1. Index:
Two new tables, T1 and T2, are created as follows: 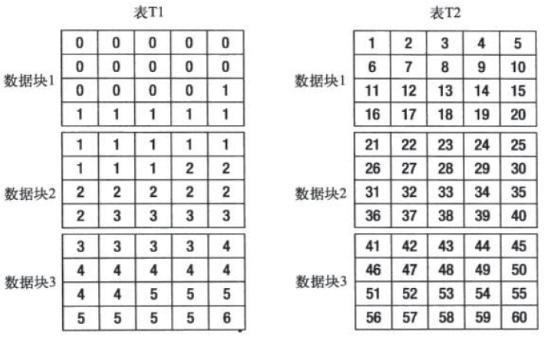
When both tables are queried the same way, the T1 table uses an index, but the T2 table does not scan the full table.
select * from t1 where id=10;
select * from t2 where id=10;This is mainly because the values of the clustering factor in the T1 table are close to the number of table blocks in the table, and the values of the clustering factor in the T2 table are close to the number of data in the table.
If the value of the clustering factor is close to the number of table blocks in the table, the storage order of the target index rows and the data rows stored in the corresponding table is very similar.This means that when Oracle retrieves the target rowid after an index range scan and accesses the data in the corresponding table block back to the table, the table data found by the rowid corresponding to the adjacent index row is most likely in the same table block.That is, after Oracle first reads the corresponding table block from the rowid return table of the index row record and caches the table block in the buffer cache, it is no longer necessary to generate physical I/O when the corresponding table block is read a second time from the rowid return table of the adjacent index row record, since the two visits are the same table block, which is already cached in the buffer cache.
If the clustering factor value is close to the number of records in the table, the storage order of the target index rows and the data rows stored in the corresponding table is very similar, which means that when Oracle scans the index range to get rowids and accesses the data in the corresponding table block back to the table, the rowids corresponding to the adjacent index rows may not be in the same table block, indicating that Oracle reads the corresponding rowids every time.A table block that generates physical I/O each time.
B-TREE Index Structure
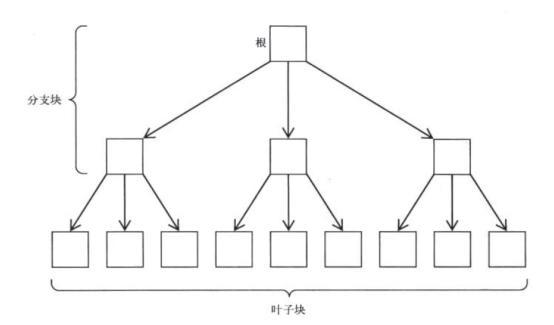
The process of accessing data through a B-tree index: first accessing the related B-tree index, then accessing the corresponding data row records based on the ROWID obtained from accessing the index and back to the table.
Accessing related B-tree indexes and loopback tables here requires I/O, which means that the cost of accessing the index consists of two parts: one is the cost of accessing the related B-tree indexes (from the root node to the related branch blocks, then to the related leaf blocks, and finally to scan them); the other is the cost of loopback tables (based on ROWID to sweep the corresponding data back to the table).Block of data where rows are located)
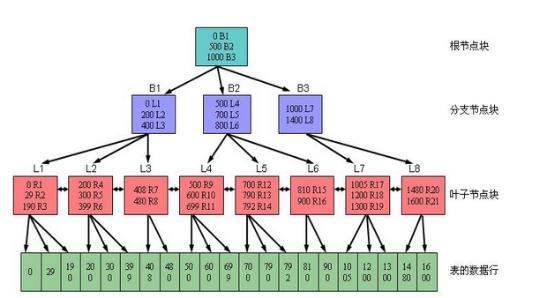
Advantages of B-tree index:
- All index leaf blocks are at the same level, that is, they are at the same depth from the index root node.This also means that access to any key value of an index leaf block takes almost the same amount of time.
- The efficiency of accessing row records in a table through a B-tree index does not decrease significantly with the increasing amount of data in the table, that is, the time of accessing data through a walking index is controllable and basically stable.
2. Methods of accessing indexes:
1. Index Uniqueness Scan, that is, the sweep that is directed to the unique index.

2. Index Range Scan. When a scanned object is uniquely indexed, where criteria must be range queries (i.e., detween, <, >, etc.); there is no restriction on non-unique indexes.

3. Full Index Scan:
Applies to all types of B-tree indexes.The so-called index full scan refers to scanning all index columns of all leaf blocks of the target index.Note here that full index scan requires scanning all leaf blocks but does not mean scanning all branch blocks.Oracle only needs to access the first row of index rows located in the leftmost leaf block of the index by accessing the necessary branch blocks to make a full index scan. It can scan all index rows of all leaf blocks of the index sequentially from left to right using a two-way pointer chain table between the index leaf blocks.
Because the index is ordered, the results from a full scan of the index are also ordered to avoid sorting. 
Because the results from a full scan of the index are ordered, they cannot be executed in parallel and can only be read on a single block.
Note: Indexed columns cannot allow null s, otherwise full scan of the index will not be performed.
4. Quick full scan of index: similar to full scan of index, it can use multiple reads or execute in parallel, but its results are out of order.
5. Full table scan can use multiple reads and will scan until high water level.
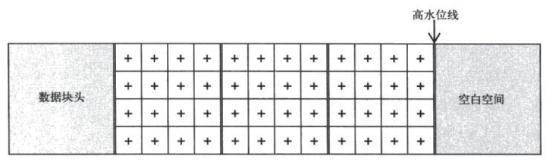
It is important to note that when delete is used to delete data, the high water level stays the same, meaning that the full table scan will take approximately the same amount of time. 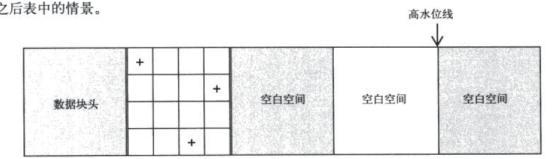
3. Use of Indexes in Actual Development
- How to index a query column with a null value refers to creating the following index:
create index idx_t3 on test3(object_id,0);- Function index:
create index idx_t3_tm on test3(trunc(created));- Left% Use Index:
create index idx_t3_nm on test3(reverse(object_name));- Two columns are spelled before the index is taken:
create index idx_t3_un on test3(owner||'_'||object_type);- Combinatorial Index: Highly Selective Fields First
create index idx_t3 on test3(object_name,object_id);
select t.* from edcs.test3 t where t.object_id > 1 and t.object_name='I_IND1';IV. Table Joining Method
1. Sort Merge Join
If two tables (T1 and T2) use sort merge links for table links, Oarcle follows these steps:
1. First access table T1 with the predicate conditions (if any) specified in the target table SQL, and then sort the access results according to the link columns in table T1. The result set after sorting is recorded as 1;
2. Access Table T2 with the predicate conditions specified in the target table SQL, if any, and then sort the access results according to the link columns in Table T2. The result set after sorting is counted as 2;
3. Finally, the result set 1 and result set 1 are merged, from which matching records are taken and returned.
Generally, sorting merge links is less efficient than hash links, but hash links can only use equal link conditions, and sorted merge links can be used for non-equal links.Sort merge links because sorting data is required Sort is I/O intensive when there is a large amount of data.
You can use the use_merge() prompt to specify a sort merge link. 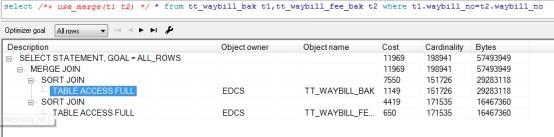
2. Nested Loops Join
If two tables (T1 and T2) use nested circular links for table linking, Oarcle follows these steps:
1. First, the optimizer will follow certain rules to determine who is driving and who is driven in tables T1 and T2.Drive tables are used for outer loops and drive tables for inner loops.It is assumed here that T1 is the driving table and T2 is the driven table.
2. Next, the result set obtained by accessing the drive table T1 is counted as result set 1 under the predicate conditions (if any) specified in the target SQL;
3. Then iterate through Result Set 1 and pull out one by one to find matching records in Driven Table T2.Equivalent to two for loops in java;
From the above description, we can see that the result set of the driven table is often smaller, and if there is a better selective index on the link of the driven table, the nested loop execution efficiency will be very high.
Another advantage of nested loops is that they can provide fast response, that is, they can return linked and qualified data first without waiting for all the link operations to complete.
You can use the use_nl() prompt to specify a nested circular link. 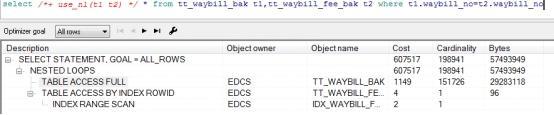
3. Hash Link (Hash Join)
Hash linking is a table linking method in which two tables mainly rely on Hash operations to get a linked result set.
Prior to Oracle7.3, the main table joining methods used in databases were sorting merge links and nested circular links, but both of them had distinct drawbacks.For ordered merge links, the execution efficiency of ordered merge links is invariably low if the result set of two tables after applying the predicate conditions specified in the target SQL is large and needs to be sorted; for nested circular links, if the corresponding driver result set of the driving table is large, even if there is an index efficiency on the link column of the driven table.Hash links have been introduced since Oracle7.3 to address these issues.But it only applies to link conditions of equal value.
You can use the use_hash() prompt to specify a hash link. 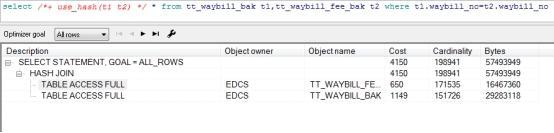
4. Cartesian Links (Cross Join)
If two tables (T1 and T2) use Cartesian links for table linking, Oarcle follows these steps:
1. First, the table T1 is accessed under the predicate conditions (if any) specified in the target table SQL, and the resulting set is denoted as result set 1 with m records.
2. Next, the table T2 is accessed under the predicate conditions (if any) specified in the target table SQL, and the resulting set is denoted as result set 2 with n records.
3. The final merge operation is performed on result set 1 and result set 2, and the final number of records is m*n.
sql optimization script
--Building tables
create table test1 as (select trunc((rownum-1)/100) id,rpad(rownum,100) t_pad from dba_source where rownum<=10000);
create table test2 as (select mod(rownum-1,100) id,rpad(rownum,100) t_pad from dba_source where rownum<=10000);
--Indexing
create index idx_t1 on test1(id);
create index idx_t2 on test2(id);
--Methods of table analysis
analyze table test1 compute statistics for table ;
analyze table test2 compute statistics for table ;
--Methods of Index Analysis
analyze index idx_t1 compute statistics ;
analyze index idx_t2 compute statistics ;
--View statistics
SELECT A.INDEX_NAME, B.NUM_ROWS, B.BLOCKS, A.CLUSTERING_FACTOR
FROM USER_INDEXES A, USER_TABLES B
WHERE A.INDEX_NAME IN ('IDX_T1','IDX_T2')
AND A.TABLE_NAME = B.TABLE_NAME;
select count(1) from test1 where id=10;
select count(1) from test2 where id=10;
select count(1) from test1 ;
select count(1) from test2 ;
select * from edcs.test1 where id=10;
select * from edcs.test2 t where id=10;
create table test3 as select * from dba_objects;
analyze table edcs.test3 compute statistics for table ;
create index idx_t3 on test3(object_id);
analyze index idx_t3 compute statistics;
create index idx_t3_tm on test3(created);
analyze index idx_t3_tm compute statistics ;
select count(1) from test3 t; --77230
--View execution plan
F5
set autot trace;
select * from table(dbms_xplan.display_cursor(null,null,'advanced'));
--unique index
select * from tm_dcs_process_detail_config t where t.process_detail_id=2585378;
--Range Index
select * from edcs.test3 t where t.object_id=15;
--Index Full Scan
select t.process_detail_id from tm_dcs_process_detail_config t ;
--Quick Full Scan of Index
select T.OBJECT_ID from TEST3 T;
select /*+ index_ffs(T IDX_T3) */ T.OBJECT_ID from TEST3 T;
--Examples of index development
--existence null Value Walk Index Method
select rowid ,t.* from test3 t where t.object_id is null;
drop index idx_t3;
create index idx_t3 on test3(object_id,0);
analyze index idx_t3 compute statistics ;
--Function Index
select * from test3 t where trunc(created)>=date'2011-09-16';
drop index idx_t3_tm;
create index idx_t3_tm on test3(trunc(created));
analyze index idx_t3_tm compute statistics ;
--%Use Index
create index idx_t3_nm on test3(object_name);
select * from test3 t where t.object_name like '%CON1';
drop index idx_t3_nm;
create index idx_t3_nm on test3(reverse(object_name));
analyze index idx_t3_nm compute statistics ;
select t.* from test3 t where reverse(t.object_name) LIKE reverse('%CON1');
--Two-column stitched index
select * from test3 t where owner||'_'||object_type ='SYS_CLUSTER';
create index idx_t3_un on test3(owner||'_'||object_type);
analyze index idx_t3_un compute statistics ;
--Combined index
create index idx_t3 on test3(object_id,object_name);
create index idx_t3 on test3(object_name,object_id);
select t.* from edcs.test3 t where t.object_id > 1 and t.object_name='I_IND1';
--Table Join Mode
select * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_merge(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_nl(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_hash(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);
select t1.*
from tt_waybill_fee_bak t1,temp3 t2
where t1.waybill_no = t2.waybill_no;
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select /*+ no_unnest */ t2.waybill_no from temp3 t2);
--parallel
select /*+ PARALLEL(T1 4)*/ t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);