type in RDD is Row: RDD[Row]
val rowRDD: RDD[Row] = rawRatingsRDD.mapPartitions { iter =>
iter.map {
line =>
// Split by tab
val arr: Array[String] = line.trim.split("\\t")
// Encapsulate sample objects
Row(arr(0), arr(1), arr(2).toDouble, arr(3).toLong)
}
}
// 3. TODO: step2. Define Schema: StructType for data in Row
val schema: StructType = StructType(
Array(
StructField("user_id", StringType, nullable = true),
StructField("movie_id", StringType, nullable = true),
StructField("rating", DoubleType, nullable = true),
StructField("timestamp", LongType, nullable = true)
)
)
// 4. TODO: step3. Use the method in SparkSession to apply the defined Schema to RDD[Row]
val ratingDF: DataFrame = spark.createDataFrame(rowRDD, schema)
ratingDF.printSchema()
ratingDF.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}
09 - [Master] - toDF function specifies that the column name is converted to DataFrame
SparkSQL provides a function: toDF, which converts RDD or Seq with data type of tuple into DataFrame by specifying column name. It is also often used in practical development.

Example demonstration: convert RDD or Seq whose data type is tuple directly to DataFrame.
package cn.itcast.spark.todf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* Implicitly call the toDF function to convert Seq and RDD sets with tuple data type into DataFrame
*/
object _03SparkSQLToDF {
def main(args: Array[String]): Unit = {
// Build the SparkSession instance object and set the application name and master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. Convert RDD whose data type is tuple to DataFrame
val rdd: RDD[(Int, String, String)] = spark.sparkContext.parallelize(
List((1001, "zhangsan", "male"), (1003, "lisi", "male"), (1003, "xiaohong", "female"))
)
// Call the toDF method, specify the column name, and convert the RDD to DataFrame
val dataframe: DataFrame = rdd.toDF("id", "name", "gender")
dataframe.printSchema()
dataframe.show(10, truncate = false)
println("==========================================================")
// Define a Seq sequence in which the data type is tuple
val seq: Seq[(Int, String, String)] = Seq(
(1001, "zhangsan", "male"), (1003, "lisi", "male"), (1003, "xiaohong", "female")
)
// Converts a Seq sequence whose data type is tuple to DataFrame
val df: DataFrame = seq.toDF("id", "name", "gender")
df.printSchema()
df.show(10, truncate = false)
// After application, close the resource
spark.stop()
}
}
10 - [understand] - data processing in SparkSQL
In the SparkSQL module, after the structured data is encapsulated into the DataFrame or Dataset set, two methods are provided to analyze and process the data, as in the previous case [word frequency statistics WordCount]:
- First: DSL (domain specific language) programming
- Call DataFrame/Dataset API (function), similar to the function in RDD;
- In DSL programming, calling functions are more like SQL sentence keyword functions, such as select and groupBy, and use function processing at the same time.

Data analysts, especially those using Python
- Second: SQL programming
- Register DataFrame/Dataset as a temporary view or table, and write SQL statements, similar to HiveQL;
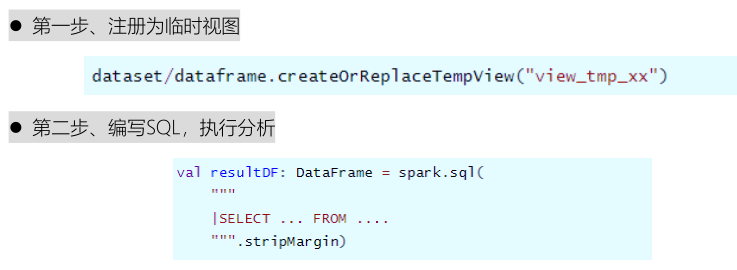
- There are two steps: first register the DataFrame as a temporary view, and then write SQL
In particular, DBA and data warehouse analysts are good at writing SQL statements and using SQL programming
11 - [Master] - based on DSL analysis (function description) and SQL analysis
- DSL based analysis
- Call the API (function) in DataFrame/Dataset to analyze the data, where the function includes the conversion function in RDD and similar SQL
Statement function, some screenshots are as follows:
- Call the API (function) in DataFrame/Dataset to analyze the data, where the function includes the conversion function in RDD and similar SQL

- SQL based analysis
- Register Dataset/DataFrame as a temporary view, write SQL, and perform analysis in two steps:
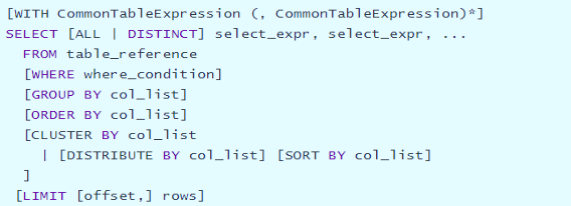
The SQL statement is similar to the SQL statement in Hive. View Hive's official documents, SQL query and analysis statement syntax, and official documents:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
12 - [Master] - demand description and loading data of film scoring data analysis
Use movie scoring data for data analysis, use DSL programming and SQL programming respectively, and be familiar with data processing functions and SQL usage. Business requirements description:
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-6ypUaVpL-1627176341890)(/img/image-20210426105132291.png)]
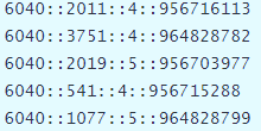
data set ratings.dat There are 1 million pieces of data in total. The data format is as follows. Each row of data is separated from each field by double colons:
The data processing and analysis steps are as follows:

Save the analysis results to MySQL database table and CSV text file respectively.
First, load the movie scoring data and package it into RDD
// Building a SparkSession instance object
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.getOrCreate()
// Import implicit conversion
import spark.implicits._
// TODO: step1. Read movie scoring data, read from the local file system, and package the data into RDD
val ratingRDD: RDD[String] = spark.read.textFile("datas/ml-1m/ratings.dat").rdd
println(s"Count = ${ratingRDD.count()}")
println(s"first:\n\t${ratingRDD.first()}")
13 - [Master] - ETL of film scoring data analysis
Read the movie scoring data, convert it into DataFrame, define the Schema information by using the specified column name, and use the toDF function. The code is as follows:
val ratingDF: DataFrame = ratingRDD
.filter(line => null != line && line.trim.split("::").length == 4)
.mapPartitions{iter =>
iter.map{line =>
// a. Parse each data
val arr = line.trim.split("::")
// b. Building tuple objects
(arr(0).toInt, arr(1).toInt, arr(2).toDouble, arr(3).toLong)
}
}
// c. Call the toDF function to specify the column name
.toDF("user_id", "item_id", "rating", "timestamp")
ratingDF.printSchema()
ratingDF.show(10, truncate = false)
println(s"count = ${ratingDF.count()}")
Convert RDD to DataFrame dataset to facilitate data analysis using DSL or SQL.
14 - [Master] - SQL analysis of film scoring data analysis
First register the DataFrame as a temporary view, then write SQL statements, and finally execute it using SparkSession. The code is as follows:;
// TODO: step3. SQL based analysis
/*
a. Register as temporary view
b. Write SQL and perform analysis
*/
// a. Register DataFrame as a temporary view
ratingDF.createOrReplaceTempView("view_temp_ratings")
// b. Write SQL and perform analysis
val top10MovieDF: DataFrame = spark.sql(
"""
|SELECT
| item_id, ROUND(AVG(rating), 2) AS avg_rating, COUNT(1) AS cnt_rating
|FROM
| view_temp_ratings
|GROUP BY
| item_id
|HAVING
| cnt_rating >= 2000
|ORDER BY
| avg_rating DESC
|LIMIT
| 10
|""".stripMargin)
/*
root
|-- item_id: integer (nullable = false)
|-- avg_rating: double (nullable = true)
|-- count_rating: long (nullable = false)
*/
top10MovieDF.printSchema()
/*
+--------+----------+------------+
|movie_id|avg_rating|count_rating|
+--------+----------+------------+
|318 |4.55 |2227 |
|858 |4.52 |2223 |
|527 |4.51 |2304 |
|1198 |4.48 |2514 |
|260 |4.45 |2991 |
|2762 |4.41 |2459 |
|593 |4.35 |2578 |
|2028 |4.34 |2653 |
|2858 |4.32 |3428 |
|2571 |4.32 |2590 |
+--------+----------+------------+
*/
top10MovieDF.show(10, truncate = false)
15 - [Master] - number of Shuffle partitions for film scoring data analysis
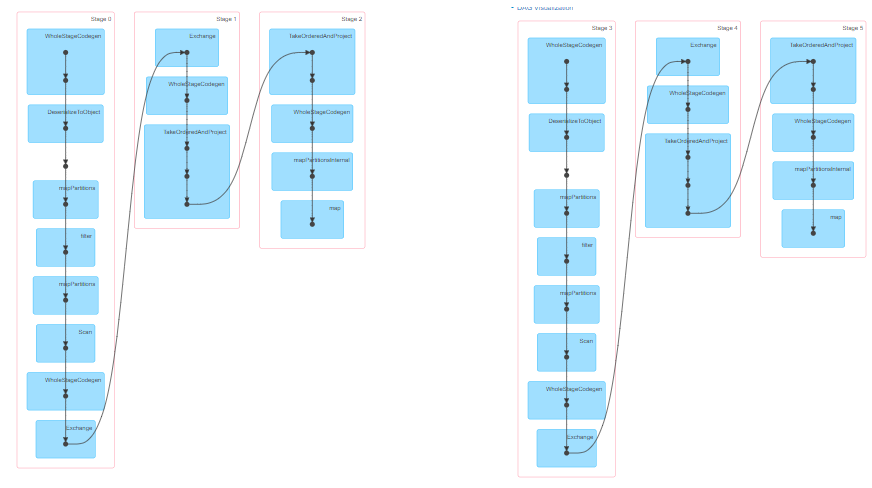
When running the above program, check the WEB UI monitoring page and find that there are 200 tasks in a Stage, that is, there are 200 partitions in RDD.

Reason: in SparkSQL, when shuffles are generated in the Job, the default number of partitions (spark.sql.shuffle.partitions) is 200, which should be set reasonably in the actual project. When building a SparkSession instance object, set the value of the parameter
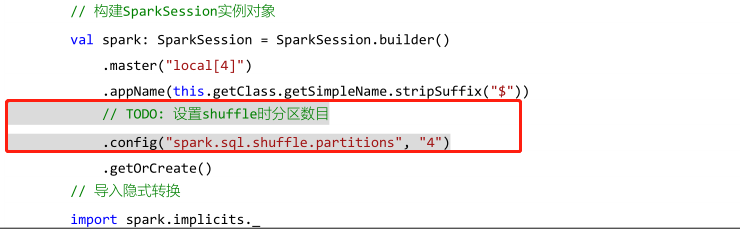
Good news: in spark3 Starting from 0, do not care about the parameter value. The program automatically sets the number of partitions reasonably according to the amount of data in Shuffle.
16 - [Master] - DSL analysis of film scoring data analysis
Call the function in the Dataset and analyze the data by chain programming. The core code is as follows:
val resultDF: DataFrame = ratingDF
// a. Group by movie ID
.groupBy($"item_id")
// b. Aggregate the combined data, the average score and the number of scores
.agg(
round(avg($"rating"), 2).as("avg_rating"), //
count($"user_id").as("cnt_rating")
)
// c. Filtering score times greater than 2000
.filter($"cnt_rating" > 2000)
// d. Sort in descending order according to the average score
.orderBy($"avg_rating".desc)
// e. Get the first 10 data
.limit(10)
resultDF.printSchema()
resultDF.show(10, truncate = false)
Use the import function library: import org apache. spark. sql. functions._
Using DSL programming analysis and SQL programming analysis, which method has better performance? How to choose in actual development???
17 - [Master] - save the results of film scoring data analysis to MySQL
Keep the analysis data in the MySQL table, directly call the writer method in the Dataframe and write the data to the MySQL table
// TODO: step 4. Save the analysis result data to an external storage system, such as a MySQL database table or a CSV file
resultDF.persist(StorageLevel.MEMORY_AND_DISK)
// Save the result data to MySQL table
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
resultDF
.coalesce(1) // Consider reducing the number of partitions for the result data
.write
.mode(SaveMode.Overwrite)
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", //
"db_test.tb_top10_movies", //
props
)
/*
mysql> select * from tb_top10_movies ;
+---------+------------+------------+
| item_id | avg_rating | cnt_rating |
+---------+------------+------------+
| 318 | 4.55 | 2227 |
| 858 | 4.52 | 2223 |
| 527 | 4.51 | 2304 |
| 1198 | 4.48 | 2514 |
| 260 | 4.45 | 2991 |
| 2762 | 4.41 | 2459 |
| 593 | 4.35 | 2578 |
| 2028 | 4.34 | 2653 |
| 2858 | 4.32 | 3428 |
| 2571 | 4.32 | 2590 |
+---------+------------+------------+
*/
// Save the result data to the CSv file
// Free resources when data is not in use
resultDF.unpersist()
18 - [Master] - save the results of film scoring data analysis to CSV file
Save the result DataFrame value in the CSV file. The first line of the file is the column name, and the core code is as follows:
// Save the result data to the CSv file
resultDF
.coalesce(1)
.write
.mode(SaveMode.Overwrite)
.option("header", "true")
.csv("datas/top10-movies")
The screenshot is as follows:
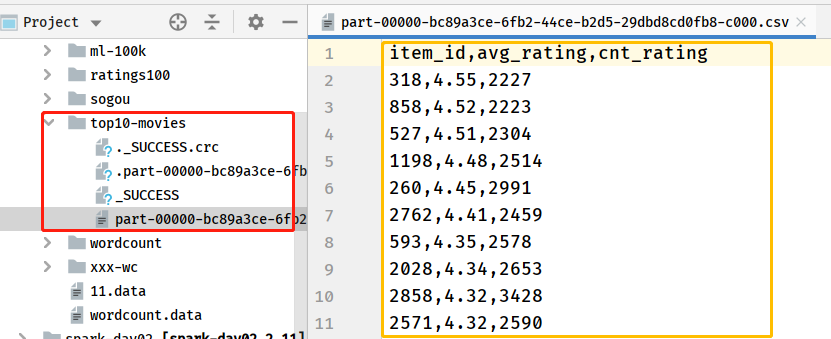
It is found that it is very convenient for SparkSQL to load data source data and save result data. The reason is that SparkSQL provides a powerful function [external data source interface], which makes the operation of data convenient and concise.
Appendix I. creating Maven module
1) . Maven engineering structure
2) . POM file content
Contents in the POM document of Maven project (Yilai package):
<!-- Specify the warehouse location, in order: aliyun,cloudera and jboss Warehouse -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- rely on Scala language -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL rely on -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL And Hive Integration dependency -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client rely on -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client rely on -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client rely on -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven Compiled plug-ins -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
aven compiled plug-ins -- >
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile