##On the self-cultivation of a reptile 2
(the first example uses Python to download a cat, and the second example uses Python to simulate the browser's text translation through online Daoist translation.)
##Download a cat in Python
http://placekitten.com/ , this website is a customized site for Maonong. You only need to add / width / height at the back of the website to get a picture of the corresponding width and height of the cat. These pictures are all in JPG format, you can simply save them to the place you want to save by right clicking.
Add / width / height after point in connection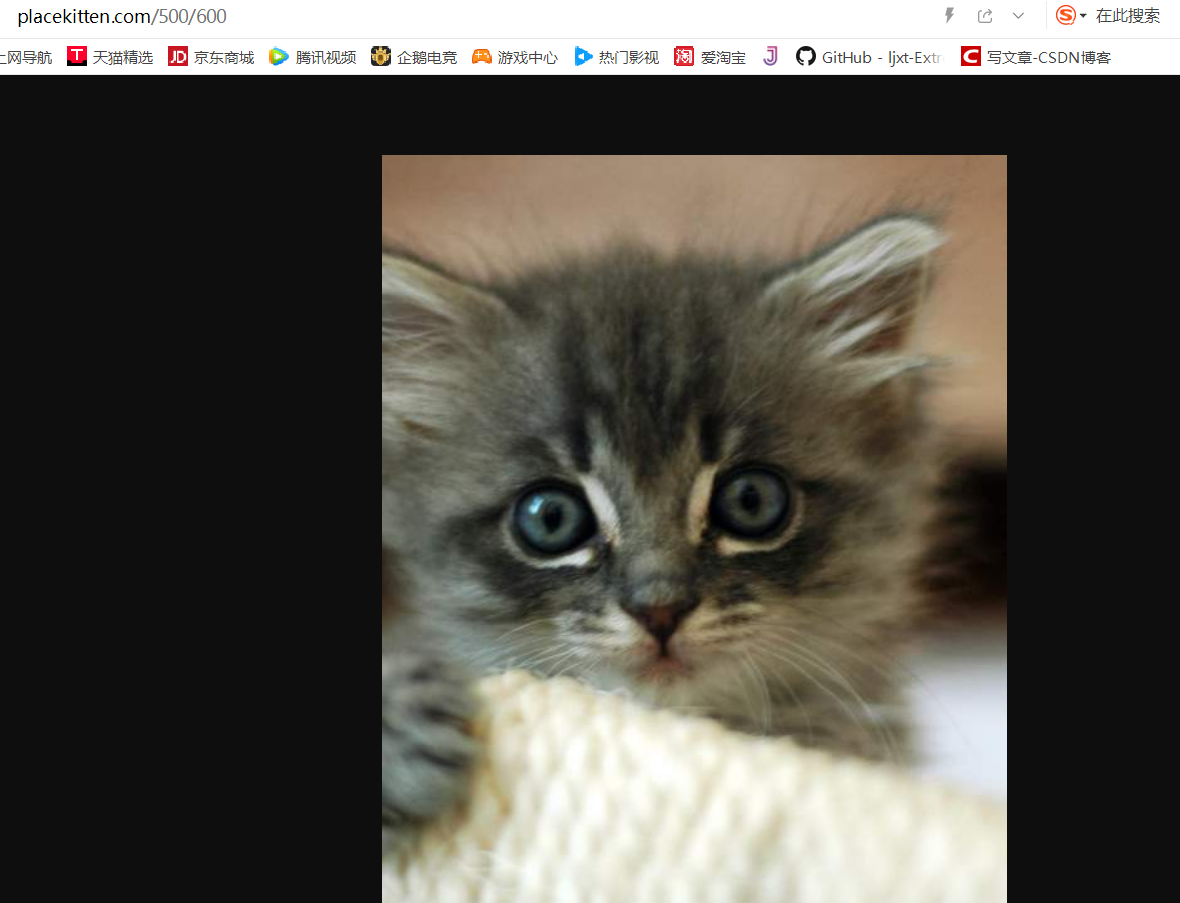
Download to desktop
(the following is to use Python to implement the operation of loading cat pictures from that website, as follows:)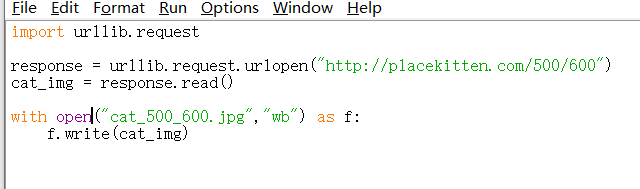

Parsing the code: first, import the request module under the urllib package, then call his urlopen function. The url parameter can be a string or Request object. In fact, in the above program, the address string is imported, but it automatically converts the address string to the Request object and then sends the object to urlopen(). At the end of this line, the content of the whole page is obtained, but the objects need to be read with the read() function. What they return is a string in binary form. When performing file operation, the first parameter is the name of the file, that is, the name of the picture. The second parameter is written to the file in binary form because cat_img is in binary form After the line is successful, it will be downloaded in the folder of your. py source program, which is the current folder of this program.)
(just mentioned that the url parameter can be a string or a Request object. If you pass in a string address, it will automatically convert it to a Request object. The above code is equivalent to:)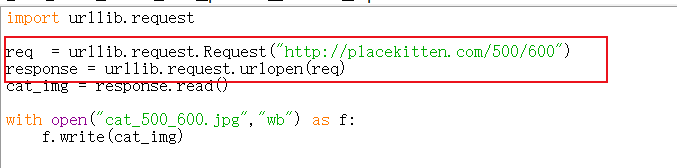
(in addition, the response returned by the urlopen() function is actually an object. This object is a class file, which is very similar to the file object, so you can use the read() method to read the content.)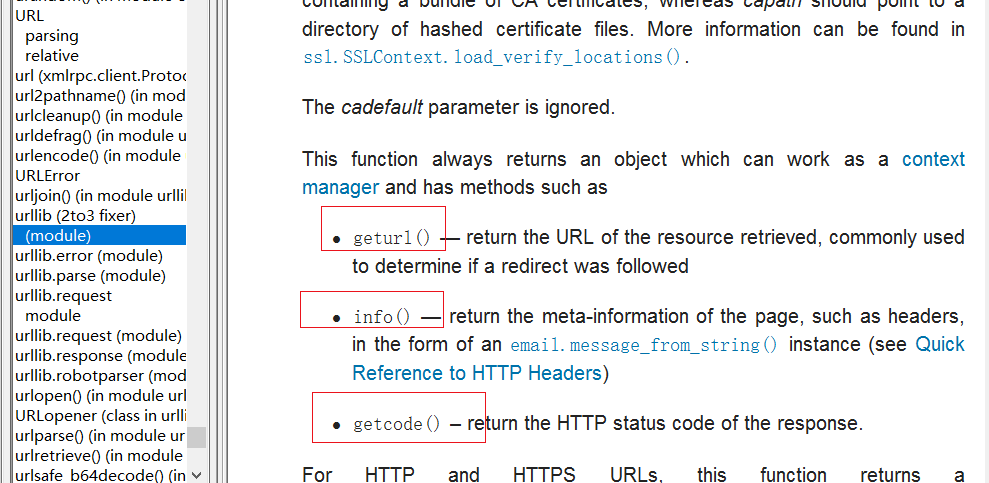
(from the document point of view, in addition to the read() method, you can also use the geturl(), info(), and getcode() methods. After running the program just now, it is as follows:)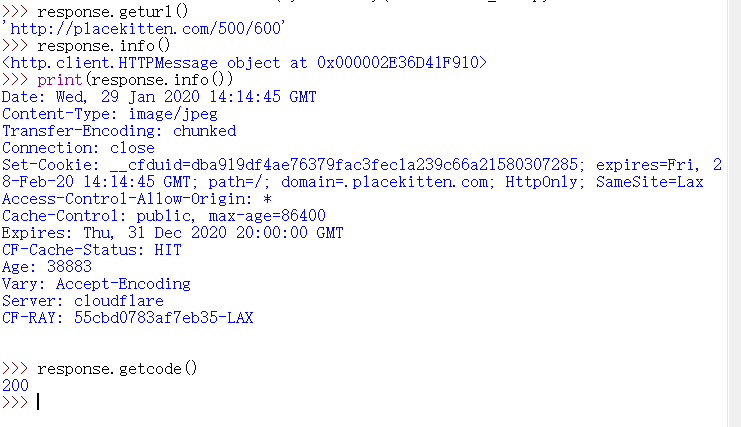
(mainly speaking of the second info(), this method returns an HTTPMessage object, which can be seen by printing out is the head header information returned by the server, and 200 represents the successful status code.)
##Using Python to simulate browser to translate text through online Daoist translation
(here is how to operate on the browser)
(first press F12 to open the review element function, and then click Network. When you click translate, many requests to the server will be displayed below, and the contents of Headers will be analyzed.)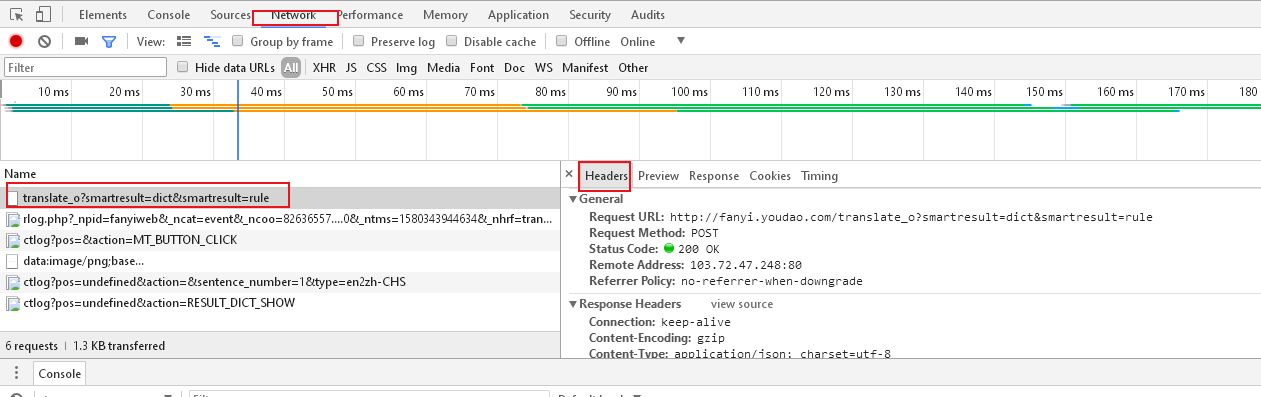
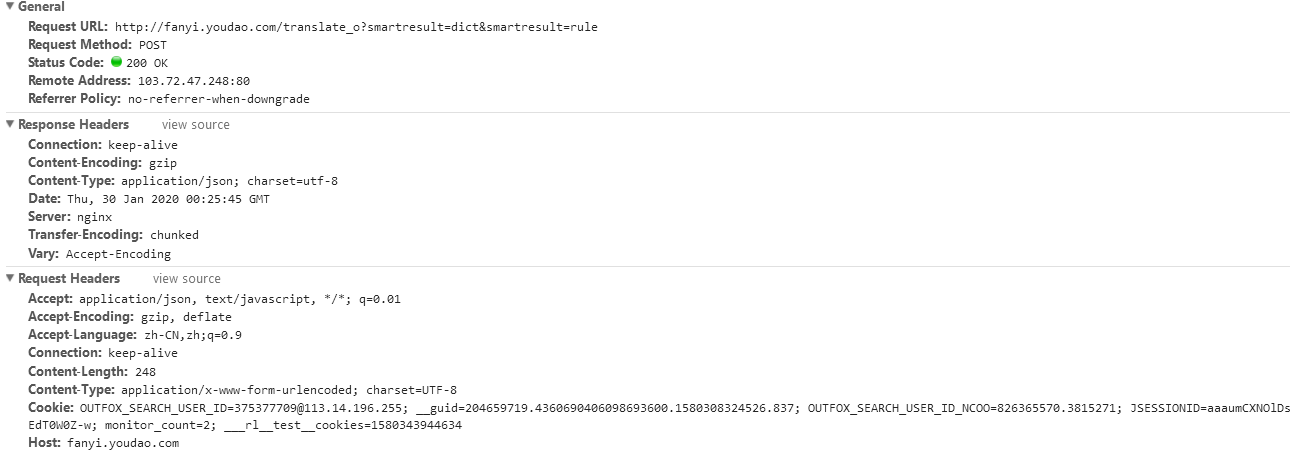
※Request URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule:
(some people think that the urlopen() function should open http://fanyi.youdao.com/ This address, in fact, is not. In fact, what is embedded inside is the previous address. The translation mechanism is here. This address can be translated.)
※Request Method:POST
(the method of the request is in the form of post. There are seven ways to request in HTTP protocol. There are two common ways: get and post. If you want to know the difference between them, please go to – > HTTP Request Message )
※Status Code:200 OK
(status code 200 indicates normal response. If it's 404, the page resource can't be found, maybe the url is wrong, or there is no such resource. To learn more about status codes, go to - > HTTP response message , or you can go to Baidu status code directly, there will be different situations corresponding to various status codes)
※Remote Address:103.72.47.248:80
(this is the ip address of the server, plus the port number he opened)
※Resquest Headers:
(request headers: it's the customer service terminal (now it's the browser, which is our code when using Python code) that sends the request header. The server often judges whether non-human access is possible. So, some people are relatively bad. Write a Python code, and then use this code to batch and continuously access the data of the website, so that Child, the pressure of the server is very big, so, the server is generally not welcome non-human access.
In general, we use the user agent request header in the request headers to identify whether it is browser access or code access. We can see that in fact, the browser tells the server that I access the version information of the browser you are using. If you use Python access, the user agent defaults to Python URL 3.8, which is used to prevent As soon as firewall recognizes that the access is actually from code, not from browser, it may block you, but this user agent can be customized. The next article will show you how to hide it,
Then if you want to know other common request headers except user agent, please call - > HTTP request header)
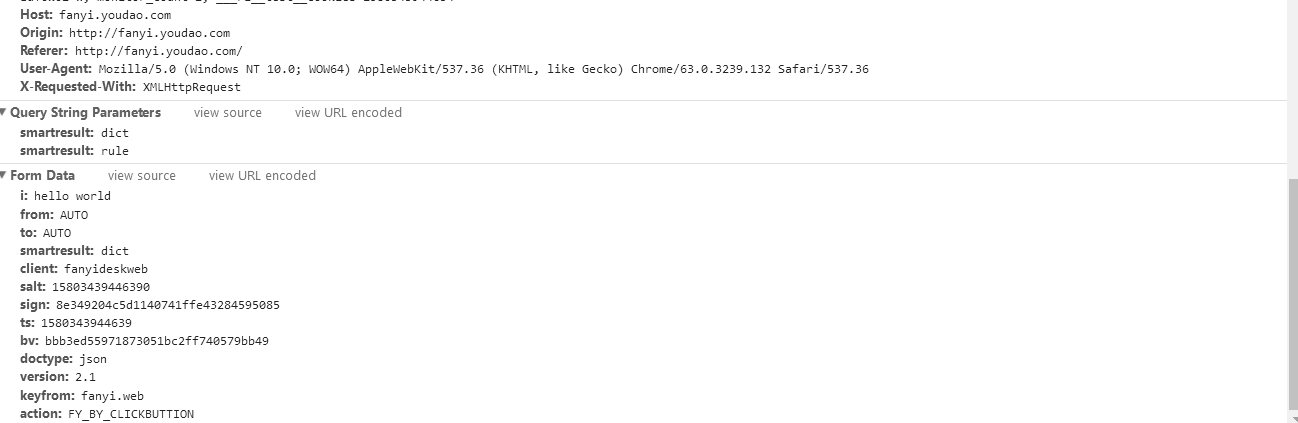
※Form Data:
(the form data, in fact, is the main content submitted by our post. Here i see the submitted content to be translated. How to submit the post form with python? Look at the document.)

(the data parameter must be based on the application/x-www-form-urlencoded format, and then we can use the urllib.parse.urlencode() function to convert the string to the desired form. )
import urllib.request import urllib.parse # From Request URL:Copy it. hold_o Deleted url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" # Data is the Form Data. Copy the contents of Form Data data = {} data['i'] = 'hello world' data['from'] = 'AUTO' data['to'] = 'AUTO' data['smartresult'] = 'dict' data['client'] = 'fanyideskweb' data['salt'] = '15803439446390' data['sign'] = '8e349204c5d1140741ffe43284595085' data['ts'] = '1580343944639' data['bv'] = 'bbb3ed55971873051bc2ff740579bb49' data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom'] = 'fanyi.web' data['action'] = 'FY_BY_CLICKBUTTION' #Using urllib.parse.urlencode()Function to convert a string to the desired form #Convert Unicode file format to uf-8Code form of data = urllib.parse.urlencode(data).encode('utf-8') response = urllib.request.urlopen(url,data) #Use uf when decoding-8To decode html = response.read().decode("utf-8") print(html)

(the result is OK, but it's for programmers to see. If it's for users, they may not be able to see it, and they think it's an error. In addition, if you are confused about coding, you can check it: Summary of solutions to Python coding problems As you can see, in fact, what is printed out is the transcoding string. You can use string search to find and print the result, but this is too passive
In fact, this is a json structure. The data structure is also the form of key value pairs. It is a lightweight data exchange structure. To put it bluntly, here is to encapsulate python's output results in the form of strings. The fact contained in this string is a dictionary, which contains "translateResult" The value in it is a list dictionary. In fact, it is a json structure. Strings contain normal structures that can be recognized in python. Just remove these strings, as follows:)
(parsing: first, import json, and load the just string with the load method of json. You can see that what you get is really a dictionary. That's easy to do. To access the key in the dictionary, use his keyword to access it. Because there are multiple layers, you can access it one layer at a time. Finally, you can beautify it, and then you can combine it easyGui makes a graphical interface, which can be translated with its own later)
import urllib.request import urllib.parse import json content = input("Please enter what you want to translate:") # From Request URL:Copy it. hold_o Deleted url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule" # Data is the Form Data. Copy the contents of Form Data data = {} data['i'] = content data['from'] = 'AUTO' data['to'] = 'AUTO' data['smartresult'] = 'dict' data['client'] = 'fanyideskweb' data['salt'] = '15803439446390' data['sign'] = '8e349204c5d1140741ffe43284595085' data['ts'] = '1580343944639' data['bv'] = 'bbb3ed55971873051bc2ff740579bb49' data['doctype'] = 'json' data['version'] = '2.1' data['keyfrom'] = 'fanyi.web' data['action'] = 'FY_BY_CLICKBUTTION' #Using urllib.parse.urlencode()Function to convert a string to the desired form #Convert Unicode file format to uf-8Code form of data = urllib.parse.urlencode(data).encode('utf-8') response = urllib.request.urlopen(url,data) #Use uf when decoding-8To decode html = response.read().decode("utf-8") target = json.loads(html) print("Translation result:%s"%(target["translateResult"][0][0]["tgt"]))

(this kind of code can't be applied to our production practice, because if you do so much, the server will find that the non-human User Agent accesses frequently, and you will be blocked. And how to access this IP so frequently will make you black. In fact, Python has solutions to these problems, which will be mentioned in the next chapter. )
##Learning from the past and learning from the new
What is the timeout parameter of the 0. urlopen() method used to set?
Answer: the timeout parameter is used to set the timeout time of the connection, in seconds.
1. How to get HTTP status code from the object returned by urlopen()?
A:
... response = urllib.request.urlopen(url) code = response.getcode() ...
2. What are the two most commonly used methods for request response between client and server?
A: GET and POST.
3. HTTP is based on the request response mode, that is, the client sends the request and the server responds; or the server sends the request and the client responds?
Answer: the client will always send the request and the server will always respond.
4. What information does the user agent attribute usually record?
A: ordinary browsers will provide the identity of the browser type, operating system, browser kernel and other information you use to visit the website through this content.
5. How to use the POST method to send a request to the server through urlopen()?
A: the urlopen function has a data parameter. If you assign a value to this parameter, the HTTP request uses the POST method. If the data value is None, which is the default value, the HTTP request uses the GET method.
6. What method of string is used to convert other encodings to Unicode encodings?
A: decode. The function of decode is to convert other encoded strings to unicode encoding. On the contrary, encode is to convert Unicode encoding to other encoded strings.
7. What the hell is JSON?
A: JSON is a lightweight data exchange format. To put it bluntly, string is used to encapsulate Python's data structure for storage and use.
Make a move
0. Cooperate with EasyGui to add interaction to the code of "download a cat":
Let users input dimensions;
If the user does not input the size, Download meow according to the default width of 400 and height of 600;
Let the user specify the save location.
The program implementation is as follows: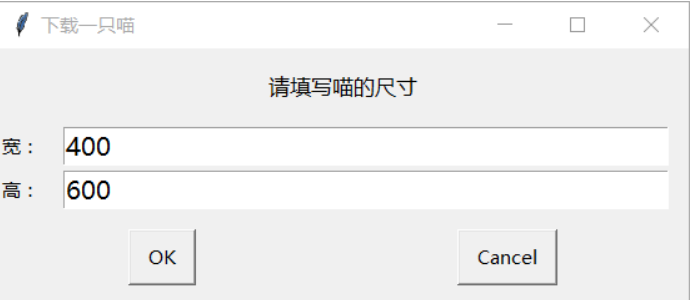
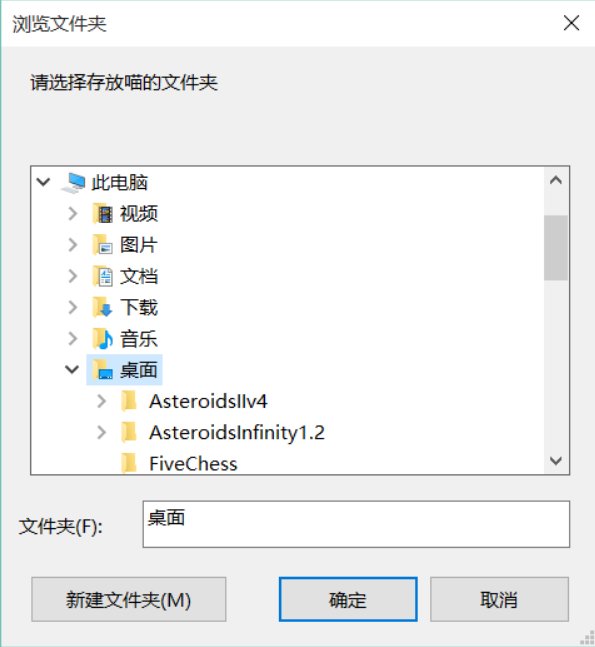

A:
import easygui as g import urllib.request def main(): msg = "Please fill in meow's size" title = "Download a meow" fieldNames = ["wide:","high:"] fieldValues = [] size = width,height = 400,600 fieldValues = g.multenterbox(msg,title,fieldNames,size) while 1: if fieldValues == None: break errmsg = "" try: width = int(fieldValues[0].strip()) except: errmsg +="Width must be an integer!" try: height = int(fieldValues[1].strip()) except: errmsg += "Height must be an integer!" if errmsg == "": break fieldValues = g.multenterbox(errmsg, title, fieldNames, fieldValues) url = "http://placekitten.com/g/%d/%d" % (width, height) response = urllib.request.urlopen(url) cat_img = response.read() filepath = g.diropenbox("Please select the folder to store meow") if filepath: filename = '%s/cat_%d_%d.jpg' % (filepath, width, height) else: filename = 'cat_%d_%d.jpg' % (width, height) with open(filename, 'wb') as f: f.write(cat_img) if __name__ == "__main__": main()
1. Write a client to log in to Douban.
This question may be difficult for you, because it needs more knowledge you haven't learned!
But I'm not going to let you give up hope. Next is a possible snippet of Python 2. Please change it to Python 3. You may not have learned some of these databases and knowledge points, but with the ability of self-study, you can complete the task without looking at the answers, right?
The program implementation is as follows: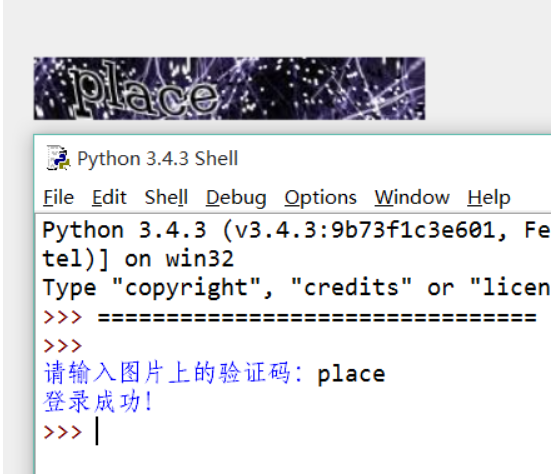
Python 2 implementation code:
# -- coding:gbk -- import re import urllib, urllib2, cookielib loginurl = 'https://www.douban.com/accounts/login' cookie = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) params = { "form_email":"your email", "form_password":"your password", "source":"index_nav" #If not, login is not successful } #Submit login from home page response=opener.open(loginurl, urllib.urlencode(params)) #Verify successfully jump to login page if response.geturl() == "https://www.douban.com/accounts/login": html=response.read() #Verification code image address imgurl=re.search('<img id="captcha_image" src="(.+?)" alt="captcha" class="captcha_image"/>', html) if imgurl: url=imgurl.group(1) #Save the picture to the same directory res=urllib.urlretrieve(url, 'v.jpg') #Get captcha-id parameter captcha=re.search('<input type="hidden" name="captcha-id" value="(.+?)"/>' ,html) if captcha: vcode=raw_input('Please enter the verification code on the picture:') params["captcha-solution"] = vcode params["captcha-id"] = captcha.group(1) params["user_login"] = "Sign in" #Submit verification code for verification response=opener.open(loginurl, urllib.urlencode(params)) ''' Log in successfully and jump to the home page ''' if response.geturl() == "http://www.douban.com/": print 'login success ! '
A: Python 3 has many changes compared with Python 2.
In this question:
* urllib and urllib2 are combined, and most functions are put into the urllib.request module;
* the original urllib.urlencode() is changed to urllib.parse.urlencode().encode(), because of the coding relationship, you need to add encode ('utf-8 ') at the back;
* cookieib was renamed http.cookiejar;
We haven't talked about it in class, so here's an opportunity to give you a brief introduction to what cookie s are:
We say that HTTP protocol is based on the request response mode, that is, the client sends a request and the server replies a response
But the HTTP protocol is stateless, that is to say, the client submits the account password to the server at this time, and the server replies that the authentication is passed, but the next second the client says that I want to visit the Xoo resource, and the server replies, "ah?? Who are you?! "
In order to solve this awkward dilemma, some people invented cookies. A cookie is the ciphertext used by the server (website) to verify your identity. So every time the client submits a request, the server can know your identity information by verifying the cookie. To learn more about cookies, go to - > Session technology overview \ , as you can guess, cookie jar is the object Python uses to store cookies.
Of course, Python 2 code has been provided for you here. You don't understand the above, and it doesn't affect the completion of the job.
import re import urllib.request from http.cookiejar import CookieJar # Douban's login url loginurl = 'https://www.douban.com/accounts/login' cookie = CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor) data = { "form_email":"your email", "form_password":"your password", "source":"index_nav" } data = {} data['form_email'] = 'Your account number' data['form_password'] = 'Your password' data['source'] = 'index_nav' response = opener.open(loginurl, urllib.parse.urlencode(data).encode('utf-8')) #Verify successfully jump to login page if response.geturl() == "https://www.douban.com/accounts/login": html = response.read().decode() #Verification code image address imgurl = re.search('<img id="captcha_image" src="(.+?)" alt="captcha" class="captcha_image"/>', html) if imgurl: url = imgurl.group(1) # Save the verification code picture to the same directory res = urllib.request.urlretrieve(url, 'v.jpg') # Get captcha-id parameter captcha = re.search('<input type="hidden" name="captcha-id" value="(.+?)"/>' ,html) if captcha: vcode = input('Please enter the verification code on the picture:') data["captcha-solution"] = vcode data["captcha-id"] = captcha.group(1) data["user_login"] = "Sign in" # Submit verification code for verification response = opener.open(loginurl, urllib.parse.urlencode(data).encode('utf-8')) # Log in successfully and jump to the home page ''' if response.geturl() == "http://www.douban.com/": print('Login succeeded!')

