introduction
Handwritten numeral recognition is a very basic pattern recognition problem. Recognition methods from traditional feature extraction and machine learning training to deep neural network training will achieve relatively high accuracy. At the same time, handwritten numeral recognition is also a particularly unstable model, which is difficult to have universality, and needs targeted data sets and training, Then we can get better recognition accuracy. OpenVINO ™ The pre training model of handwritten numeral recognition has been added in version 2021.4 to support handwritten numeral recognition. Take the following figure (figure-1) as an example, let's explore and try its use method and effect!

Figure-1 (original)
Model introduction
In OpenVINO ™ The handwritten numeral recognition model supported in 2021.4 is handwritten-score-recognition-0003
, support or Digital recognition and decimal point recognition of format. The structure of the model consists of two parts. The front is a typical CNN backbone network, which adopts a VGG-16 similar architecture to realize feature extraction; The latter is a bidirectional LSTM network to realize sequence prediction; The final prediction result can be analyzed based on CTC. The input and output formats are as follows:
The input format is: [NCHW]= [1x1x32x64]
The output format is: [wxbxl] = [16x13]
Where 13 represents "0123456789. #", # represents blank_ Represents a non numeric character
The decoding method of the output format supports CTC greedy and Beam search. The demonstration program uses CTC greedy decoding. This method is relatively simple. We have described it in detail in the previous article, and we can apply it directly later!
Model use and demonstration
The use of this model must be based on the ROI area obtained from common text detection, and then transformed into gray image. The prediction is completed by using this model. I have explained in detail about scene text detection in the previous article, so I won't repeat it here. Here, the small brain hole is wide open. For common text images, OpenCV binary image contour analysis is used to intercept the digital ROI area, and good results are also achieved. The basic process is as follows:
Step 1: read the image and binarize it
The code is as follows
Mat src = imread("D:/images/zsxq/ocr.png");
imshow("input", src);
Mat gray, binary;
cvtColor(src, gray, COLOR_BGR2GRAY);
adaptiveThreshold(gray, binary, 255, ADAPTIVE_THRESH_GAUSSIAN_C, THRESH_BINARY_INV, 25, 10);
The adaptive threshold function realizes the adaptive binarization of gray image. The parameter blockSize=25 represents the Gaussian window size and constants=10 represents the adaptive constant value. Note that the value of the parameter blockSize must be odd. The output binary image is shown in figure-2
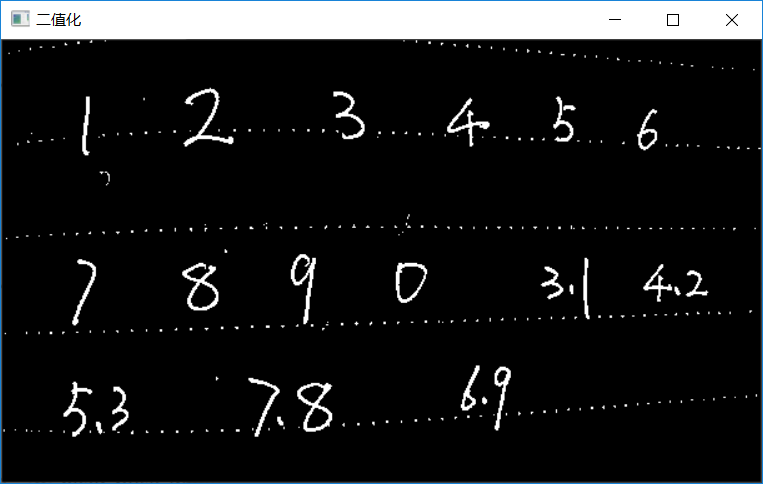
Figure-2 (adaptive binarization)
Step 2: filter small noise using contour analysis overfill
The code is as follows
std::vector<vector<Point>> contours;
std::vector<Vec4i> hireachy;
findContours(binary, contours, hireachy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
int image_height = src.rows;
int image_width = src.cols;
for (size_t t = 0; t < contours.size(); t++) {
double area = contourArea(contours[t]);
if (area < 10) {
drawContours(binary, contours, t, Scalar(0), -1, 8);
}
}
The above code findContours indicates contour discovery and RETR_EXTERNAL means to find the outermost contour by using CHAIN_APPROX_SIMPLE means that the pixel set on the contour is collected by simple chain coding. contourArea means to calculate the area of a contour. The calculation method is based on Green's integral formula. drawContours refers to drawing outline, where thickness parameter - 1 refers to filling, and greater than zero refers to drawing edge. Here, the noise is removed by filling the white noise with black. The following figure is the image after interference removal:
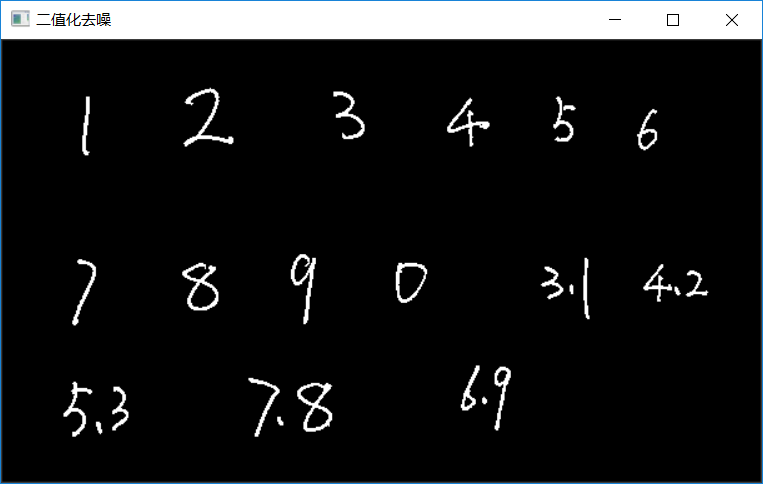
Figure-3 (after denoising)
Step 3: expansion pretreatment
For the image output in the second step, we can't intercept ROI directly through contour discovery, and then hand it over to the digital recognition network for recognition. The reason is that this will lead to the imbalance of the aspect ratio of the ROI area, resulting in the distortion of the input number after resizing, and the recognition accuracy will be reduced. Therefore, we can appropriately widen and heighten the number through expansion operation, mainly widening, In this way, it is easy to identify by keeping the invariance after resizing the input ROI area. The preprocessing code of this part is as follows:
Mat se = getStructuringElement(MORPH_RECT, Size(45, 5)); Mat temp; dilate(binary, temp, se);
dilate represents the expansion operation, and then the temp late image is obtained. The output of this operation is as follows:
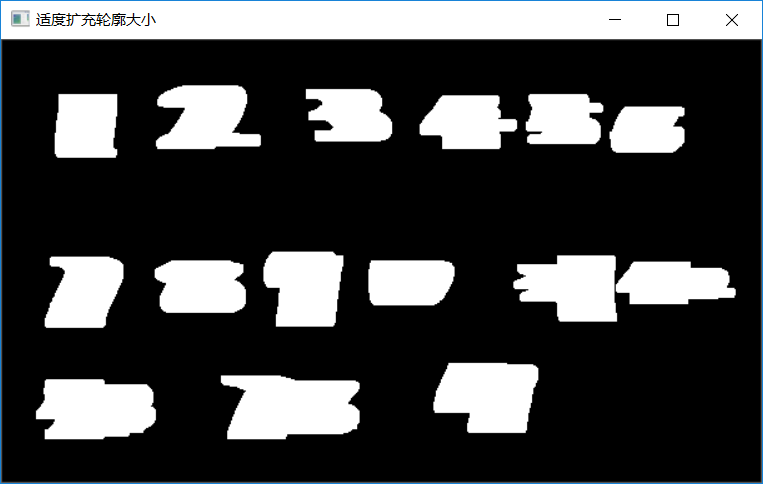
Figure-4 (after moderate expansion)
Step 4: digital recognition reasoning and analysis
Find the contour of figure-4, intercept ROI, traverse each contour, and call recognition reasoning to output. The loading model and obtaining reasoning request will not be repeated here. The code of intercepting ROI and reasoning analysis is as follows:
// Process output results
findContours(temp, contours, hireachy, RETR_EXTERNAL, CHAIN_APPROX_SIMPLE);
for (size_t t = 0; t < contours.size(); t++) {
Rect box = boundingRect(contours[t]);
Mat roi = gray(box);
size_t image_size = h*w;
Mat blob_image;
resize(roi, blob_image, Size(w, h));
// NCHW
unsigned char* data = static_cast<unsigned char*>(input->buffer());
for (size_t row = 0; row < h; row++) {
for (size_t col = 0; col < w; col++) {
data[row*w + col] = blob_image.at<uchar>(row, col);
}
}
// Execute forecast
infer_request.Infer();
auto output = infer_request.GetBlob(output_name);
const float* blob_out = static_cast<PrecisionTrait<Precision::FP32>::value_type*>(output->buffer());
const SizeVector reco_dims = output->getTensorDesc().getDims();
const int RW = reco_dims[0];
const int RB = reco_dims[1];
const int RL = reco_dims[2];
std::string ocr_txt = ctc_decode(blob_out, RW, RL);
std::cout << ocr_txt << std::endl;
cv::putText(src, ocr_txt, box.tl(), cv::FONT_HERSHEY_PLAIN, 1.0, cv::Scalar(255, 0, 0), 1)
cv::rectangle(src, box, Scalar(0, 0, 255), 2, 8, 0);
}
Firstly, the contour is found, then the ROI area is intercepted according to each contour, the input data is set, the reasoning and analysis output adopts CTC mode, and the final output is shown in the following figure:
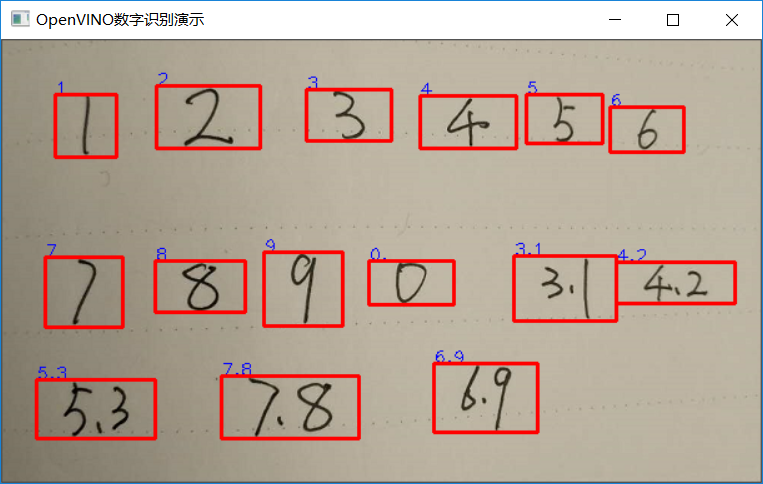
Figure-5 (operation results)
Extended exploration
Instead of using scene text detection to obtain ROI, I use traditional binary image analysis to avoid overlapping with the previous text content and inspire more ideas. In addition, expansion expansion is sometimes not the best choice, but can also be expanded by directly modifying the ROI size. In fact, this part can refer to the code of text recognition in the previous scene. Figure-6 shows the way to obtain the external rectangle after binarization, directly modify the ROI size, and filter non digital symbols according to the horizontal and vertical ratio. The change part is to remove the expansion in the third step, and then directly add the following code in the fourth step cycle;
Rect box = boundingRect(contours[t]);
float rate = box.width / box.height;
if (rate > 1.5) {
continue;
}
box.x = box.x - 15;
box.width = box.width + 30;
box.y = box.y - 5;
box.height = box.height + 10;

Figure-6