[PaddleWeekly33] walnuts are so cute, let's "draw" walnuts and shake them by hand~
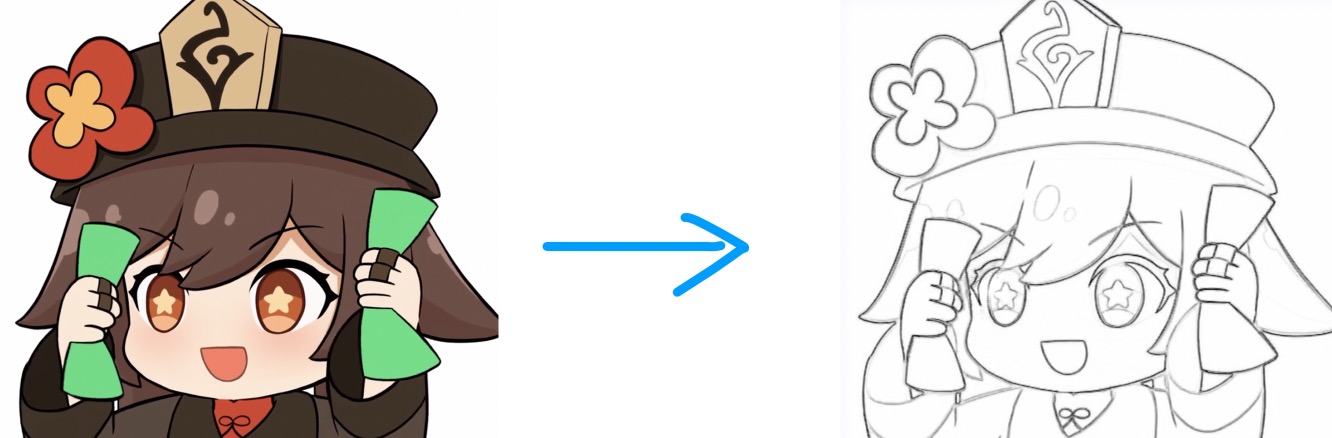
This issue of PaddleWeekly will introduce you from Seven year term And Mr. Zheng_ Two big guys cooperate on an open source project: line drawing generator ExtractLine.
In this project, we will briefly encapsulate it in addition to introducing its implementation principle. You can easily AI Studio Image - > line drawing, video - > video line drawing can be operated in various ways.
Of course, if you want to use it locally, you can click the one click Run button in the upper right corner. After entering the project, you can find the exe installation package in the folder on the left. Also Click the link here Or scan the QR code below to join the QPT project exchange Q group to exchange playing methods and ideas with you!
Project practice - welcome to one button three company
follow Bleep bleep GT_ Lao Zhang Updated every Friday~
Award winning activities
Paddleweakly's original intention is to show the excellent open source projects / works of propeller developers to more like-minded people. For example, you like this project in front of the screen: line drawing generator ExtractLine , welcome to send one to the original author on GitHub 🌟 Star 🌟 Supported by tables.
Of course, you can also use this project to create two tiktok platforms, such as beep, beep and voice. It is better to paste the AI Studio link of this project.
Finally, we will send it to the original author on the first anniversary 🌟 Star 🌟 And the developers of secondary creation, select 3-5 as the developers of this issue of Eurogas, and send one around the mysterious propeller~
HD version of "walnut shake" source: Bili Bili - conch Zhang
Warmup
Entry difficulty
For use only
Difficulty: ★☆☆☆
Technology stack: no special requirements
Since the project has been uploaded to AI Studio and the exe installation package is also provided locally, it is very difficult and does not need a technical stack. You can do it by hand.
Secondary development
Difficulty: ★☆☆☆
Technology stack: basic Python capabilities
The project is integrated with PaddleHub as a whole. The API is simple and easy to use. We don't need to pay too much attention to the technical ability of in-depth learning during secondary development.
Algorithm development
Difficulty: ★★★☆☆
Technology stack: Python basic capability, flying propeller PaddlePaddle or any deep learning framework.
Although the introduction of this type of task is simple, and even the lines that look good can be made with a simple edge detection operator, there is still a big gap between these lines and "sketch".
In order to make a good online manuscript extraction model, there are still some tests in data set and deep learning model modeling.
Relevant information
If you just want to know how to use it, scroll to the start section at the bottom of the page.
Algorithm modeling
Mission objectives
Since what we want to do is to extract the character's line draft from the picture, the input and output determined during model modeling should be any picture - > line draft picture.
Namely:
[N, C, H, W] -> [N, 1, H, W]
Algorithm modeling
Since this type of input and output can be associated with the network structure of Pix2Pix?

That means that if we want to model an extremely simple online manuscript extraction model, a simple model structure such as U-Net can be briefly verified in the early stage.
Online sketch generator ExtractLine Although the author does not provide model related networking files, we can use VisualDL In its model file__ model__ Finally, we can see that it uses a brief Pix2Pix structure like U-Net, which is not too difficult.
Due to the large size of the model visualized by VisualDL, if you need to view the model structure, you can find the "model visualization. PNG" file in the left folder after Fork this project.
Is traditional edge detection feasible?
Of course, some students may ask: isn't line draft extraction a simple edge detection? Can I solve this problem with the traditional edge detection operator?
Of course, this method is not only portable, but also can get a good effect without online manuscript data set, but this scheme has one disadvantage: the extracted result may contain noise.
Next, we will use a very simple and easy-to-use edge detection project, which comes from Xiao Lao of EdgeOPs,
# Clone EdgeOPs can be used locally if clone is slow https://github.com/QPT-Family/QWebSiteOptimizer Replace the mirror source # !git clone https://hub.fastgit.org/jm12138/EdgeOPs
Cloning to 'EdgeOPs'... remote: Enumerating objects: 13, done.[K remote: Counting objects: 100% (13/13), done.[K remote: Compressing objects: 100% (12/12), done.[K remote: Total 13 (delta 3), reused 0 (delta 0), pack-reused 0[K Expand objects: 100% (13/13), complete. Check connection... Done.
# The following code comes from Xiao Lao's edge detection Series 1: traditional edge detection operators
# https://aistudio.baidu.com/aistudio/projectdetail/2512704
import os
import cv2
import numpy as np
import paddle
from EdgeOPs.edgeops.paddle import EdgeOP
from PIL import Image
def test_edge_det(kernel, img_path='inp.jpg'):
img = cv2.imread(img_path, 0)
print(img.shape)
img_tensor = paddle.to_tensor(img, dtype='float32')[None, None, ...]
op = EdgeOP(kernel)
all_results = []
for mode in range(4):
results = op(img_tensor, mode=mode)
all_results.append(results.numpy()[0])
results = op(img_tensor, mode=4)
for result in results.numpy()[0]:
all_results.append(result)
return all_results, np.concatenate(all_results, 1)
roberts_kernel = np.array([
[[
[1, 0],
[0, -1]
]],
[[
[0, -1],
[1, 0]
]]
])
_, concat_res = test_edge_det(roberts_kernel)
im = Image.fromarray(concat_res)
im = im.resize((im.size[0]//4, im.size[1]//4))
import PIL.ImageOps
PIL.ImageOps.invert(im)
(812, 916)

We can see that the effect of traditional edge detection is also very good.
However, this scheme carries out edge detection without difference, which will also lead to the "violation" of the depth of the contour of the target.
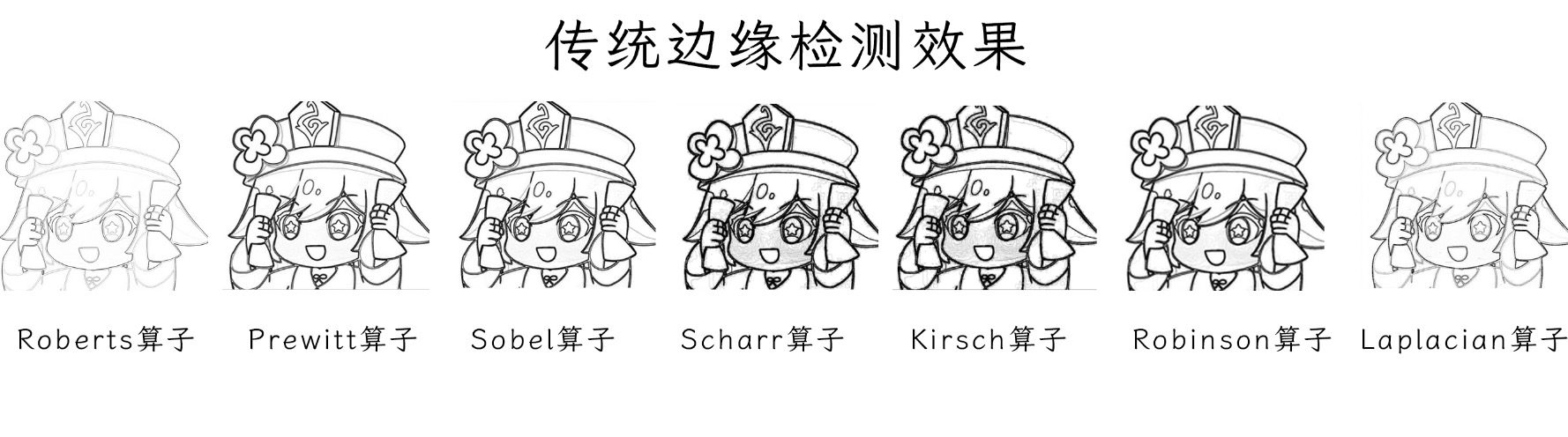
For example, in the Robert operator, we can obviously see that the contour lines in areas without hierarchy (eye and face contour) show the effect of depth and light.
Similarly, the Scharr operator completely avoids this problem, but the face obviously has color filling we don't need. Even the Prewitt operator with good performance, the face is still affected by similar effects.
Of course, this is made on the basis of no label data. If we want to use the deep learning method to complete the line draft extraction, we also need to prepare the label data, which means that edge detection is a good choice without label data.
How effective is the deep learning program?
Compared with the traditional edge detection scheme, the scalability of deep learning method will also be improved. For example, we can combine the "significant target extraction" model with ExtractLine It is combined so that it can only extract the main target line of the picture, not the surrounding noise.
Significant target extraction effect
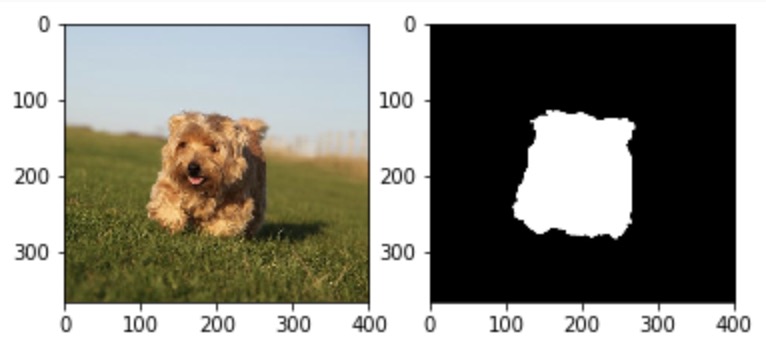
Whether there is significant target extraction comparison
It can be seen that the "barrage" in the figure below disappears after significant target extraction.

If you don't know about significant target detection, you can refer to the advice of the big man The research direction of significant target detection is shared with paddy's code skills when dealing with CV tasks
Start using

Here, we use the data encapsulated in PaddleHub ExtractLine Plan to "hand draw" a line version of walnut shake it~
Use process
- Upload a picture in the left folder
- Change the picture file name to inp.jpg
- Click the start button below to execute. After the program is completed, you can find the picture we generated in the output folder on the left, and right-click to see the download button.
import paddlehub as hub
Extract_Line_Draft_test = hub.Module(name="Extract_Line_Draft")
test_img = "./inp.jpg"
Extract_Line_Draft_test.ExtractLine(test_img)
print("Picture saved to output/output.png")
# Read the thread draft and display it
from PIL import Image
im = Image.open("output/output.png")
im = im.resize((im.size[0]//4, im.size[1]//4))
im
Advanced play
If you want to make it as a page turning picture, you can use the code below to present the video file in the form of frame drawing on the canvas of A4 paper size. After printing + cutting, it can become a page turning picture.
Use process
- Upload a video file in mp4 format.
- Modify the file name to inp.mp4.
- Click the run button below to run the code block. (to use GPU, modify use_gpu = True)
- Download out_a4.jpg file can be made into page turning picture by printing + cutting + binding.

Although it does not have very high commercial value, it should not be used for commercial purposes outside the authorization.
%set_env CUDA_VISIBLE_DEVICES=0
import cv2
import paddlehub as hub
from PIL import Image
Extract_Line_Draft_test = hub.Module(name="Extract_Line_Draft")
videoFile = "inp.mp4"
cache_path = "./cache.jpg"
use_gpu = False
a4_image = Image.new(mode="RGB", size=(2480, 3508), color="white")
cap = cv2.VideoCapture(videoFile)
count = 0
mod_x = 256 + 256
mod_y = 256 + 10
im_list = list()
while (cap.isOpened()):
ret, frame = cap.read()
if frame is None:
break
# Draw a frame
if count % 2 == 0:
print(f"Processing page{count}frame")
# Because this Module is encapsulated too hard, you can only save it first and then read it
cache = cv2.imwrite(cache_path, frame)
Extract_Line_Draft_test.ExtractLine(cache_path, use_gpu=use_gpu)
im = Image.open("output/output.png")
im = im.resize((256, 256))
im_list.append(im)
count += 1
count = 0
im_count = len(im_list)
for x in range(2480-256 // mod_x):
for y in range(3508 // mod_y):
im = im_list[count % im_count]
a4_image.paste(im, (80 + (x * mod_x), y * mod_y))
count += 1
a4_image.save("out_a4.jpg")
cap.release()
print("File generation completed")
About
- Some expression packets come from the network and are invaded and deleted.
- HD version of "walnut shake" source: Bili Bili - conch Zhang Thanks again.