In jdk 1. * version, the main containers are vector (implementing List interface) and hashtable (implementing Map interface). With the evolution of jdk version, in order to deal with transactions in high concurrency environment, jdk later added some containers suitable for high concurrency; Now let's follow the footsteps of history to explore the containers in java and understand why the implementation of some containers has faded out of our vision;
collection interface
API for collection
Inheritance implementation relationship ---- > > >
public interface Collection extends Iterable
 Methods in interface ----- > > >
Methods in interface ----- > > >
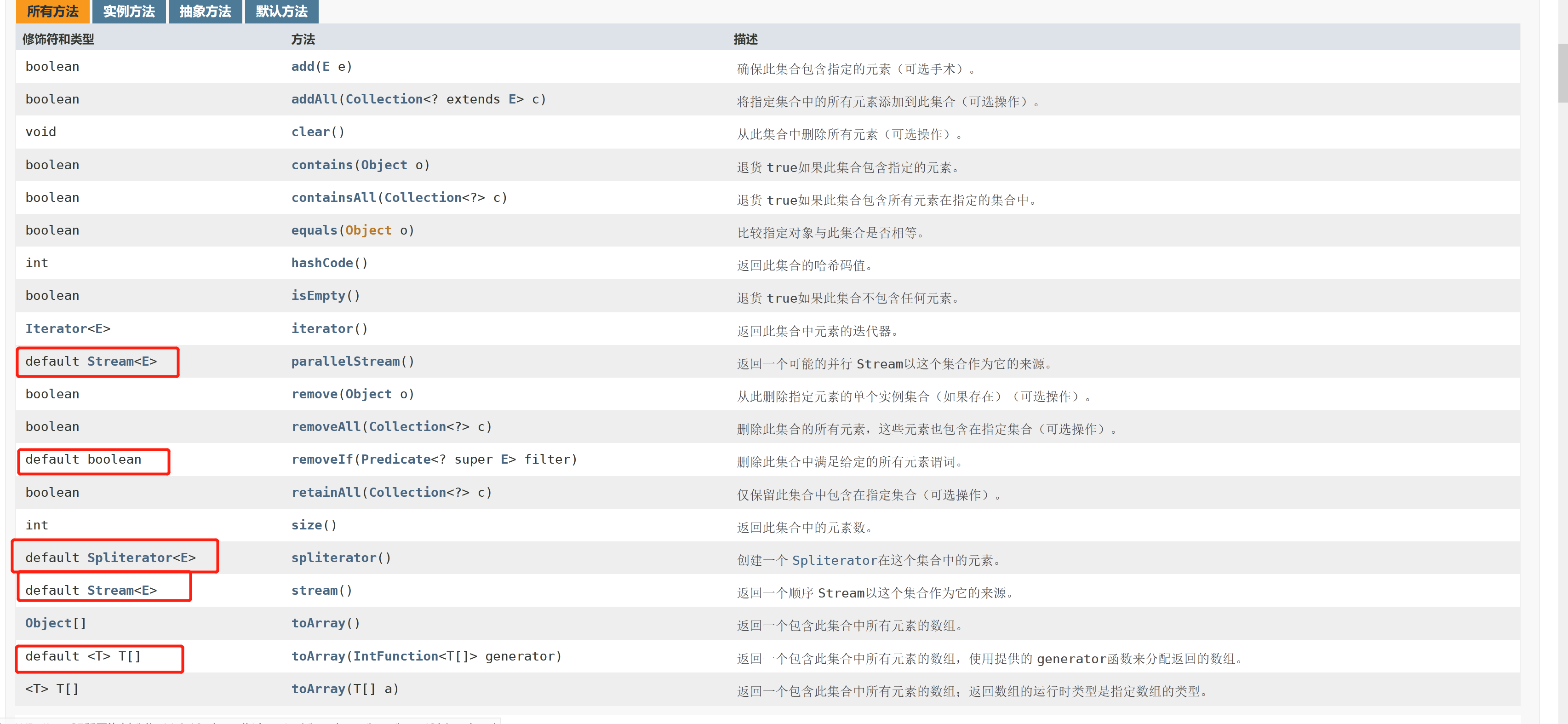
There are many implementation classes under this interface,
According to the characteristics of storage:
Store a List,Set and Queue,
map for storing key value pairs
According to inheritance and implementation relationship:
List
Set
Queue
Map
Don't worry, one by one: first look at the root interface of the container - > > > collection interface
Description of the interface ----- >
The root interface in the collection hierarchy. A collection represents a Set of objects, called its elements. Some collections allow duplicate elements, while others do not. Some are orderly and some are disordered. JDK does not provide any direct implementation of this interface: it provides the implementation of more specific sub interfaces (such as Set and List). This interface is typically used to pass collections and manipulate them where maximum versatility is required.
Default method in Collection interface ------ > >

For the default method, subclasses can choose to implement it or not;
List interface
Implementation class of list interface ----- > > >
From the earliest vector and stack to ArrayList,LinkedList.CopyOnWriteList
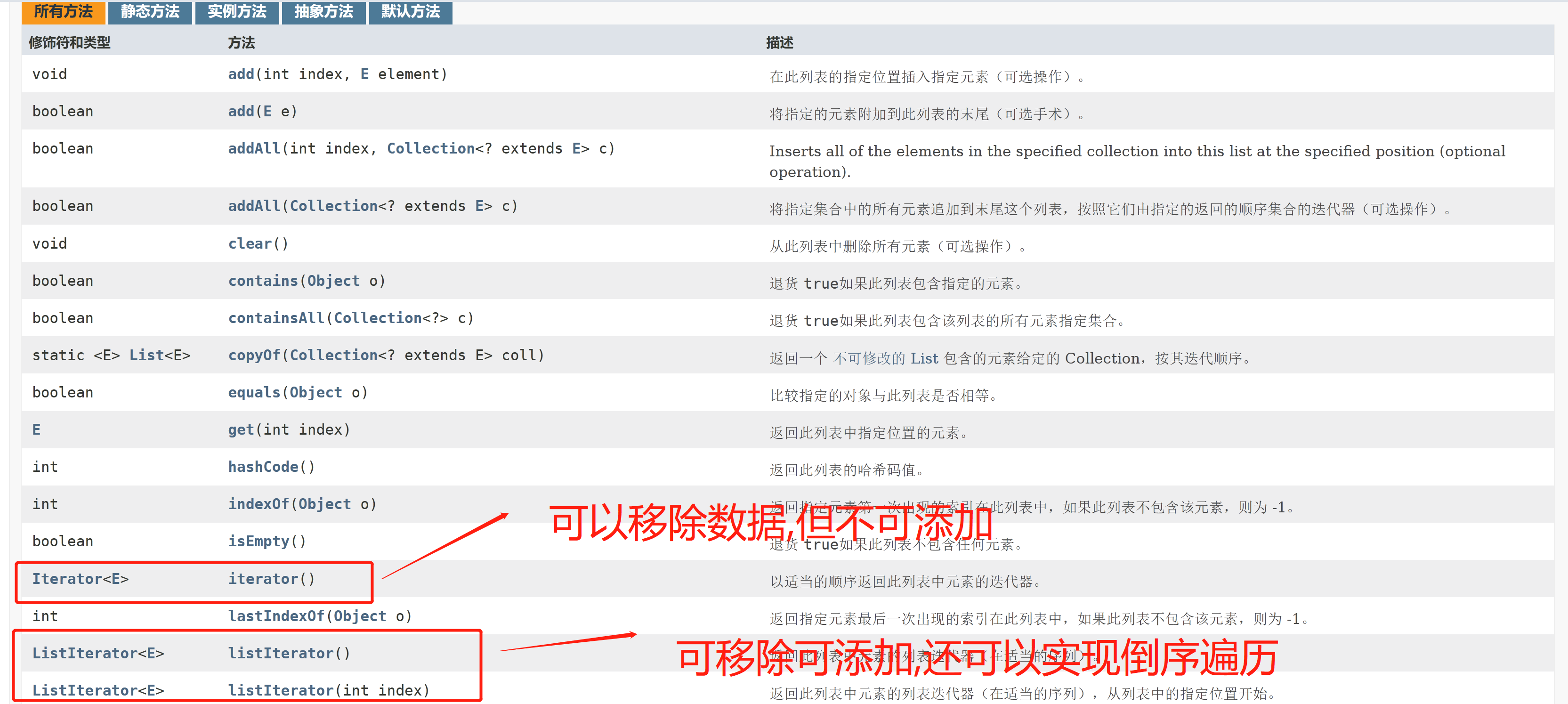
 Static methods in List ------ > > >
Static methods in List ------ > > >
import java.util.List;
public class ListDemo {
public static void main(String[] args) {
List<String> he = List.of("Hello");
he.add("hello");
he.forEach(s -> {
System.out.println(s);
});
}
}
You can see that the of method returns a List collection that cannot be modified;
Exception in thread "main" java.lang.UnsupportedOperationException
Vector and its subclass Stack
Vector
import java.util.Collection;
import java.util.Iterator;
import java.util.Vector;
import java.util.stream.Stream;
class Person{
String name;
public Person(String name) {
this.name = name;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
'}';
}
}
public class Vector_1Demo {
public static void main(String[] args) {
/* If no capacity is specified, it defaults to 10 and the growth factor is 0*/
Collection<Person>c=new Vector<>(100,12);
c.add(new Person("Zhang San"));
c.add(new Person("Li Si"));
System.out.println(c.size());
/* Vector Iterators are supported, but subscript access is not supported;*/
for (Person per:
c ) {
System.out.println(per);
}
Iterator<Person> iterator = c.iterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
//For stream operation, you can check the API if you are interested
Stream<Person> personStream1 = c.parallelStream();
personStream1.forEach(person -> System.out.println(person));
Stream<Person> personStream = c.parallelStream();
personStream.forEach(person -> System.out.println(person));
}
}
Look at API - > >
Inheritance and implementation relationship of Vector
public class Vector extends AbstractList
implements List, RandomAccess, Cloneable, Serializable
Description: the Vector class implements a growing array object. Like an array, it contains components that can be accessed using integer indexes. However, a size Vector can be increased or reduced as needed to accommodate the addition and deletion of items
There is no need to say more about the methods in the class. Focus on the following two points----
Construction method ---- > >
Class construction----
 Intercepting part method ----- >
Intercepting part method ----- >
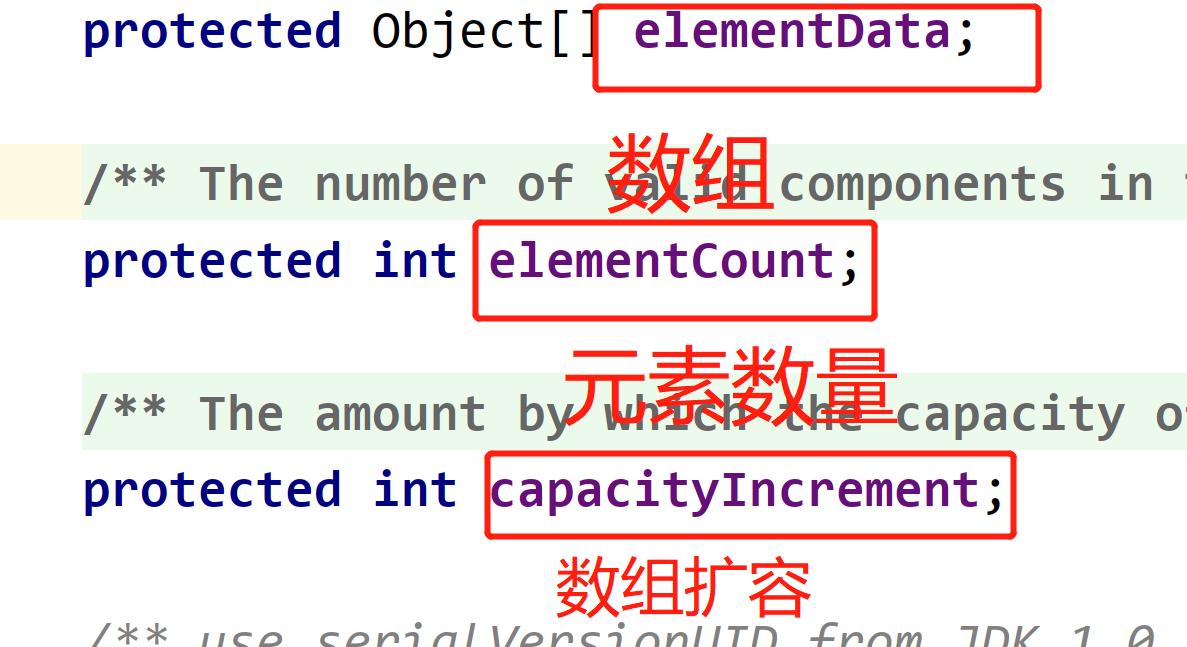
 Underlying structure of Vector ----- > >
Underlying structure of Vector ----- > >
Vector maintains three variables------
Object[] elementData -------- array
Int elementcount ------ > > number of elements
Int capacityincrement - > > > capacity expansion
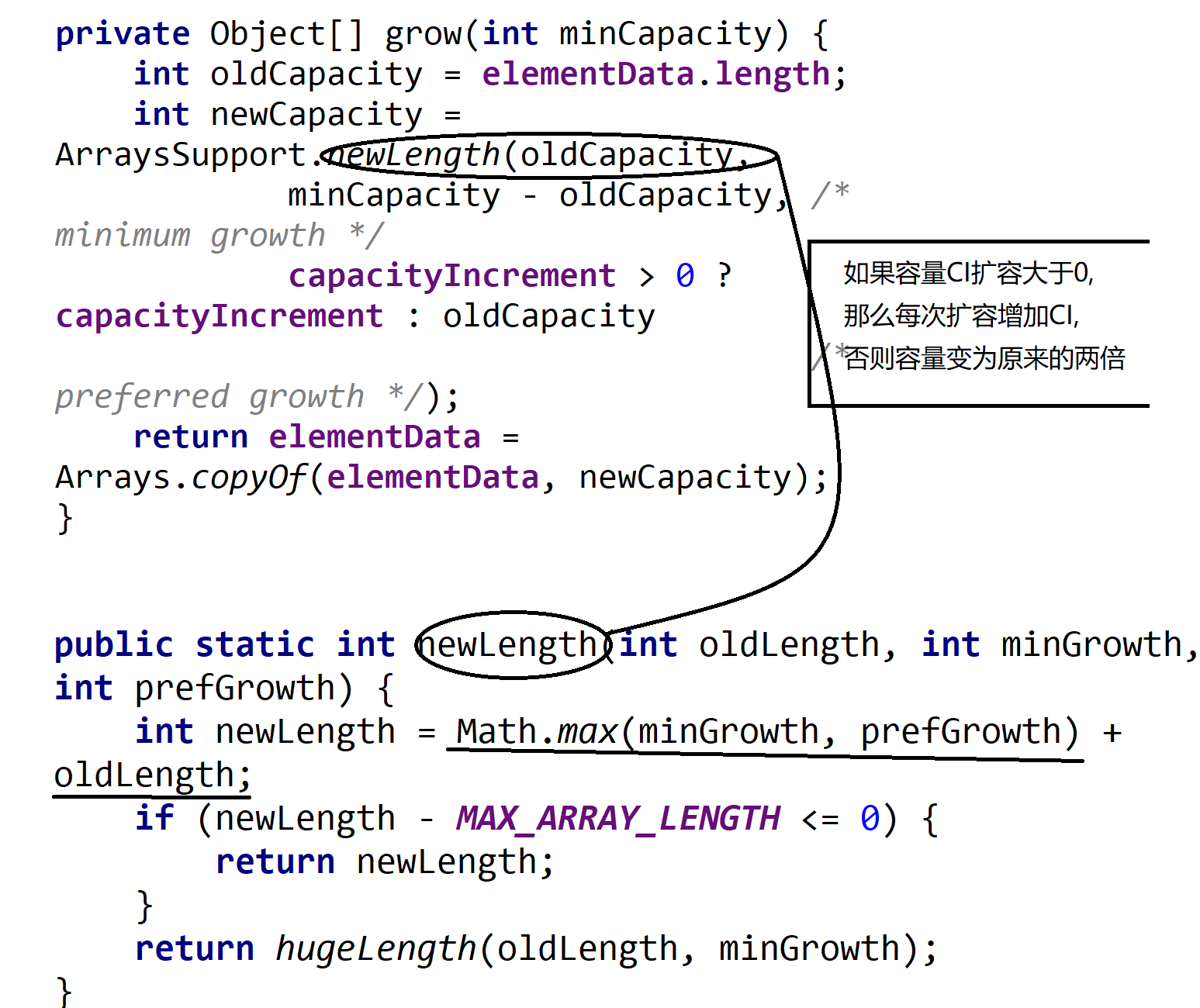
Capacity expansion mechanism of Vector - > > >
1. If the initial capacity and capacity expansion are specified through the construction method, when the capacity is insufficient, the Vector will be expanded to the old length + expansion length
2. If the expansion capacity is not specified, the capacity becomes twice that of the expansion
Most methods in the Vector class are locked, so adding or removing elements in high concurrency is not as efficient as ArrayList;
Stack class
public class Stack extends Vector
Description ----- > >
This Stack class represents a Stack of last in first out (LIFO) objects.
When you first create a stack, it does not contain any items.
Deque interface and its implementation provide a more complete and consistent set of LIFO stack operations, which should take precedence over such use. For example:
Deque stack = new ArrayDeque();
import java.util.Stack;
public class StackDemo {
public static void main(String[] args) {
Stack<Integer>stack= new Stack<>();
stack.add(10);
stack.add(88);
stack.add(99);
stack.add(111);
stack.add(88);
Integer peek = stack.peek();//View the top element of the stack without removing it from the stack;
System.out.println("A-Stack top element"+peek);//111
System.out.println("B-Stack top element"+stack.push(4444));//Press 4444 into the top of the stack
Integer pop = stack.pop();
System.out.println("Remove stack top element"+pop);
System.out.println("Check the stack top element at this time--"+stack.peek());
System.out.println("88 Location of stack--"+stack.search(88));//Returns the position of the object on this stack starting from 1.
}
}
Summary ----- > > > >
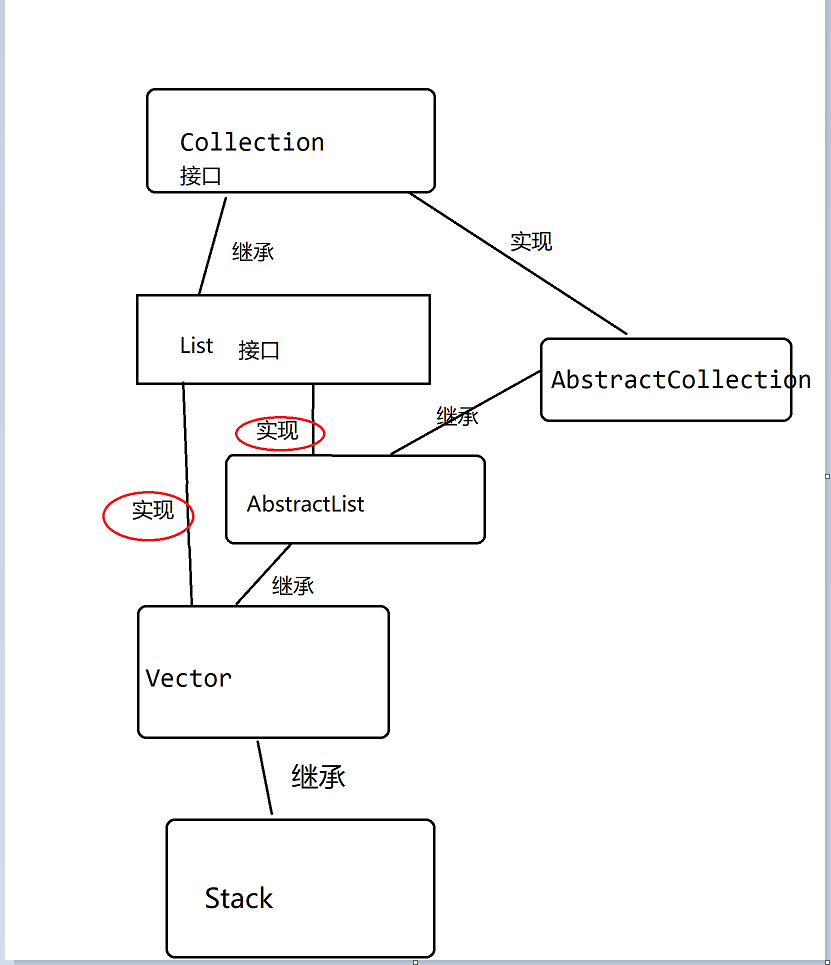 For historical reasons, you will find that some containers implement the same interface many times. For example, Vector inherits AbstractList, while AbstractList implements List, but Vector also implements the List interface;
For historical reasons, you will find that some containers implement the same interface many times. For example, Vector inherits AbstractList, while AbstractList implements List, but Vector also implements the List interface;
ArrayList and LinkedList
ArrayList
public class ArrayList extends AbstractList implements List, RandomAccess, Cloneable, Serializable
Description: resizable array implements the List interface. It is also a List operation and allows all elements, including null. In addition to implementing the List interface, this class provides a method to operate the array size, which is internally used to store the List. (this class is roughly equivalent to Vector, except that it is asynchronous.)
The insertion efficiency of ArrayList is relatively high, and the time complexity of add() method is O(N)
If multiple threads access an ArrayList instance at the same time, and at least one thread has structurally modified the list, it must be synchronized externally. (structure modification is any operation of adding or deleting one or more elements, or explicitly adjusting the size of the backing array; only setting the value of the element is not structure modification.) this is usually done by synchronizing some objects that naturally encapsulate the list. If such an object does not exist, the Collections.synchronizedList method should be used.
List list = Collections.synchronizedList(new ArrayList(...));

import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
ArrayList<Integer>list= new ArrayList<>();
// Make this list a thread safe collection
List<Integer> synList = Collections.synchronizedList(list);
// Asynchronous addition
list.add(0);
// Synchronous addition
synList.add(1);
list.forEach(i->{
System.out.println(i);
});
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//Return the position of the element -- if there are multiple elements, return the first one
System.out.println(synList.indexOf(0));
//Return a shallow copy of the list - that is, it is only a copy of the elements, and the address is different
Object clone = list.clone();
System.out.println(clone);
ArrayList list1=list;//This is a deep copy. Both elements and addresses are copied
}
}
Underlying principle of ArrayList ----- > > > array
Two variables are maintained at the bottom of ArrayList----
transient Object[] elementData;
private int size;

Capacity expansion principle of ArrayList ---- > >
When it comes to the expansion principle, let's first look at the construction method - > >
Do not specify the initial capacity, that is, new ArrayList(), which is the default capacity of 10
 Capacity expansion principle ---- > >
Capacity expansion principle ---- > >
When we create a set with a parameterless construct;
Although the default capacity is 10, it takes effect only when the first element is added;

Summary - > > >
1. Capacity expansion mechanism in ArrayList - capacity expansion is 1.5 times of the original, saving space
2. The method in ArrayList is asynchronous, but it can also be changed into a synchronized List through the Collections tool class

LinkedList
Inheritance implementation relationship:
public class LinkedList
extends AbstractSequentialList
implements List, Deque, Cloneable, Serializable
Description: --- the implementation of bidirectional linked List implements the interface of List and Deque. All elements (including null) are allowed
If multiple threads access a linked list at the same time, and at least one thread modifies the list structurally, it must be external synchronization. (structure modification is any operation to add or delete one or more elements; setting value elements only is not structure modification.) This is usually done by synchronizing some natural objects. If such objects do not exist, the Collections.synchronizedList method should be used. This is best done at creation time to prevent accidental asynchronous access to the list:
List list = Collections.synchronizedList(new LinkedList(...));
Construction method

import java.util.Collections;
import java.util.LinkedList;
import java.util.List;
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList<Integer>linkedList= new LinkedList<>();
List<Integer> lks = Collections.synchronizedList(linkedList);//Synchronous linked list
linkedList.add(0);
lks.add(100);
linkedList.add(0,12);
System.out.println(lks);
System.out.println(linkedList.peek());//Returns the first element
System.out.println(linkedList.peekFirst());
System.out.println(linkedList.peekFirst());//Returns the first element
System.out.println(linkedList.peekLast());//Returns the last element
System.out.println(linkedList.element());//Returns the first element
System.out.println(linkedList.offer(88));//Insert an element at the end of the linked list
System.out.println(linkedList.offerFirst(99));//Insert an element into the head of the linked list
System.out.println(linkedList.offerLast(100));//Insert an element at the end of the linked list
System.out.println(linkedList);
System.out.println(linkedList.poll());//Retrieve and delete the first element and return this element
System.out.println(linkedList.pollFirst());//Retrieve and delete the first element and return this element
System.out.println(linkedList.pollLast());//Retrieve and delete the last element and return this element
System.out.println(linkedList);
linkedList.removeFirst();//Remove first
linkedList.removeLast();//Remove second
}
}
The linked list is inefficient when querying data, because it needs to traverse the whole set, but it is more efficient when inserting data!
Underlying implementation of LinkedList ----- >
The bottom layer maintains a node and its size

The difference between LinkedeList and ArrayList
1. The underlying data structures are different. ArrayList is the data structure of object (dynamic array) and LinkedList is the data structure of node (linked list).
2. ArrayList can query data quickly by subscript because of the time array, while linkedlist queries data by moving the pointer,
3. LinkedList is efficient in adding and deleting data,
No information about the capacity of LinkedList is found in the API - that is, LinkedList does not need to consider the initial capacity, that is, how much is used, and there is no need to reserve capacity;
CopyOnWriteArrayList
Inheritance implementation relationship:
public class CopyOnWriteArrayList extends Object implements List, RandomAccess, Cloneable, Serializable
Description information:
A thread safe variant of ArrayList in which all mutation operations (add, set, etc.) are made by a new copy of the underlying array.
This is usually too expensive, but it may be more effective. It will mutate when the number of traversal operations far exceeds the alternatives. It is very useful for synchronous traversal when you can't or don't want to, but you need to eliminate the interference between concurrent threads.
In short, it is an ArrayList about read-write thread safety
Construction method - > >

import java.util.ArrayList;
import java.util.concurrent.CopyOnWriteArrayList;
public class CopyOnWriteArraylistDemo {
public static void main(String[] args) {
//Create an empty list
CopyOnWriteArrayList<Integer> copy = new CopyOnWriteArrayList<>();
//Thread safe write operation
//Write mutex
copy.add(0);
copy.add(1);
// Read sharing
Integer integer = copy.get(0);
System.out.println("_________________");
ArrayList<Integer> list = new ArrayList<>(10);
list.add(0);
list.add(1);
list.add(2);
list.add(3);
CopyOnWriteArrayList CWASList=new CopyOnWriteArrayList(list);
CWASList.add(100);
System.out.println(CWASList);
Object []objects= new Object[100];
CopyOnWriteArrayList ca=new CopyOnWriteArrayList(objects);
ca.add(999);
System.out.println(ca);
}
}
One advantage of this class is that for high concurrency environments, simultaneous reading does not need to be locked. Reading, writing, reading and writing operations need to be locked, which is similar to the implementation of read-write lock;
First, let's take a look at the add() method of the write operation - > >

In this class, those about adding data are locked with different granularity, and those about reading data are not locked;
Compared with ArrayList, it can achieve thread safety, but if the amount of data is too large, it will cost a lot to the server, because thread safety is realized by modifying the copy, and the original is replaced by this copy;
Set interface
Inheritance implementation relationship - >
public interface Set extends Collection
Description:
A collection that does not contain duplicate elements. More formally, the set does not contain a pair of elements e1 and e2, so that e1.equals(e2) and at most one empty element.
Some collection implementations in the implementation class of this interface have restrictions on the elements they may contain. For example, some implementations prohibit empty elements, while others restrict the types of their elements.
The Set.of and Set.copyOf static factory methods provide a convenient way to create immutable sets. The Set instances created by these methods have the following characteristics:
- They are not modifiable. You cannot add or remove elements. Calling any mutator method on a Set will always result in a throw
UnsupportedOperationException. - If the contained element itself is variable, this may cause the behavior of the Set to be inconsistent or its content to appear to have changed.
- They do not allow empty elements. Attempting to create them with empty elements will result in NullPointerException.
- If all elements are serializable, they are serializable.
- They reject duplicate elements when they are created. Duplicate elements passed to static factory methods result in IllegalArgumentException
Methods in interface ----- >
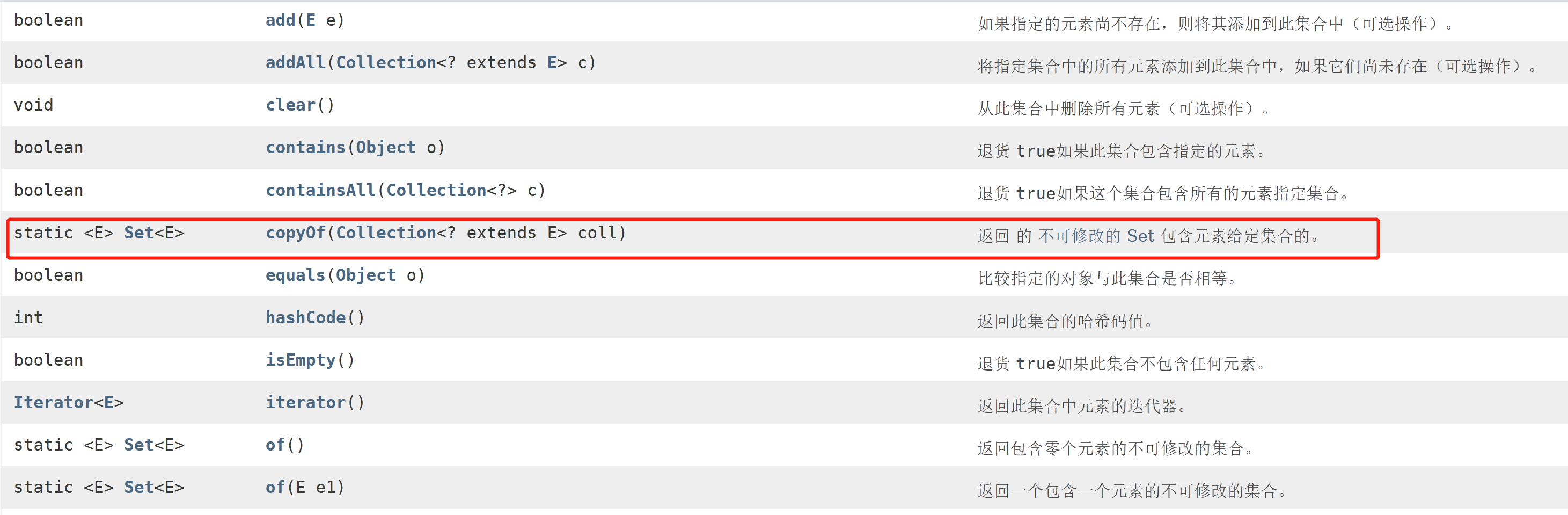

HashSet and its subclass LinkedHashSet
HashSet
Inheritance implementation relationship ------ > >
public class HashSet extends AbstractSet
implements Set, Cloneable, Serializable
Description:
This class implements the Set interface, which is supported by the hash table (actually a HashMap instance). It does not guarantee the iterative order of the Set; In particular, it does not guarantee that orders will remain unchanged over time. This class allows null elements.
This implementation is not synchronized. If multiple threads access the hash set at the same time, and at least one thread has modified the hash set, you must synchronize externally. This is usually achieved by synchronizing on an object in a natural encapsulation set. If there are no such objects, the collection "wrapper" should be used. Synchronous set method. It is best to do this at creation time to prevent accidental asynchronous access to the set:
Set s = Collections.synchronizedSet(new HashSet(...));
Construction method:
 A HashMap is maintained at the bottom of the HashSet,
A HashMap is maintained at the bottom of the HashSet,
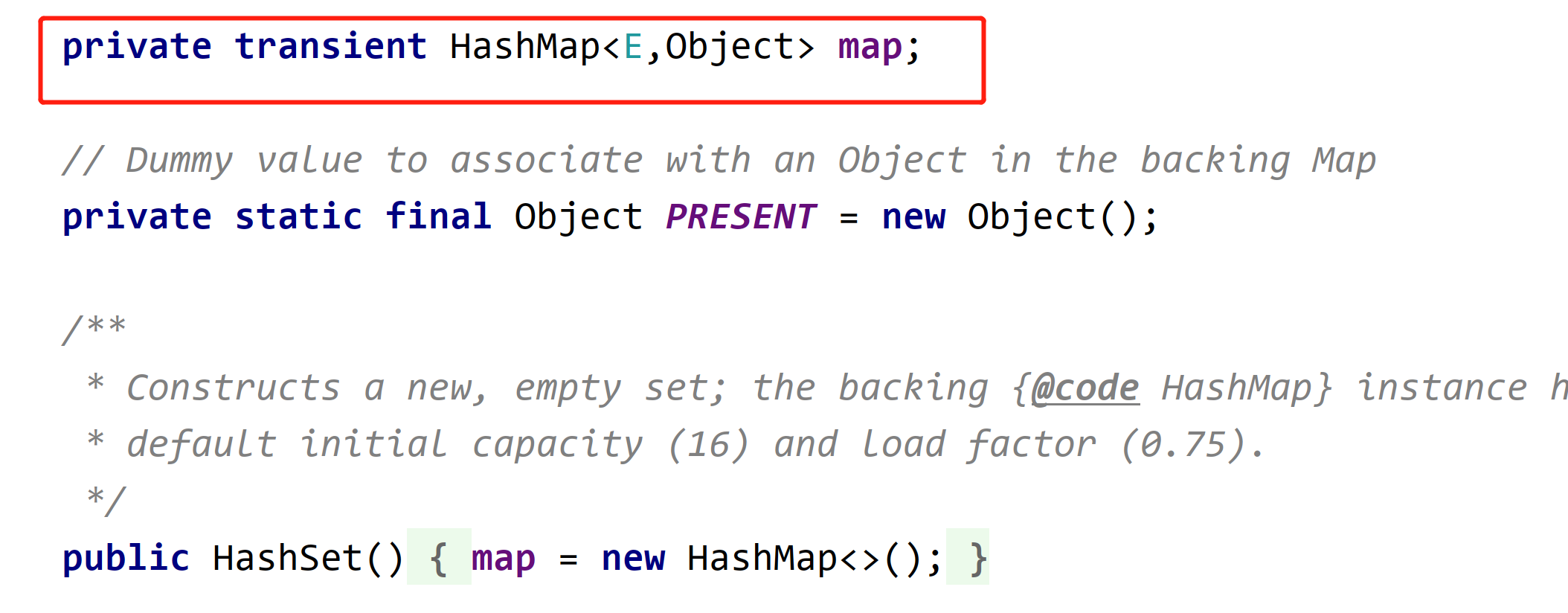
import java.util.HashSet;
import java.util.Set;
public class HashSetDemo {
public static void main(String[] args) {
//Nonparametric construction - default 16, loading factor 0.75
Set<Integer>set= new HashSet<>();
set.add(1);
set.add(6);
set.add(1);
set.add(null);
set.add(2);
System.out.println(set);//[null, 1, 2, 6] - indicates that the following repeated elements are automatically filtered out and arranged in ascending order
//Only the initial capacity is specified, and the loading factor is still 0.75 by default
Set<Integer>set1= new HashSet<>(8);
//Specify the initial capacity and the load factor
Set<Integer>set2= new HashSet<>(8,1);
}
}
HashSet capacity initialization analysis - > > >

How does a hashSet have no duplicate elements?

The addition order of HashSet is unordered, that is, it is not displayed in the order we added;
For example, the following code ------ > >
public class HashSetDemo {
public static void main(String[] args) {
//Nonparametric construction - default 16, loading factor 0.75
Set<Integer>set= new HashSet<>();
set.add(9);
set.add(6);
set.add(5);
set.add(7);
set.add(8);
set.add(7);
System.out.println(set);
//Only the initial capacity is specified, and the loading factor is still 0.75 by default
Set<Integer>set1= new HashSet<>(8);
//Specify the initial capacity and the load factor
Set<Integer>set2= new HashSet<>(8,1);
}
}

Summary HashSet:
1. The bottom layer is implemented through hashmap, but the key in the key value pair is used;
2. The capacity expansion mechanism is (nonparametric structure). Capacity expansion starts when capacity = threshold, and each expansion is twice the original;
Why is the default load factor 0.75?
When the loading factor is too small, the probability of hash collision will increase, which makes the data distribution uneven; When the loading factor is too large, there will be a waste of space, so go to a compromise value of 0.75;
LinkedHashSet
Inheritance implementation relationship ---- >
public class LinkedHashSet
extends HashSet implements Set, Cloneable, Serializable
Description:
The implementation Set interface of hash table and linked list has a predictable iterative order. This implementation is different from HashSet because it maintains a two-way linked list through all its entries. This linked list defines the iterative order, which is the order in which elements are inserted into the collection (insertion order).
Note that the insertion order does not affect if an element is reinserted into the collection. (an element e is re inserted into a collection s if s.contains(e) is called when s.add(e) is invoked, true will be called back before it is called.
Note that this implementation is not synchronized. If multiple threads access a linked hash set at the same time, and at least one thread modifies the set, it must be external to synchronization. This is usually done by synchronizing some objects that naturally encapsulate the collection. If such an object does not exist, the Collections.synchronizedSet method should be used. This is best done at creation time to prevent accidental asynchronous access to the collection:
Set s = Collections.synchronizedSet(new LinkedHashSet(...));
Underlying implementation principle - > > >
Hash table and bidirectional linked list
Constructor ----- > has the same form as HashSet;

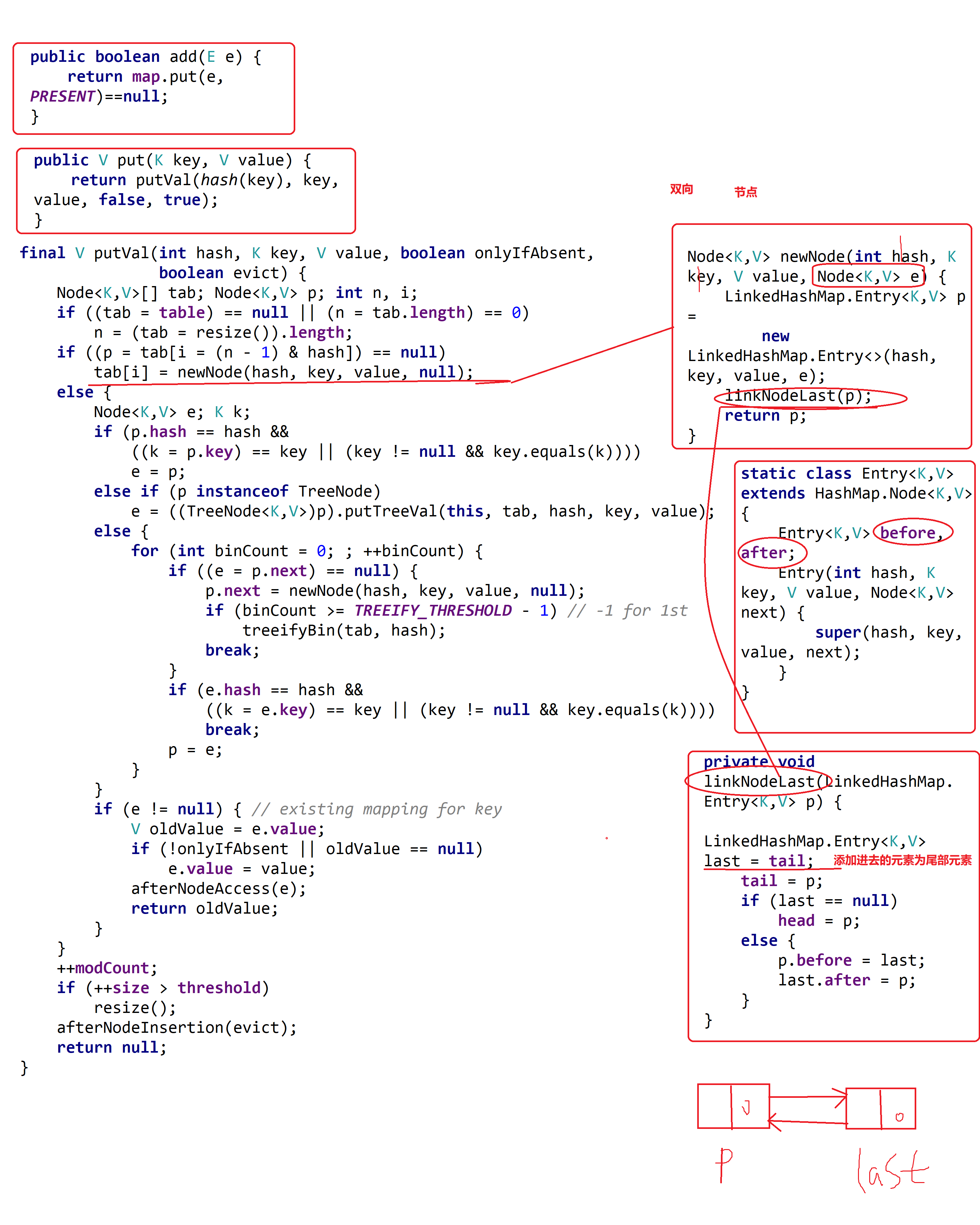 Except for the two-way linked list, other aspects are basically the same as HashSet;
Except for the two-way linked list, other aspects are basically the same as HashSet;
Summary:
1. The elements in the linkedhashset are ordered because each element can be found in the form of a two-way linked list;
2. The bottom layer is still hashMap, and a linked list is maintained on the basis of HashSetde; It is realized by hash table and bidirectional linked list
Unfinished to be continued;