Input and output of bert model
Model input
Three embedding: token embedding word vector, position Embedding position vector Embedding text vector
- about token embedding
token embedding To convert each word into a fixed dimensional vector. stay BERT In, each word is converted into a 768 dimensional vector representation. Enter text before entering token embeddings The layer should be tested before tokenization handle.
tokenization The method used is WordPiece tokenization. Two special token Will be inserted into tokenization The beginning of the result ([CLS])And ending ([SEP])
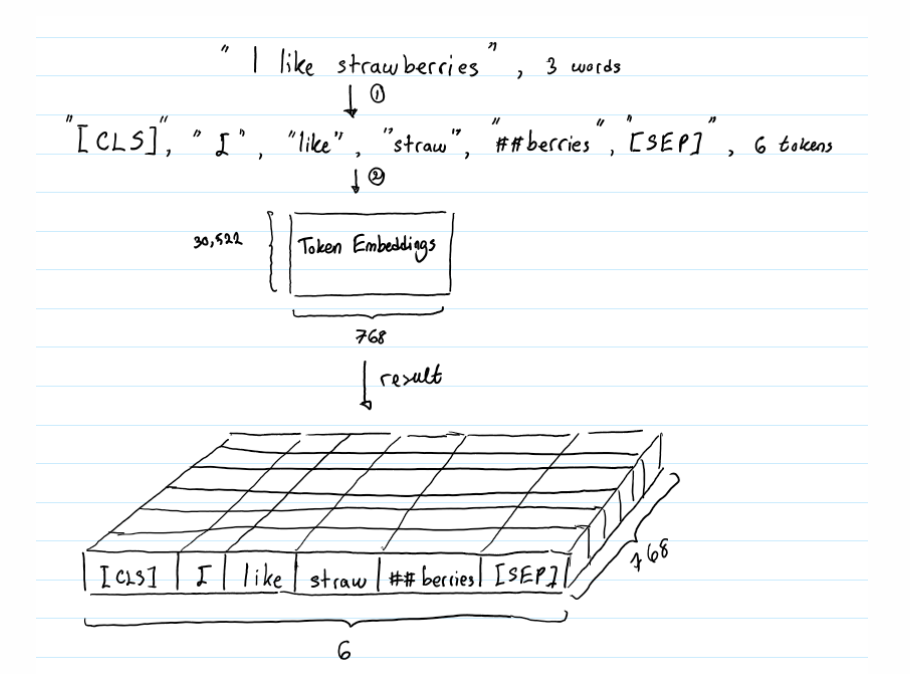
BERT Medium Position Embedding and Transformer dissimilarity, transormer The Chinese formula directly uses the formula to calculate the value of the corresponding dimension. stay BERT Learning is to learn. for instance d_model If the size is 512, each sentence will generate one[0,1,2,...511]A one-dimensional array of, and then repeat batch Times, so the actual input is[batch,d_model],Send it to one_hot The specific coding process and Token Embedding Same, and then the final output is[batch,seq_len,d_model]. and Token Embedding The output dimensions are the same
- about position embedding
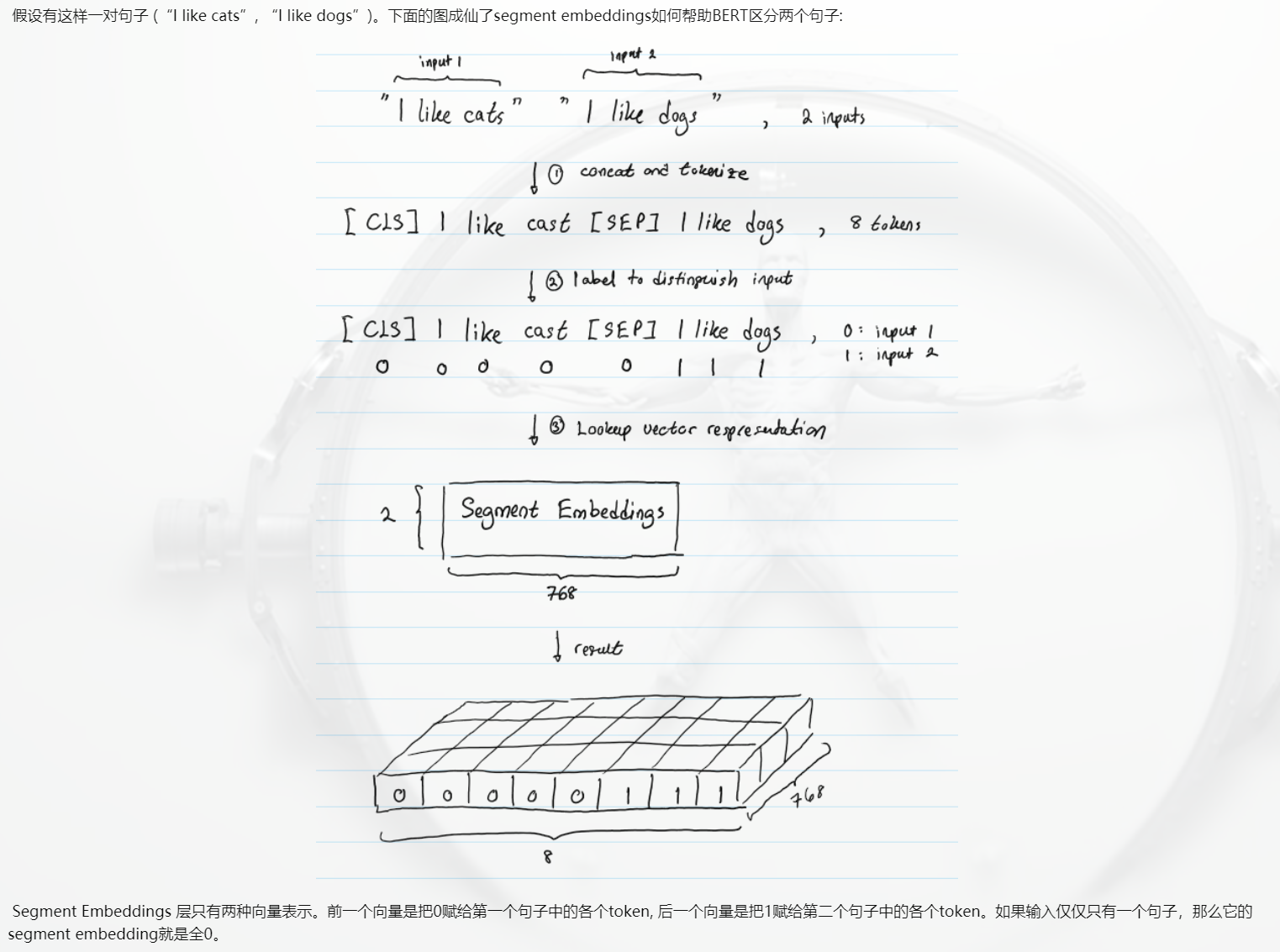
- about segement embedding
participle
(Refer to the original link: https://blog.csdn.net/u010099080/article/details/102587954)
BERT Source code tokenization.py It is the procedure for word segmentation by preprocessing. There are two word splitters:BasicTokenizer and WordpieceTokenizer,Another one FullTokenizer It is the combination of the two: firstBasicTokenizer Get a rough one token List, and then for each token Once WordpieceTokenizer,Get the final word segmentation result.
BasicTokenizerIt is a preliminary word splitter. For a character string to be segmented, the process is roughly converted to unicode-->Remove all kinds of strange characters-->Processing Chinese(Judge whether it is Chinese (Chinese is separated by characters)-->Space participle-->Remove redundant characters and punctuation word segmentation-->Space participle again
WordpieceTokenizerYes BT On the basis of the results, the sub words are segmented again( subword,with ## The vocabulary was introduced at this time. This class has only two methods: an initialization method__init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200),A word segmentation methodtokenize(self, text). tokenize(self, text): This method is the main word segmentation method. The general idea of word segmentation is to split a word into multiple sub words in order from left to right, and each sub word is as long as possible. according to Source code This method is called greedy longest-match-first algorithm,Greedy longest first matching algorithm.
Sample aspect
def convert_single_example( max_seq_length, tokenizer,text_a, text_b=None): tokens_a = tokenizer.tokenize(text_a) tokens_b = None if text_b: tokens_b = tokenizer.tokenize(text_b)# This is mainly to divide Chinese characters if tokens_b: # If there is a second sentence, the total length of the two sentences should be less than max_seq_length - 3 # Because you have to fill in the sentence[CLS], [SEP], [SEP] _truncate_seq_pair(tokens_a, tokens_b, max_seq_length - 3) else: # If there is only one sentence, just add it before and after[CLS], [SEP] So the sentence length should be less than max_seq_length - 3 if len(tokens_a) > max_seq_length - 2: tokens_a = tokens_a[0:(max_seq_length - 2)] # convert to bert Input, pay attention to the following type_ids In the source code, the corresponding is segment_ids # (a) Two sentences: # tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP] # type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1 # (b) Single sentence: # tokens: [CLS] the dog is hairy . [SEP] # type_ids: 0 0 0 0 0 0 0 # # here "type_ids" It is mainly used to distinguish the first sentence from the second sentence. # The first sentence is 0 and the second sentence is 1. It will be added to the word vector during pre training, but this is not necessary # because[SEP] The first sentence and the second sentence have been distinguished. but type_ids It will make learning easier tokens = [] segment_ids = [] tokens.append("[CLS]") segment_ids.append(0) for token in tokens_a: tokens.append(token) segment_ids.append(0) tokens.append("[SEP]") segment_ids.append(0) if tokens_b: for token in tokens_b: tokens.append(token) segment_ids.append(1) tokens.append("[SEP]") segment_ids.append(1) input_ids = tokenizer.convert_tokens_to_ids(tokens)# Convert Chinese into ids # establish mask input_mask = [1] * len(input_ids) # Make up 0 for input while len(input_ids) < max_seq_length: input_ids.append(0) input_mask.append(0) segment_ids.append(0) assert len(input_ids) == max_seq_length assert len(input_mask) == max_seq_length assert len(segment_ids) == max_seq_length return input_ids,input_mask,segment_ids # The corresponding is to create bert Model time input_ids,input_mask,segment_ids parameter
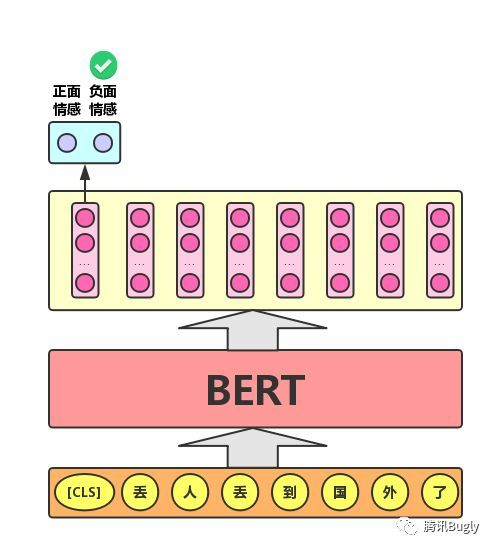
- For text classification task, BERT model inserts a [CLS] symbol in front of the text, and takes the output vector corresponding to the symbol as the semantic representation of the whole text
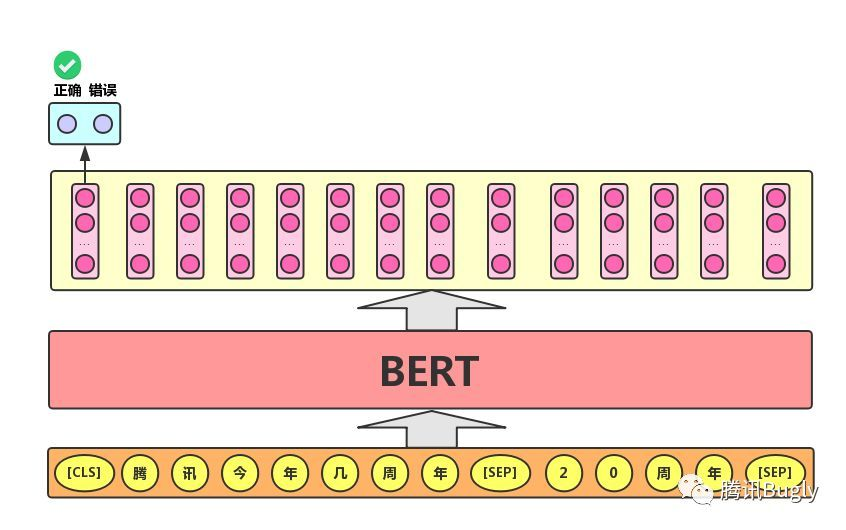
- Sentence pair classification task: the actual application scenarios of this task include: question and answer (judge whether a question matches an answer), sentence matching (whether two sentences express the same meaning), etc. For this task, the BERT model not only adds the [CLS] symbol and takes the corresponding output as the semantic representation of the text, but also divides the input two sentences with a [SEP] symbol, and attaches two different text vectors to the two sentences respectively for differentiation
- Sequence annotation task: the practical application scenarios of this task include: Chinese Word Segmentation & new word discovery (marking each word as the first, middle or last word of the word), answer extraction (start and end position of the answer), etc. For this task, BERT model uses the output vector corresponding to each word in the text to label (classify) the word, as shown in the following figure (B, I and E represent the first word, middle word and last word of a word respectively).
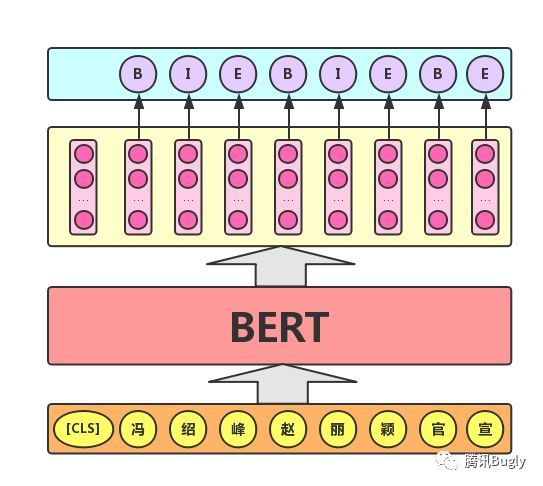
Model output
Get the output of bert model and use model.get_sequence_output() and model.get_pooled_output() Two methods.
output_layer = model.get_sequence_output()# This gets each token of output output[batch_size, seq_length, embedding_size]"""Gets final hidden layer of encoder.
Returns:
float Tensor of shape [batch_size, seq_length, hidden_size] corresponding
to the final hidden of the transformer encoder.
"""output_layer = model.get_pooled_output() # This gets the of the sentence output
mask problem
In BERT's Masked LM training task, 15% of the words in the corpus will be replaced with [MASK] token, and then predicted at the last layer. However, there will be no [MASK] token in downstream tasks, resulting in inconsistency between pre training and fine tune. In order to reduce the impact of inconsistency on the model, in the replaced 15% corpus:
1. 80% of tokens will be replaced by [MASK] token
2. 10% of tokens will be replaced by random tokens
3. 10% of tokens will remain unchanged but need to be predicted
Substitution in the first point: it is the main part of Masked LM, which can fuse true two-way semantic information without divulging label;
Random substitution of the second point: because the token bit that needs to be randomly replaced at the last layer is needed to predict its real word, and the model does not know that the token bit is randomly replaced, it forces the model to learn the representation of a global context on each word as much as possible, so it can also enable BERT to obtain better context related word vectors (this is the most important feature of solving polysemy);
The third point remains unchanged: that is, 10% of the cases are leaked (accounting for 15% * 10% = 1.5% of all words). This can give the model a certain bias, which is equivalent to an additional reward, and pull the model's representation of words to the real representation of words (at this time, the input layer is the real embedding of the word to be predicted. The embedding obtained at the position of the word in the output layer is obtained after layers of self attention. Some of the input embedding information is still retained in this part of embedding, which is the additional reward brought by inputting a certain proportion of real words, which will eventually make the output vector of the model There is an offset towards the real embedding of the input layer). If all mask s are used, the model only needs to ensure the accurate classification of the output layer and does not care about the vector representation of the output layer. Therefore, the final vector output effect may not be good.
model structure
About attention mechanism
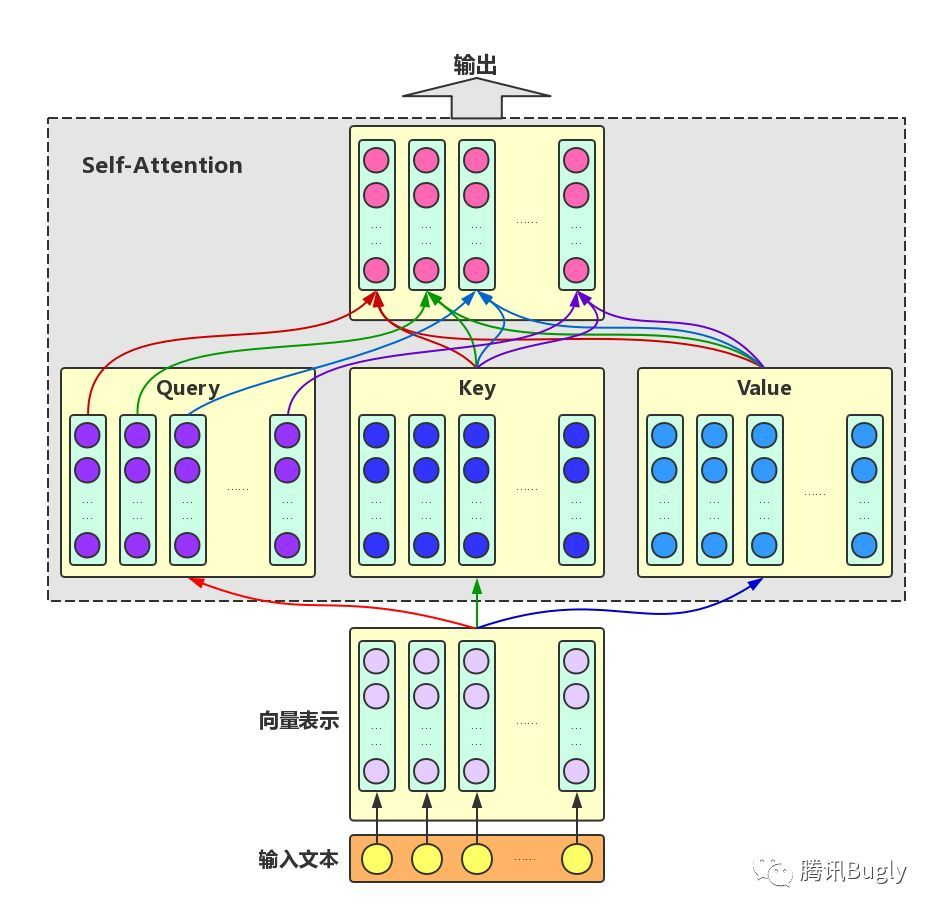
The Attention mechanism takes the semantic vector representation of the target word and the context words as the input. Firstly, the Query vector representation of the target word, the Key vector representation of the context words and the original Value representation of the target word and the context words are obtained through linear transformation, and then the similarity between the Query vector and each Key vector is calculated as the weight, The Value vector of the target word and the Value vector of each upper and lower text are weighted and fused as the output of Attention, that is, the enhanced semantic vector representation of the target word.
Self Attention: for the input text, we need to enhance the semantic vector representation of each word. Therefore, we take each word as a Query and weight the semantic information of all words in the text to obtain the enhanced semantic vector of each word, as shown in the figure below. In this case, the vector representations of Query, Key and Value all come from the same input text. Therefore, the Attention mechanism is also called self Attention
Multi head self Attention: in order to enhance the diversity of Attention, the author further uses different self Attention modules to obtain the enhanced semantic vector of each word in the text in different semantic spaces, and linearly combines multiple enhanced semantic vectors of each word to obtain a final enhanced semantic vector with the same length as the original word vector
Using multi head attention can extract information from different angles and improve the comprehensiveness of information extraction
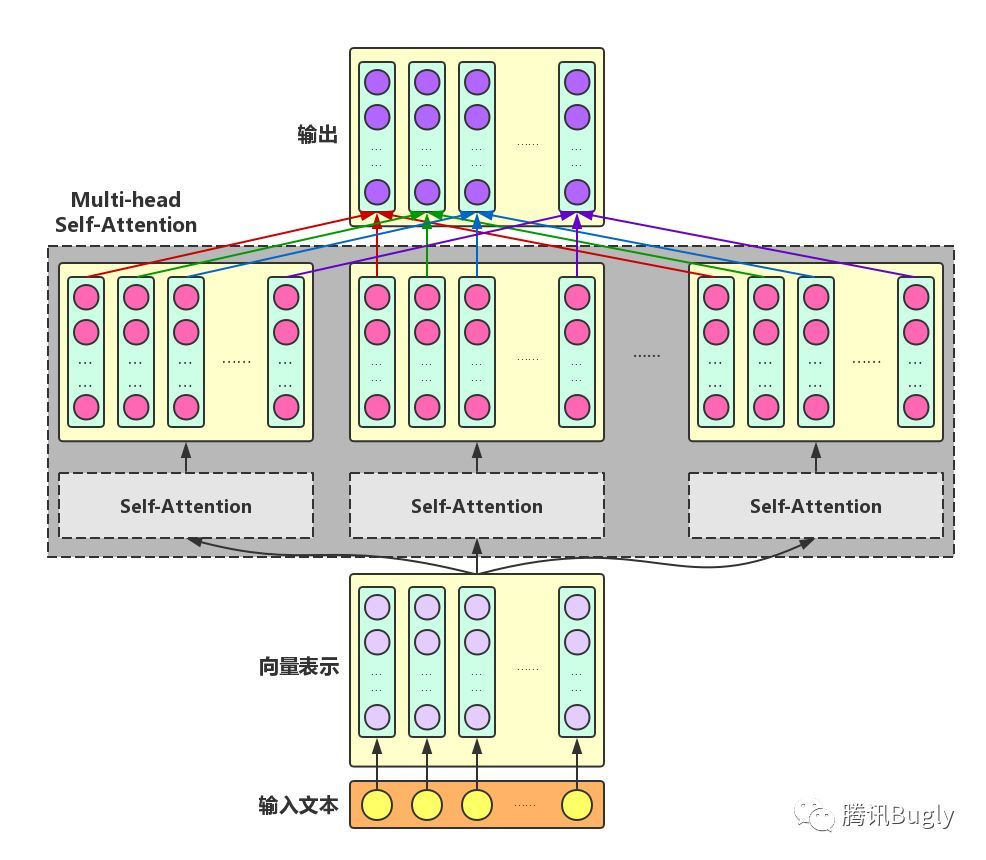
[the input and output of multi head self attention are exactly the same in form. The input is the original vector representation of each word in the text, and the output is the enhanced vector representation of each word after integrating the full-text semantic information]
Transformer Encoder adds three key operations to multi head self attention:
- Residual connection: add the input and output of the module directly as the final output. One of the basic considerations behind this operation is that it is easier to modify the input than to reconstruct the entire output ("icing on the cake" is much easier than "helping in the snow!"). In this way, the network can be easier to train. Solve the problem that the gradient disappears when the number of network layers is large
- Layer Normalization: normalize the 0 mean 1 Variance of a layer of neural network nodes.
Difference between layer normalization and batch normalization
The calculated dimensions are different. BN is calculated based on the same channel of different batches, and LN is calculated based on different characters of the same batch
- Linear transformation: perform two more linear transformations on the enhanced semantic vector of each word to enhance the expression ability of the whole model. Here, the transformed vector remains the same length as the original vector.
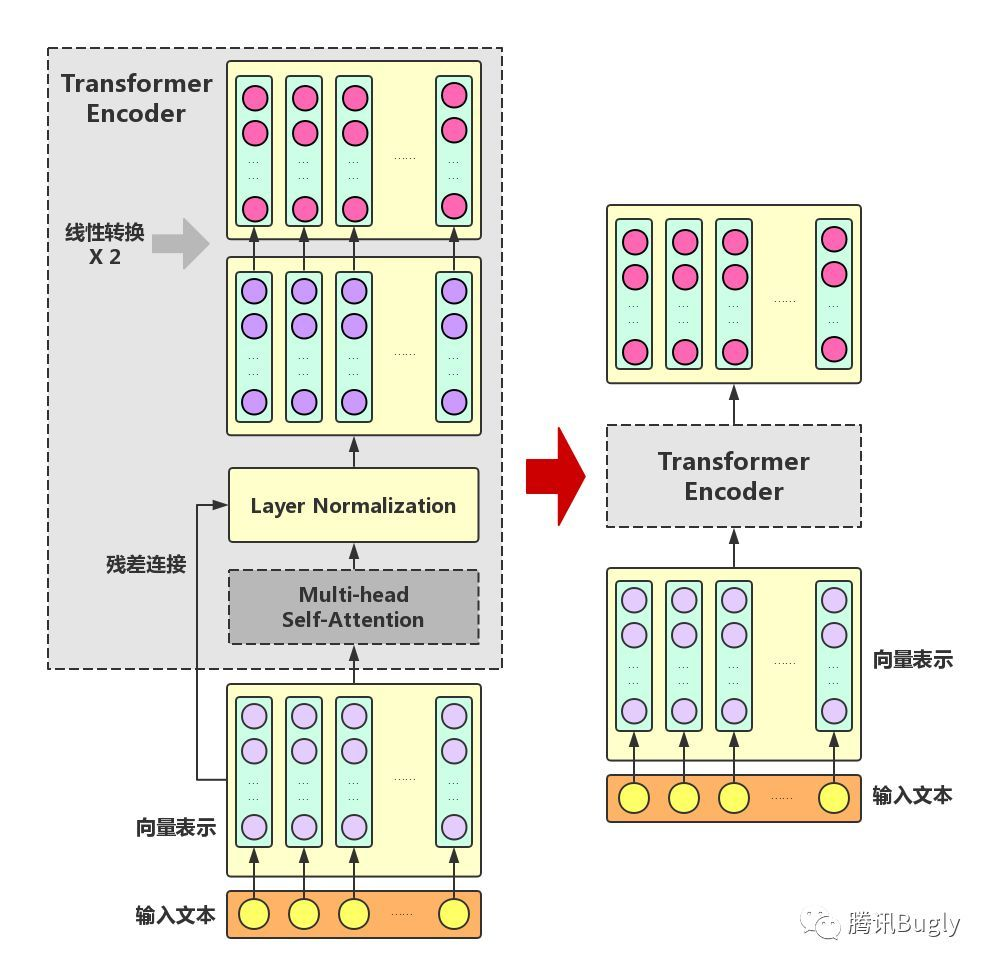
[the input and output of Transformer Encoder are exactly the same in form, so Transformer Encoder can also be expressed as converting the semantic vector of each word in the input text into an enhanced semantic vector of the same length]