background
With the continuous expansion of data volume, the strengthening of analysis demand and the process of localization, the original traditional database can no longer support and complete heavy tasks.
More and more data warehouses and data Lake platforms are migrating to MPP, big data and cloud original platforms.
However, in this process, the original core system is temporarily retained, or a database more suitable for transaction processing is selected.
Data interaction between different databases is inevitable in this system. We take the cloud native database (OushuDB) and ORACLE as an example to explore the advantages and disadvantages of the scheme, and implement a DBLINK to complete some requirements.
Implementation of traditional ORACLE
ORACLE database because of its stable performance, huge player foundation and perfect training mechanism. It can be seen everywhere in the domestic system and is also very representative.
In the early days, many data reference databases were built directly on ORACLE, but they were divided into different databases from the core database. From the core database to the data warehouse ODS layer, data synchronization was generally completed through OGG and ADG, and some systems completed data interaction directly through DBLINK or with materialized view.
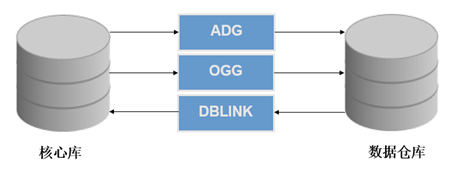
Advantages of ADG and OGG:
Both ADG and OGG synchronize through redo log, which has little impact on the core system
ADG and OGG disadvantages:
1. It can only be used between ORACLE, and different databases are not applicable
2. Troublesome deployment and high operation and maintenance cost
DBLINK benefits:
1. It is easy to use without additional deployment components
2. You can interact with different libraries through a transparent gateway
DBLINK disadvantages:
1. DBLINK is affected by optimizer and network, and cannot reach the performance of local library
2. The use of DBLINK needs to consider the load of the production core library. It cannot be abused, resulting in the failure of the core library
Implementation of new data warehouse and data Lake
With the increasing demand for real-time and quasi real-time data warehouses, it is necessary to build an integrated flow batch architecture. Take the flow batch integration architecture of OushuDB as an example
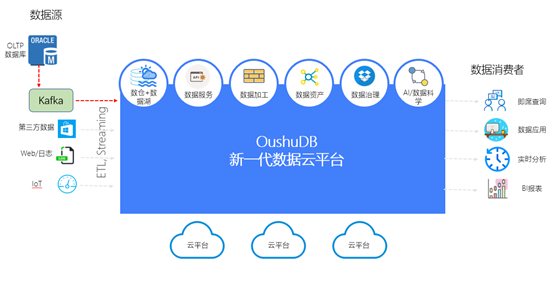
Based on the cloud architecture, the new generation of ohudb can complete the synchronization of various data sources, which is also the way of ohudb.
However, some special requirements may require DBLINK implementation. Of course, this DBLINK is used conditionally and cannot be abused.
Realize DBLINK and complete effective supplement
OushuDB has rich interfaces, which can facilitate secondary development.
General implementation
For the common practice of DBLINK, the external program can be called through the web external table to achieve the effect of DBLINK. Take the simplest shell example to illustrate this process:
1. First, install the ORACLE client on MASTER
2. Modify parameter gp_external_enable_exec = on
3. Define a SHELL script to access ORACLE data, VI lineitem sh
#!/bin/bash sqlplus -S sh/sh <<EOF set arraysize 5000; set linesize 32767; set pagesize 0; set heading off; set feedback off; alter session set nls_date_format='YYYY-MM-DD'; select '"'||L_ORDERKEY ||'","'||L_PARTKEY ||'","'||L_SUPPKEY ||'","'||L_LINENUMBER ||'","'||L_QUANTITY ||'","'||L_EXTENDEDPRICE ||'","'||L_DISCOUNT ||'","'||L_TAX ||'","'||L_RETURNFLAG ||'","'||L_LINESTATUS ||'","'||L_SHIPDATE ||'","'||L_COMMITDATE ||'","'||L_RECEIPTDATE ||'","'||L_SHIPINSTRUCT ||'","'||L_SHIPMODE ||'","'||L_COMMENT||'"' as text from LINEITEM_DATA where rownum<10; set feedback on; set heading on; quit; EOF exit
chmod 777 lineitem.sh
4. Define web external table and call lineitem sh
CREATE EXTERNAL WEB TABLE ora_LINEITEM ( l_orderkey bigint ,l_partkey bigint ,l_suppkey bigint ,l_linenumber bigint ,l_quantity numeric(15,2) ,l_extendedprice numeric(15,2) ,l_discount numeric(15,2) ,l_tax numeric(15,2) ,l_returnflag character(1) ,l_linestatus character(1) ,l_shipdate date ,l_commitdate date ,l_receiptdate date ,l_shipinstruct character(25) ,l_shipmode character(10) ,l_comment character varying(44) ) EXECUTE '/home/oracle/lineitem.sh' ON MASTER FORMAT 'CSV' ;
5. Direct query
Select * from ora_LINEITEM;
The above method can be changed to jdbc or oci call, but this method is not of high practical value, because every time this method is executed, the data will be read to the master in full and then processed. Even if the where condition is added, it is also the behavior after the master is read in full. This is equivalent to the effect of select * from tab. Then it doesn't matter if the small table is large? It often happens that you can only read the dimension table and code table. However, this demand generally requires real-time data acquisition of the flow table. The configuration table of code table can be synchronized regularly, so the scope of application is very small.
Available mode
The real and available way still needs to be realized through UDF, at the cost of reduced friendliness.
OushuDB can use multi language UDF s, such as c, java and python
The following is an example of pljava to complete this process
1. Install pljava
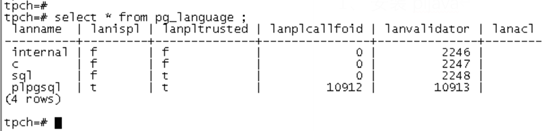
Through PG_ The language view can check the existing language support. There is no java initialization
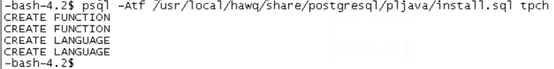
Execute / usr / local / hawq / share / PostgreSQL / pljava / install SQL complete creation
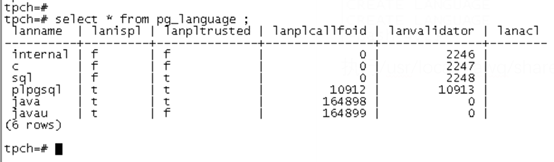
At this time, you can build the pljava function
But first we have to finish the java program
In order to realize the return record, the ResultSetHandle interface is used, which is in pljava Jar
Sample code:
package cn.oushu.dblink;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import org.postgresql.pljava.ResultSetHandle;
public class getDataBase implements ResultSetHandle {
private final String m_filter;
private final String m_tablename;
private Statement m_statement;
private Conn c = new Conn();
private Connection conn = null;
public getDataBase(String tablename, String filter){
m_tablename= tablename;
m_filter= filter;
}
public ResultSet getResultSet() throws SQLException
{
conn = c.sourceConnection();
m_statement= conn.createStatement();
if(m_filter.length() > 0) {
return m_statement.executeQuery("SELECT * FROM " + m_tablename + " WHERE " + m_filter);
} else{
return m_statement.executeQuery("SELECT * FROM " + m_tablename);
}
}
public void close() throws SQLException {
m_statement.close();
}
public static ResultSetHandle listDataBase(String tablename, String filter) {
return new getDataBase(tablename, filter);
}
}After the code is written, it is printed into a jar package, plus other dependent jars
Put it under / usr/local/hawq/lib/postgresql/java /
Modify pljava_ The classpath parameter adds all jar packages

When these are ready, you can build database functions
drop function if exists public.lineitem_data_ora_poc(text,text); create or replace function public.lineitem_data_ora_poc (funcname_in text,filter_in text) RETURNS table( L_ORDERKEY numeric(38,0) ,L_PARTKEY numeric(38,0) ,L_SUPPKEY numeric(38,0) ,L_LINENUMBER numeric(38,0) ,L_QUANTITY numeric(15,2) ,L_EXTENDEDPRICE numeric(15,2) ,L_DISCOUNT numeric(15,2) ,L_TAX numeric(15,2) ,L_RETURNFLAG char(1) ,L_LINESTATUS char(1) ,L_SHIPDATE timestamp ,L_COMMITDATE timestamp ,L_RECEIPTDATE timestamp ,L_SHIPINSTRUCT char(25) ,L_SHIPMODE char(10) ,L_COMMENT varchar(44) ) AS 'cn.oushu.dblink.getDataBase.listDataBase' IMMUTABLE LANGUAGE javau;
Execution function
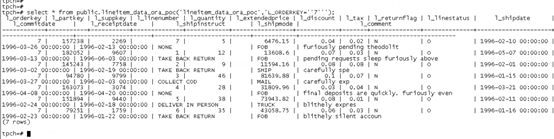
Join operation

The above methods can push the conditions to oracle. In this way, the data obtained from OushuDB is the data after conditional brushing. If the data is controlled within a certain range, there will be no OOM
Use restrictions
This DBLINK method still has restrictions and cannot be abused
1. The result set of the query must not be too large. Otherwise, not only the possibility of OOM, but also the lack of database statistics during the join will affect the execution plan
2. The query must be conditional. The best condition is the oracle index or partition, which can also protect the oracle core database
The above conditions are not met. It is recommended to add this requirement to the flow batch architecture
This scheme can be completed by changing oci. Of course, the performance will be better. The reason why we use java is mainly convenient without installing the client. java is convenient (lazy)
DBLINK utility link
Link: https://pan.baidu.com/s/16UucBYqlMLvzwq2Cscz_fw
Extraction code: 9cpt