Problem description
To complete the parallel optimization of the sum by column protocol program, the main requirements are as follows:
∙
\bullet
∙ only one Tesla K40m GPU can be used for calculation.
∙
\bullet
· test the acceleration effect of several typical scales in the annex slurm.
Original code parsing:

Code operation: after entering the folder, we first load the cuda module. Here, we need to use the command:
module add cuda/9.0 loads cuda version 9.0.
Then use make to compile. If you directly use make or load cuda with the wrong version and compile, some intermediate files will be generated. At this time, the compilation will report an error. At this time, reloading cuda with version 9.0 will still report an error. The reason is that these intermediate files may affect the compilation, At this time, you need to use the command make clean to delete the previously generated file with suffix o and recompile it. After the original version of the code is run, it will print the time after the matrix specifications of different shapes, including the running time of CPU, GPU and kernel.

Code description
The only difference between the later versions of the code is col_reduce.cu, the rest of the code remains unchanged.
Makefile
CC = gcc CFLAGS = -std=c99 NVCC = nvcc NVCC_FLAGS = --gpu-architecture=sm_35 -std=c++11 -O3 -Wno-deprecated-gpu-targets LIBRARIES = -L/mnt/lustrefs/softwares/cuda/9.0/lib64 -lcudart -lm col_reduce: main.o cpu_col_reduce.o gpu_col_reduce.o $(CC) $^ -o $@ $(LIBRARIES) main.o: main.c $(CC) $(CFLAGS) -c $^ -o $@ cpu_col_reduce.o: col_reduce.c $(CC) $(CFLAGS) -c $^ -o $@ gpu_col_reduce.o: col_reduce.cu $(NVCC) $(NVCC_FLAGS) -c $^ -o $@ clean: rm -f *.o col_reduce
col_reduce.c
// M: [m, n]
// vec: [n]
void cpu_mat_column_reduce(double* mat, double* vec, int m, int n) {
for (int i = 0; i < n; i++) { // n col
double sum = 0.0;
for (int j = 0; j < m; j++) { // m row
sum += mat[j * n + i];
}
vec[i] = sum;
}
}
col_reduce.h
#ifndef MAT_MUL_H
#define MAT_MUL_H
#include <stdio.h>
#include <time.h>
#include <sys/time.h>
#define SEED 0
void cpu_mat_column_reduce(double* mat, double* vec, int m, int n);
void gpu_mat_column_reduce(double* mat, double* vec, int m, int n);
// Returns a randomized matrix containing mxn elements
static inline double *rand_mat(int m, int n) {
srand(SEED);
double *mat = (double *) malloc(m * n * sizeof(double));
if (mat == NULL) {
printf("Error allocating CPU memory");
exit(1);
}
for(int i = 0; i < m; i++){
for(int j = 0; j < n; j++){
mat[i * n + j] = (double)(rand() % 10) / 100000.0;
}
}
return mat;
}
// Returns a raw matrix containing n elements
static inline double *raw_mat(int m, int n) {
double *mat = (double *) malloc(m * n * sizeof(double));
if (mat == NULL) {
printf("Error allocating CPU memory");
exit(1);
}
return mat;
}
// Returns a raw matrix containing n elements
static inline double *zero_vec(int m) {
double *vec = (double *) malloc(m * sizeof(double));
if (vec == NULL) {
printf("Error allocating CPU memory");
exit(1);
}
for (int i = 0; i < m; i++) {
vec[i] = 0.0;
}
return vec;
}
// Returns the current time in microseconds
static inline long long start_timer() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec*1000000 + tv.tv_usec;
}
// Prints the time elapsed since the specified time
static inline long long stop_timer(long long start_time, char *name) {
struct timeval tv;
gettimeofday(&tv, NULL);
long long end_time = tv.tv_sec*1000000 + tv.tv_usec;
printf("%s: %f milisec\n", name, ((double) (end_time - start_time)) / 1000);
return end_time - start_time;
}
#endif
main.c
/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "col_reduce.h"
int main(int argc, char **argv){
int m = 3; // default value
int n= 3; // default value
if (argc == 3) {
m = atoi(argv[1]); // user-specified value
n = atoi(argv[2]); // user-specified value
}
printf("\nDo column reduce on mat m: %d n: %d ...\n", m, n);
double* mat = rand_mat(m, n);
double* cpu_vec = zero_vec(n);
double* host_vec = zero_vec(n);
// CPU
long long cpu_start_time = start_timer();
cpu_mat_column_reduce(mat, cpu_vec, m, n);
long long cpu_time = stop_timer(cpu_start_time, "CPU");
// GPU
long long gpu_start_time = start_timer();
gpu_mat_column_reduce(mat, host_vec, m, n);
long long gpu_time = stop_timer(gpu_start_time, "GPU");
// Check the correctness of the GPU results
int num_wrong = 0;
for (int i = 0; i < n; i++) {
if (fabs(cpu_vec[i] - host_vec[i]) > 0.001) {
num_wrong++;
printf("cpu vec: %f, host vec: %f \n", cpu_vec[i], host_vec[i]);
}
}
// Report the correctness results
if (num_wrong) printf("GPU %d / %d values incorrect\n", num_wrong, n);
else printf("Passed, GPU all values correct!\n");
free(mat);
free(cpu_vec);
free(host_vec);
}
run.slurm
#!/bin/bash #SBATCH -o job_%j_%N.out #SBATCH --partition=gpu #SBATCH -J col_reduce #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --gres=gpu:1 #SBATCH -t 20:00 module add cuda/9.0 ./col_reduce 160000 8 ./col_reduce 1600000 8 ./col_reduce 6400000 8 ./col_reduce 160000 32 ./col_reduce 1600000 32 ./col_reduce 6400000 32 ./col_reduce 160000 64 ./col_reduce 1600000 64
col_reduce.cu
#include <cuda.h>
#include <stdio.h>
#include <math.h>
#define ThreadNum 128
#if !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
static __inline__ __device__ double atomicAdd(double *address, double val) {
unsigned long long int* address_as_ull = (unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
if (val==0.0)
return __longlong_as_double(old);
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val +__longlong_as_double(assumed)));
} while (assumed != old);
return __longlong_as_double(old);
}
#endif
extern "C" void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n);
__global__
void gpu_mat_col_reduce_kernel(double* mat, double* vec, int m, int n){
int i = blockIdx.x * blockDim.x + threadIdx.x;
if(i < n){
double sum = 0.0;
for (int j = 0; j < m; j++) { // m row
sum += mat[j * n + i];
}
vec[i] = sum;
}
}
void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n) {
double *d_M, *d_vec;
size_t size_of_float = sizeof(double);
size_t size_M = m * n * size_of_float;
size_t size_vec = n * size_of_float;
// malloc and memcpy
cudaMalloc((void**)&d_M, size_M);
cudaMalloc((void**)&d_vec, size_vec);
cudaMemcpy(d_M, h_M, size_M, cudaMemcpyHostToDevice);
cudaMemcpy(d_vec, h_vec, size_vec, cudaMemcpyHostToDevice);
// timing
cudaEvent_t start, stop;
float elapsed_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// running
dim3 grid_dim(int(ceil((double)n/ThreadNum)), 1, 1);
dim3 block_dim(ThreadNum, 1, 1);
gpu_mat_col_reduce_kernel<<<grid_dim, block_dim>>>(d_M, d_vec, m, n);
// timing
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_time, start, stop);
// memcpy
cudaMemcpy(h_vec, d_vec, size_vec, cudaMemcpyDeviceToHost);
// print res
printf(" grid dim: %d, %d, %d.\n", grid_dim.x, grid_dim.y, grid_dim.z);
printf(" block dim: %d, %d, %d.\n", block_dim.x, block_dim.y, block_dim.z);
printf(" kernel time: %f milisec\n", elapsed_time);
// free
cudaFree(d_M);
cudaFree(d_vec);
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
Version optimization
high1
In the above original code, since the maximum n is only 64 and rounded up according to 64 divided by 128, the first dimension of grid is 1 and blockdim Although x is 128, n only takes 64 at most, so a large number of threads will be idle. In the original code above, each thread handles the summation of a column of elements. We think about whether multiple threads can operate a column according to this idea. The specific ideas are as follows:
We set blockdim x = 64 indicates that in the x dimension, a row of thread processing operations and a column of elements are viewed, and then blockdim is considered y. Due to the limitation of the machine, a block can only have 1024 threads at most, so set blockdim Y = 16, that is, each column of elements is divided into 16 parts, and one thread operates a section. After the 16 threads operate, these results are added up respectively. \textbf {note:} after we do this, because different threads operate on a section of the element of the column, we finally need to add the sum calculated by different threads to the vec. There is a read-write conflict here. Therefore, we need to use atomic operation to avoid this conflict,
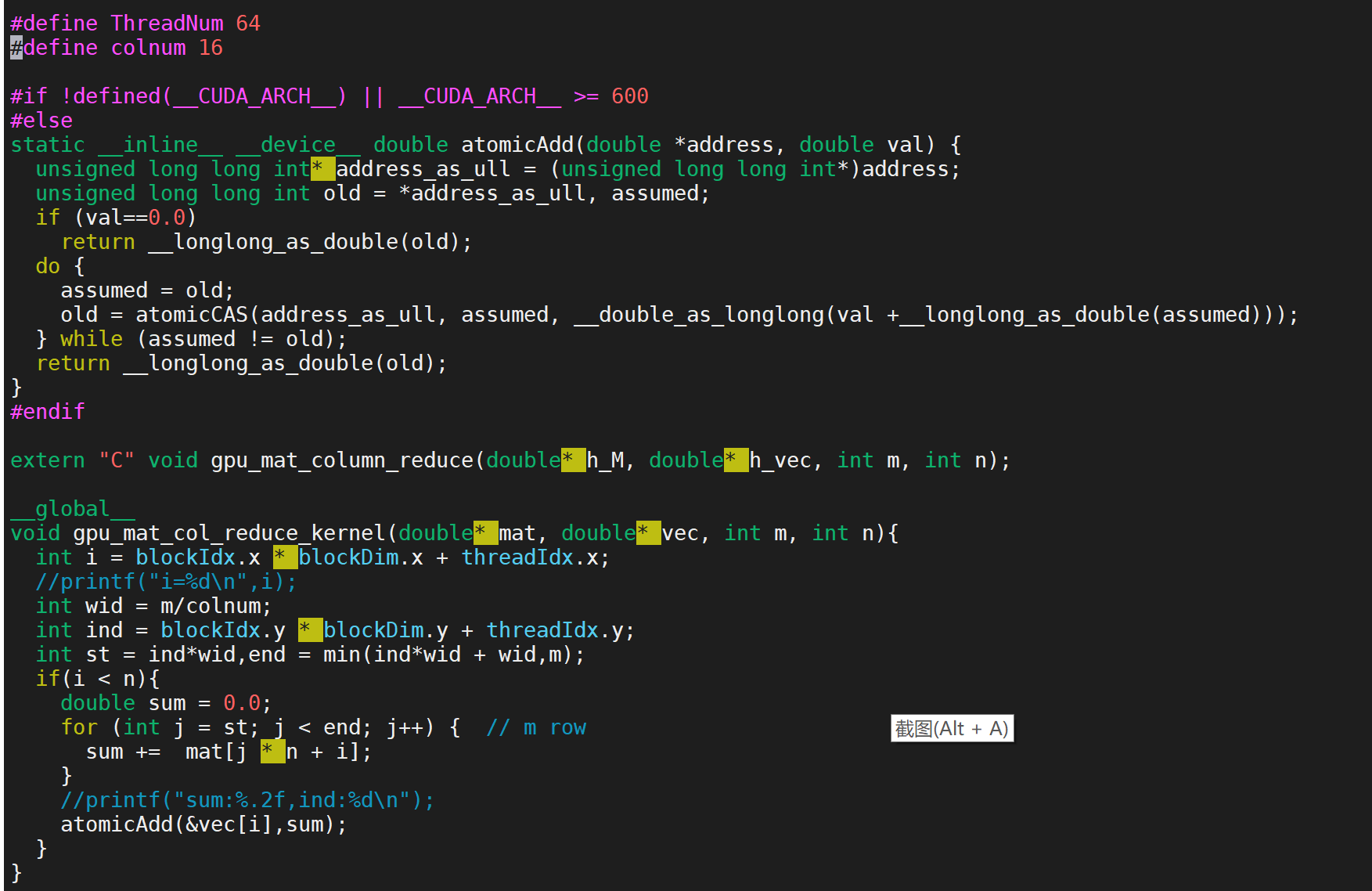
col_reduce.cu
#include <cuda.h>
#include <stdio.h>
#include <math.h>
#define ThreadNum 64
#define colnum 16
#if !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
static __inline__ __device__ double atomicAdd(double *address, double val) {
unsigned long long int* address_as_ull = (unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
if (val==0.0)
return __longlong_as_double(old);
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val +__longlong_as_double(assumed)));
} while (assumed != old);
return __longlong_as_double(old);
}
#endif
extern "C" void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n);
__global__
void gpu_mat_col_reduce_kernel(double* mat, double* vec, int m, int n){
int i = blockIdx.x * blockDim.x + threadIdx.x;
//printf("i=%d\n",i);
int wid = m/colnum;
int ind = blockIdx.y * blockDim.y + threadIdx.y;
int st = ind*wid,end = min(ind*wid + wid,m);
if(i < n){
double sum = 0.0;
for (int j = st; j < end; j++) { // m row
sum += mat[j * n + i];
}
//printf("sum:%.2f,ind:%d\n");
atomicAdd(&vec[i],sum);
}
}
void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n) {
double *d_M, *d_vec;
size_t size_of_float = sizeof(double);
size_t size_M = m * n * size_of_float;
size_t size_vec = n * size_of_float;
// malloc and memcpy
cudaMalloc((void**)&d_M, size_M);
cudaMalloc((void**)&d_vec, size_vec);
cudaMemcpy(d_M, h_M, size_M, cudaMemcpyHostToDevice);
cudaMemcpy(d_vec, h_vec, size_vec, cudaMemcpyHostToDevice);
// timing
cudaEvent_t start, stop;
float elapsed_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// running
dim3 grid_dim(int(ceil((double)n/ThreadNum)), 1, 1);
dim3 block_dim(ThreadNum, colnum, 1);
gpu_mat_col_reduce_kernel<<<grid_dim, block_dim>>>(d_M, d_vec, m, n);
// timing
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_time, start, stop);
// memcpy
cudaMemcpy(h_vec, d_vec, size_vec, cudaMemcpyDeviceToHost);
// print res
printf(" grid dim: %d, %d, %d.\n", grid_dim.x, grid_dim.y, grid_dim.z);
printf(" block dim: %d, %d, %d.\n", block_dim.x, block_dim.y, block_dim.z);
printf(" kernel time: %f milisec\n", elapsed_time);
// free
cudaFree(d_M);
cudaFree(d_vec);
cudaEventDestroy(start);
cudaEventDestroy(stop);
}

In the above, I provided two optimization ideas. I originally planned to write an optimized version of shared memory. However, for this protocol operation, I really can't see how to do shared memory. In addition, for high2 optimization, you can also define some constants mentioned above as register variables to achieve the acceleration effect, but after my test, the effect is not obvious. In addition, we can think like this. We can apply for more blocks to process a column of elements in one block. This code is very easy to write, but it involves a problem: the maximum n is 64, that is, we need to apply for at least 64 blocks. At this time, what is the number of threads in each block? I try to set the number of threads in each block to 1024, Then I don't know why the calculation result is wrong. I guess there may be an upper limit on the number of threads that can be applied on the GPU. If I try to reduce the number of threads in each block, I find that the calculation result is correct, but I find that the acceleration effect is poor after testing, so I don't list the results. Below, I use a table \ ref{out} to show the acceleration ratios of the two accelerated versions mentioned above, in which radio1 and radio2 respectively represent the acceleration ratios of high1 and high2 relative to the original version.
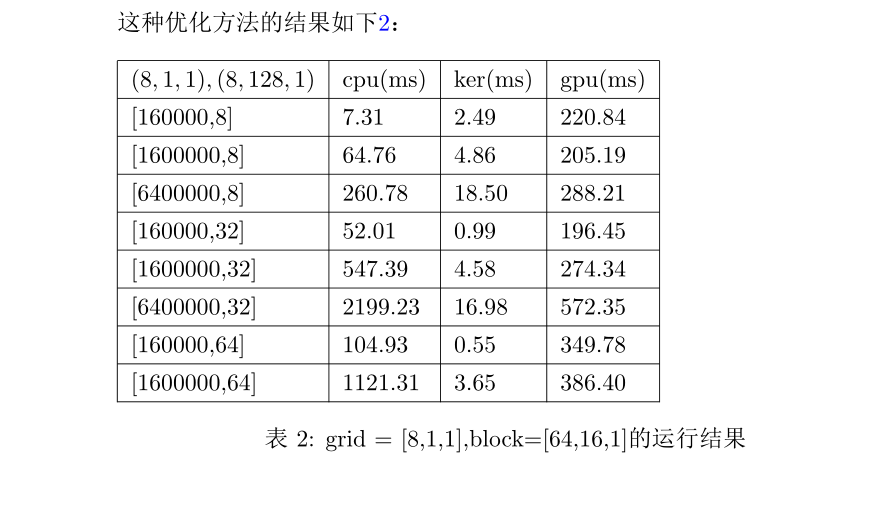
col_reduce.cu
#include <cuda.h>
#include <stdio.h>
#include <math.h>
#define gridnum 8
#define blocknum 8
#define colnum 128
#if !defined(__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
static __inline__ __device__ double atomicAdd(double *address, double val) {
unsigned long long int* address_as_ull = (unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
if (val==0.0)
return __longlong_as_double(old);
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val +__longlong_as_double(assumed)));
} while (assumed != old);
return __longlong_as_double(old);
}
#endif
extern "C" void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n);
__global__
void gpu_mat_col_reduce_kernel(double* mat, double* vec, int m, int n){
int fen = n/blockDim.x;
int H = blockDim.y,V = (int)((double)(blockDim.x/fen));
int i;
if (fen > 1 && fen < blockDim.x){
if (threadIdx.x%2 == 0) i = blockIdx.x*fen + (threadIdx.x/2);
else i = blockIdx.x*fen + (threadIdx.x - 1)/2;
}
else {
i = blockIdx.x*fen + threadIdx.x%fen;
}
//if (threadIdx.x%2 == 0) i = blockIdx.x*fen + (threadIdx.x/2);
// else i = blockIdx.x*fen + (threadIdx.x - 1)/2;
// int i = blockIdx.x*fen + threadIdx.x%fen;
int wid = (int)(ceil((double)m/(H*V)));
int thread = threadIdx.x%V + threadIdx.y*V;
int jst = thread*wid,jend = min((thread + 1)*wid,m);
if(i < n){
double sum = 0.0;
for (int j = jst; j < jend; j++) { // m row
//atomicAdd(&sum,mat[j*n + i]);
sum += mat[j * n + i];
}
atomicAdd(&vec[i],sum);
}
}
void gpu_mat_column_reduce(double* h_M, double* h_vec, int m, int n) {
double *d_M, *d_vec;
size_t size_of_float = sizeof(double);
size_t size_M = m * n * size_of_float;
size_t size_vec = n * size_of_float;
// malloc and memcpy
cudaMalloc((void**)&d_M, size_M);
cudaMalloc((void**)&d_vec, size_vec);
cudaMemcpy(d_M, h_M, size_M, cudaMemcpyHostToDevice);
cudaMemcpy(d_vec, h_vec, size_vec, cudaMemcpyHostToDevice);
// timing
cudaEvent_t start, stop;
float elapsed_time = 0.0;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// running
dim3 grid_dim(gridnum , 1, 1);
dim3 block_dim(blocknum, colnum, 1);
gpu_mat_col_reduce_kernel<<<grid_dim, block_dim>>>(d_M, d_vec, m, n);
// timing
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsed_time, start, stop);
// memcpy
cudaMemcpy(h_vec, d_vec, size_vec, cudaMemcpyDeviceToHost);
// print res
printf(" grid dim: %d, %d, %d.\n", grid_dim.x, grid_dim.y, grid_dim.z);
printf(" block dim: %d, %d, %d.\n", block_dim.x, block_dim.y, block_dim.z);
printf(" kernel time: %f milisec\n", elapsed_time);
// free
cudaFree(d_M);
cudaFree(d_vec);
cudaEventDestroy(start);
cudaEventDestroy(stop);
}
After our test, we found that different thread organization methods can effectively speed up the algorithm after reasonable matching. At the same time, we can also find that the number of threads applied for each time is limited, especially for a block, there is an upper bound for the number of threads. I didn't know this at the beginning. The number of threads applied for each block is huge, so the Kernel function can't enter the GPU. \par
In addition, through our experiments, it is obvious that modifying the thread scheduling method can only reduce the kernel time. However, the impact on the running time of the GPU is not particularly obvious. It is difficult to manually modify the variable memory access model and improve the thread access speed to different variables.