As we all know, regular expressions define the pattern of strings that can be used to search, edit, or process text. It is very convenient for us to use in some specific scenes. It is tantamount to delimiting a range for us so that we can accurately match the results we want. For example, I want to judge whether a file with dozens of pages contains an email address. If I use the traditional method, I have to traverse and filter it from beginning to end. The workload is very heavy, but with regularity, we can delimit patterns to judge, which is very convenient. Regular expressions are not limited to one language, but there are subtle differences in each language. Let me illustrate the basic usage of regular expressions in Java.
1. What can regular expressions be used for
Just saying what regular expressions are, some people have questions. What can he do with it? Now I'll give you an example, and then slowly tell you:
For example, if I judge whether a bunch of strings contain numbers, I can use regular to do the following:
@Test
public void test1(){
String s = "fsjkdhfgjh666hgdfshjhahaksgefj";
System.out.println(s.matches("^.*[\\d+].*$"));
}
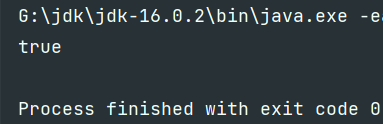
It proves that there are figures and there are.
But you may have said, I will traverse the string, and then judge one by one. Can't I find it? Of course. For such a string, of course you can. But what if we face a book? I want to judge whether there is an ID number in a book. First, I am not sure how much this ID number is (of course 18). I can't go through this book from beginning to end. It's a heavy workload. And you don't know how much it is. At this time, the advantages of regular expressions come out. I can draw a rule to search. This greatly improves our development efficiency.
2. How to use regular expressions
So how to use regular expressions.
First of all, let me give you a list:
1. Regular expression metacharacter
| character | describe |
|---|---|
| \ | Marks the next character as a special character, or a literal character, or a backward reference, or an octal escape character. For example, 'n' matches the character 'n'\ N 'matches a newline character. Sequence '\' matches' ', while' ('matches' ('. |
| ^ | Matches the starting position of the input string. If the Multiline property of the RegExp object is set, ^ also matches the position after '\ n' or '\ r'. |
| $ | Matches the end position of the input string. If the Multiline property of the RegExp object is set, $also matches the position before '\ n' or '\ r'. |
| * | Matches the previous subexpression zero or more times. For example, zo * can match "z" and "zoo". * is equivalent to {0,}. |
| + | Match the previous subexpression one or more times. For example, 'zo +' can match 'zo' and 'zoo', but not 'z'. + is equivalent to {1,}. |
| ? | Matches the previous subexpression zero or once. For example, "do(es)?" can match "do" or "does".? is equivalent to {0,1}. |
| {n} | N is a non negative integer. The matching is determined n times. For example, 'o{2}' cannot match 'o' in "Bob", but it can match two o's in "food". |
| {n,} | n is a non negative integer. It matches at least n times. For example, 'o{2,}' cannot match 'o' in 'Bob', but can match all o in 'fooood'. 'o{1,}' is equivalent to 'O +'. 'o{0,}' is equivalent to 'o *'. |
| {n,m} | Both M and N are nonnegative integers, where n < = M. match at least N times and at most m times. For example, "o{1,3}" will match the first three o's in "food". o{0,1} 'is equivalent to' o? '. Note that there can be no spaces between commas and two numbers. |
| ? | The matching pattern is non greedy when the character follows any other qualifier (*, +,?, {n}, {n,}, {n,m}). The non greedy pattern matches the searched string as little as possible, while the default greedy pattern matches the searched string as much as possible. For example, for the string "oooo", 'O +?' will match a single "O" , and 'O +' will match all 'o'. |
| . | Matches any single character except line breaks (\ n, \ r). To match any character including '\ n', use a pattern like '(. | \ n)'. |
| (pattern) | Match pattern and obtain this match. The obtained match can be obtained from the generated Matches collection, using the SubMatches collection in VBScript and the $0... $9 attribute in JScript. To match parenthesis characters, use '(' or '). |
| (?:pattern) | Matches the pattern but does not get the matching result, that is, it is a non fetched match and will not be stored for later use. This is very useful when using the "or" character (|) to combine various parts of a pattern. For example, 'industry (: y| ies) is a simpler expression than' industry|industries'. |
| (?=pattern) | look ahead positive assert matches the lookup string at the beginning of any string matching pattern. This is a non fetch match, that is, the match does not need to be fetched for later use. For example, "Windows(?=95|98|NT|2000)" can match "windows" in "Windows2000", but not "windows" in "Windows3.1" . the pre query does not consume characters, that is, after a match occurs, the search for the next match starts immediately after the last match, rather than after the characters containing the pre query. |
| (?!pattern) | Positive negative assert matches the lookup string at the beginning of any string that does not match the pattern. This is a non fetch match, that is, the match does not need to be fetched for later use. For example, "Windows(?!95|98|NT|2000)" can match "windows" in "Windows3.1", but not "windows" in "Windows2000" . the pre query does not consume characters, that is, after a match occurs, the search for the next match starts immediately after the last match, rather than after the characters containing the pre query. |
| (?<=pattern) | The look behind positive pre check is similar to the positive positive pre check, but in the opposite direction. For example, "(? < = 95|98|nt|2000) Windows" can match "Windows" in "2000Windows", but cannot match "Windows" in "3.1 Windows". |
| (?<!pattern) | Reverse negative prefetching is similar to positive negative prefetching, but in the opposite direction. For example, "(? <! 95|98|nt|2000) Windows" can match "Windows" in "3.1 Windows", but cannot match "Windows" in "2000 Windows". |
| x|y | Match x or y. for example, 'z|food' can match 'Z' or 'food'. '(z|f)ood' matches' zoo 'or' food '. |
| [xyz] | Character set. Match any character contained. For example, '[abc]' can match 'a' in 'plain'. |
| [^xyz] | Negative character set. Matches any characters that are not included. For example, '[^ abc]' can match 'p', 'l', 'i' and 'n' in 'plain'. |
| [a-z] | Character range. Matches any character within the specified range. For example, 'a-z]' can match any lowercase character from 'a' to 'z'. |
| [^a-z] | Negative character range. Matches any character that is not within the specified range. For example, '[^ a-z]' can match any character that is not in the range of 'a' to 'z'. |
| \b | Match a word boundary, that is, the position between the word and the space. For example, 'er\b' can match 'er' in 'never', but not 'er' in 'verb'. |
| \B | Matches non word boundaries‘ er\B 'can match' er 'in' verb ', but cannot match' er 'in' never '. |
| \cx | Matches the control character indicated by x. For example, \ cM matches a Control-M or carriage return. The value of x must be either A-Z or one of A-Z. Otherwise, c is treated as a literal 'c' character. |
| \d | Matches a numeric character. Equivalent to [0-9]. |
| \D | Matches a non numeric character. Equivalent to [^ 0-9]. |
| \f | Match a page feed. Equivalent to \ x0c and \ cL. |
| \n | Match a newline character. Equivalent to \ x0a and \ cJ. |
| \r | Match a carriage return. Equivalent to \ x0d and \ cM. |
| \s | Matches any white space characters, including spaces, tabs, page breaks, and so on. Equivalent to [\ f\n\r\t\v]. |
| \S | Matches any non whitespace characters. Equivalent to [^ \ f\n\r\t\v]. |
| \t | Match a tab. Equivalent to \ x09 and \ cI. |
| \v | Match a vertical tab. Equivalent to \ x0b and \ cK. |
| \w | Match letters, numbers, underscores. Equivalent to '[A-Za-z0-9#]'. |
| \W | Matches non letters, numbers, underscores. Equivalent to '[^ A-Za-z0-9_]'. |
| \xn | Match n, where n is the hexadecimal escape value. Hexadecimal escape value must be two digits long. For ex amp le, '\ x41' matches' A '\ x041 'is equivalent to' \ x04 '& "1". ASCII encoding can be used in regular expressions. |
| \num | Match num, where num is a positive integer. A reference to the match obtained. For example, '(.) \ 1' matches two consecutive identical characters. |
| \n | Identifies an octal escape value or a backward reference. If \ n at least n previously obtained subexpressions, then n is a backward reference. Otherwise, if n is an octal digit (0-7), then n is an octal escape value. |
| \nm | Identifies an octal escape value or a backward reference. If at least nm subexpressions are obtained before \ nm, nm is a backward reference. If there are at least n fetches before \ nm, n is a backward reference followed by the text M. If none of the preceding conditions are met, if n and m are octal digits (0-7), \ nm will match the octal escape value nm. |
| \nml | If n is an octal digit (0-3) and both m and l are octal digits (0-7), the octal escape value nml is matched. |
| \un | Match n, where n is a Unicode character represented by four hexadecimal digits. For example, \ u00A9 matches the copyright symbol (?). |
Turn from Original address . The list is very detailed. So how should we use it in Java? Here I'll give some more common examples:
2. Directly use the string method
At present, the String class supports the following regular methods:
. replaceAll() replace all
. replaceFirst() replaces the first
. split() splits strings into arrays
. matches() determines whether the string matches the given pattern
I'll take some common metacharacters with me, for example:
@Test
public void test2(){
// . A. represents an arbitrary symbol, so four points match four
System.out.println("a4^-".matches("....")); //true this sentence means to match four arbitrary characters
// -Indicates the range, such as a-z 0-9
// [] character set matches any character contained in it. For example, [0-9] matches any number from 0-9
System.out.println("h".matches("a-z")); //false this sentence is written directly to indicate juxtaposition of a or - or z
System.out.println("h".matches("[a-z]")); //true indicates any character in []
// ^$indicates the beginning and end
System.out.println("a4^-".matches("^....$")); //true
// *The value length range indicates 0 to more than {0,} is a quantifier
System.out.println("a4^-".matches(".*")); //true this sentence means to match any symbol of any length
// +The value length range indicates 0 to more than {1,} is a quantifier
System.out.println("123".matches("[0-9]+")); //true this sentence means that at least one number is matched
System.out.println("abc".matches("[0-9]+")); //false
// ? The value length range indicates that 0 to more {0,1} belong to quantifiers
System.out.println("8".matches("[0-9]?")); //true this sentence means to match 0 or 1 numbers
System.out.println("88".matches("[0-9]?")); //false two, out of range
// {m,n} value length range m to n
System.out.println("12345".matches("[0-9]{4,8}")); // true indicates that the length of the number is between 4-8
System.out.println("123".matches("[0-9]{4,8}")); // False is not in range
// \d the number is the same as [0-9]
// \D non numeric
System.out.println("123".matches("\\d+")); //true note that two \ \ are used here because a single \ is an escape character in Java
System.out.println("abc".matches("\\D+")); //true
//Example: judge whether there are numbers in the string
System.out.println("zdjghj9jd".matches(".*\\d+.*"));//true before and after. * because we are not sure about the number of characters before and after
// |Or followed by the character to match
//Example: judge whether the string is
System.out.println("123".matches("[0-9]+|[a-z]+")); //true
System.out.println("abc".matches("[0-9]+|[a-z]+")); //true
System.out.println("abc123".matches("[0-9]+|[a-z]+")); //false
// ^Note that putting it in the character set means negation
System.out.println("abc".matches("[0-9]+")); //false
System.out.println("abc".matches("[^0-9]+")); //true is the same as \ D +
// () grouping operation
System.out.println("food".matches("(f|z).*")); //true
System.out.println("zood".matches("(f|z).*")); //true
System.out.println("hood".matches("(f|z).*")); //false
//In addition, you need to remember the format of Chinese characters \ u4e00-\u9fa5
//For example: judge whether there are Chinese characters in the string
System.out.println("abhhj Would be better hu".matches(".*[\\u4e00-\\u9fa5]+.*")); //true
}
In the above examples, I use matches as an example. Next, I will briefly give examples of the other three methods:
@Test
public void test3() {
//split()
//For example: divide the following string into an array according to numbers without retaining numbers
String s = "abc123hello6world101java";
String[] ss = s.split("\\d+");
System.out.println(Arrays.toString(ss)); //[abc, hello, world, java]
//replaceAll() replaces all
//Example: replace all consecutive numbers in the string with "java"
String s1 = "hello123c++456world789python";
System.out.println(s1.replaceAll("[\\d]+","java")); //hellojavac++javaworldjavapython
//replaceFirst() replaces the first
String s2 = "javajavajava";
System.out.println(s2.replaceFirst("java","hello")); //hellojavajava
}
3. Use Pattern and Matcher classes
For Java, the use of regular expressions must be inseparable from classes. We generally use Pattern and Matcher. Through these two classes, we can easily use regular expressions.
His general format is as follows:
@Test
public void test4() {
String s = "123abc";
Pattern p = Pattern.compile("[0-9a-z]+"); //Compile a regular
Pattern p2 = Pattern.compile("[0-9a-z]+", Pattern.CASE_INSENSITIVE); //Compile a regular. The second argument is case insensitive
Matcher m = p.matcher(s); //Pass in a string to match the regular. The result is stored in the Matcher object. We can manipulate the result through its methods
}
If the second parameter is passed in during Pattern compilation, it is equivalent to that we have specified a modifier. We can choose from (content from API documents):
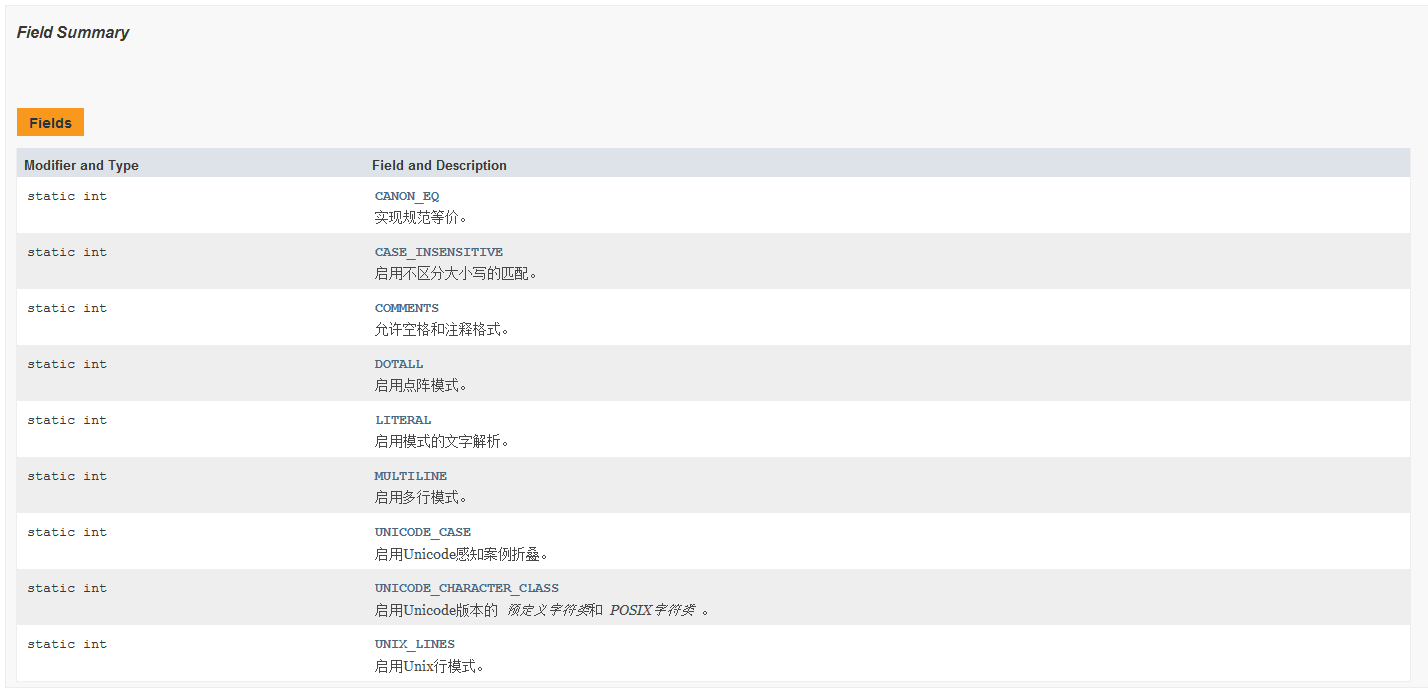
After we get the results through the Matcher class, it also provides us with some methods for us to use. The common methods are as follows:
matches() attempts to match the entire region to the pattern.
find() attempts to find the next subsequence of the input sequence that matches the pattern.
group() returns the input subsequence that matches the previous one.
The find() method is often used in conjunction with group(). The following examples are used one by one:
@Test
public void test5() {
//matches() attempts to match the entire input sequence to the pattern
//Example: determine whether there are numbers in a String. The usage is similar to that of String matches()
String s = "abd56jgh";
Pattern p = Pattern.compile(".*\\d.*");
Matcher m = p.matcher(s);
System.out.println(m.matches()); //true
//find() and group()
//Example: find all consecutive letters in the string and output them
String s1 = "123java%&^hello687*&^email _python";
Pattern p1 = Pattern.compile("[a-z]+", Pattern.CASE_INSENSITIVE);
Matcher m1 = p1.matcher(s1);
while (m1.find()) {
System.out.println(m1.group());
// java
// hello
// email
// python
}
}
4. Greedy mode and disable greedy
What is the greedy model? In short, when we match strings, we match them according to the maximum length as much as possible. Generally, the default is greedy mode. For example, I have such a string:
@Test
public void test6() {
//For example: filter out the contents contained in the < div > < / div > tag
String s = "<div>hello</div><html>hello</html><div>hello 15</div>";
Pattern p = Pattern.compile("<div>(.*)</div>");
Matcher m = p.matcher(s);
while(m.find()){
System.out.printf("%s\t",m.group(1));
// hello</div><html>hello</html><div>hello 15
}
}
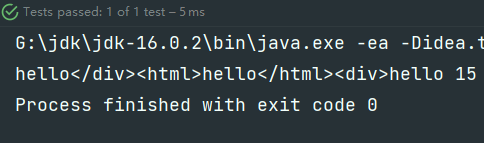
You can see that the program intercepts the div at the outermost layer directly, but this is not what we want. What we want is to intercept every small div inside. This is because the program follows the greedy mode by default, that is, it can intercept the large, not the small.
So how to disable greedy mode?
The so-called disable greedy mode is non greedy mode, which is also called lazy mode in some places. But what he expressed is the same, that is, he can intercept the small, not the big.
So how? We also take the above example:
@Test
public void test6() {
//For example: filter out the contents contained in the < div > < / div > tag
String s = "<div>hello</div><html>hello</html><div>hello 15</div>";
Pattern p = Pattern.compile("<div>(.*)</div>"); //Greedy model
Matcher m = p.matcher(s);
while(m.find()){
System.out.printf("%s\t",m.group(1));
// hello</div><html>hello</html><div>hello 15
}
System.out.println();
Pattern p1 = Pattern.compile("<div>(.*?)</div>"); //Disable greedy mode
Matcher m1 = p1.matcher(s);
while(m1.find()){
System.out.println(m1.group(1));
//hello
//hello 15
}
}
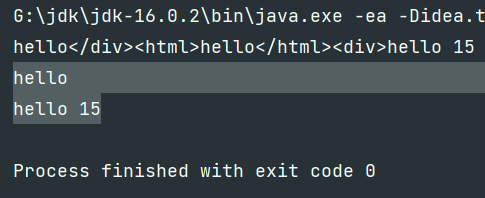
It's easy to add?, after the length you want to match?, You can disable greed
be careful:
? Be sure to add it after the quantifier, otherwise? Means {0,1}
5. Advantages and disadvantages
Is regular really so versatile? Since regularization is so convenient to use, does it give priority to regularization when dealing with all string related problems in the future?
Obviously not.
In fact, with the increasing update of the system, sometimes the use of regular will slow down the running speed of our program. Greedy matching symbols such as. * are easy to cause a lot of backtracking, and sometimes the performance will be degraded by millions of times.
So under what circumstances should we use it?
We know that regularization gives us a pattern through which we can match strings. For example, if we want to search for a name, we only know his surname is Li, and we don't know his name. At this time, it's certainly convenient to use regular rules, but if we clearly know that this person's name is "Li Si", wouldn't it be more convenient to use indexOf()? It's not easy to make mistakes.
And regularization is not very applicable in some situations. For example, I want to judge whether a person's age is between 18 and 30, which is very troublesome through regularization.
In short, regularization just provides us with a way to solve problems, so that we can be surprisingly efficient in some situations, and we don't have to overuse it. Specific problems need to be analyzed in detail.
This article only expresses personal views. If there are any mistakes, please correct them in the comment area. Let's discuss and study together.