1, Concept
1. Nova computing services
Computing service is one of the core services of openstack. It is responsible for maintaining and managing the computing resources of cloud environment. Its code name is nova in openstack project.
Nova itself does not provide any virtualization capabilities. It provides computing services and uses different virtualization drivers to interact with the underlying hypervisor (Virtual Machine Manager). All computing instances (virtual servers) are scheduled and managed by Nova in the life cycle (start, suspend, stop, delete, etc.)
Nova needs the support of other services such as keystone, grace, neutron, cinder and swift, and can integrate with these services, such as encrypted disk, bare metal computing instance, etc.
2. Nova system architecture
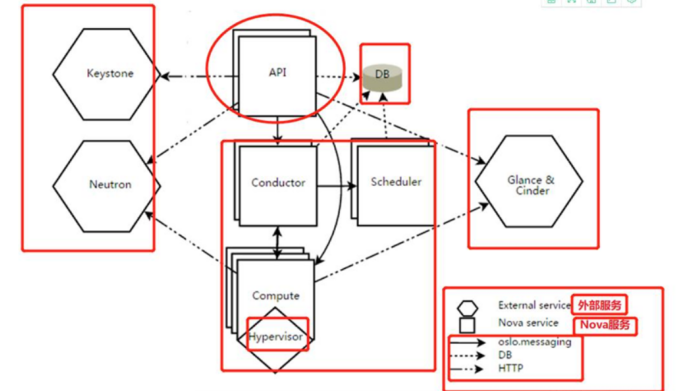
External contact:
DB: sql database for data storage
Network: manages the nova network components of IP forwarding, bridges, or virtual LANs
Keystone: security certified component
Grace & cinder: the component responsible for managing the image
Internal structure:
API: nova component used to receive HTTP requests, convert commands, and communicate with other components through message queue or http
Scheduler: nova scheduler used to decide which computing node hosts the computing instance
Compute: nova computing component that manages the communication between the virtual machine manager and the virtual machine
Conductor: handles requests that require coordination (building virtual machines or resizing virtual machines), or handles object transformations
2, nova component introduction
1. API -- communication interface
API is the http interface for customers to access nova. It is implemented by Nova API service. Nova API service receives and responds to computing API requests from end users. As the main interface of openstack external services, Nova API provides a centralized endpoint that can query all APIs
All requests to nova are first handled by nova API, which provides REST standard call services to facilitate integration with third-party systems
Instead of sending RESTful API requests directly, end users use these APIs through the openstack command line, dashbord er and other components that need to be exchanged with nova
Nova API can respond to any operation related to the virtual machine life cycle
Nova API handles the received HTTP API requests as follows:
1) Check whether the parameters passed in by the client are legal and valid
2) Call nova other services to process client HTTP requests
3) Format the results returned by other nova sub services and return them to the client
nova API is the only way to access and use various services provided by nova externally, and it is also the middle layer between the client and nova
2. Scheduler ---- scheduler
Scheduler can be translated into scheduler, which is implemented by Nova Scheduler service. It mainly solves the problem of how to select which computing node to start the instance on. It can apply a variety of rules. If considering memory utilization, cpu load rate, cpu architecture (Intel/amd) and other factors, it can determine which computing server the virtual machine instance can run on according to a certain algorithm, The node Nova scheduler will read the latest available content from the virtual machine database through the request queue
When creating a virtual machine instance, the user will put forward resource requirements, such as how much cpu, memory and disk are needed. openstack says that these requirements are defined in the instance type, and the user only needs to specify which instance type to use
(1) Type of nova scheduler
Chance scheduler: select randomly from all nodes running Nova compute service normally.
Filter scheduler: select the best calculation node according to the specified filter conditions and weights. Filter is also called filter
·Scheduler scheduling process: it is mainly divided into two stages
·Select the computing nodes that meet the conditions through the specified filter. For example, if the memory utilization is less than 50%, multiple filters can be used for filtering in turn.
·Calculate and sort the weight of the filtered host list, and select the best calculation node to create a virtual machine instance.
Caching scheduler: it can be regarded as a special type of random scheduler. On the basis of random scheduling, the host resource information is cached in the local memory, and then the latest host resource information is obtained from the database regularly through the background timing task.
(2) Filter
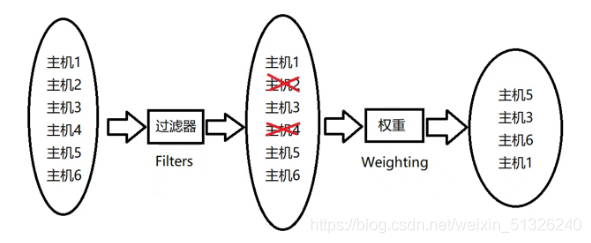
When the filter scheduler needs to perform scheduling operations, it will let the filter judge the computing node and return True or False.
In the configuration file / etc / Nova / nova In conf
· scheduler_ available_ The filters option is used to configure the available filters. By default, all nova built-in filters can be used for filtering
·Another option is scheduler_ default_ filters is used to specify the filters that the Nova Scheduler service actually uses
The filter scheduler will filter in the following order
① Retryfilter
The main function is to filter out the nodes that have been scheduled before. For example, A, B and C have passed the filter, and A has the largest weight. It is selected to perform the operation. For some reason, the operation failed on A. Nova filter will perform the filtering operation again. At this time, A will be directly excluded by RetryFilter to avoid failure again
② AvailabilityZoneFilter
In order to improve disaster tolerance and provide isolation services, computing nodes can be divided into different available areas. Openstack has an available area named nova by default, and all computing nodes are initially placed in the nova area. Users can create their own available areas as needed. When creating an instance, you need to specify which available region the instance will be deployed in. When nova scheduler performs filtering, it will use the availability zonefilter to filter out the calculation nodes that do not belong to the specified availability area
③ RamFilter (memory filter)
Scheduling virtual machine creation based on available memory filters out computing nodes that cannot meet the memory requirements of instance types. However, in order to improve the utilization of system resources, Openstack allows the available memory of nodes to exceed the actual memory size through nova Conf configuration file
ram_ allocation_ The default value is 1.5.
vi /etc/nova/nova.conf
ram_ allocation_ ratio=1 .5
④ DiskFilter (hard disk scheduler)
Schedule virtual machine creation according to disk space, and filter out computing nodes that cannot meet the requirements of disk types. The disk also allows excess. The excess value can be modified to Nova Disk in conf_ The allocation ratio parameter controls. The default value is 1.0
vi /etc/nova/nova.conf
disk_allcation_ratio=1.0
⑤ Computefilter
Ensure that only the Nova compute service is normal: the working computing node can be scheduled by the Nova scheduler, which is a required filter.
⑥ Computecapablitiesfilter
Filter according to the characteristics of the computing node, such as x86_ 64 and ARM architecture, and filter the instances respectively
⑦ Imagepropertiesfilter
Filter matching compute nodes based on the attributes of the selected mirror. Specify its properties through metadata. If you want the image to run only on the Hypervisor of KVM, you can specify it through the Hypervisor Type attribute.
⑧ Servergroupantiaffinityfilter
It is required to deploy instances to different nodes as far as possible. For example, there are three instances s1, s2 and S3 and three computing nodes A, B and C. The specific operations are as follows:
Create a server group with anti affinity policy
openstack server group create -policy antiaffinity group-1
Create three instances and put them into the group-1 server group
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s1
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s2
openstack server create -flavor m1.tiny -image cirros -hint group=group-1 s3
Servergroupaffinity filter
In contrast to the anti affinity filter, this filter tries to deploy instances to the same - compute node
(3) Weight
·The Nova Scheduler service can use multiple filters to filter in turn. After filtering, the nodes that can deploy instances are selected by calculating the weight.
·Note:
·All weights are located in the nova/scheduler/weights directory. At present, the default implementation is RAMweighter, which calculates the weight value according to the amount of free memory of the computing node. The more free, the greater the weight, and the instance will be deployed to the computing node with the most free memory
·openstack source location / usr / lib / python2 7/site-packages
·Weight source location / usr / lib / python2 7site-packages/nova/scheduler/weights
3. Compute ---- calculator
·Nova compute runs on the computing node and is responsible for managing instances on the node.
·Usually, a host runs a nova compute service, and the available host on which an instance is deployed depends on the scheduling algorithm. OpenStack's operations on instances are finally submitted to Nova compute to complete.
·Nova compute can be divided into two categories
·One is to report the status of computing nodes to openstack
·The other is to realize the management of instance life cycle.
(1) Support mode
·Multiple Hypervisor virtual machine managers are supported through the Driver architecture
·Facing a variety of hypervisors (virtual layers), Nova compute provides a unified interface to interact with the underlying virtualization resources
·Calling virtualized resources and supplying them to openstack are completed in the form of driver
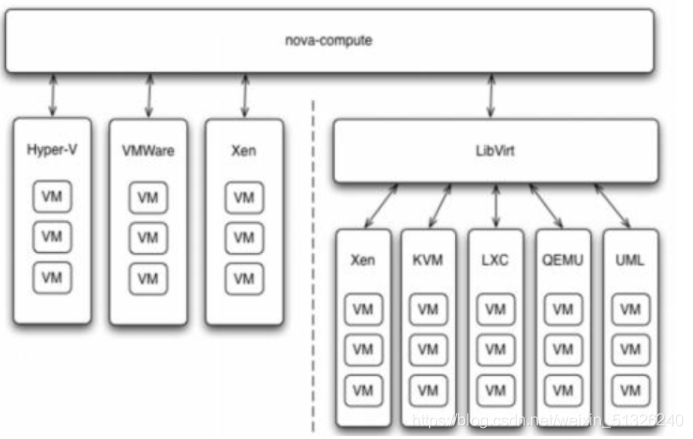
(2) Function
·Periodically report the status of computing nodes to OpenStack
·Every once in a while, Nova compute will report the resource usage and Nova compute service status of the current computing node.
·Nova compute obtains this information through the driver of Hypervisor.
·Realize the management of virtual machine instance life cycle
·OpenStack's main operations on virtual machine instances are implemented through Nova compute.
·Create, shut down, restart, suspend, resume, abort, resize, migrate, snapshot
·An example is given to illustrate the implementation process of Nova compute.
·(1) Prepare resources for the instance.
·(2) Create a mirror file of the instance.
·(3) Create an XML definition file for the instance.
·(4) Create a virtual network and start the virtual machine.
4. Conductor - Manager
·Implemented by Nova conductor module, it aims to provide a layer of security for database access.
·As an intermediary between Nova compute service and database, Nova conductor avoids direct access to the docking database created by Nova compute service.
·All operations of Nova compute accessing the database are changed to Nova conductor. Nova conductor acts as an agent for database operations, and Nova conductor is deployed on the control node
·Nova conductor helps improve database access performance. Nova compute can create multiple threads to access Nova conductor using remote procedure call (RPC).
·In a large-scale openstack deployment environment, administrators can cope with the increasing monthly access of computing nodes to the database by increasing the number of Nova conductors
5. PlacementAPI - management interface
·In the past, the management of resources was all undertaken by the computing node. In the statistics of resource usage, the resources of all computing nodes were simply accumulated, but there were also external resources in the system, which were provided by the external system. Such as storage resources provided by ceph, nfs, etc. Facing a variety of resource providers, administrators need a unified and simple management interface to count the resource usage in the system. This interface is PlacementAPl.
·The placement API is implemented by the Nova placement API service to track and record the directory and resource usage of resource providers.
·The types of resources consumed are tracked by class. Such as computing node class, shared storage pool class, IP address class, etc.
3, Virtual machine instantiation process
Users can access the console of the virtual machine in many ways
**· Nova novncproxy daemon: * * access the running instance through vnc connection and provide a proxy to support the browser novnc client.
·Nova spice html5 proxy daemon: access the running instance through spice connection, provide a proxy, and support clients based on html5 browser
·Nova xvpvncproxy daemon: access the running instance through vnc connection, provide a proxy, and support the java client dedicated to openstack
**· Nova consoleauth daemon: * * responsible for providing user token authentication for accessing the virtual machine console. This service must be used with the console agent
4, Console interface
·First, the user (either OpenStack end user or other programs) executes the commands provided by Nova Client to create the virtual machine
·Nova API service listens to HTTP requests from Nova Client, converts these requests into AMQP messages, and then joins the message queue.
·Call Nova conductor service through message queue.
·After the Nova conductor service receives the virtual machine instantiation request message from the message queue, it makes some preparations.
·The Nova conductor service tells the Nova Scheduler service through the message queue to select an appropriate computing node to create a virtual machine. At this time, the Nova scheduler will read the contents of the database.
·After the Nova conductor service obtains the appropriate information of the computing node from the Nova Scheduler service, it notifies the Nova compute service through the message queue to realize the creation of the virtual machine.
5, Structure
1. Nova deployment architecture
(1) Nova classic deployment architecture
One control node + multiple calculation nodes
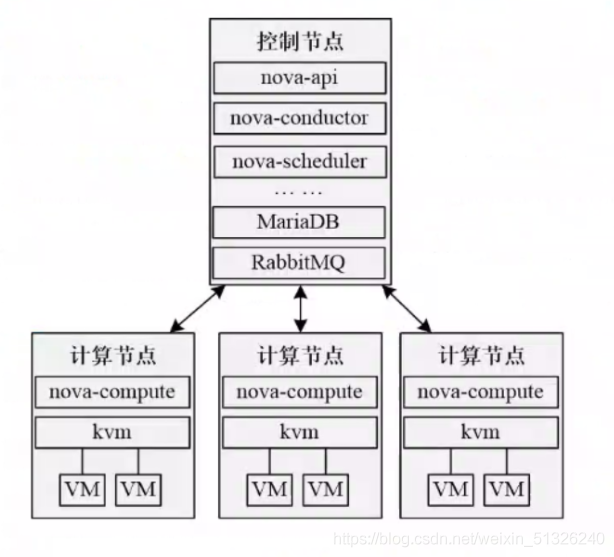
(2) Nova load balancing deployment architecture
Multiple control nodes + multiple computing nodes + independent databases (MariaDB, RabbitMQ)
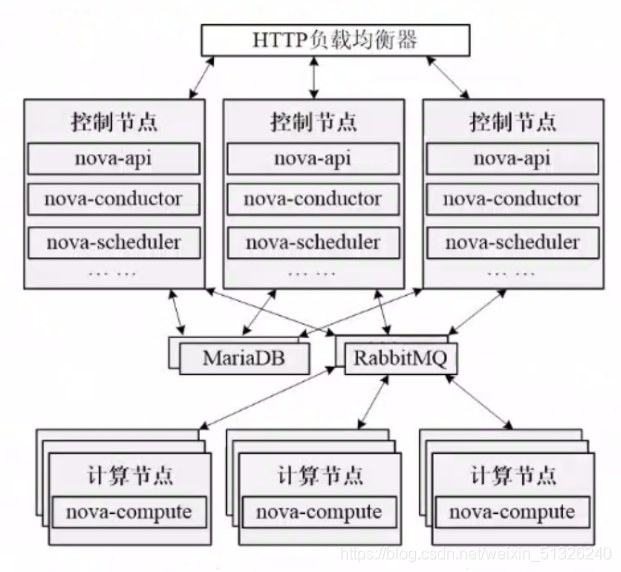
2. Nova's cell architecture
(1) Causes of cell
·When the scale of openstack nova cluster becomes larger, the database and message queue services will have bottleneck problems. Nova introduced the concept of Cell in order to improve the horizontal expansion, distributed and large-scale deployment capability without increasing the complexity of database and message middleware.
·Cell can be translated into unit. In order to support larger scale deployment, openstack divides the large nova cluster into small units. Each unit has its own message queue and database, which can solve the bottleneck problem caused by the increase of scale. In cell, Keystone, Neutron, Cinder, grace and other resources are shared.
(2) cell architecture diagram
Database on API node
· nova_api database stores global information. These global data tables are migrated from Nova database, such as flavor (instance model), instance groups (instance group) and quota (quota)
· nova_ The mode of cell0 database is the same as that of Nova. Its main purpose is that when the instance scheduling fails, the instance information does not belong to any cell, so it is stored in nova_cell0 is in the database.
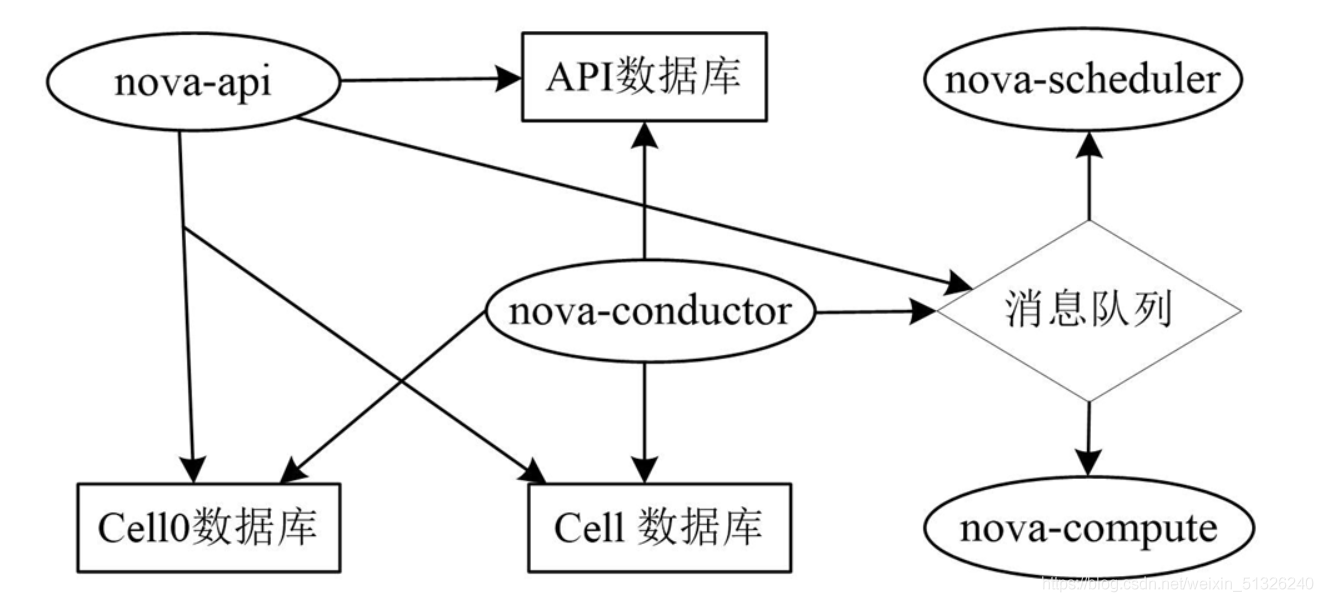
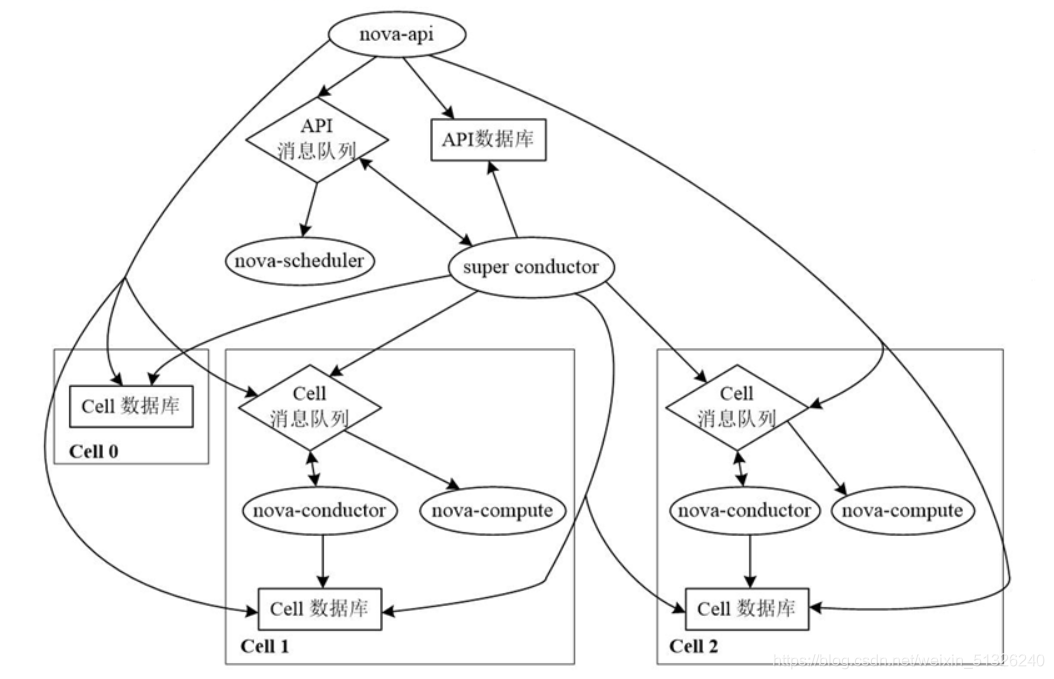
Architecture of Cells V2
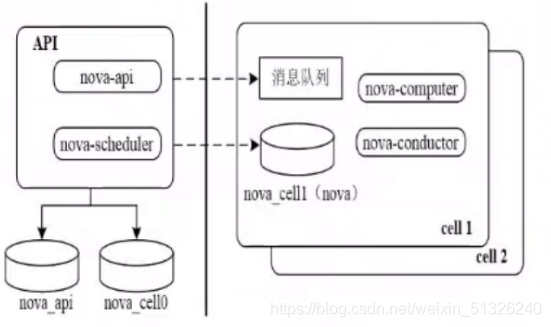
Single Cell deployment
Multi Cell deployment
6, Metadata for nova
·The function of metadata is to inject metadata information into the virtual machine instance, obtain its own metadata when the instance is started, and the cloud init tool in the instance completes personalized configuration according to the metadata.
·Openstack divides the metadata information obtained when cloud init customizes the virtual machine instance configuration into two categories
·Metadata
·User data.
·Metadata refers to structured data, which is injected into an instance in the form of key value pairs, including some common attributes of the instance itself
·Such as host name, network configuration information (IP address and security group), SSH key, etc.
·User data is unstructured data, which is injected through files or scripts, and supports a variety of file formats
·Such as gzip, shell and cloud init configuration files, which mainly include some commands and scripts, such as shell scripts.
·Openstack divides the configuration information injection mechanism of metadata and user data into two types
·One is to configure the drive mechanism
·The other is metadata service mechanism.
7, Openstack Nova component deployment
CT VM:192.168.100.20 NAT:192.168.37.100
nova API (nova main service)
nova scheduler (nova scheduling service)
nova conductor (nova database service, providing database access)
nova novncproxy (vnc service of nova, console providing instances)
C1 VM:192.168.100.30 NAT:192.168.37.110
C2 VM:192.168.100.40 NAT:192.168.37.40
nova compute (nova compute service)
1. Configure Nova service on CT control node
CT VM:192.168.100.20 NAT:192.168.37.100
(1) Create database instance and authorization
mysql -uroot -p CREATE DATABASE nova_api; GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS'; GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS'; CREATE DATABASE nova; GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS'; GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS'; CREATE DATABASE nova_cell0; GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS'; GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS'; flush privileges; exit
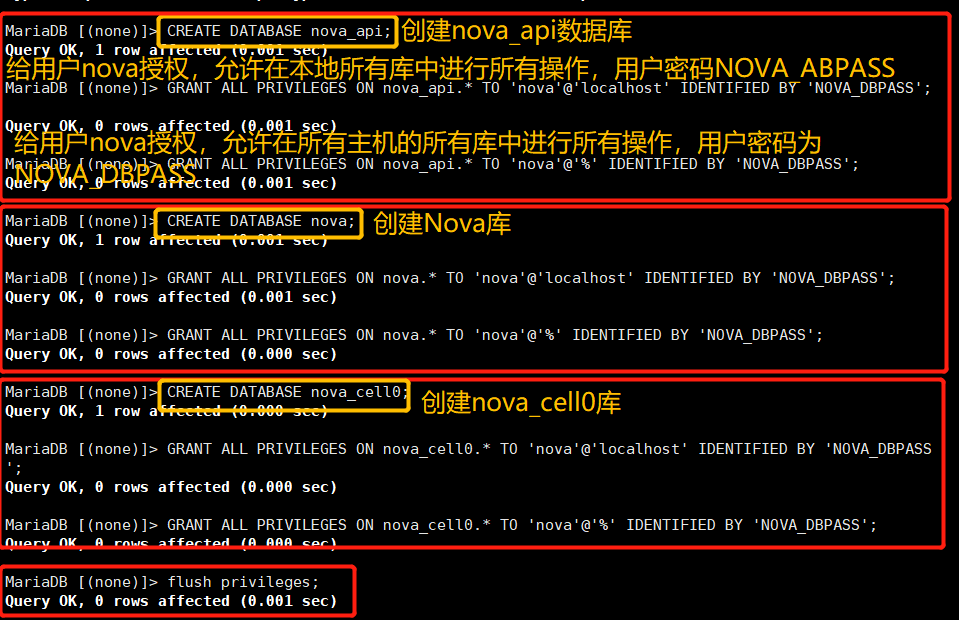
(2) Create user, modify profile
nova user who created OpenStack
#Create nova user; Verify openstack user list openstack user create --domain default --password NOVA_PASS nova #Add admin role to nova user; Verify the openstack role assignment list, and check the role, user and project list to see the id number openstack role add --project service --user nova admin #Create nova service entity; Verify openstack service list openstack service create --name nova --description "OpenStack Compute" compute
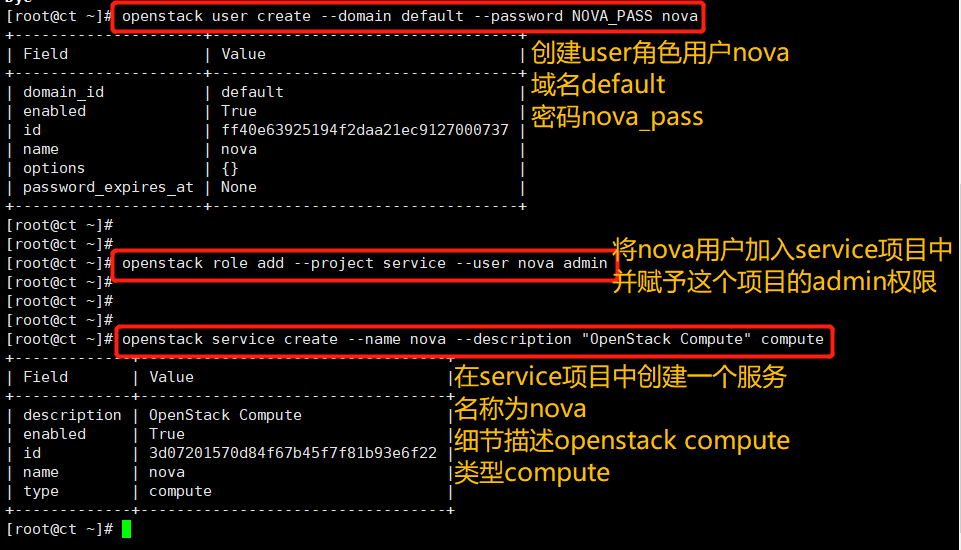
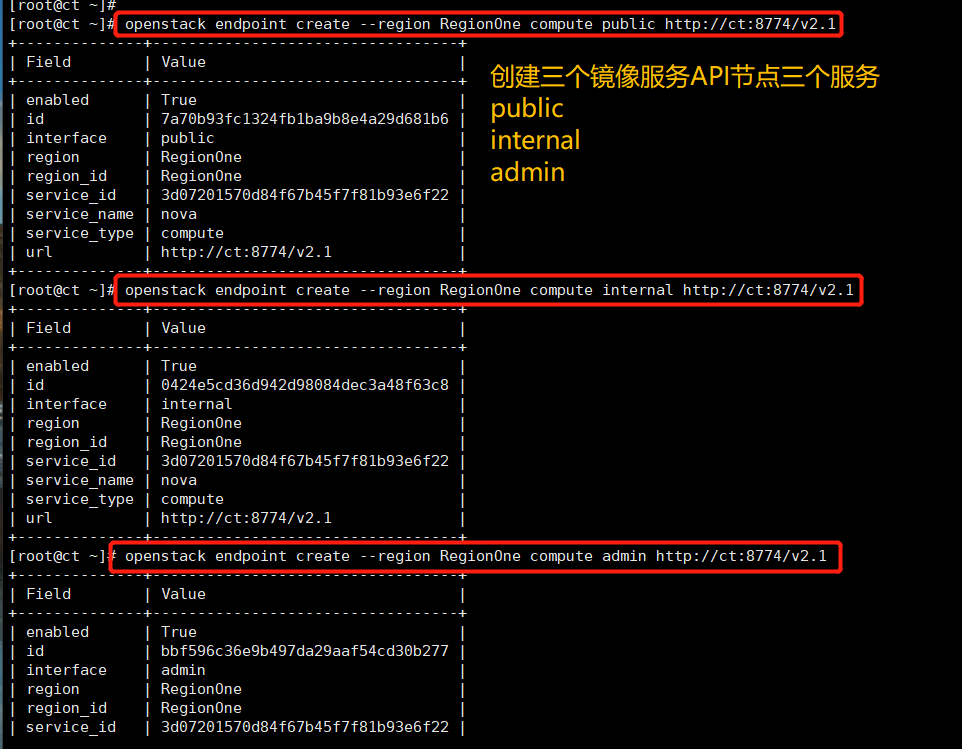
Create compute API service endpoint
openstack endpoint create --region RegionOne compute public http://ct:8774/v2.1 openstack endpoint create --region RegionOne compute internal http://ct:8774/v2.1 openstack endpoint create --region RegionOne compute admin http://ct:8774/v2.1
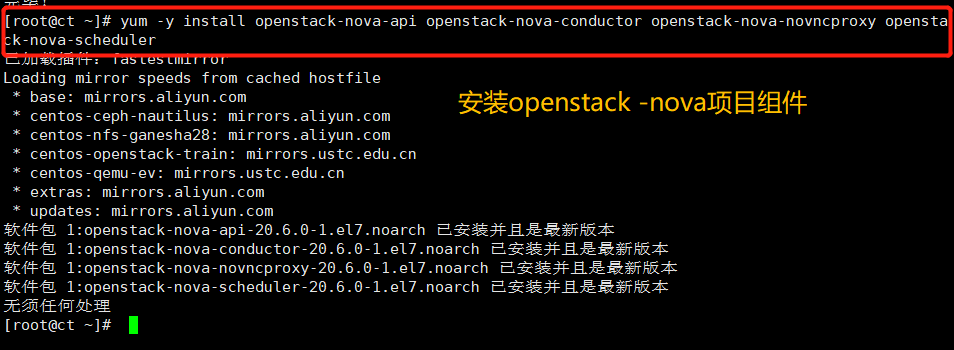
Install package
yum -y install openstack-nova-api openstack-nova-conductor openstack-nova-novncproxy openstack-nova-scheduler
Modify profile
cp -a /etc/nova/nova.conf{,.bak}
grep -Ev '^$|#' /etc/nova/nova.conf.bak > /etc/nova/nova.conf
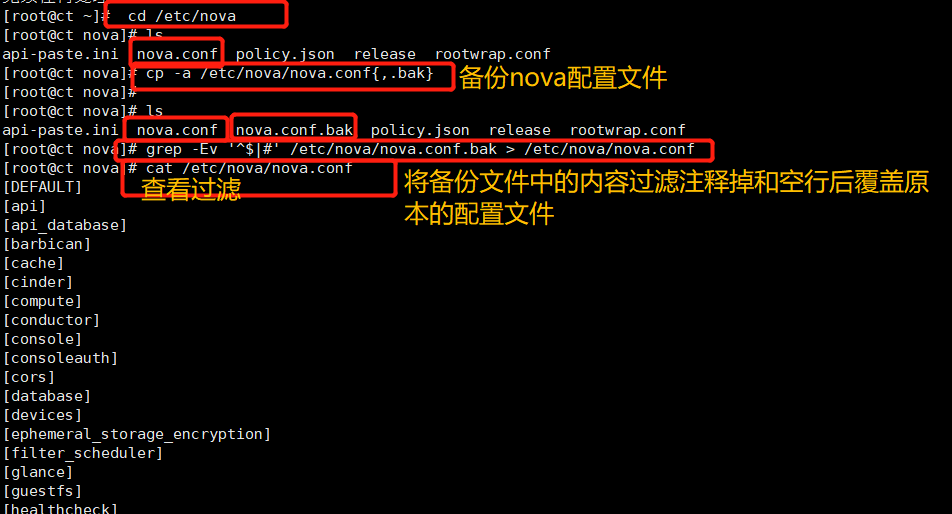
Add / etc / Nova / nova Conf configuration (parameter transmission)
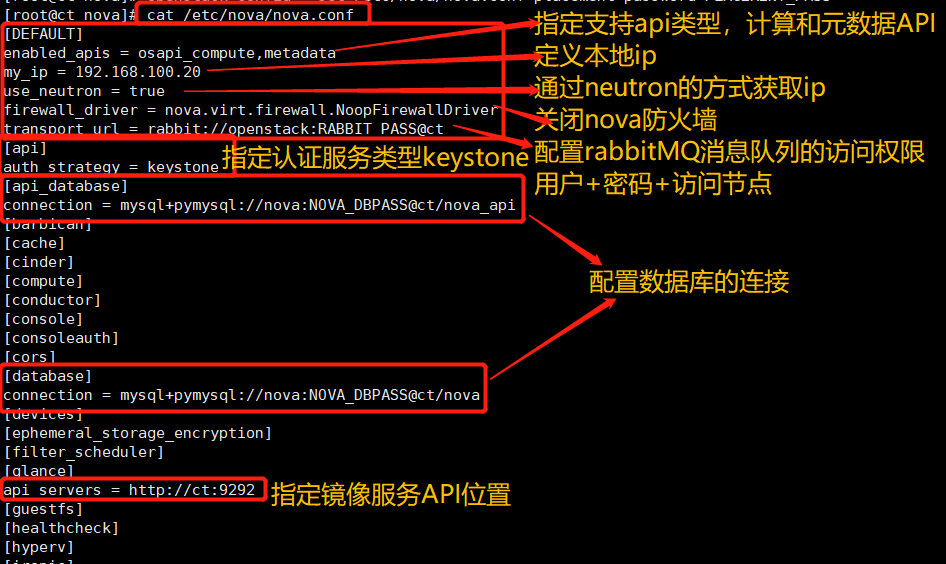
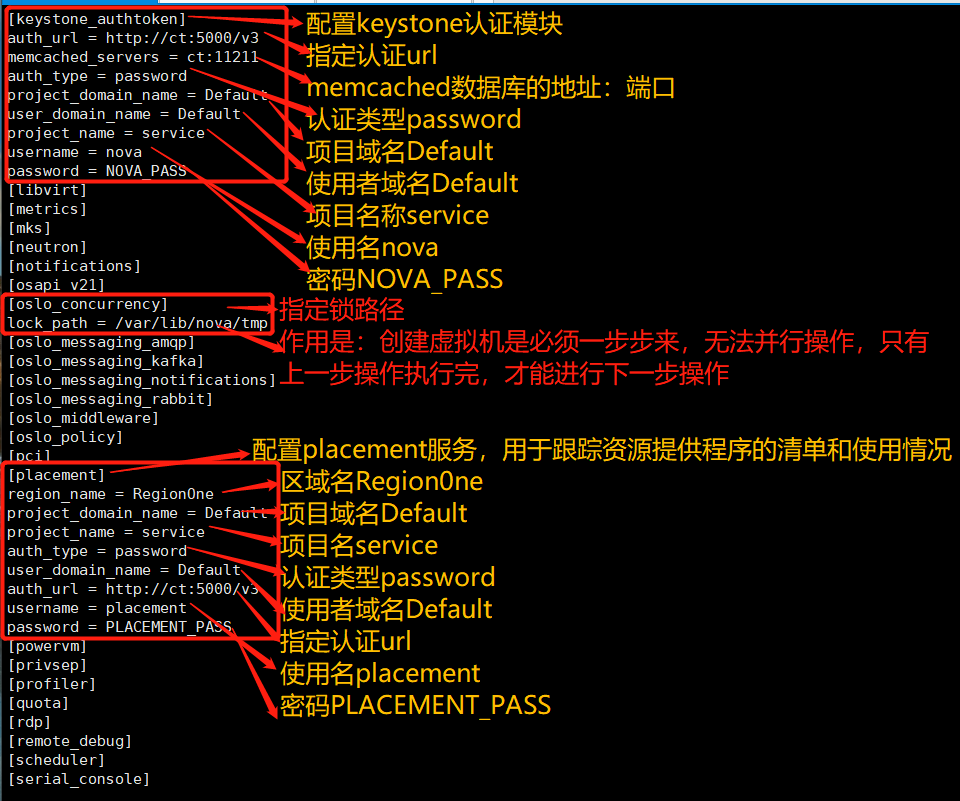
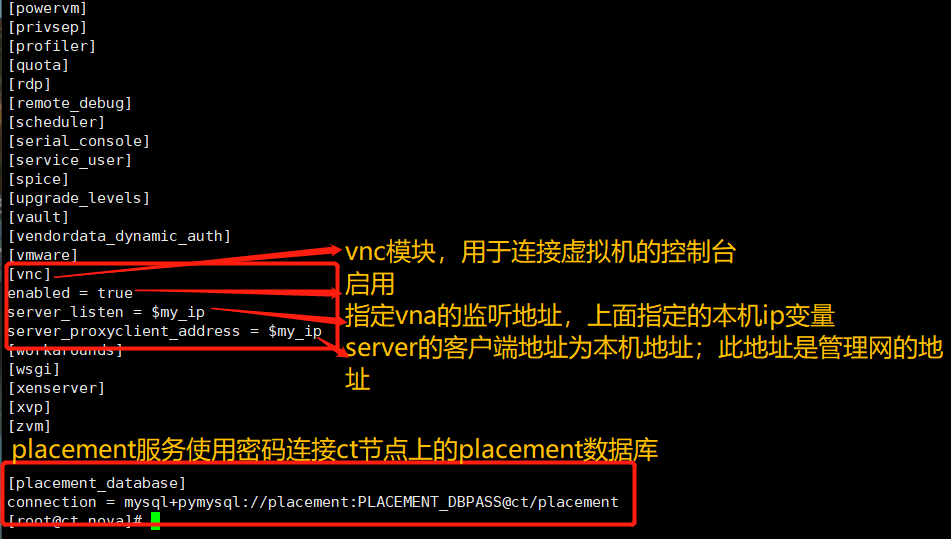
openstack-config --set /etc/nova/nova.conf DEFAULT enabled_apis osapi_compute,metadata openstack-config --set /etc/nova/nova.conf DEFAULT my_ip 192.168.100.20 openstack-config --set /etc/nova/nova.conf DEFAULT use_neutron true openstack-config --set /etc/nova/nova.conf DEFAULT firewall_driver nova.virt.firewall.NoopFirewallDriver openstack-config --set /etc/nova/nova.conf DEFAULT transport_url rabbit://openstack:RABBIT_PASS@ct openstack-config --set /etc/nova/nova.conf api_database connection mysql+pymysql://nova:NOVA_DBPASS@ct/nova_api openstack-config --set /etc/nova/nova.conf database connection mysql+pymysql://nova:NOVA_DBPASS@ct/nova openstack-config --set /etc/nova/nova.conf placement_database connection mysql+pymysql://placement:PLACEMENT_DBPASS@ct/placement openstack-config --set /etc/nova/nova.conf api auth_strategy keystone openstack-config --set /etc/nova/nova.conf keystone_authtoken auth_url http://ct:5000/v3 openstack-config --set /etc/nova/nova.conf keystone_authtoken memcached_servers ct:11211 openstack-config --set /etc/nova/nova.conf keystone_authtoken auth_type password openstack-config --set /etc/nova/nova.conf keystone_authtoken project_domain_name Default openstack-config --set /etc/nova/nova.conf keystone_authtoken user_domain_name Default openstack-config --set /etc/nova/nova.conf keystone_authtoken project_name service openstack-config --set /etc/nova/nova.conf keystone_authtoken username nova openstack-config --set /etc/nova/nova.conf keystone_authtoken password NOVA_PASS openstack-config --set /etc/nova/nova.conf vnc enabled true openstack-config --set /etc/nova/nova.conf vnc server_listen '$my_ip' openstack-config --set /etc/nova/nova.conf vnc server_proxyclient_address '$my_ip' openstack-config --set /etc/nova/nova.conf glance api_servers http://ct:9292 openstack-config --set /etc/nova/nova.conf oslo_concurrency lock_path /var/lib/nova/tmp openstack-config --set /etc/nova/nova.conf placement region_name RegionOne openstack-config --set /etc/nova/nova.conf placement project_domain_name Default openstack-config --set /etc/nova/nova.conf placement project_name service openstack-config --set /etc/nova/nova.conf placement auth_type password openstack-config --set /etc/nova/nova.conf placement user_domain_name Default openstack-config --set /etc/nova/nova.conf placement auth_url http://ct:5000/v3 openstack-config --set /etc/nova/nova.conf placement username placement openstack-config --set /etc/nova/nova.conf placement password PLACEMENT_PASS
Initialize nova database and generate related table structure
su -s /bin/sh -c "nova-manage api_db sync" nova su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova su -s /bin/sh -c "nova-manage db sync" nova
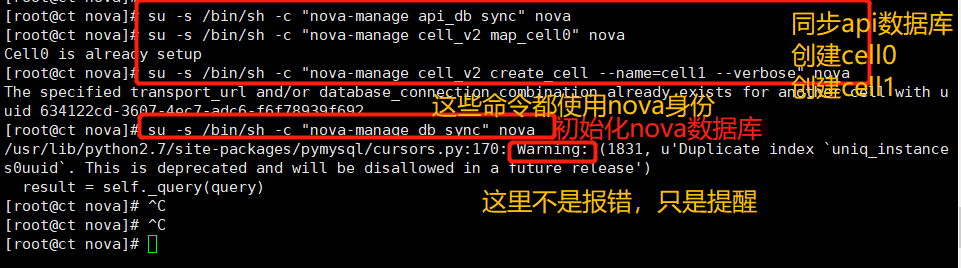
Verify that nova cell0 and cell1 are registered correctly
su -s /bin/sh -c "nova-manage cell_v2 list_cells" nova

Start Nova service and configure startup
systemctl start openstack-nova-api openstack-nova-scheduler openstack-nova-conductor openstack-nova-novncproxy systemctl enable openstack-nova-api openstack-nova-scheduler openstack-nova-conductor openstack-nova-novncproxy

The service startup error may be due to the lack of placement components
Check whether nova service is started
netstat -tnlup|egrep '8774|8775' curl http://ct:8774

2. Configure Nova service on C1 and C2 computing nodes
C1 VM:192.168.100.30 NAT:192.168.37.110
C2 VM:192.168.100.40 NAT:192.168.37.120
(1) Install the package and modify the configuration file
yum -y install openstack-nova-compute
cp -a /etc/nova/nova.conf{,.bak}
grep -Ev '^$|#' /etc/nova/nova.conf.bak > /etc/nova/nova.conf
Note: the third line of the following commands needs to modify the IP address of the current node (C1: 192.168.100.30 C2:192.168.100.40)
openstack-config --set /etc/nova/nova.conf DEFAULT enabled_apis osapi_compute,metadata openstack-config --set /etc/nova/nova.conf DEFAULT transport_url rabbit://openstack:RABBIT_PASS@ct openstack-config --set /etc/nova/nova.conf DEFAULT my_ip 192.168.100.30 openstack-config --set /etc/nova/nova.conf DEFAULT use_neutron true openstack-config --set /etc/nova/nova.conf DEFAULT firewall_driver nova.virt.firewall.NoopFirewallDriver openstack-config --set /etc/nova/nova.conf api auth_strategy keystone openstack-config --set /etc/nova/nova.conf keystone_authtoken auth_url http://ct:5000/v3 openstack-config --set /etc/nova/nova.conf keystone_authtoken memcached_servers ct:11211 openstack-config --set /etc/nova/nova.conf keystone_authtoken auth_type password openstack-config --set /etc/nova/nova.conf keystone_authtoken project_domain_name Default openstack-config --set /etc/nova/nova.conf keystone_authtoken user_domain_name Default openstack-config --set /etc/nova/nova.conf keystone_authtoken project_name service openstack-config --set /etc/nova/nova.conf keystone_authtoken username nova openstack-config --set /etc/nova/nova.conf keystone_authtoken password NOVA_PASS openstack-config --set /etc/nova/nova.conf vnc enabled true openstack-config --set /etc/nova/nova.conf vnc server_listen 0.0.0.0 openstack-config --set /etc/nova/nova.conf vnc server_proxyclient_address '$my_ip' openstack-config --set /etc/nova/nova.conf vnc novncproxy_base_url http://ct:6080/vnc_auto.html openstack-config --set /etc/nova/nova.conf glance api_servers http://ct:9292 openstack-config --set /etc/nova/nova.conf oslo_concurrency lock_path /var/lib/nova/tmp openstack-config --set /etc/nova/nova.conf placement region_name RegionOne openstack-config --set /etc/nova/nova.conf placement project_domain_name Default openstack-config --set /etc/nova/nova.conf placement project_name service openstack-config --set /etc/nova/nova.conf placement auth_type password openstack-config --set /etc/nova/nova.conf placement user_domain_name Default openstack-config --set /etc/nova/nova.conf placement auth_url http://ct:5000/v3 openstack-config --set /etc/nova/nova.conf placement username placement openstack-config --set /etc/nova/nova.conf placement password PLACEMENT_PASS openstack-config --set /etc/nova/nova.conf libvirt virt_type qemu
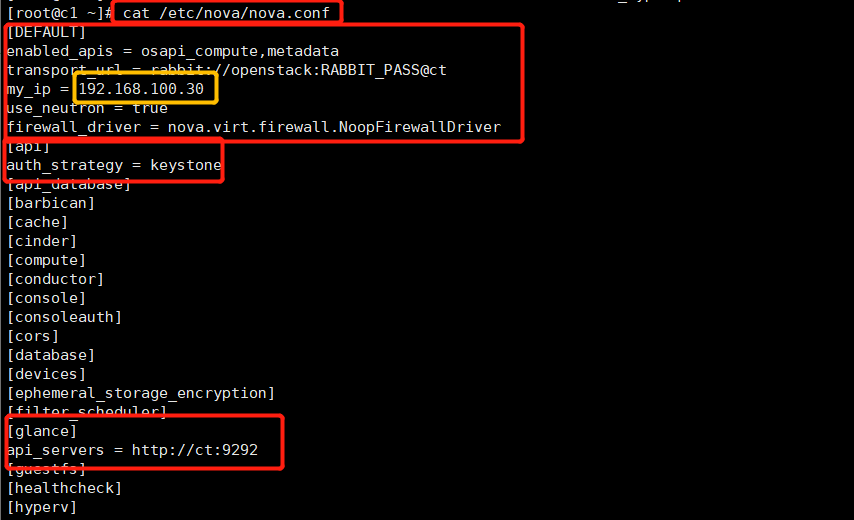
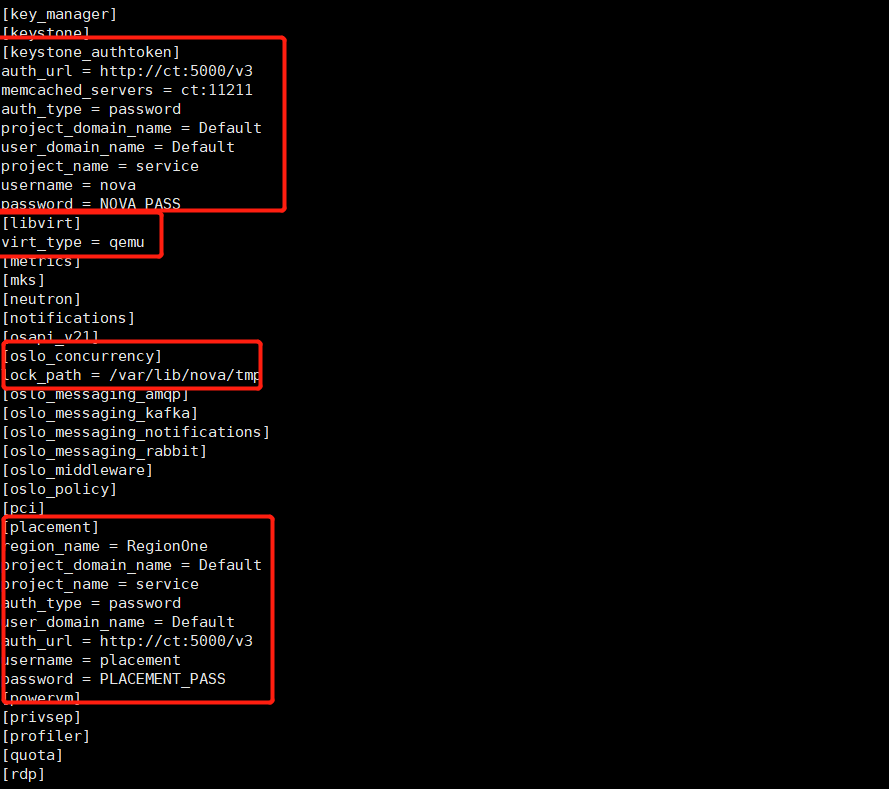
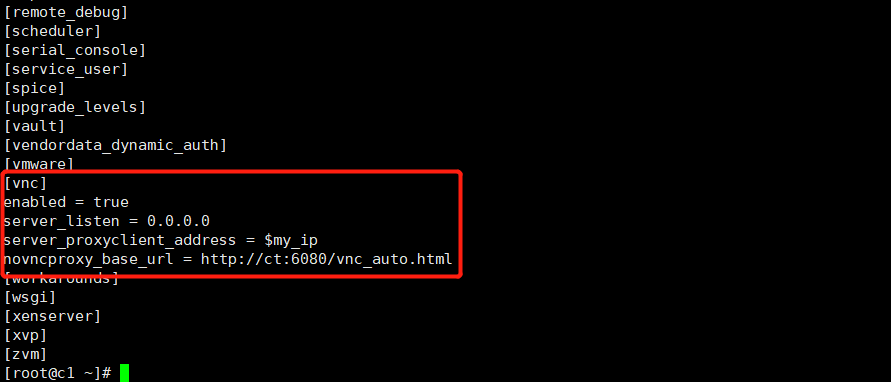
(2) Determine whether the computer supports virtual machine hardware acceleration
In fact, we have changed the configuration here. Check again to prevent configuration failure
egrep -c '(vmx|svm)' /proc/cpuinfo

If the return value of the above command is not 0, the computing node supports hardware acceleration and the following configuration is not required.
If the return value of the above command is 0, the computing node does not support hardware acceleration, and libvirt must be configured to use
QEMU instead of KVM, you need to edit / etc / Nova / nova [libvirt] section in conf file
vim /etc/nova/nova.conf
[libvirt]
virt_type = qemu
(3) Start Nova computing service and configure startup
systemctl start libvirtd.service openstack-nova-compute.service systemctl enable libvirtd.service openstack-nova-compute.service

Please note: when there are multiple compute nodes and the configuration file is copied to other compute nodes through the scp command, if it is found that the service cannot be started,
And the error is: "Failed to open some config files: /etc/nova/nova.conf", then the main reason is the wrong permission of the configuration file,
Need to modify nova The owner and group of the conf file are root.
3. Follow up operation of CT control node
CT VM:192.168.100.20 NAT:192.168.37.100
(1) Add calculation node to cell database
openstack compute service list --service nova-compute

(2) Discover compute nodes
su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
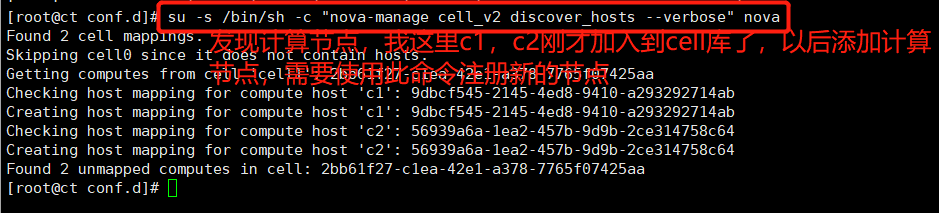
When adding new compute nodes later, you must run su -s /bin/sh -c "nova manage cell_v2 discover_hosts -- verbose" nova on the controller node to register these new compute nodes.
Set the appropriate discovery interval (optional)
vim /etc/nova/nova.conf [scheduler] discover_hosts_in_cells_interval = 300 systemctl restart openstack-nova-api.service


(3) Validate computing services
List the service components to verify the successful startup and registration of each process
openstack compute service list
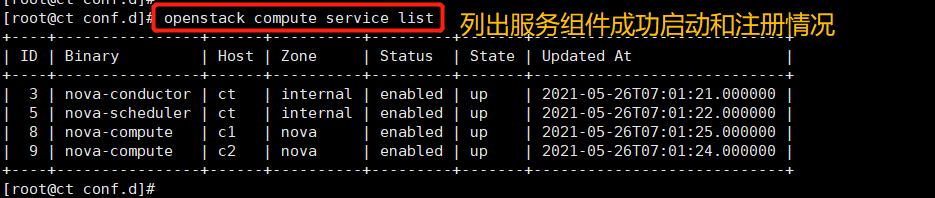
Lists the API endpoints in the identity service to verify the connection to the identity service
openstack catalog list
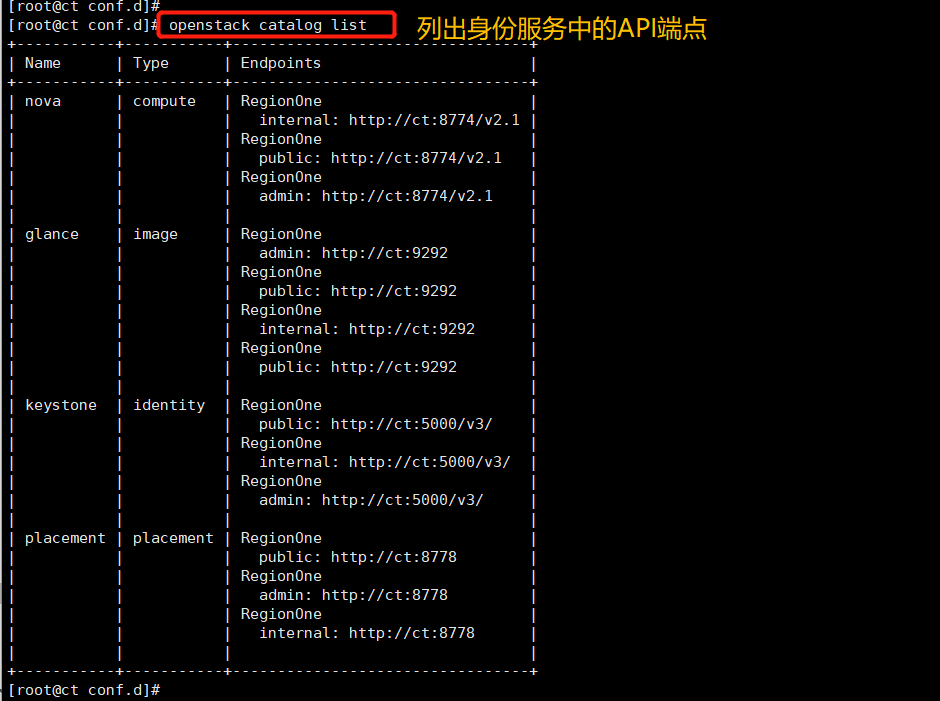
Lists the images in the image service to verify connectivity to the image service
openstack image list

Check that the Cells and placement API s are working properly
nova-status upgrade check
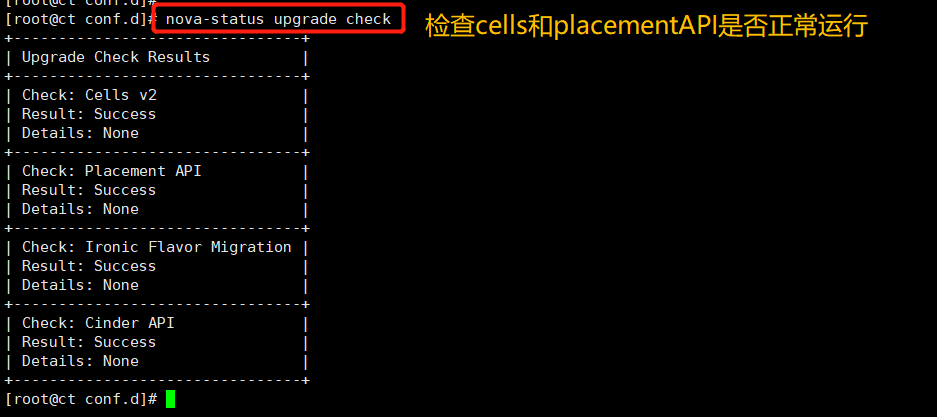
Summary:
There is an error when starting Nova service, or c1 and c2 start do not respond.
It may be incomplete components (less placement components)
Just install the placement.
Next step: OpenStack deployment (six) – Neutron network service