The text and pictures of this article are from the Internet, only for learning and communication, not for any commercial purpose. The copyright belongs to the original author. If you have any questions, please contact us in time for handling. Author: Clear wind turns evil spirit_

text
Note to novice: if you can't find a solution to the problem in your study, you can Point me into the skirt. , in which big guys solve problems and Python teaching. Cheng download and a group of progressive people to communicate!
1. Attach the code of the package graph crawler without multithreading
import requests
from lxml import etree
import os
import time
Start time = time. Time() ා record start time
for i in range(1,7):
#1. Request the packet graph network to get the overall data
response = requests.get("https://ibaotu.com/shipin/7-0-0-0-0-%s.html" %str(i))
#2. Extract video title and video link
html = etree.HTML(response.text)
Title list = HTML. XPath ('/ / span [@ class = "video title"] / text()') get video title
SRC list = HTML. XPath ('/ / div [@ class = "video play"] / video / @ SRC') get video link
for tit,src in zip(tit_list,src_list):
#3. Download Video
response = requests.get("http:" + src)
#Add the http header to the video link header. http is fast but not necessarily safe. https is safe but slow
#4. Save video
if os.path.exists("video1") == False: ා judge whether there is video in this folder
os.mkdir("video1")? If not, create a video folder
fileName = "video1\" + tit + ".mp4" ා save it in the video folder and name it with its own title. The file format is mp4
#If there are special characters, you need to use \ to annotate it, and \ is a special character, so you need to use 2 here\
print("saving video file:" + fileName) ා print out which file is being saved
with open (fileName,"wb") as f: write video to a file named fileName
f.write(response.content)
End? Time = time. Time()? Record end time
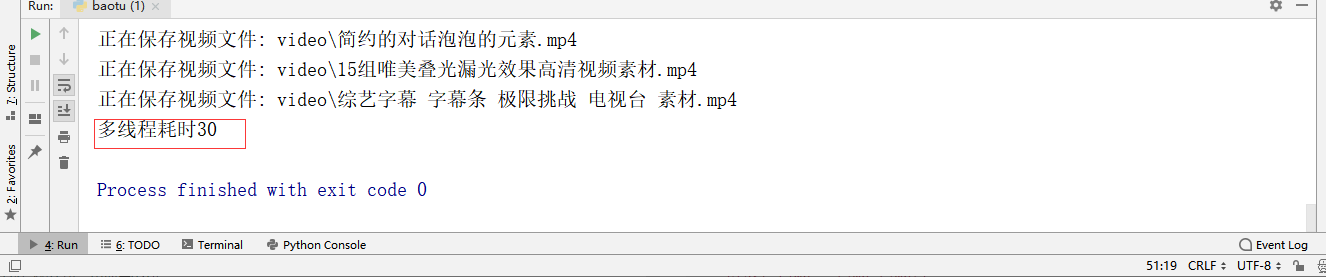
print("time-consuming% d seconds"% (end? Time-start? Time)) how long does the output take
2. Apply the above code to multithreading, and create multithreading first
data_list = []#Set a list of global variables
# Create multithreading
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#Call get? Index()
def run(self) -> None:
self.get_index()
#After getting the web address, get the required data and store it in the global variable data list
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# Visit URL
# Convert the returned data to lxml format, and then use xpath to grab it
html = etree.HTML(resp.content)
tit_list = html.xpath('//Span [@ class = "video title"] / text() ') get video title
src_list = html.xpath('//Div [@ class = "video play"] / video / @ SRC ') get video link
for tit, src in zip(tit_list, src_list):
data_dict = {}#Set up a dictionary for storing data
data_dict['title'] = tit#Add video title to dictionary
data_dict['src'] = src#Add video link to dictionary
# print(data_dict)
data_list.append(data_dict)#Add this dictionary to the list of global variables
except Exception as e:
# If the access times out, the error information will be printed, and the url will be put into the queue to prevent the wrong url from crawling
self.q.put(url)
print(e)3. Queue is used. The queue module is mainly multi-threaded to ensure the safe use of threads
def main():
# Create queue store url
q = queue.Queue()
for i in range(1,6):
# Encode the parameters of url and splice them to url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# Put the spliced url into the queue
q.put(url)
# If the queue is not empty, continue to climb
while not q.empty():
# Create 3 threads
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
4. Create a storage method. If you don't find a solution to the problem, you can Point me into the skirt. , in which big guys solve problems and Python teaching. Cheng download and a group of progressive people to communicate!
#Extract data from data list and save
def save_index(data_list):
if data_list:
for i in data_list:
# Download Video
response = requests.get("http:" + i['src'])
# Add the http header to the video link header. http is fast but not safe. https is safe but slow
# Save video
if os.path.exists("video") == False: # Determine whether there is a video folder
os.mkdir("video") # Create a video folder if you don't have one
fileName = "video\\" + i['title'] + ".mp4" # Save it in the video folder and name it with its own title. The file format is mp4
# If there are special characters, you need to use \ to annotate it, and \ is a special character, so you need to use 2 here\
print("Saving video file: " + fileName) # Print out which file you are saving
with open(fileName, "wb") as f: # Write video to a fileName named file
f.write(response.content)5. Finally, the function is called
if __name__ == '__main__':
start_time = time.time()
# Start crawler
main()
save_index(data_list)
end_time = time.time()
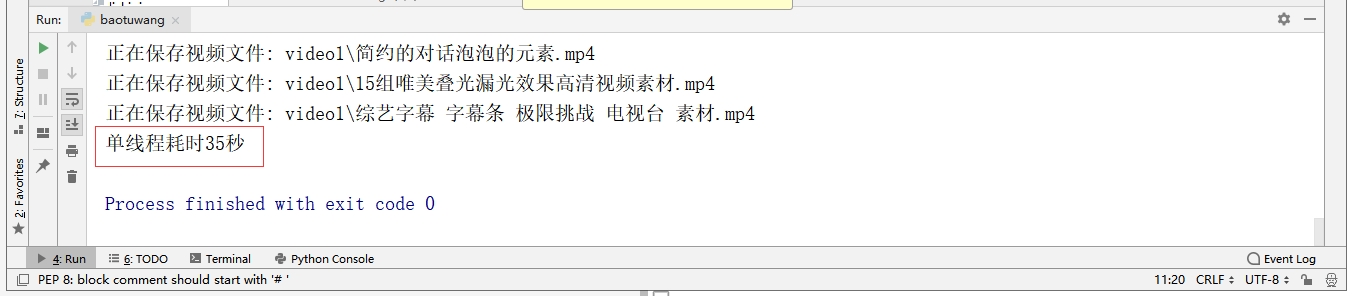
print("time consuming%d"%(end_time-start_time))6. Attach complete multithreaded code
import requests
from lxml import etree
import os
import queue
import threading
import time
data_list = []#Set a list of global variables
# Create multithreading
class MyThread(threading.Thread):
def __init__(self, q):
threading.Thread.__init__(self)
self.q = q
#Call get? Index()
def run(self) -> None:
self.get_index()
#After getting the web address, get the required data and store it in the global variable data list
def get_index(self):
url = self.q.get()
try:
resp = requests.get(url)# Visit URL
# Convert the returned data to lxml format, and then use xpath to grab it
html = etree.HTML(resp.content)
tit_list = html.xpath('//Span [@ class = "video title"] / text() ') get video title
src_list = html.xpath('//Div [@ class = "video play"] / video / @ SRC ') get video link
for tit, src in zip(tit_list, src_list):
data_dict = {}#Set up a dictionary for storing data
data_dict['title'] = tit#Add video title to dictionary
data_dict['src'] = src#Add video link to dictionary
# print(data_dict)
data_list.append(data_dict)#Add this dictionary to the list of global variables
except Exception as e:
# If the access times out, the error information will be printed, and the url will be put into the queue to prevent the wrong url from crawling
self.q.put(url)
print(e)
def main():
# Create queue store url
q = queue.Queue()
for i in range(1,7):
# Encode the parameters of url and splice them to url
url = 'https://ibaotu.com/shipin/7-0-0-0-0-%s.html'%str(i)
# Put the spliced url into the queue
q.put(url)
# If the queue is not empty, continue to climb
while not q.empty():
# Create 3 threads
ts = []
for count in range(1,4):
t = MyThread(q)
ts.append(t)
for t in ts:
t.start()
for t in ts:
t.join()
#Extract data from data list and save
def save_index(data_list):
if data_list:
for i in data_list:
# Download Video
response = requests.get("http:" + i['src'])
# Add the http header to the video link header. http is fast but not safe. https is safe but slow
# Save video
if os.path.exists("video") == False: # Determine whether there is a video folder
os.mkdir("video") # Create a video folder if you don't have one
fileName = "video\\" + i['title'] + ".mp4" # Save it in the video folder and name it with its own title. The file format is mp4
# If there are special characters, you need to use \ to annotate it, and \ is a special character, so you need to use 2 here\
print("Saving video file: " + fileName) # Print out which file you are saving
with open(fileName, "wb") as f: # Write video to a fileName named file
f.write(response.content)
if __name__ == '__main__':
start_time = time.time()
# Start crawler
main()
save_index(data_list)
end_time = time.time()
print("time consuming%d"%(end_time-start_time))
7. I have set the start time and end time for both crawlers, and can use (end time start time) to calculate and compare the efficiency of both.