🍅 Programmer Xiao Wang's blog: Programmer Xiao Wang's blog
🍅 Welcome to like 👍 Collection ⭐ Leaving a message. 📝
🍅 If you have an editor's error and contact the author, if you have a good article, welcome to share it with me, I will extract the essence and discard the dross.
🍅 Learning route of java self-study: Learning route of java self-study
1, View
-
A view is a statement that encapsulates a complex query.
1. Syntax 1.: CREATE VIEW subview name
-
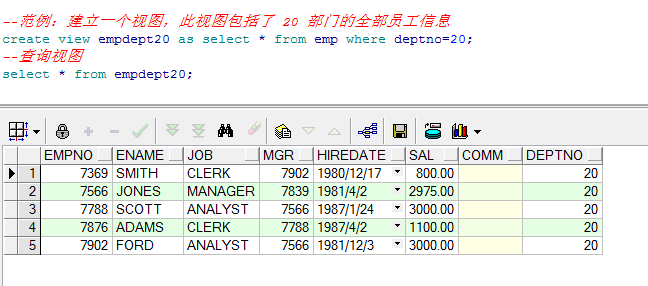
Example: create a view that includes all employee information of 20 departments
--Example: create a view that includes 20 All employee information of the Department create view empdept20 as select * from emp where deptno=20;
After the view is created, you can use the view to query, and the queried employees are all employees of 20 departments
--Query view select * from empdept20;
2. Syntax 2: CREATE OR replace VIEW view name AS subquery
-
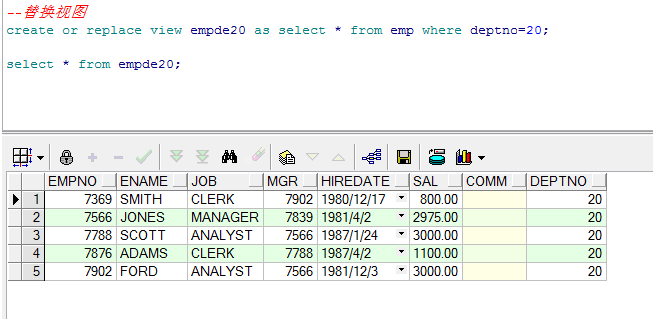
If the view already exists, we can use syntax 2 to create the view, so that the existing view will be overwritten.
--Replace view create or replace view empde20 as select * from emp where deptno=20; select * from empde20;
3. Advantages:
-
View is to define the name of SQL query statement, which is convenient for reuse and simplifies SQL
-
Security, shield the information of tables and fields for developers
4. Note:
-
The view is equivalent to a query statement and does not store actual data. The view basically does not occupy hard disk space, and the efficiency has not been improved
-
Delete view: drop view view name;
2, Index
1. What is an index?
-
Understanding: similar to the table of contents in front of the book, it is used to improve query efficiency. Indexes are data objects used to speed up data access. Reasonable use of index can greatly reduce the number of i/o, so as to improve the performance of data access.
-
Note: the data (index column data and rowid) is stored in the index, and is in ascending order according to the index column
-
Create index:
CREATE [UNIQUE] | [BITMAP] INDEX index_name --unique Represents a unique index ON table_name([column1 [ASC|DESC],column2 --bitmap,create bitmap index [ASC|DESC],...] | [express]) [TABLESPACE tablespace_name] [PCTFREE n1] --Specifies that the index has free space in the data block [STORAGE (INITIAL n2)] [NOLOGGING] --Indicates that changes to the table are allowed when creating and rebuilding indexes DML Operation, which should not be used by default [NOLINE] [NOSORT]; --It means that the index is not sorted when it is created. It is not applicable by default. If the data is already arranged according to the index order, it can be used
-
Use: it does not need to be used manually. By default, when the index field is used as the condition for query, the database will automatically use the index to find data
-
be careful:
1. The more indexes you create, the better,Index space(Have data);When adding, deleting or modifying data,At the same time, the data in the index needs to be maintained 2. Indexes are usually created on columns that are frequently queried 3. Columns with primary keys and unique constraints,The database is automatically indexed. 4. Delete index: drop index Index name;
2. Single column index
-
Single column index is an index based on a single column, such as:
CREATE index Index name on Table name(Listing)
-
Case: index the name of the person table
create index pname_index on person(name);
3. Composite index
A composite index is an index based on two or more columns. There can be multiple indexes on the same table, but
The combination of columns must be different, for example:
Create index emp_idx1 on emp(ename,job); Create index emp_idx1 on emp(job,ename);
-
Case: create an index of name and gender for the person table
create index pname_gender_index on person(name,gender)
4. Use principle of index:
-
It makes sense to build an index on a large table
-
Index the fields after the where clause or on the join condition
-
It is not recommended to establish an index when the data in the table is modified frequently
5. Index principle
-
If there is no index, you need to search all records when searching for a record (for example, find name='whj '), because there is no guarantee that there is only one whj, you must search all records
-
If the index is established on name, oracle will search the whole table once, and arrange the name value of each record in ascending order. Then build index entries (name and rowid) and store them in the index segment. When the query name is whj, you can directly find the corresponding place
-
The index may not be used after it is created. After oracle automatically counts the information of the table, it decides whether to use the index. When there is little data in the table, the scanning speed of the whole table is very fast, so it is not necessary to use the index
3, Restraint
1. Primary key constraint: primary key
-
Function: used to uniquely identify a row of data in the table, such as student number and job number
-
Features: unique, non empty
-
Syntax: field name data type primary key
-
Note: during development, each table usually has a primary key constraint
2. Unique constraint: unique
-
Function: the value identifying this field cannot be repeated. Such as ID number, mobile phone number.
-
Features: unique and can be empty
-
Syntax: field name data type unique
3. Non NULL constraint: not null
-
Function: the field must have content and cannot be null; Such as student name
-
Features: non empty, repeatable
-
Syntax: field name data type not null
4. Check constraints: check (expression)
-
Role: limit the content of this field according to user-defined rules. For example, the gender can only be male or female
-
Syntax: field name data type check (expression for checking constraints)
-
Common usage scenarios:
Gender can only be Male or female: check( sex in ('male','female')) or
check(sex = 'male' or sex='female')
Mobile phone number must be 11 digits: phone char(11) check(phone like '_____')or
phone char(11) check(length(pone)=11)
Mailbox must have@: check (email like '%@%')
5. Foreign key constraint
-
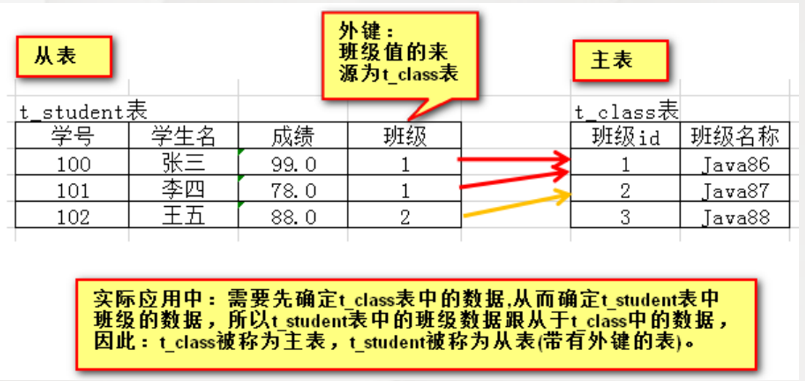
Function: the value identifying this field cannot be entered arbitrarily. It must be the value existing in the primary key or unique key of another table. (identify the relationship between the current table [slave table] and another table [master table])
-
Features: repeatable and null
-
Syntax: field name data type references main table name (field name of primary key / unique key)
6. Default constraint
-
Default: default
-
Function: identify the content assigned by default when no content is filled in this field
-
Syntax: field name data type DefaultValue constraint
-
Note: the type of the given default value must be consistent with the data type of the field
7. Joint constraint
-
Union constraint: when a primary key or unique constraint cannot be identified by any field in the table, the combination of multiple keys is used for constraint
-
Common union constraints: Union primary key, union unique constraint
-
Syntax:
1. Federated primary key: primary key(Field name 1 , Field name 2) 2. Joint unique constraint: unique(Field name 1 , Field name 2)
(1) Create class table
--Student list create table t_class( cls_id number(10) primary key, cls_name varchar2(20) not null );
(2) Create student table
-
Student ID number - primary key, name, email box (must have @), date of birth (default date), ID number - unique, class number.
--Student list --Student number-Primary key, name, email(Must have@),date of birth(Default current date),ID number-Number and unique class create table t_student( stu_id number(5) primary key, stu_name varchar2(20) not null, email varchar2(50) not null check(email like '%@%'), birthday date default sysdate, card_id char(18) unique, cls_id number(5) references t_class(cls_id) );

(3) Query all tables under the user
-
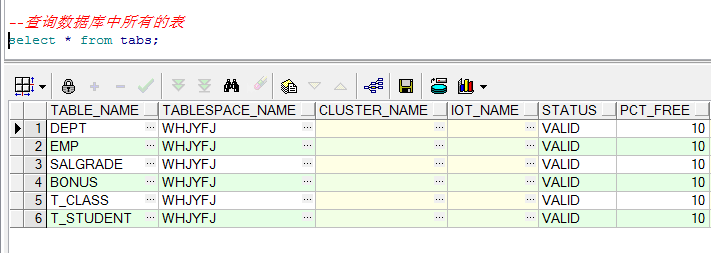
Note: query all tables in the Library: select * from tabs;
--Query all tables in the database select * from tabs;
(4) Joint constraint case
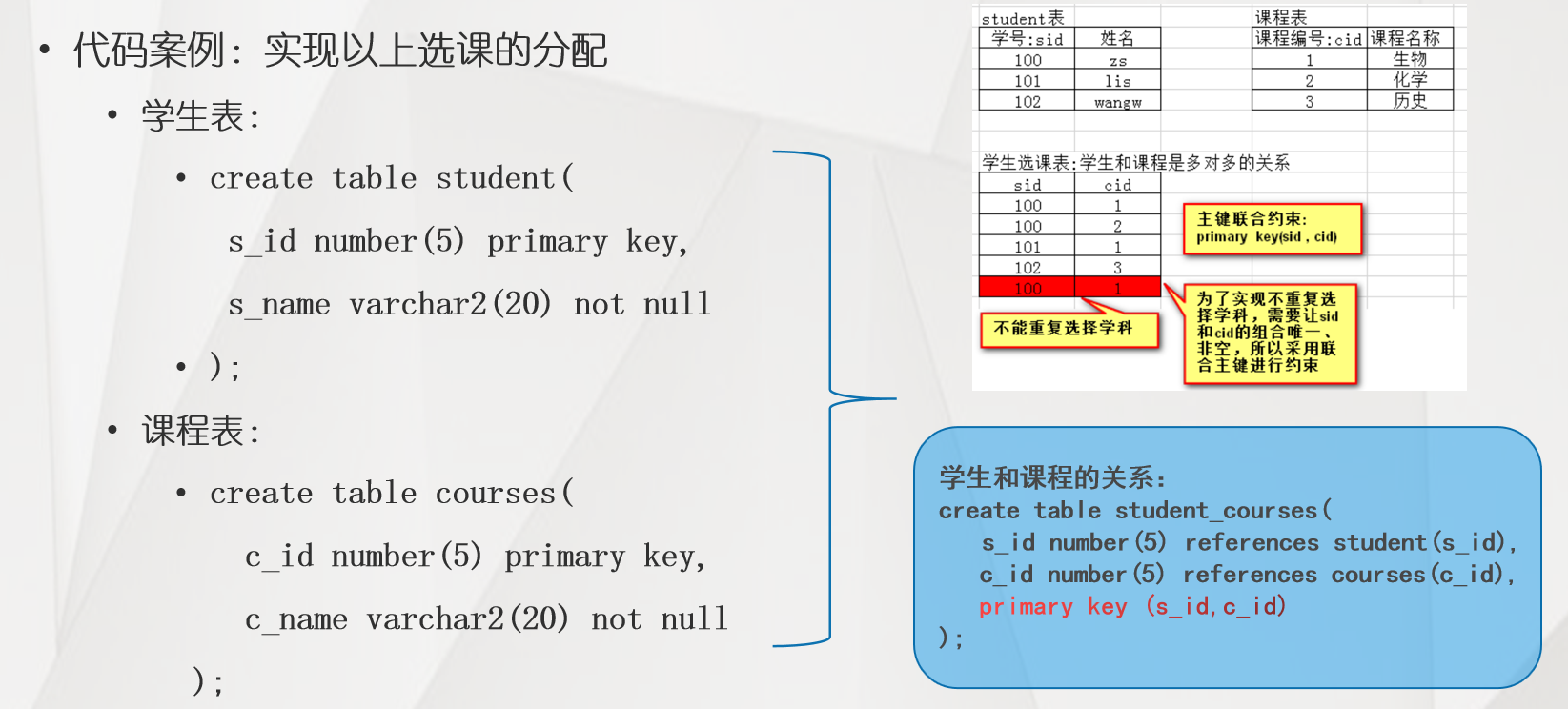
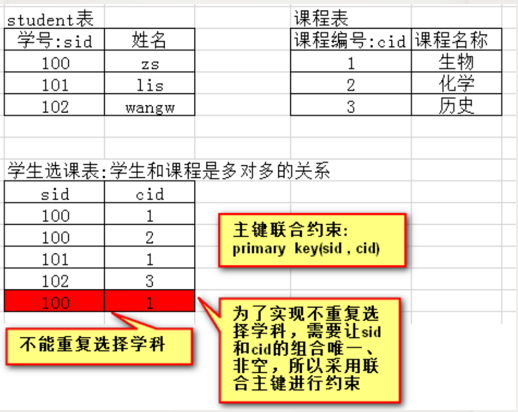
-- Student list create table t_student( s_id number(5) primary key, s_name varchar2(30) not null ); -- Class Schedule Card create table t_course( c_id number(5) primary key, c_name varchar2(30) not null ); -- Description: a student can choose multiple courses and define the relationship table create table t_sc( s_id number(5) references t_student(s_id), c_id number(5) references t_course(c_id), primary key(s_id,c_id) ); -- insert data create sequence stud_seq insert into t_student values(stud_seq.nextval,'Big baby') select * from t_student create sequence cour_seq start with 100 insert into t_course values(cour_seq.nextval,'oracle') select * from t_course -- Insert data into relational tables insert into t_sc values(2,101); -- Query students' course selection select s.s_id,s_name,c.c_name from t_student s join t_sc sc on s.s_id=sc.s_id join t_course c on sc.c_id=c.c_id where s.s_name='Jiaming'
4, transaction
1. What is a transaction?
-
Concept: the smallest execution unit in the database, which is usually composed of one or more sql. Only when all sql is executed successfully can the transaction succeed, then the transaction is committed; As long as one sql fails to execute, the transaction fails and the transaction is rolled back
-
The size of the transaction depends on the business
(1) In actual development, a business corresponds to different numbers of transactions sql,These are many sql The composition of is called a transaction (To realize business needs, control transactions) (2) Case: Transfer business: money from one account is transferred to another account update account set balance=balance-money where id = 894893 update account set balance=balance+money where id = 242546 Note: there are at least 2 transfer businesses sql,Constitute a transaction(2 strip sql) Account opening: to account Add information to table insert into ..... Note: there is one business for opening an account sql,Constitute a transaction(1 strip sql)
-
Transaction boundaries
(1) Start: from day one sql Start execution, transaction start (2) end: a. DML sentence(insert/delete/update)The end boundary needs to be clearly specified: I. Encountered: commit,Commit transaction, transaction succeeded II.encounter: rollback,Rollback transaction, transaction failed b. DDL Statements: statements that create tables(create table/create sequence),Auto commit transaction
2. Rollback segment:
-
Database server DBServer will open up a small memory space (called rollback segment) for each connected client to temporarily store the execution results of sql statements. If all sql statements are executed successfully, commit and write the rolled back data into the DB; If an sql fails to execute, the data in the rollback segment will be cleared when the transaction is rolled back, and the result will be restored to that before the transaction.
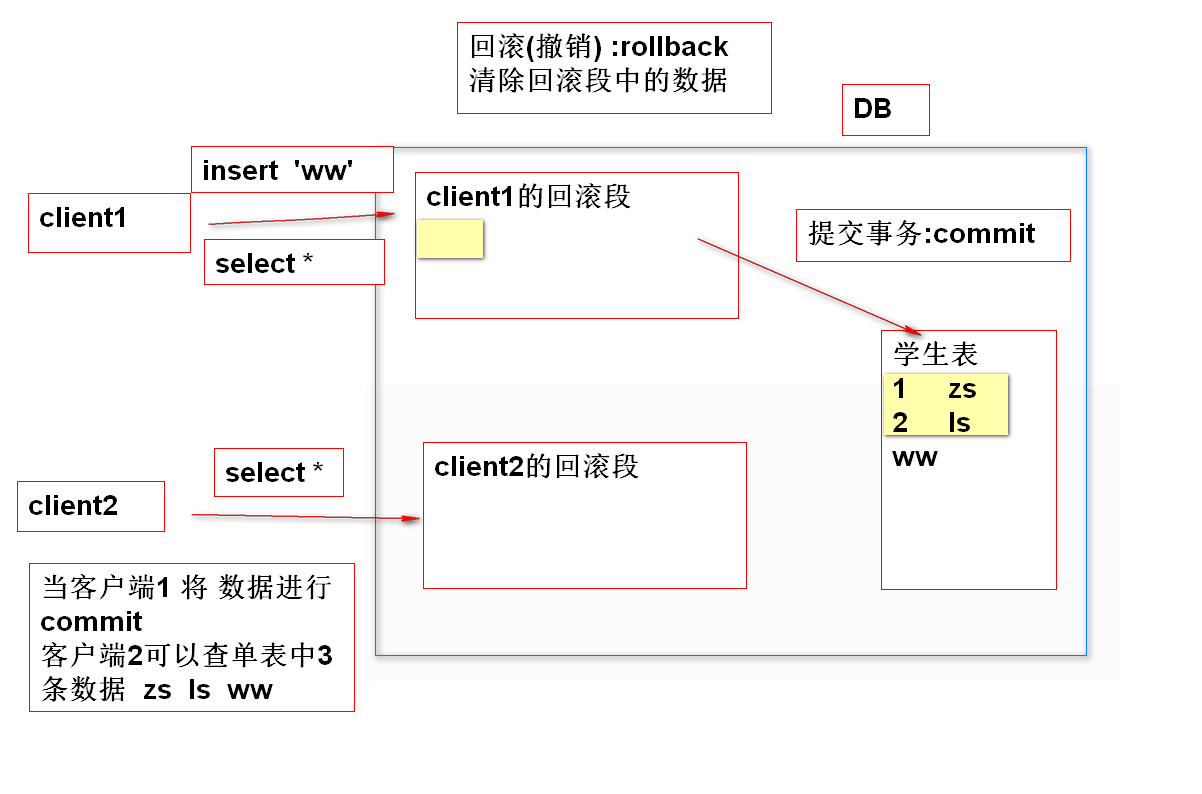
3. Lock
(1) The bottom layer of transaction adopts the mechanism of lock to ensure the security of data
(2) The database assigns a lock to each data. If a client performs the insert/delete/update operation, it will obtain the lock mark of the current operation data. The lock mark will not be released until it is commit ted or rollback, and other clients can operate the current data
-
Note: the select query operation does not need to consider transactions.
4. Transaction characteristics: (ACID)
(1)Atomicity of transactions(Atomic): Multiple in a transaction sql The statement is a whole, Or all succeed,Or lose it all Defeat. (2)Consistency of transactions(Consistency): (Rationality of data),Before and after transaction execution(Whether failure or success),most The final data is reasonable. (3) Isolated type of transaction(Isolation): When multiple transactions are concurrent, the transactions are independent and do not affect each other (4) Transaction persistence(Durability): End of transaction(Success or failure),Data modification to the database is permanent.
5, Database paradigm
1. What is paradigm?
In short, the paradigm is some norms that should be followed when designing the database, which can play a guiding role in creating tables. Following the normal form when designing database tables can reduce redundant data and make the management of data more scientific.
2. First paradigm
-
The key point of the first paradigm is that fields cannot be subdivided
-
Case: for the hobby attribute, the actual stored data may be:
| number | full name | hobby |
|---|---|---|
| 1 | Wang Hengjie | Play basketball, sing songs and play games |
| 2 | Yang Fujun | Singing, watching movies, dancing |
For example, now there is a need to modify all film hobbies to film and television, and then there is a need to delete all dance hobbies. These operations are bound to be converted into string splicing and query operations, which is very inconvenient.
The solution is to split the attributes again and separate them into another table
| number | full name |
|---|---|
| 1 | Wang Hengjie |
| 2 | Yang Fujun |
| number | hobby |
|---|---|
| 1 | sing |
| 1 | Play basketball |
| 1 | Play games |
| 2 | sing |
| 2 | watch movie |
| 3 | dance |
3. Second paradigm
-
The second paradigm means that attributes cannot be partially dependent on primary attributes
-
For example:
Student number Student name Course number Course name achievement s001 Zhang San c001 java 90 s001 Zhang San c002 oracle 80 s002 Li Si c002 oracle 60 s003 Li Si c001 java 50 s003 Wang Wu c002 oracle 100
If a grade sheet is designed to represent the course selection of students, the attribute that can play a unique identification in the sheet is called the main attribute. The secondary number in this sheet cannot be used as the main attribute alone, and the course number cannot be used as the main attribute alone. Therefore, there are two main attributes: student number and course number.
The grade attribute depends on these two main attributes at the same time, while the student name and course name can only partially depend on the main attributes. Calling the attributes of student name and course name as partial dependency should be separated from this table.
There are some problems with the existing table structure. For example, adding new students will have problems. If the new students have no elective courses, some columns must be left blank; There will also be problems in modifying students. Zhang San is renamed Zhang Si, and multiple records need to be modified
These problems are called adding exceptions, modifying exceptions and deleting exceptions respectively. If these partially dependent attributes are separated, these problems can be avoided, such as:
Student number Student name s001 Zhang San s002 Li Si s003 Wang Wu Course number Course name c001 java c002 oracle Student number Course number achievement s001 c001 90 s001 c002 80 s002 c002 60 s003 c001 50 s003 c002 100
Firstly, some redundant information of students and courses is removed. Secondly, adding, modifying and deleting students will not cause exceptions, which is the same for courses.
4. Third paradigm
-
The third paradigm means that attributes cannot be indirectly dependent on primary attributes
-
For example:
empno ename deptno dname 7369 Smith 10 Finance Department 7499 Scott 10 Finance Department 7869 King 10 Finance Department
If the above table structure exists, dname directly depends on the deptno attribute and deptno directly depends on the main attribute of empno. In this case, dname indirectly depends on empno.
The problem caused by this dependency is where to add a new department. Similarly, there are modification exceptions and deletion exceptions. The solution is to separate the attribute (dname) indirectly dependent on the primary attribute (empno) from this table. As follows:
empno ename deptno 7369 Smith 10 7499 Scott 10 7869 King 10 deptno dname 10 Finance Department