preface:
This column mainly combines OpenCV4 to realize some basic image processing operations, classical machine learning algorithms (such as K-Means, KNN, SVM, decision tree, Bayesian classifier, etc.), and common deep learning algorithms.
Series of articles, continuously updated:
- OpenCV4 machine learning (I): Construction and configuration of OpenCV4+VS2017 environment
- OpenCV4 machine learning (II): image reading, display and storage
- OpenCV4 machine learning (III): conversion between color spaces (RGB, HSI, HSV, Lab, Gray)
- OpenCV4 machine learning (4): geometric transformation and affine transformation of images
- OpenCV4 machine learning (V): dimension text and rectangular box
1, Basic introduction
K-means, namely K-means, is an iterative clustering algorithm. Clustering is a process of classifying and organizing data members who are similar in some aspects. Clustering is a technology to discover this internal structure. Clustering technology is often called unsupervised learning.
K-means clustering is the most famous partition clustering algorithm. Because of its simplicity and efficiency, it has become the most widely used of all clustering algorithms. Given a set of data points and the required number of clusters K, K is specified by the user, and the k-means algorithm repeatedly divides the data into K clusters according to a distance function.
2, Algorithm principle
For a given data set, the process of clustering by K-means method is as follows:
- Initialize K cluster centers.
- Sample allocation. Place each sample in the collection with its nearest category center. Determine which center the sample is closest to through the set distance function and put it into the corresponding sample. The distance function generally adopts: Euclidean distance, Manhattan distance, Minkowski distance and Hamming distance.
- Update category center. For the samples allocated in each set, calculate the sample mean and take it as the current category center.
- Determine termination conditions. Judge whether the category label reaches the convergence accuracy or the number of training rounds.
3, Function interpretation
In OpenCV4, the cv::kmeans function implements K-means, which finds the centers of K categories and groups the input samples around the categories.
The cv::kmeans function is defined as follows:
double cv::kmeans(InputArray data, //sample int K, //Number of categories InputOutputArray bestLabels, //The output integer array is used to store the cluster category index of each sample TermCriteria criteria, //Algorithm termination condition: maximum number of iterations or required accuracy int attempts, //Specifies the number of times the algorithm is executed using different initial tags int flags, //Method of initializing mean point OutputArray centers = noArray() //The output matrix of cluster centers, each cluster center occupies one row )
4, Actual combat demonstration
The following will demonstrate an example of clustering a two-dimensional coordinate point set using the kmeans() method in OpenCV.
#include<iostream>
#include<opencv.hpp>
using namespace std;
using namespace cv;
int main() {
const int MAX_CLUSTERS = 5; //Maximum number of categories
Scalar colorTab[] = { //Drawing color
Scalar(0, 0, 255),
Scalar(0, 255, 0),
Scalar(255, 100, 100),
Scalar(255, 0, 255),
Scalar(0, 255, 255)
};
Mat img(500, 500, CV_8UC3); //New canvas
img = Scalar::all(255); //Set canvas to white
RNG rng(35345); //Random number generator
//Number of initialization categories
int clusterCount = rng.uniform(2, MAX_CLUSTERS + 1);
//In the specified interval, randomly generate an integer, the number of samples
int sampleCount = rng.uniform(1, 1001);
//Input sample matrix: sampleCount row x1 column, floating point, 2 channels
Mat points(sampleCount, 1, CV_32FC2);
Mat labels;
//Number of cluster categories < number of samples
clusterCount = MIN(clusterCount, sampleCount);
//Clustering result index matrix
vector<Point2f> centers;
//Randomly generate samples with multi Gaussian distribution
//for (int k = 0; k < clusterCount; k++) {
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
//Assign values to the sample points assignment
Mat pointChunk = points.rowRange(0, sampleCount / clusterCount);
//Take center as the center, generate random points with Gaussian distribution, and save the coordinate points in pointChunk
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));
//Disrupt values in points
randShuffle(points, 1, &rng);
//Execute k-means
double compactness = kmeans(points, //sample
clusterCount, //Number of categories
labels, //The output integer array is used to store the cluster category index of each sample
TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 1.0), //Algorithm termination condition: maximum number of iterations or required accuracy
3, //Specifies the number of times the algorithm is executed using different initial tags
KMEANS_PP_CENTERS, //Method of initializing mean point
centers); //The output matrix of cluster centers, each cluster center occupies one row
//Draw or output clustering results
for (int i = 0; i < sampleCount; i++) {
int clusterIdx = labels.at<int>(i);
Point ipt = points.at<Point2f>(i);
circle(img, ipt, 2, colorTab[clusterIdx], FILLED, LINE_AA);
}
//Draw a circle with the cluster center as the center of the circle
for (int i = 0; i < (int)centers.size(); ++i) {
Point2f c = centers[i];
circle(img, c, 40, colorTab[i], 1, LINE_AA);
}
cout << "Compactness: " << compactness << endl;
imshow("clusters", img);
waitKey(0);
return 0;
}
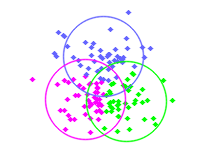
The clustering results are shown in the figure below:
All the complete codes of this column will be updated on my GitHub warehouse. Welcome to learn:
Enter the GitHub warehouse, click star (shown by the red arrow), and get the dry goods at the first time:
The best relationship is mutual achievement. Your "three companies" are the biggest driving force for the creation of [AI bacteria]. See you next time!