1, Presto overview
coupon https://www.fenfaw.cn/1. Introduction to Presto
Presto is an open source distributed SQL query engine, which is suitable for interactive analysis and query. The data volume supports GB to PB bytes. Although Presto has the ability to parse SQL, it does not belong to the standard database category.
Presto supports online data query, including Hive, relational database and proprietary data storage. A Presto query can merge data from multiple data sources and analyze across the entire organization. Presto is mainly used to deal with scenarios with response time less than 1 second to a few minutes.
2. Presto architecture
Presto query engine is a distributed system based on master slave architecture and running on multiple servers. It is composed of one Coordinator node and multiple Worker nodes. The Coordinator is responsible for parsing SQL statements, generating execution plans, distributing execution tasks to the Worker node for execution, and the Worker node is responsible for actually executing query tasks.
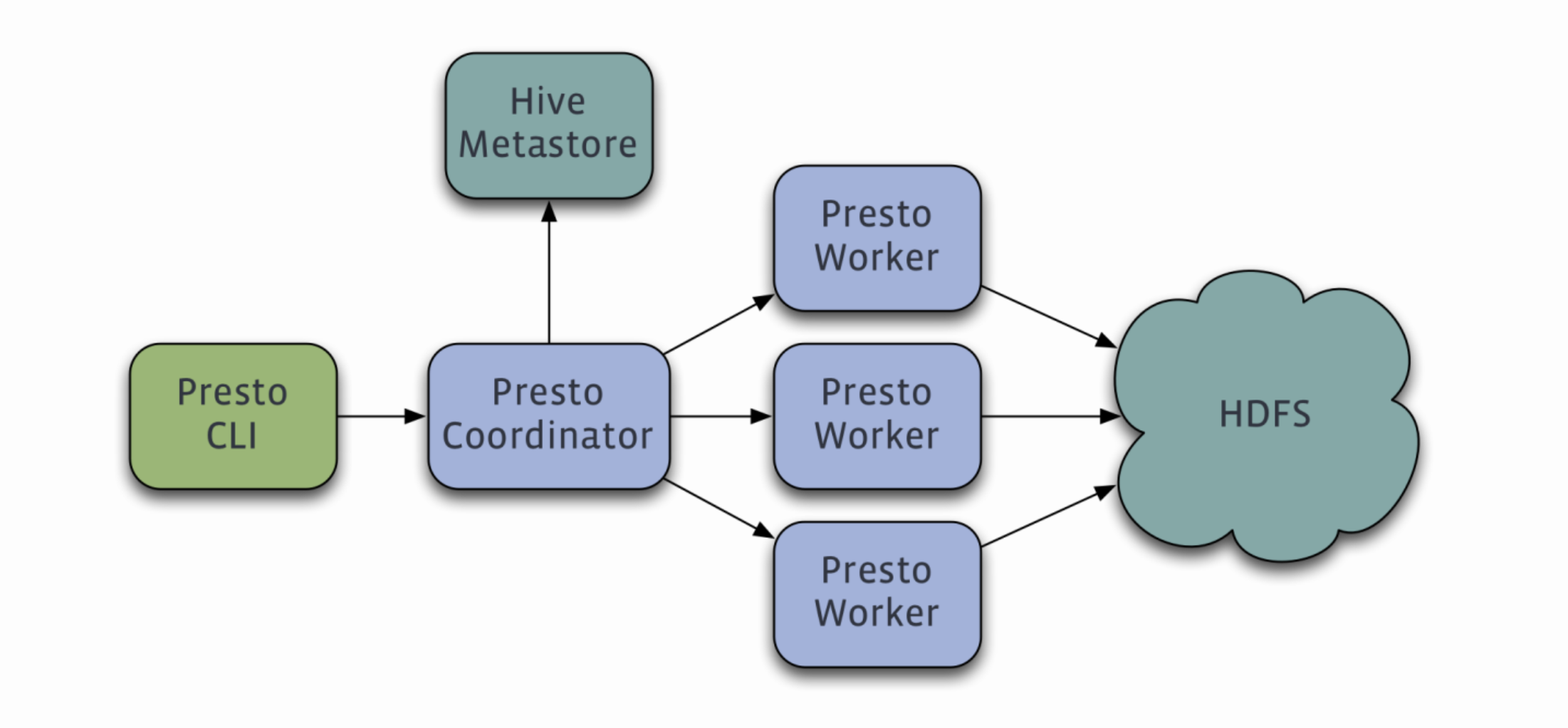
Coordinator node
Coordinator server is used to parse query statements, execute plans, analyze and manage Presto's Worker nodes, track the activities of each Work and coordinate the execution of query statements. The coordinator establishes a model for each query. The model contains multiple stages. Each Stage is converted into a Task and distributed to different workers for execution. The coordination communication is based on REST-API. Presto installation must have a coordinator node.
Worker node
Workers are responsible for executing query tasks and processing data, obtaining data from connectors, and exchanging intermediate data between workers. The Coordinator obtains the results from the Worker and returns the final results to the Client. When the Worker starts, it will broadcast itself and find the Coordinator to inform the Coordinator of the available status. The coordinated communication is based on the REST-API. Presto usually installs multiple Worker nodes.
Data source adaptation
Presto can adapt to many different data sources, and can connect and interact with data sources. Presto processes table through the fully qualified name of the table, Catalog corresponds to the class data source, Schema corresponds to the database, and table corresponds to the data table.
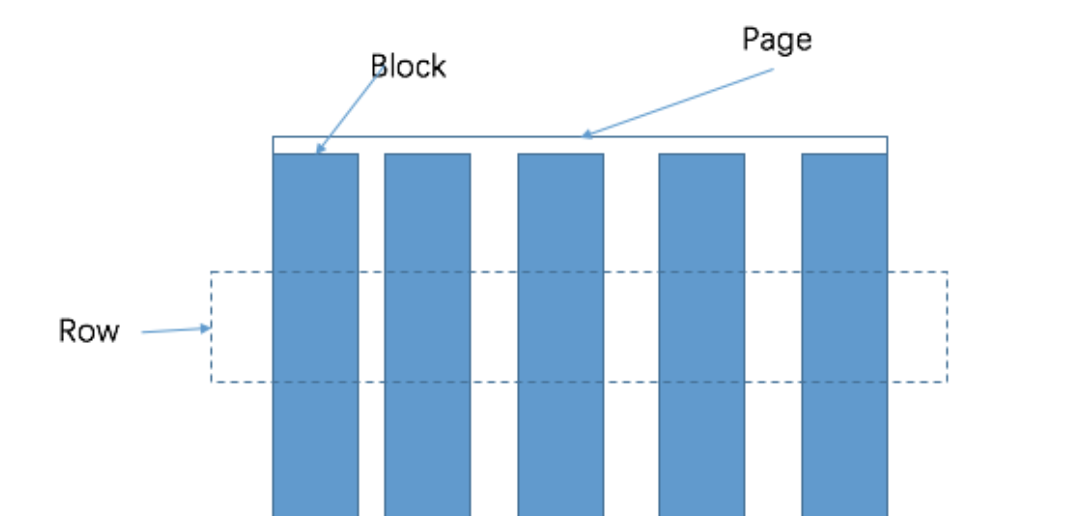
The smallest data unit processed in Presto is a Page object. A Page object contains multiple Block objects. Each Block object is a byte array that stores several rows of a field. A row crosscut by multiple blocks is a real row of data.
2, Presto installation
1. Installation package management
[root@hop01 presto]# pwd /opt/presto [root@hop01 presto]# ll presto-cli-0.196-executable.jar presto-server-0.189.tar.gz [root@hop01 presto]# tar -zxvf presto-server-0.189.tar.gz
2. Configuration management
Create the etc folder in the presto installation directory and add the following configuration information:
/opt/presto/presto-server-0.189/etc
Node attribute
Specific environment configuration of each node: etc / node properties;
[root@hop01 etc]# vim node.properties node.environment=production node.id=presto01 node.data-dir=/opt/presto/data
Configuration content: environment name, unique ID, and data directory.
JVM configuration
Command line options of JVM, list of command line options for starting Java virtual machine: etc / JVM config.
[root@hop01 etc]# vim jvm.config -server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError
Configuration properties
For the configuration of Presto server, each Presto server can act as a coordinator and worker. If a single machine is used to perform coordination, it can provide the best performance on a larger cluster. Here, Presto server is both a coordinator and a worker node: etc / config properties.
[root@hop01 etc]# vim config.properties coordinator=true node-scheduler.include-coordinator=true http-server.http.port=8083 query.max-memory=3GB query.max-memory-per-node=1GB discovery-server.enabled=true discovery.uri=http://hop01:8083
Here coordinator=true means that the current Presto instance acts as coordinator.
Log configuration
[root@hop01 etc]# vim log.properties com.facebook.presto=INFO
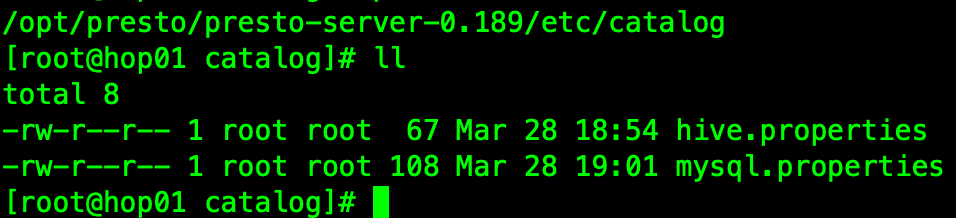
Catalog properties
/opt/presto/presto-server-0.189/etc/catalog
Configure hive adaptation:
[root@hop01 catalog]# vim hive.properties connector.name=hive-hadoop2 hive.metastore.uri=thrift://192.168.37.133:9083
Configure MySQL adapter:
[root@hop01 catalog]# vim mysql.properties connector.name=mysql connection-url=jdbc:mysql://192.168.37.133:3306 connection-user=root connection-password=123456
3. Running services
Start command
[root@hop01 /]# /opt/presto/presto-server-0.189/bin/launcher run
start log

So presto starts successfully.
3, Client installation
1. Jar package management
[root@hop01 presto-cli]# pwd /opt/presto/presto-cli [root@hop01 presto-cli]# ll presto-cli-0.196-executable.jar [root@hop01 presto-cli]# mv presto-cli-0.196-executable.jar presto-cli.jar
2. Connect to MySQL
java -jar presto-cli.jar --server ip:9000 --catalog mysql --schema sq_export
4, Source code address
GitHub·address https://github.com/cicadasmile/big-data-parent GitEE·address https://gitee.com/cicadasmile/big-data-parent
Reading labels
[Java foundation] [design pattern] [structure and algorithm] [Linux system] [database]
[distributed architecture] [microservices] [big data components] [advanced SpringBoot] [Spring & Boot foundation]
[data analysis] [technology map] [workplace]
