1, Foreword
Let's look at an interesting case first
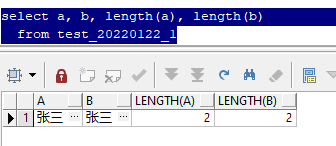
The above sql queries two fields a and b, both of which are "Zhang San", and uses the length function to check that the length is 2.
However, when you see the following sql output results, your first reaction is likely to be:
"How is this possible?"
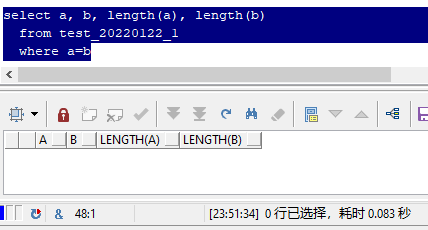
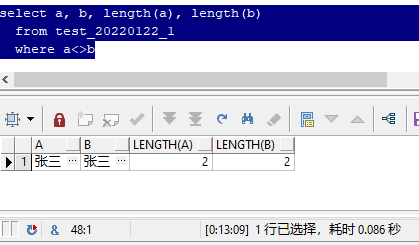
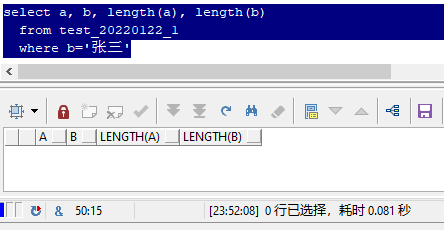
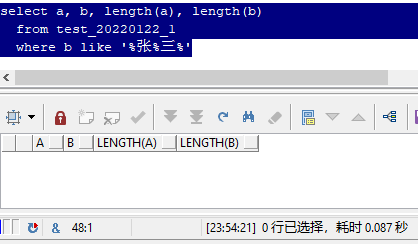
In fact, as like as two peas, you can see that the two "Zhang three" you see is exactly the same.
But why are a and b not equal?
This is because they are composed of different components, which is the character set
2, What is a character set?
Baidu Encyclopedia
In short,
Character is the general name of various characters and symbols, including national characters, punctuation marks, graphic symbols, numbers, etc.
A Character set is a collection of multiple characters
As we all know, the bottom layer of the computer system is composed of binary 1 and 0, and these 1 and 0 are just "on" and "off" of the electrical signal, and there are no characters at all. In fact, the character set can be understood as an indexed dictionary. According to the specified binary data, look up the character at the corresponding position of the dictionary, and then display the word in the selected font from the character set.
For example, the binary data "1011000010100001" (hexadecimal "B0A1") corresponds to the Chinese character "ah" in the GB2312 character set.
Even English letters and numbers must also rely on character sets. For example, binary data "1100001" (hexadecimal "61") represents lowercase letter "a". Of course, in almost all character sets, this binary data represents a.
Therefore, for all our current computer systems, if we want to recognize characters, we must use the binary data of this character to check a specific character set and find the corresponding characters. If we find the wrong character set, what we find may be garbled.
3, Character set of ORACLE Database
During oracle database installation, there will be an option to select the character set of the database, which most DBA s know and needless to say.
However, many people are often confused when they learn about the oracle character set through articles on the Internet:
What is AL32UTF8? Why not utf8?
Simple machine set in environment variable_ CHINA. What is ZHS16GBK? Why not set GBK directly?
Is the character set found in each view of the database client or database?
1. Character set code
The character set code in ORACLE is not equal to the current common character set name. Let's take a look at the official information
Comparison table between ORACLE character set and general character set
In fact, according to the "Description" in this table, the names of these common character sets are too long and irregular to be used as code; There are also some special cases, such as "JA16EUCTILDE" and "JA16EUC", which are actually "EUC 24 bit Japanese". Only the wavy lines are different, they are divided into two character sets.
Therefore, oracle must name these character sets uniformly again, so there are character set codes such as "AL32UTF8" and "ZHS16GBK"
II.NLS_LANG
In the system environment variable (or registry) "NLS_LANG", values like the following are often configured
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
AMERICAN_AMERICA.AL32UTF8
In fact, this environment variable consists of three parts
<Language>_<territory>.<character>
Namely
Language_ Area character set
Only the last section is the true representation of the character set
Therefore, "simple chinese_china.zhs16gbk" means: "simplified Chinese"_ "China region" "16 bit GBK simplified Chinese"
Similarly, "american_american. AL32UTF8" means "American English"_ "U.S. region." "Unicode 12.1 universal character set UTF-8 encoding scheme".
Of course, not all of these three are required in the environment variables. You can even use ". AL32UTF8" to indicate that the default language and region of the database are used, but the client uses the character set you specify; Use "_american." Only specify the client region. The language uses the default language of the region, and the character set uses the character set corresponding to the default language of the region.
---Query the language of Belgium
DECLARE
retval UTL_I18N.STRING_ARRAY;
cnt INTEGER;
BEGIN
retval := UTL_I18N.GET_LOCAL_LANGUAGES('BELGIUM');
for i in 0..retval.count-1 loop
DBMS_OUTPUT.PUT_LINE(retval(i));
END LOOP;
END;
/
---Query the default character set of French
select UTL_I18N.GET_DEFAULT_CHARSET('French') from dual;
---from ISO Standard language code conversion ORACLE Languages and regions in
select UTL_I18N.MAP_LANGUAGE_FROM_ISO('en_US') ,
UTL_I18N.MAP_TERRITORY_FROM_ISO('en_US') from dual;
---take ORACLE Language and region conversion to standard ISO Standard language code
select UTL_I18N.MAP_LOCALE_TO_ISO('American','America') from dual;
In the actual user scenario, a region can have more than one language, and a character set can also represent multiple languages. By flexibly configuring this environment variable, you can make the database more compatible with the time zone, language, currency, text, etc. of each region.
However, you may ask:
Don't they all say that the environment variables of the database should be consistent with those of the client?
Yes, yes, it is recommended to be consistent, but it is not absolute. At present, there are many companies in many countries and languages. When using the same database, there must be different needs.
It is divided into three parts
A. Language
First, for the language, let's make a test like this:
- When installing the database, the language is "AMERICAN", and then the "NLS_LANG" of the client environment variable is set to "simple machine_china.al32utf8". Open the client software and execute an incorrect sql after connecting to the database
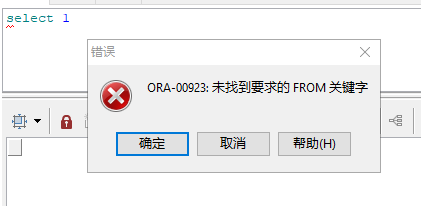
- Then change the "NLS_LANG" of the client environment variable to "AMERICAN_CHINA.AL32UTF8", reopen the client software, and execute the same sql after connecting to the database
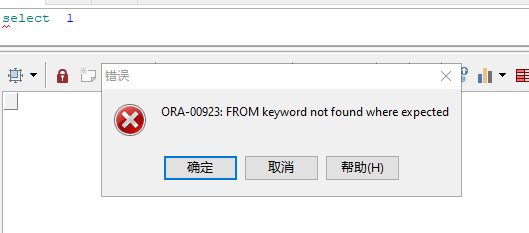
Yes, the language of the client environment variable is used to do this. It is used to display error reports or prompt messages in different languages on the client. You can even set them to Japanese or French. These system prompt messages are recorded in multiple languages in the database. In addition, you can also convert the corresponding system prompt information into a language not set by the client through the plsql package "UTL_LMS" provided in the database.
DECLARE
s varchar2(200);
i pls_integer;
BEGIN
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'french', s);
dbms_output.put_line('French : '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'AMERICAN', s);
dbms_output.put_line('American English is: '||s);
i:= utl_lms.get_message(26052, 'rdbms', 'ora', 'SIMPLIFIED CHINESE', s);
dbms_output.put_line('Simplified Chinese is: '||s);
END;
/
Output is:
French: type% D non pris en charge pour l'expression SQL sur la Colonne% s
American English: unsupported type% d for SQL expression on column% s
English: SQL expression type% d at column% s is not supported.
Of course, we also have to see whether the current character set supports the current language. Please refer to the official documents
Comparison table of ORACLE language and supported character sets
B. Region
For regions, in addition to the function of taking the default language of the region when no language is set, it also affects the time zone, currency and date format. This has little to do with this article, so it is omitted.
C. Character set
Next is the last parameter, the character set
Through the articles on the network and my own exploration in the database, I get the following sql, which can query language, region and character set
select * from nls_database_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from nls_instance_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from nls_session_parameters where parameter in ('NLS_TERRITORY','NLS_LANGUAGE','NLS_CHARACTERSET');
select * from v$parameter;
select * from v$nls_parameters;
select * from v$system_parameter where name like 'nls%';
select name,substr(value$, 1, 64) from x$props where name like 'NLS%';
select userenv('language') from dual;
select sys_context('USERENV','LANGUAGE') from dual;
However, there is a problem. These sql can let us know the language and region used in the database and the client respectively, but for the character set, it is either not available or displayed as the database character set, and the character set set set in the client environment variable cannot be found through any sql!
This is also described in the official Oracle documentation
FAQ-NLS-LANG
SELECT USERENV ('language') FROM DUAL; gives the session's _ but the DATABASE character set not the client, so the value returned is not the client's complete NLS_LANG setting!
SELECT USERENV (‘language’) FROM DUAL; Get the language of the current session_ The region and database character set are not the client character set, so the returned value is not the complete client NLS_LANG setting!
Let's not discuss why ORACLE does not provide the query method of client character sets in the database. Let's focus on what problems will occur if the character sets are different.
I created a table with two fields: row number and value. Then, four text files are written, all of which insert into a record into this table. The line numbers are 1, 2, 3 and 4 respectively, and the values are "Zhang San". The test scenarios and results are summarized as follows
insert data
| Line number | Database language | Database character set | Client language | Client character set | Insert the file code of sql | Hexadecimal data in the database | Visible characters in plsql developer |
|---|---|---|---|---|---|---|---|
| 1 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | ZHS16GBK | UTF-8 | E5AFAEE78AB1E7AC81 | For three years |
| 2 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | ZHS16GBK | ANSI | E5BCA0E4B889 | Zhang San |
| 3 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | AL32UTF8 | UTF-8 | E5BCA0E4B889 | Zhang San |
| 4 | AMERICAN | AL32UTF8 | SIMPLIFIED CHINESE | AL32UTF8 | ANSI | D5C5C8FD | Zhang San |
(actually, when unicode is enabled in the plsql developer option, the client character set does not affect its data display)
Query data with SQL plus
| Client character set | Line number | Visible characters (chcp 936) | Visible characters (chcp 65001) |
|---|---|---|---|
| AL32UTF8 | 1 | Ignition | For three years |
| AL32UTF8 | 2 | For three years | Zhang San |
| AL32UTF8 | 3 | For three years | Zhang San |
| AL32UTF8 | 4 | Zhang San | Zhang San |
| Client character set | Line number | Visible characters (chcp 936) | Visible characters (chcp 65001) |
|---|---|---|---|
| ZHS16GBK | 1 | For three years | Zhang San |
| ZHS16GBK | 2 | Zhang San | |
| ZHS16GBK | 3 | Zhang San | |
| ZHS16GBK | 4 | ?? |
According to the above test, the following points can be obtained
- When inserting data, the character set of the data file shall be consistent with the client character set to avoid garbled code (the corresponding text needs to exist in both character sets), even if it is inconsistent with the database character set (for example, lines 2 and 3 are correct and consistent)
- When inserting data, when the client character set is inconsistent with the data file character set, it may cause garbled code (line 1) or no garbled code (line 4), but whether the garbled code is just "display effect", its value is wrong in a sense
- When querying, the client character set is consistent with the database character set, which can improve the probability of correctly displaying text
- When querying, the code page (chcp) is consistent with the client character set, which can improve the probability of displaying text correctly
- Code page (chcp) and data file coding are one thing, that is, only three variables are involved in this test, database character set, client character set and data coding (affected by code page or file coding)
- To minimize the occurrence of "garbled code", the database character set, client character set and data coding should be consistent
- If the three cannot be consistent, for example, when the database character set is uncontrollable, try to keep the client character set and data coding consistent
- If the database character set is inconsistent with the client character set, for example, if the database character set is ZHS16GBK, but the client character set is AL32UTF8, some words may not be converted when the client inserts data (UTF-8 has more words than GBK), but the reverse problem is not great, as long as the character sets of all clients accessing the same data are unified
3, Restoring garbled code in Oracle
It is necessary to ensure the consistency of the character set in advance to avoid garbled code. However, if the consistency of the character set is not guaranteed in advance, resulting in garbled code, how to save this batch of garbled data afterwards?
Some garbled codes can be restored in the following ways
select utl_i18n.raw_to_char(UTL_I18N.string_to_raw('For three years', 'ZHS16GBK'),
'AL32UTF8')
from dual;
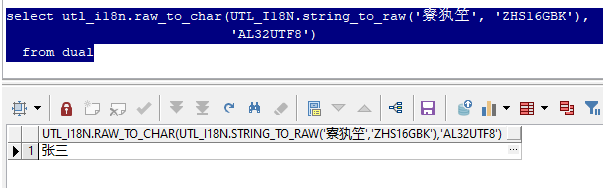
However, the above only takes ZHS16GBK and AL32UTF8 as examples. There are many actual scenes, such as Japanese, Korean, French, etc. it is difficult to judge which character set of a garbled code turns into which character set.
Therefore, I developed a plsql package to perform exhaustive conversion and output a table. Users can visually check how the garbled code is generated (in order to reduce the number of data output, only for the garbled code participated by one party with the Asian language character set)
create or replace package charset_util_pkg is
type convert_any_charset_type is RECORD(
original_str varchar2(4000),
original_HEX RAW(32767),
to_str varchar2(4000),
to_hex raw(32767),
from_charset varchar2(50),
to_charset varchar2(50),
sql_text varchar2(200));
type convert_any_charset_table is table of convert_any_charset_type;
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
PIPELINED;
end charset_util_pkg;
/
create or replace package body charset_util_pkg is
charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('JA16EUC',
--'JA16EUCTILDE',
'JA16SJIS',
--'JA16SJISTILDE',
'KO16MSWIN949',
'TH8TISASCII',
'VN8MSWIN1258',
'ZHS16GBK',
'ZHT16HKSCS',
--'ZHT16MSWIN950',
'ZHT32EUC',
'BLT8ISO8859P13',
'BLT8MSWIN1257',
'CL8ISO8859P5',
'CL8MSWIN1251',
'EE8ISO8859P2',
'EL8ISO8859P7',
'EL8MSWIN1253',
'EE8MSWIN1250',
'NE8ISO8859P10',
'NEE8ISO8859P4',
'WE8ISO8859P15',
'WE8MSWIN1252',
'AR8ISO8859P6',
'AR8MSWIN1256',
'IW8ISO8859P8',
'IW8MSWIN1255',
'TR8MSWIN1254',
'WE8ISO8859P9',
'AL32UTF8');
ASIA_charsetlist ora_mining_varchar2_nt := ora_mining_varchar2_nt('JA16EUC',
-- 'JA16EUCTILDE',
'JA16SJIS',
-- 'JA16SJISTILDE',
'KO16MSWIN949',
'TH8TISASCII',
'VN8MSWIN1258',
'ZHS16GBK',
'ZHT16HKSCS',
--'ZHT16MSWIN950',
'ZHT32EUC');
function convert_any_charset(original_str varchar2)
return convert_any_charset_table
PIPELINED is
to_str varchar2(4000);
begin
for rec in (select f.column_value from_charset,
t.column_value to_charset
from table(charsetlist) f, table(charsetlist) t
where f.column_value <> t.column_value
AND (F.column_value IN
(SELECT column_value FROM TABLE(ASIA_charsetlist)) OR
T.column_value IN
(SELECT column_value FROM TABLE(ASIA_charsetlist)))) loop
begin
to_str := utl_i18n.raw_to_char(UTL_I18N.string_to_raw(original_str,
rec.from_charset),
rec.to_charset);
exception
when others then
begin
to_str := utl_i18n.raw_to_char(UTL_I18N.string_to_raw(original_str ||
chr(0),
rec.from_charset),
rec.to_charset);
exception
when others then
to_str := 'convert error!';
end;
end;
if to_str in (rpad(chr(63), length(original_str), chr(63)),
rpad(UTL_RAW.cast_to_varchar2('C2BF'),
length(original_str),
UTL_RAW.cast_to_varchar2('C2BF'))) then
CONTINUE;
end if;
PIPE ROW(convert_any_charset_type(original_str,
UTL_RAW.cast_to_raw(original_str),
to_str,
UTL_RAW.cast_to_raw(to_str),
rec.to_charset,
rec.from_charset,
'utl_i18n.raw_to_char(UTL_I18N.string_to_raw(%s,''' ||
rec.from_charset || '''),''' ||
rec.to_charset || ''')'));
end loop;
end;
end charset_util_pkg;
/
select A.* from charset_util_pkg.convert_any_charset('For three years') A;
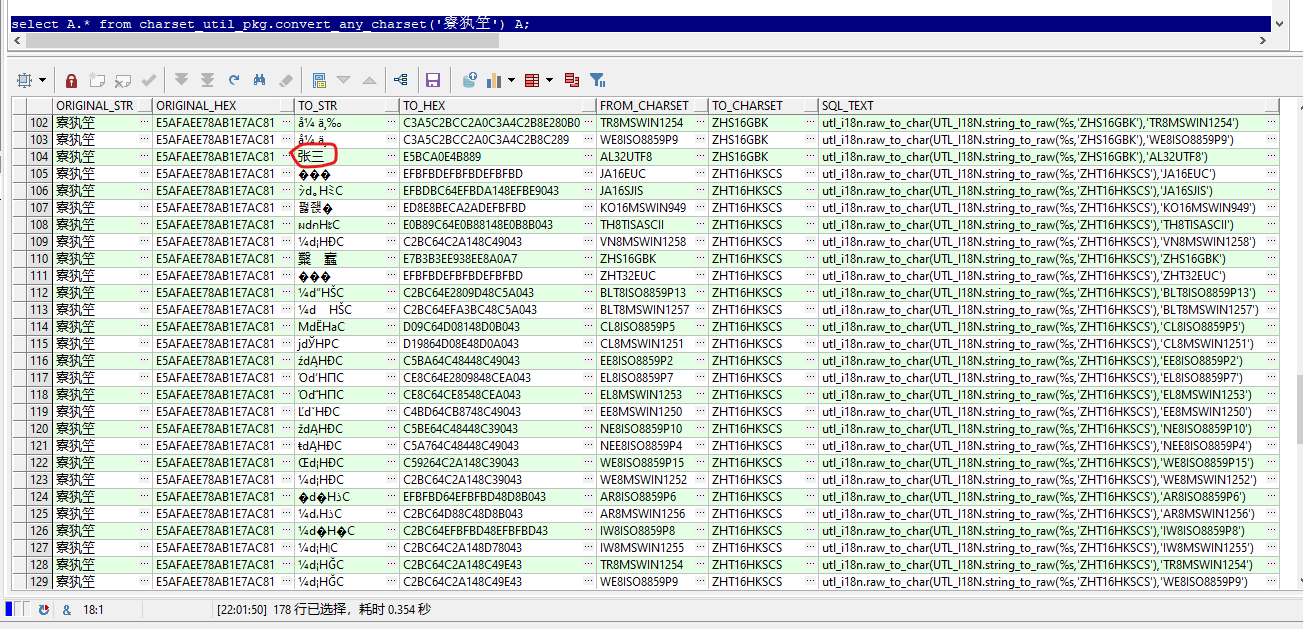
Or limit the current database character set to reduce entries
select A.*
from charset_util_pkg.convert_any_charset('For three years') A
where from_charset =
(select value
from nls_database_parameters
where parameter = 'NLS_CHARACTERSET');
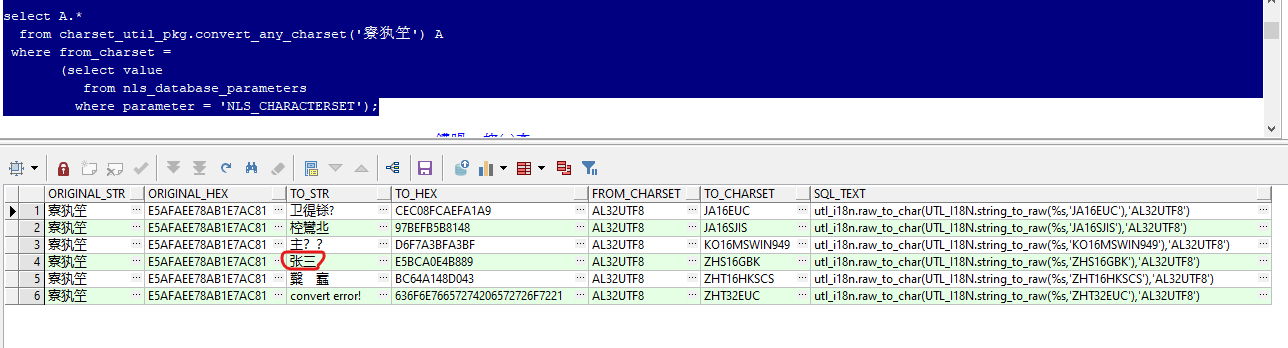
Or use columns as incoming parameters
select A.*
from test_20220122_1 b,charset_util_pkg.convert_any_charset(b.b) A
where b.b='For three years' and from_charset =
(select value
from nls_database_parameters
where parameter = 'NLS_CHARACTERSET');
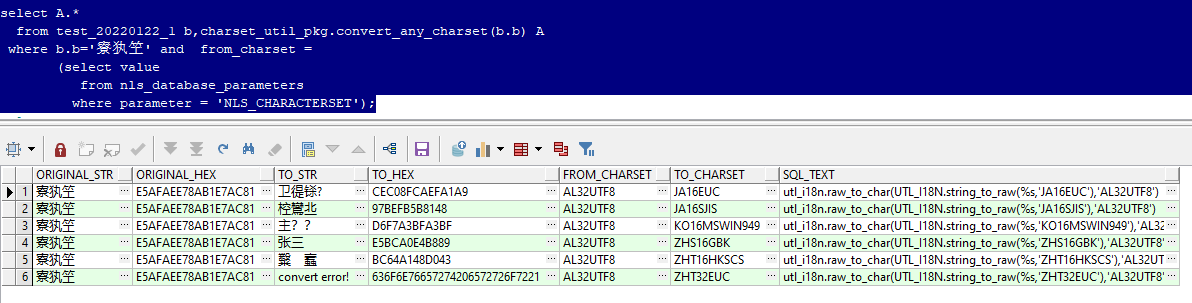
In addition, you can copy its corresponding SQL from the results_ Textto get the correct conversion code quickly.
summary
Through the above research, it can be seen that if the developed application project is garbled, the application developer should take the primary responsibility, because the client character set and data code are specified by the developer. In a database with only application input data, the garbled code has little relationship with the database character set (unless a partial character set is specified during database installation).
If you don't pay attention to the unity of character sets during the development of application projects, various strange problems will appear, such as finding data without conditions, copying that value as a condition and not finding it; And all kinds of strange garbled code.
Back to the case at the beginning, in fact, the values of a and b are the values of lines 3 and 4 in the above test. Although the display is the same, in fact, one is UTF8 coding and the other is GBK coding.
Test data and sql attached at the beginning:
create table test_20220122_1 as
select utl_raw.cast_to_varchar2('E5BCA0E4B889') a,
utl_raw.cast_to_varchar2('D5C5C8FD') b
from dual;
select a,
b,
length(a),
length(b),
lengthb(a),
lengthb(b),
UTL_RAW.cast_to_raw(a),
UTL_RAW.cast_to_raw(B)
from test_20220122_1;
Note: the above is only for ORACLE database, and the situation of other databases will be different
- Author: DarkAthena
- Link to this article: https://www.darkathena.top/archives/about-oracle-charset
- Copyright notice: all articles on this blog are in English unless otherwise stated CC BY-NC-SA 3.0 License agreement. Reprint please indicate the source!