In the previous part, we briefly analyzed the naming specification in the specification, the timing of variable declaration, the specification of if and braces, the common problems and specifications of packaging classes and basic types, and the null pointer in project development. In this article, we continue to talk about some common details that are easy to be ignored in enterprise development.
Do not use enumeration types as return values
I still remember that Alibaba's Java development manual mentioned the specification of enumeration in many places:
[reference] enum class names are suffixed with enum. Enum member names need to be capitalized and separated by underscores. Note: enumeration is actually a special class. All domain members are constants, and the construction method is forced to be private by default.
[recommended] if the variable value changes only within a fixed range, it is defined by enum type.
[mandatory] enumeration types can be defined in the two-party database. Enumeration types can be used for parameters, but enumeration types or POJO objects containing enumeration types are not allowed for interface return values.
One is the recommended reference naming specification and the other is the recommended use method. However, we notice that there is a mandatory specification. Generally, mandatory specifications are marked to avoid the risk of some details of enterprise development. You can see that Alibaba manual mentions that it is not allowed to use enumeration type parameters for transmission in the process of interface interaction, So why?
As we know, the use scenario of enumeration is generally that when a set of fixed constants of the same type is required, we can use enumeration as a tag replacement. Therefore, the enumeration class does not need multiple instances, which ensures that the memory overhead can be reduced after a single instance.
**And we also know that when writing enumeration, if it is modified by abstract or final, or the enumeration constant is repeated, the compiler will immediately report an error. And in the whole enumeration class, there is no other instance except the current enumeration constant** Because of these features, it is easier for us to use constants in the development process.
However, after in-depth understanding, * * we can know that the clone method of enumeration is modified by final, so the enum constant will not be cloned, and the enumeration class prohibits the creation of instances through reflection, which ensures the absolute singleton. In the process of deserialization, the enumeration class is not allowed to have different instances** The two most important methods of enumerating classes are:
1. The publicstatic valueof (string) method used to obtain the corresponding enumeration constant according to the enumeration name
2. The publicstatic [] values () method used to obtain all the current enumeration constants
3. Function for cloning - clone
Let's study why there are enumeration specifications according to these methods. First, let's take a look at the comments of clone method:
1. `/**` 2. `* Throws CloneNotSupportedException. This guarantees that enums` 3. `* are never cloned, which is necessary to preserve their "singleton"` 4. `* status.` 5. `*` 6. `* @return (never returns)` 7. `*/` </pre>
From annotations, we can see that enumeration types do not support the clone method. If we call the clone method, we will throw CloneNotSupportedException exceptions, and there is also a newInstance method that reflects the creation instance. We all know that if we do not call the clone method, we can generally use reflection, and setAccessible is called newInstance after true. You can build a new instance, and we can see the source code of this method:
1. `public T newInstance(Object... initargs)`
2. `throwsInstantiationException, IllegalAccessException,`
3. `IllegalArgumentException, InvocationTargetException`
4. `{`
5. `.........`
6. `//If the current type is an enumeration type, the current method will be called to throw an exception directly`
7. `if((clazz.getModifiers() & Modifier.ENUM) != 0)`
8. `thrownewIllegalArgumentException("Cannot reflectively create enum objects");`
10. `.........`
11. `return inst;`
12. `}`
</pre>
From this, we can see that enumeration prohibits clone and reflection from creating instances in order to * * ensure that they cannot be cloned and maintain the singleton state** Then let's look at serialization. Since all enumerations are subclasses and instances of Eunm class, and Eunm class implements Serializable and Comparable interfaces by default, sorting and serialization are allowed by default. The implementation of the sorting method compareTo is roughly as follows:
1. `/**`
2. `* Compares this enum with the specified object for order. Returns a`
3. `* negative integer, zero, or a positive integer as this object is less`
4. `* than, equal to, or greater than the specified object.`
5. `*`
6. `* Enum constants are only comparable to other enum constants of the`
7. `* same enum type. The natural order implemented by this`
8. `* method is the order in which the constants are declared.`
9. `*/`
10. `public final int compareTo(E o) {`
11. `Enum<?> other = (Enum<?>)o;`
12. `Enum<E> self = this;`
13. `if (self.getClass() != other.getClass() && // optimization`
14. `self.getDeclaringClass() != other.getDeclaringClass())`
15. `throw new ClassCastException();`
16. `return self.ordinal - other.ordinal;`
17. `}`
</pre>
ordinal represents the declaration order corresponding to each enumeration constant, indicating that the enumeration sorting method is sorted according to the declaration order by default. What is the process of serialization and deserialization? Let's write a serialized code. After debug ging and the code, we can see that Java is finally called Lang. enum#valueof method. The contents after serialization are as follows:
1. `arn_enum.CoinEnum?xr?java.lang.Enum?xpt?PENNYq?t?NICKELq?t?DIMEq~?t?QUARTER` </pre>
As you can see, serialization mainly includes enumeration types and each name of enumeration. Then let's take a look at Java Source code of lang. enum#valueof method:
1. `/**`
2. `* Returns the enum constant of the specified enum type with the`
3. `* specified name. The name must match exactly an identifier used`
4. `* to declare an enum constant in this type. (Extraneous whitespace`
5. `* characters are not permitted.)`
6. `*`
7. `* <p>Note that for a particular enum type {@code T}, the`
8. `* implicitly declared {@code public static T valueOf(String)}`
9. `* method on that enum may be used instead of this method to map`
10. `* from a name to the corresponding enum constant. All the`
11. `* constants of an enum type can be obtained by calling the`
12. `* implicit {@code public static T[] values()} method of that`
13. `* type.`
14. `*`
15. `* @param <T> The enum type whose constant is to be returned`
16. `* @param enumType the {@code Class} object of the enum type from which`
17. `* to return a constant`
18. `* @param name the name of the constant to return`
19. `* @return the enum constant of the specified enum type with the`
20. `* specified name`
21. `* @throws IllegalArgumentException if the specified enum type has`
22. `* no constant with the specified name, or the specified`
23. `* class object does not represent an enum type`
24. `* @throws NullPointerException if {@code enumType} or {@code name}`
25. `* is null`
26. `* @since 1.5`
27. `*/`
28. `public static <T extends Enum<T>> T valueOf(Class<T> enumType,`
29. `String name) {`
30. `T result = enumType.enumConstantDirectory().get(name);`
31. `if (result != null)`
32. `return result;`
33. `if (name == null)`
34. `throw new NullPointerException("Name is null");`
35. `throw new IllegalArgumentException(`
36. `"No enum constant " + enumType.getCanonicalName() + "." + name);`
37. `}`
</pre>
From the source code and comments, we can see that if the enumeration class used by service A is the old version and only has five constants, while the enumeration of service B contains new constants. At this time, when deserializing, because name == null, an exception will be thrown directly, which we can finally see, Why is it mandatory in the specification not to use enumeration types as parameters for serialization and transmission.
Use variable parameters with caution
When I looked through the major specification manuals, I saw this one in Ali's Manual:
[mandatory] Java variable parameters can only be used if they have the same parameter type and the same business meaning. Avoid using Object. Note: variable parameters must be placed at the end of the parameter list. (students are encouraged to avoid variable parameter programming as much as possible)
Positive example: public ListlistUsers(String type, Long... ids) {...}
It attracted me because in the previous development process, I encountered a pit buried by variable parameters. Next, let's take a look at a pit related to variable parameters.
I believe many people have written tool classes used in enterprises. When I first wrote a Boolean tool class, I wrote the following two methods:
1. `private static boolean and(boolean... booleans) {`
2. `for (boolean b : booleans) {`
3. `if (!b) {`
4. `return false;`
5. `}`
6. `}`
7. `return true;`
8. `}`
10. `private static boolean and(Boolean... booleans) {`
11. `for (Boolean b : booleans) {`
12. `if (!b) {`
13. `return false;`
14. `}`
15. `}`
16. `return true;`
17. `}`
</pre>
These two methods look the same. They both pass multiple Boolean parameters to judge whether multiple conditions can be connected together and become the result of true. However, when I write the test code, the problem arises:
1. `public static void main(String[] args) {`
2. `boolean result = and(true, true, true);`
3. `System.out.println(result);`
4. `}`
</pre>
What will such a method return? In fact, when the code has just been written, you will find that the compiler has reported an error and will prompt:
1. `Ambiguous method call. Both and (boolean...) in BooleanDemo and and (Boolea` 2. `n...) in BooleanDemo match.` </pre>
Fuzzy function matching, because the compiler thinks that there are two methods that fully meet the current function, so why? We know that in Java 1 After 5, the automatic unpacking process was added. In order to be compatible with jdk versions before 1.5, this process is set to three stages:
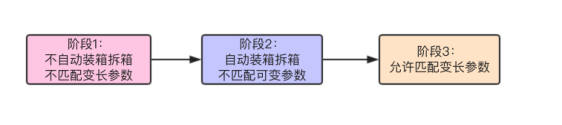
In the test method we use, in the first stage, we judge whether the jdk version does not allow automatic unpacking. Obviously, the jdk version is greater than 1.5 and allows automatic unpacking. Therefore, we enter the second stage. At this time, we judge whether there are more consistent parameter methods. For example, we pass three Boolean parameters, but if there are three Boolean parameter methods, This method will be preferentially matched instead of the method of matching variable parameters. Obviously, there is no method. At this time, it will enter the third stage. After unpacking, find the method of matching variable length parameters. At this time, because unpacking is completed, the two types will be regarded as one type. If there are two matching methods in the method, an error will be reported.
So how can we deal with this problem? After all, we are familiar with org apache. commons. lang3. There are similar methods in the Boolean utils tool class. We all know that variable length parameters actually load the current multiple passed parameters into the array and then process them. Then, all parameters can be wrapped through the array in the process of transmission. At this time, the unpacking process will not occur! For example:
1. `@Test`
2. `public void testAnd_primitive_validInput_2items() {`
3. `assertTrue(`
4. `! BooleanUtils.and(new boolean[] { false, false })`
5. `}`
</pre>
In reference to the writing method of other framework source codes, there are also examples of writing for this:

This method can ensure that if the basic type is passed in, it will directly match the current method. If it is a wrapper type, it will match the current function after the second stage, and finally call the and method of the basic type in Boolean utils.
De duplication of List and xxList method
As the most common collection class in our enterprise development, List often encounters de duplication, conversion and other operations in the development process, but the poor operation of collection class will often lead to the slow performance of our program or the risk of abnormality. For example, it is mentioned in Alibaba Manual:
[mandatory] the subList result of ArrayList cannot be forcibly converted to ArrayList, otherwise ClassCastException will be thrown, that is, Java util. RandomAccessSubList cannot be cast to java. util. ArrayList.
[mandatory] in the SubList scenario, pay great attention to the addition or deletion of the original set elements, which will lead to the traversal, addition and deletion of the SubList, resulting in the ConcurrentModificationException exception.
[mandatory] use the tool class arrays When aslist() converts an array into a collection, it cannot be used to modify the methods related to the collection. Its add/remove/clear method will throw an unsupported operationexception.
These xxList methods in the manual are commonly used in our development process, so why do Alibaba manuals have these specifications? Let's take a look at the first method SubList. First, let's look at the difference between SubList class and ArrayList class. From the class diagram, we can see that there is no inheritance relationship between the two classes:
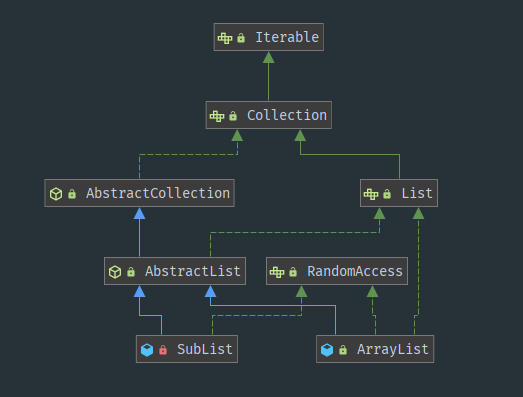
Therefore, it is not allowed to use subList to forcibly convert to ArrayList in the manual, so why can't the original set be added, deleted, modified and queried? Let's take a look at its source code:
1. `/**`
2. `* Returns a view of the portion of this list between the specified`
3. `* {@code fromIndex}, inclusive, and {@code toIndex}, exclusive. (If`
4. `* {@code fromIndex} and {@code toIndex} are equal, the returned list is`
5. `* empty.) The returned list is backed by this list, so non-structural`
6. `* changes in the returned list are reflected in this list, and vice-versa.`
7. `* The returned list supports all of the optional list operations.`
8. `*`
9. `* <p>This method eliminates the need for explicit range operations (of`
10. `* the sort that commonly exist for arrays). Any operation that expects`
11. `* a list can be used as a range operation by passing a subList view`
12. `* instead of a whole list. For example, the following idiom`
13. `* removes a range of elements from a list:`
14. `* <pre>`
15. `* list.subList(from, to).clear();`
16. `* </pre>`
17. `* Similar idioms may be constructed for {@link #indexOf(Object)} and`
18. `* {@link #lastIndexOf(Object)}, and all of the algorithms in the`
19. `* {@link Collections} class can be applied to a subList.`
20. `*`
21. `* <p>The semantics of the list returned by this method become undefined if`
22. `* the backing list (i.e., this list) is <i>structurally modified</i> in`
23. `* any way other than via the returned list. (Structural modifications are`
24. `* those that change the size of this list, or otherwise perturb it in such`
25. `* a fashion that iterations in progress may yield incorrect results.)`
26. `*`
27. `* @throws IndexOutOfBoundsException {@inheritDoc}`
28. `* @throws IllegalArgumentException {@inheritDoc}`
29. `*/`
30. `publicList<E> subList(int fromIndex, int toIndex) {`
31. `subListRangeCheck(fromIndex, toIndex, size);`
32. `returnnewSubList(this, 0, fromIndex, toIndex);`
33. `}`
</pre>
We can see that the logic of the code has only two steps. The first step is to check whether the current index and length change. The second step is to build a new SubList and return it. From the comments, we can also know that the scope contained in the SubList will change from the current index + offSet if it is added, deleted, modified and queried.
So why does the addition, deletion, modification and query of the original ArrayList cause the SubList set operation exception? Let's take a look at the add method of ArrayList:
1. `/**`
2. `* Appends the specified element to the end of this list.`
3. `*`
4. `* @param e element to be appended to this list`
5. `* @return <tt>true</tt> (as specified by {@link Collection#add})`
6. `*/`
7. `publicboolean add(E e) {`
8. `ensureCapacityInternal(size + 1); // Increments modCount!!`
9. `elementData[size++] = e;`
10. `returntrue;`
11. `}`
</pre>
We can see that every time an element is added, there will be an ensureCapacityInternal(size+1); Operation, which will cause the length of modCount to change, and modCount is used to record the length in the construction of SubList:
1. `SubList(AbstractList<E> parent,`
2. `int offset, int fromIndex, int toIndex) {`
3. `this.parent = parent;`
4. `this.parentOffset = fromIndex;`
5. `this.offset = offset + fromIndex;`
6. `this.size = toIndex - fromIndex;`
7. `this.modCount = ArrayList.this.modCount; // Note: the modCount of ArrayList is copied here`
8. `}`
</pre>
The source code of get operation of SubList is as follows:
1. `public E get(int index) {`
2. `rangeCheck(index);`
3. `checkForComodification();`
4. `returnArrayList.this.elementData(offset + index);`
5. `}`
</pre>
You can see that the subscript and modCount are checked every time. Let's take a look at the checkForComodification method:
1. `private void checkForComodification() {`
2. `if (ArrayList.this.modCount != this.modCount)`
3. `throw new ConcurrentModificationException();`
4. `}`
</pre>
It can be seen that it will be checked every time. If it is found that the length of the original set has changed, an exception will be thrown. This is why we should pay attention to whether the original set has been changed when using SubList.
So why is the collection of asList method not allowed to add, modify, delete and other operations?
Let's take a look at the method comparison with ArrayList:

Obviously, we can see that the List constructed by asList does not override the add and remove functions, which indicates that the collection operation methods of this class come from the parent class AbstactList. Let's take a look at the add method of the parent class:
1. `public void add(int index, E element) {`
2. `throw new UnsupportedOperationException();`
3. `}`
</pre>
From this, we can see that if we add or remove, we will throw exceptions directly.
Set de duplication operation
Let's take another look at one of the most common operations in enterprise development. I used to think that everyone would choose to use Set for de duplication. However, when I looked at the team code, I found that many people were lazy and chose the contains method of the List to judge whether it existed, and then did the de duplication operation! Let's take a look at the code we write when we use Set to remove duplicates:
1. `public static <T> Set<T> removeDuplicateBySet(List<T> data) {`
2. `if (CollectionUtils.isEmpty(data)) {`
3. `return new HashSet<>();`
4. `}`
5. `return new HashSet<>(data);`
6. `}`
</pre>
The construction method of HashSet is as follows:
1. `publicHashSet(Collection<? extends E> c) {`
2. `map = newHashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));`
3. `addAll(c);`
4. `}`
</pre>
It's mainly about addAll after creating a HashMap. Let's take a look at the addAll method:
1. `public boolean addAll(Collection<? extends E> c) {`
2. `boolean modified = false;`
3. `for (E e : c)`
4. `if (add(e))`
5. `modified = true;`
6. `return modified;`
7. `}`
</pre>
We can also see from this that the internal loop calls the add method to add elements:
1. `public boolean add(E e) {`
2. `return map.put(e, PRESENT)==null;`
3. `}`
</pre>
The add method internally relies on the put method of hashMap. We all know that the key in the put method of hashMap is unique, that is, repetition can be avoided naturally. Let's see how the hash of key is calculated:
1. `static final int hash(Object key) {`
2. `int h;`
3. `return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);`
4. `}`
</pre>
It can be seen that if the key is null, the hash value is 0. Otherwise, the key will XOR the hash value calculated by its own hashCode function and its right shift by 16 bits to obtain the final hash value. In the final putVal method, the logic to judge whether it exists is as follows:
1. `p.hash == hash && ((k = p.key) == key || (key != null&& key.equals(k)))` </pre>
Seeing this, we have basically understood that the hash calculation of set still depends on the hashCode calculation of the element itself. As long as the element instances we need to de duplicate follow the rule of rewriting hashCode and equals, it is very simple to directly use set for de duplication. In turn, let's take a look at the implementation of the contains method of List:
1. `/**`
2. `* Returns <tt>true</tt> if this list contains the specified element.`
3. `* More formally, returns <tt>true</tt> if and only if this list contains`
4. `* at least one element <tt>e</tt> such that`
5. `* <tt>(o==null ? e==null : o.equals(e))</tt>.`
6. `*`
7. `* @param o element whose presence in this list is to be tested`
8. `* @return <tt>true</tt> if this list contains the specified element`
9. `*/`
10. `public boolean contains(Object o) {`
11. `return indexOf(o) >= 0;`
12. `}`
</pre>
It can be seen that the judgment depends on the indexOf method:
1. `/**`
2. `* Returns the index of the first occurrence of the specified element`
3. `* in this list, or -1 if this list does not contain the element.`
4. `* More formally, returns the lowest index <tt>i</tt> such that`
5. `* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>,`
6. `* or -1 if there is no such index.`
7. `*/`
8. `public int indexOf(Object o) {`
9. `if (o == null) {`
10. `for (int i = 0; i < size; i++)`
11. `if (elementData[i]==null)`
12. `return i;`
13. `} else {`
14. `for (int i = 0; i < size; i++)`
15. `if (o.equals(elementData[i]))`
16. `return i;`
17. `}`
18. `return -1;`
19. `}`
</pre>
You can see that the logic of indexOf is. If it is null, you will traverse all elements to determine whether there is null. If it is not null, you will also traverse the equals method of all elements to determine whether it is equal. Therefore, the time complexity is close to O(n^2), and the containsKey method of Set mainly depends on the getNode method:
1. `/**`
2. `* Implements Map.get and related methods.`
3. `*`
4. `* @param hash hash for key`
5. `* @param key the key`
6. `* @return the node, or null if none`
7. `*/`
8. `finalNode<K,V> getNode(int hash, Object key) {`
9. `Node<K,V>[] tab; Node<K,V> first, e; int n; K k;`
10. `if((tab = table) != null&& (n = tab.length) > 0&&`
11. `(first = tab[(n - 1) & hash]) != null) {`
12. `if(first.hash == hash && // always check first node`
13. `((k = first.key) == key || (key != null&& key.equals(k))))`
14. `return first;`
15. `if((e = first.next) != null) {`
16. `if(first instanceofTreeNode)`
17. `return((TreeNode<K,V>)first).getTreeNode(hash, key);`
18. `do{`
19. `if(e.hash == hash &&`
20. `((k = e.key) == key || (key != null&& key.equals(k))))`
21. `return e;`
22. `} while((e = e.next) != null);`
23. `}`
24. `}`
25. `returnnull;`
26. `}`
</pre>
It can be seen that the first element of the table is found through the calculated hash value first. If it is equal, the first element is returned directly. If it is a tree node, it is found from the tree species, and if it is not, it is found from the chain. It can be seen that if the hash conflict is not very serious, the search speed is close to O(n). It is obvious that if there are a large number, The contents speed of List may even be thousands of times different!
String and splicing
In the Java core library, there are three classes of string operations, namely string, StringBuffer and StringBuilder, which will inevitably involve a problem. String operations are often used in enterprise development, such as string splicing, but incorrect use will lead to a large number of performance traps, So where to use string splicing and when to use the other two better? Let's start with a case:
1. `public String measureStringBufferApend() {`
2. `StringBuffer buffer = new StringBuffer();`
3. `for (int i = 0; i < 10000; i++) {`
4. `buffer.append("hello");`
5. `}`
6. `return buffer.toString();`
7. `}`
9. `//The second way to write`
10. `public String measureStringBuilderApend() {`
11. `StringBuilder builder = new StringBuilder();`
12. `for (int i = 0; i < 10000; i++) {`
13. `builder.append("hello");`
14. `}`
15. `return builder.toString();`
16. `}`
18. `//Direct String splicing`
19. `public String measureStringApend() {`
20. `String targetString = "";`
21. `for (int i = 0; i < 10000; i++) {`
22. `targetString += "hello";`
23. `}`
24. `return targetString;`
25. `}`
</pre>
The performance test results of JMH test show that the efficiency of StringBuffer splicing is 200 times faster than that of String + = and the efficiency of StringBuilder is 700 times faster than that of Stirng + = why?
During the + = operation of the original String, you need to create a new String object every time, then copy the contents of the two times, destroy the original String object, and then create.... The reason why StringBuffer and StringBuilder are fast is that some memory is pre allocated internally. Only when the memory is insufficient will the memory be expanded. The implementation of StringBuffer and StringBuilder is almost the same. The only difference is that the method is synchronized package, which ensures the security of String operation under concurrency, Therefore, the performance will decline to a certain extent.
So is String splicing the fastest?
Not necessarily. For example, the following example:
1. `public void measureSimpleStringApend() {`
2. `for (int i = 0; i < 10000; i++) {`
3. `String targetString = "Hello, " + "world!";`
4. `}`
5. `}`
6. `//StringBuilder splicing`
7. `public void measureSimpleStringBuilderApend() {`
8. `for (int i = 0; i < 10000; i++) {`
9. `StringBuilder builder = new StringBuilder();`
10. `builder.append("hello, ");`
11. `builder.append("world!");`
12. `}`
13. `}`
</pre>
I believe experienced people will find that the direct + splicing of two string segments is even faster than StringBuilder! This huge difference mainly comes from the optimization of string processing by Java compiler and JVM. " Hello, " + "world! " Such expressions do not really perform string concatenation.
The compiler will process it into a connected constant string "Hello, world!". In this way, there will be no repeated object creation and destruction, and the connection of constant strings shows ultra-high efficiency.
However, we need to note that if the spliced two strings are not fragment constants, but a variable, the efficiency will drop sharply, and the jvm cannot optimize the operation of string variables, for example:
1. `public void measureVariableStringApend() {`
2. `for (int i = 0; i < 10000; i++) {`
3. `String targetString = "Hello, " + getAppendix();`
4. `}`
5. `}`
7. `private String getAppendix() {`
8. `return "World!";`
9. `}`
</pre>
Therefore, we can summarize several practical suggestions for using string splicing:
1. The java compiler will optimize the connection of constant strings. We can safely replace long strings with multiple lines. We should pay attention to the use of + concatenation constants instead of + =. These two concepts are different.
2. String connection with variables makes StringBuilder more efficient. For efficiency sensitive code, it is recommended to use StringBuilder, and StringBuffer is generally not recommended in daily development, unless there are strict concurrency security requirements.
end
Redis is based on memory and is often used as a technology for caching, and redis is stored in the form of key value. Redis is the most widely used cache in today's Internet technology architecture, which is often used in work. Redis is also one of the most popular questions that interviewers like to ask in the technical interview of middle and senior back-end engineers. Therefore, as a Java developer, redis is something we must master.
Redis is a leader in the field of NoSQL database. If you need to know how redis realizes high concurrency and massive data storage, this Tencent expert's Manual "redis source code log notes" will be your best choice.

String variable operation is optimized, for example:
1. `public void measureVariableStringApend() {`
2. `for (int i = 0; i < 10000; i++) {`
3. `String targetString = "Hello, " + getAppendix();`
4. `}`
5. `}`
7. `private String getAppendix() {`
8. `return "World!";`
9. `}`
</pre>
Therefore, we can summarize several practical suggestions for using string splicing:
1. The java compiler will optimize the connection of constant strings. We can safely replace long strings with multiple lines. We should pay attention to the use of + concatenation constants instead of + =. These two concepts are different.
2. String connection with variables makes StringBuilder more efficient. For efficiency sensitive code, it is recommended to use StringBuilder, and StringBuffer is generally not recommended in daily development, unless there are strict concurrency security requirements.
end
Redis is based on memory and is often used as a technology for caching, and redis is stored in the form of key value. Redis is the most widely used cache in today's Internet technology architecture, which is often used in work. Redis is also one of the most popular questions that interviewers like to ask in the technical interview of middle and senior back-end engineers. Therefore, as a Java developer, redis is something we must master.
Redis is a leader in the field of NoSQL database. If you need to know how redis realizes high concurrency and massive data storage, this Tencent expert's Manual "redis source code log notes" will be your best choice.
[external chain picture transferring... (IMG dbglmtpq-1623622185354)]
Interested friends can Click like + stamp here for free Tencent experts handwritten Redis source code log notes pdf version!