2021SC@SDUSC
KeyStone overview
Identity service is usually the first service with which users interact. After authentication, end users can use their identity to access other OpenStack services. Similarly, other OpenStack services use identity services to ensure that users are the people they claim and find the location of other services in the deployment. Identity services can also be integrated with some external user management systems, such as LDAP.
Users and services can use the service directory managed by the Identity service to locate other services. As the name suggests, a service directory is a collection of services available in an OpenStack deployment. Each service can have one or more endpoints, and each endpoint can be one of three types: administrative, internal, or public. In a production environment, for security reasons, different endpoint types may be located on different networks exposed to different types of users. For example, a public API network may be visible on the Internet, so customers can manage their cloud. The Management API network may be limited to operators managing cloud infrastructure within the organization. The internal API network may be limited to hosts that contain OpenStack services. In addition, OpenStack supports multiple regions for scalability. The regions, services, and endpoints created in the Identity service together constitute the deployed service directory. Each OpenStack service in your deployment requires a service entry, where the corresponding endpoint is stored in the Identity service. All this can be done after installing and configuring the Identity service.
The identity service consists of the following components:
The server
The central server provides authentication and authorization services using a RESTful interface.
Driver
The driver or service backend is integrated into the central server. They are used to access identity information in an OpenStack external repository and may already exist in the infrastructure where OpenStack is deployed (for example, an SQL database or LDAP server).
modular
The middleware module runs in the address space of the OpenStack component that uses identity services. These modules intercept service requests, extract user credentials, and send them to the central server for authorization. The integration between the middleware module and OpenStack components uses the Python Web server gateway interface.
Architecture diagram
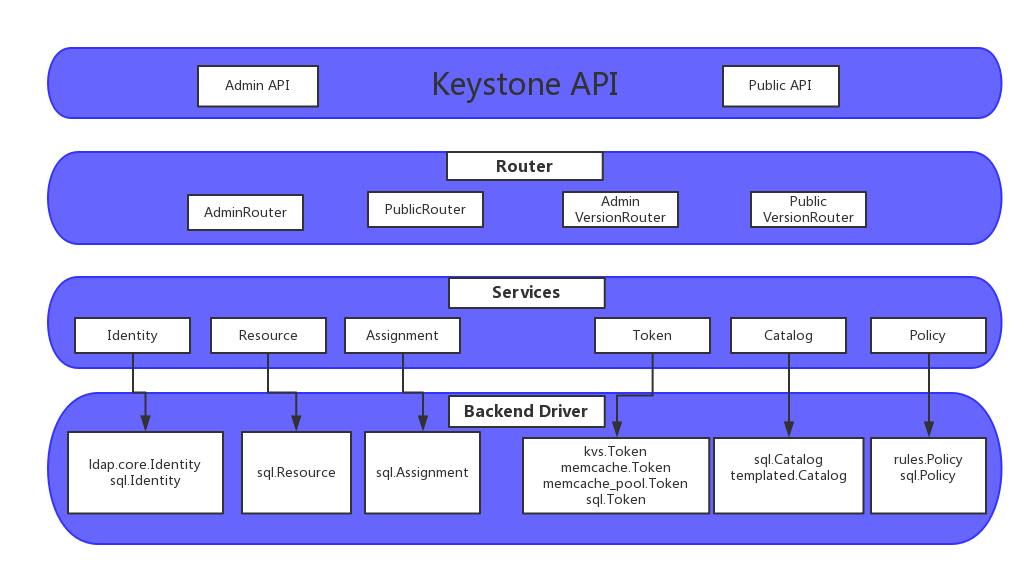
The Identity service provides authorization authentication and provides data about users and groups. In complex cases, data is managed by an authorization back-end service, and Identity service is the front-end of LDAP.
User: represents an individual API user. A user must be in its own domain, so the user name does not need to be globally unique, but it is unique in its own domain.
Groups: represents a collection of API users. A group must be in its own domain, so the group name does not need to be globally unique, but it is unique in its own domain.
The Resource service provides data about projects and domains.
Project: Project is the basic unit of OpenStack ownership. All resources in OpenStack must belong to a project and all projects must belong to a field. Therefore, the project name does not need to be globally unique, but is unique in its own domain. If the domain of an item is not specifically specified, it will be added to the default domain.
Domains: Domains is a high-level container for projects, users, and groups. Each domain defines a namespace.
The Assignment service provides data about roles and role assignments.
Roles: Roles specifies an authorization level that end users can obtain. You can grant roles at the domain or project level, and you can grant roles to individual users or groups. The role name is unique in its own domain.
Role Assignments: a (role, resource, identity) triple.
The Token service verifies the authorization requests of users with verified qualifications and manages tokens
The Catalog service provides an access point registration mechanism for discovering access points.
Begin to understand keystone system
Keystone is the HTTP front end of a series of services. It also uses the REST API interface. Each service has a corresponding back-end implementation. The names of these service backend in setup.cfg all have "base" or "backend". In fact, they also inherit from the base class.
Entry of setup.cfg_ The pointers module indicates the implementation class of each service provided by keystone. Observe the name of the service and find that the second field gives the category to which the service belongs (such as auth: authorization, identity: authentication, etc.).
Keystone access process
Take creating a virtual machine (server) as an example, and briefly describe the access process of keystone in openstack in combination with the following figure.
- First, users provide keystone with their own authentication information, such as user name and password. Keystone will read data from the database and verify it. If it passes the verification, it will return a token to the user. After that, all user requests will use the token for authentication. If a user applies to nova for a virtual machine service, nova will send the token provided by the user to keystone for authentication. Keystone will judge whether the user has the permission to perform this operation according to the token. If the authentication passes, nova will provide the corresponding service. The same is true for the interaction between other components and keystone.
Let's see how keystone completes this process in combination with the source code:
-
Authenticate the user name and password, and return the token(id)
The back-end of the authentication mechanism is a method authenticate(user_id,password) of the Identity class in identity/backends/ldap/core.py
def authenticate(self, user_id, password): try: user_ref = self._get_user(user_id) except exception.UserNotFound: raise AssertionError(_('Invalid user / password')) if not user_id or not password: raise AssertionError(_('Invalid user / password')) conn = None try: conn = self.user.get_connection(user_ref['dn'], password, end_user_auth=True) if not conn: raise AssertionError(_('Invalid user / password')) except Exception: raise AssertionError(_('Invalid user / password')) finally: if conn: conn.unbind_s() return self.user.filter_attributes(user_ref)It first tries to get user_id indicates user, if unsuccessful or user_ If the ID and password have null values, the error 'Invalid user / password' will be reported; If successful, try to connect to the LDAP server with password. Here, the get method of BaseLdap class in ldap/common.py is called_ connection(…)
def get_connection(self, user=None, password=None, end_user_auth=False): use_pool = self.use_pool pool_size = self.pool_size pool_conn_lifetime = self.pool_conn_lifetime if end_user_auth: if not self.use_auth_pool: use_pool = False else: pool_size = self.auth_pool_size pool_conn_lifetime = self.auth_pool_conn_lifetime conn = _get_connection(self.LDAP_URL, use_pool, use_auth_pool=end_user_auth) # Unfinished to be continuedRead this code carefully and you can see that it is called again_ get_connection(...) method to get the handler, if conn is given_ If the handler corresponding to the prefix of the URL is already in the registry, the handler will be returned directly. If use_ If the pool option is true, PooledLDAPHandler is returned; otherwise, Python ldaphandler is returned.
def _get_connection(conn_url, use_pool=False, use_auth_pool=False): for prefix, handler in _HANDLERS.items(): if conn_url.startswith(prefix): return handler() if use_pool: return PooledLDAPHandler(use_auth_pool=use_auth_pool) else: return PythonLDAPHandler()Regardless of the type of handler, it is converted to keystone LDAP handler in the next sentence
conn = KeystoneLDAPHandler(conn=conn)
Then, call conn.connect(...) to try to connect to the LDAP server.
try: conn.connect(self.LDAP_URL, page_size=self.page_size, alias_dereferencing=self.alias_dereferencing, use_tls=self.use_tls, tls_cacertfile=self.tls_cacertfile, tls_cacertdir=self.tls_cacertdir, tls_req_cert=self.tls_req_cert, chase_referrals=self.chase_referrals, debug_level=self.debug_level, conn_timeout=self.conn_timeout, use_pool=use_pool, pool_size=pool_size, pool_retry_max=self.pool_retry_max, pool_retry_delay=self.pool_retry_delay, pool_conn_timeout=self.pool_conn_timeout, pool_conn_lifetime=pool_conn_lifetime)Then judge that if the user is empty, use the user in conf. if the password is empty, use the password in conf. then package the user and password into conn and return to Conn. Finally, handle some exceptions.
if user is None: user = self.LDAP_USER if password is None: password = self.LDAP_PASSWORD # not all LDAP servers require authentication, so we don't bind # if we don't have any user/pass if user and password: conn.simple_bind_s(user, password) else: conn.simple_bind_s() return conn except ldap.INVALID_CREDENTIALS: raise exception.LDAPInvalidCredentialsError() except ldap.SERVER_DOWN: raise exception.LDAPServerConnectionError( url=self.LDAP_URL)Go back to Ldap/core.py. If you get conn correctly, it means that the password is correct. Unpack user and password and return other attributes of user except password, tenant and groups (defined in identity / backs / base. Py).
-
Verify the token and respond to the request carried by the token
The code to verify the token is in auth/plugins/token.py
def authenticate(self, auth_payload): if 'id' not in auth_payload: raise exception.ValidationError(attribute='id', target='token') token = self._get_token_ref(auth_payload) if token.is_federated and PROVIDERS.federation_api: response_data = mapped.handle_scoped_token( token, PROVIDERS.federation_api, PROVIDERS.identity_api ) else: response_data = token_authenticate(token) # NOTE(notmorgan): The Token auth method is *very* special and sets the # previous values to the method_names. This is because it can be used # for re-scoping and we want to maintain the values. Most # AuthMethodHandlers do no such thing and this is not required. response_data.setdefault('method_names', []).extend(token.methods) return base.AuthHandlerResponse(status=True, response_body=None, response_data=response_data)The core verification process is to call token_authenticate(token) is completed.
def token_authenticate(token): response_data = {} try: # Do not allow tokens used for delegation to # create another token, or perform any changes of # state in Keystone. To do so is to invite elevation of # privilege attacks json_body = flask.request.get_json(silent=True, force=True) or {} project_scoped = 'project' in json_body['auth'].get( 'scope', {} ) domain_scoped = 'domain' in json_body['auth'].get( 'scope', {} ) if token.oauth_scoped: raise exception.ForbiddenAction( action=_( 'Using OAuth-scoped token to create another token. ' 'Create a new OAuth-scoped token instead')) elif token.trust_scoped: raise exception.ForbiddenAction( action=_( 'Using trust-scoped token to create another token. ' 'Create a new trust-scoped token instead')) elif token.system_scoped and (project_scoped or domain_scoped): raise exception.ForbiddenAction( action=_( 'Using a system-scoped token to create a project-scoped ' 'or domain-scoped token is not allowed.' ) ) if not CONF.token.allow_rescope_scoped_token: # Do not allow conversion from scoped tokens. if token.project_scoped or token.domain_scoped: raise exception.ForbiddenAction( action=_('rescope a scoped token')) # New tokens maintain the audit_id of the original token in the # chain (if possible) as the second element in the audit data # structure. Look for the last element in the audit data structure # which will be either the audit_id of the token (in the case of # a token that has not been rescoped) or the audit_chain id (in # the case of a token that has been rescoped). try: token_audit_id = token.parent_audit_id or token.audit_id except IndexError: # NOTE(morganfainberg): In the case this is a token that was # issued prior to audit id existing, the chain is not tracked. token_audit_id = None # To prevent users from never having to re-authenticate, the original # token expiration time is maintained in the new token. Not doing this # would make it possible for a user to continuously bump token # expiration through token rescoping without proving their identity. response_data.setdefault('expires_at', token.expires_at) response_data['audit_id'] = token_audit_id response_data.setdefault('user_id', token.user_id) return response_data except AssertionError as e: LOG.error(e) raise exception.Unauthorized(e)
By understanding the whole process, we also have a preliminary understanding of keystone file structure. The auth package is related to "the user brings a thing and I'll verify whether it's right". Among them, the plugins sub package is the code to verify various things; The method related functions in core.py are responsible for loading the methods used to verify the specified things. AuthContext class is defined to integrate the required attributes of various verification plugins, AuthInfo is used to encapsulate authorization requests, and UserMFARulesValidator is used to help verify MFA Rules.