Since my work mainly focuses on the network subsystem of the kernel, I just came into contact with this module, so I want to sort out the packet receiving process driven by the network card. The following contents are my personal understanding. If there is anything wrong, I hope you can make more corrections and grow up with each other~
In the follow-up, we will continue to update the contents related to the kernel network subsystem, and insist on updating every Monday!
Original is not easy, please indicate the source of reprint~
OK, let's get to the point.
At present, network card packet receiving can be divided into two types: interrupt mode and polling mode.
Interrupt packet receiving
As a data transceiver, the network card converts our data into binary signals and transmits them to the core network through the medium. Then, when the core network has data transmitted to the local, how do we know the data is coming? The simplest method is that the network card generates an interrupt signal to inform the CPU that a data packet is coming. The CPU enters the interrupt service function of the network card to read the data, build a skb, and then submit it to the network subsystem for further analysis.
The method of interrupting packet receiving responds in time, and the data packet can be processed immediately when it comes, but this method has a fatal disadvantage when a large number of data packets come, that is, the CPU is frequently interrupted, and other tasks cannot be executed, which is unbearable for the kernel. Therefore, the kernel proposes a new way to receive packets under high network load, NAPI (new API).
NAPI packet receiving
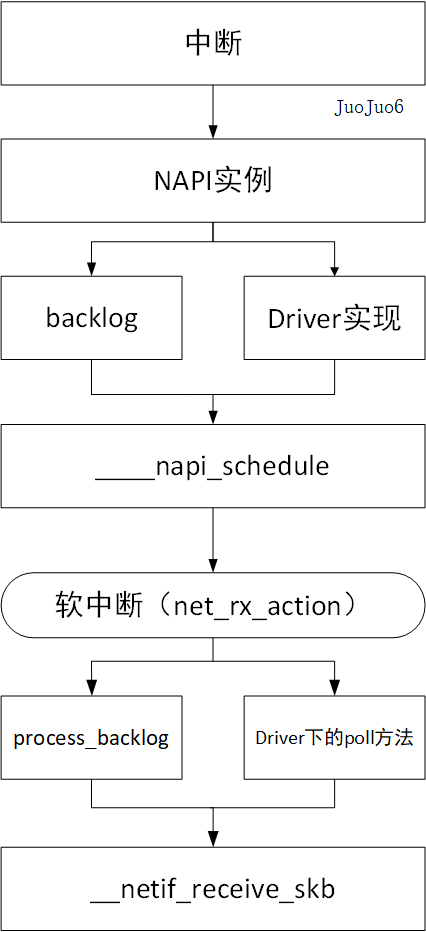
NAPI packet receiving is actually the polling function provided by the driver. In the scenario of a large number of data packets, turn off the network card interrupt, and execute the polling function of the driver in the soft interrupt to receive packets. This way avoids the frequent interruption of CPU in and out, and the soft interrupt also ensures the performance of the system.
However, NAPI mode requires the network card to receive packets. That is, the network card that supports ring buffer (i.e. DMA) can really use NAPI mode to receive packets. The network card that does not support DMA still needs to receive packets through interrupt. The following figure describes how the network card that supports DMA mode receives packets:
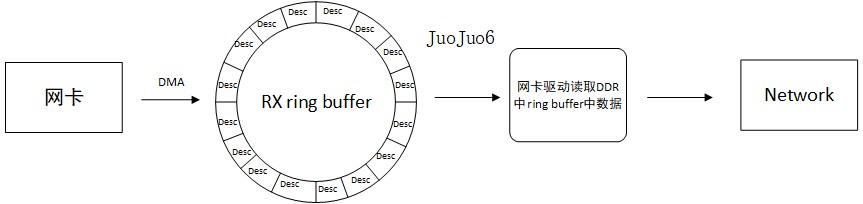
The network card driver will apply for a ring buffer to receive data packets. The ring buffer stores descriptors (note that descriptors are not real data). When the network card receives data, the driver applies for skb and stores the data area address of skb in the descriptor of the ring buffer, and marks that the descriptor is ready, The network card will find the ready descriptor and write the data to the data area of the skb through DMA. At the same time, the network card will mark that the descriptor has been used, drive to read the data in the ring buffer and maintain the state of the ring buffer.
After talking about the ring buffer, the NAPI packet receiving method is easier to understand. Because the network card supports DMA, when there is data in the network card, it can notify the CPU to process the data through interrupt. Then, the DMA is responsible for carrying the data to the memory. The CPU only needs to clear the unread data in the ring buffer at intervals (call the poll function of the driver), This is the idea of NAPI.
What about network cards that do not support DMA? In order to unify the idea of using NAPI, the kernel is only responsible for hanging the data packet to the input in the network card interrupt for the network card that does not support DMA_ pkt_ Queue linked list, and then kernel designed a poll function (process_backlog function) to process packets.
Data structure analysis
As mentioned earlier, in order to uniformly use NAPI mode, the kernel is compatible with network cards that do not support DMA. Next, let's sort out the packet receiving mode of network cards from bottom to top.
The first is the softnet, which is the entry for the CPU to receive packets_ Data structure:
For several important members of this structure, see Notes:
struct softnet_data {
struct list_head poll_list; //Poll the linked list, and the poll methods of each driver will be linked under this linked list
struct sk_buff_head process_queue;
/* stats */
unsigned int processed;
unsigned int time_squeeze;
unsigned int received_rps;
#ifdef CONFIG_RPS
struct softnet_data *rps_ipi_list;
#endif
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit __rcu *flow_limit;
#endif
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
struct sk_buff *completion_queue;
#ifdef CONFIG_RPS
/* input_queue_head should be written by cpu owning this struct,
* and only read by other cpus. Worth using a cache line.
*/
unsigned int input_queue_head ____cacheline_aligned_in_smp;
/* Elements below can be accessed between CPUs for RPS/RFS */
struct call_single_data csd ____cacheline_aligned_in_smp;
struct softnet_data *rps_ipi_next;
unsigned int cpu;
unsigned int input_queue_tail;
#endif
unsigned int dropped;
struct sk_buff_head input_pkt_queue; //Input queue. The network card that does not support DMA will hang the received packets under this linked list
struct napi_struct backlog; //The kernel constructs a NAPI structure for network cards that do not support DMA in order to unify NAPI packet collection
};
Next comes napi_struct structure:
The most important member of this structure is the poll callback function that needs to be registered. Since the kernel adopts the NaPi method uniformly at present, each network card needs to build its own NaPi structure (of course, in the case of receiving multiple queues, a network card may need to build a NaPi instance for each cpu).
struct napi_struct {
/* The poll_list must only be managed by the entity which
* changes the state of the NAPI_STATE_SCHED bit. This means
* whoever atomically sets that bit can add this napi_struct
* to the per-CPU poll_list, and whoever clears that bit
* can remove from the list right before clearing the bit.
*/
struct list_head poll_list; //Hook up softnet_ Poll under data structure_ List chain header
unsigned long state;
int weight; //Packet weight
unsigned int gro_count;
int (*poll)(struct napi_struct *, int); //poll callback function that drives registration
#ifdef CONFIG_NETPOLL
spinlock_t poll_lock;
int poll_owner;
#endif
struct net_device *dev;
struct sk_buff *gro_list;
struct sk_buff *skb;
struct hrtimer timer;
struct list_head dev_list;
struct hlist_node napi_hash_node;
unsigned int napi_id;
};
After introducing two important data structures, let's take the e100 network card (which supports DMA) as an example to introduce the function call of the network card when receiving packets.
-
First in E100_ In the probe function, the NAPI structure is constructed:
netif_napi_add(netdev, &nic->napi, e100_poll, E100_NAPI_WEIGHT);
-
In the network card interrupt, the local interrupt is prohibited and the NAPI packet receiving is started:
if (likely(napi_schedule_prep(&nic->napi))) { e100_disable_irq(nic); __napi_schedule(&nic->napi); //Hook the napi structure of the driver to the local CPU softnet_ Poll under data structure_ List and open NET_RX_SOFTIRQ soft interrupt starts receiving packets } -
Soft interrupt net_ rx_ In action, start traversing the poll under the cpu_ List linked list, take out the napi structure attached to the following and execute the poll function of driver registration to receive packets:
struct softnet_data *sd = this_cpu_ptr(&softnet_data); unsigned long time_limit = jiffies + 2; int budget = netdev_budget; LIST_HEAD(list); LIST_HEAD(repoll); local_irq_disable(); list_splice_init(&sd->poll_list, &list); //Take out the hook on the poll_list and re initialize the poll_list linked list local_irq_enable(); for (;;) { struct napi_struct *n; if (list_empty(&list)) { if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll)) return; break; } n = list_first_entry(&list, struct napi_struct, poll_list); //Take out the first napi structure budget -= napi_poll(n, &repoll); //Execute the poll function of driver registration to receive packets /* If softirq window is exhausted then punt. * Allow this to run for 2 jiffies since which will allow * an average latency of 1.5/HZ. */ if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) { sd->time_squeeze++; break; } }
Next, let's look at how the network card that does not support DMA receives packets. Take the DM9000 network card as an example:
-
In the interrupt function of DM9000 network card: the following shows the function call for receiving packets in the interrupt of DM9000 network card, and the kernel finally calls enqueue_to_backlog function, which has two data structures. Softnet was introduced earlier_ The data structure is annotated, that is, input_pkt_queue and backlog, input_ pkt_ The skb built in the interrupt is hung under the queue list, and the backlog is the NAPI built by the kernel for the network card that does not support DMA in order to unify the NAPI packet receiving method_ Struct structure instance.
dm9000_interrupt dm9000_rx netif_rx netif_rx_internal enqueue_to_backlog static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) { struct softnet_data *sd; unsigned long flags; unsigned int qlen; sd = &per_cpu(softnet_data, cpu); local_irq_save(flags); rps_lock(sd); if (!netif_running(skb->dev)) goto drop; qlen = skb_queue_len(&sd->input_pkt_queue); if (qlen <= netdev_max_backlog && !skb_flow_limit(skb, qlen)) { if (qlen) { enqueue: __skb_queue_tail(&sd->input_pkt_queue, skb); //Hook skb to input_pkt_queue linked list input_queue_tail_incr_save(sd, qtail); rps_unlock(sd); local_irq_restore(flags); return NET_RX_SUCCESS; } /* Schedule NAPI for backlog device * We can use non atomic operation since we own the queue lock */ if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) { if (!rps_ipi_queued(sd)) ____napi_schedule(sd, &sd->backlog); //Hook the backlog (NAPI) structure to the poll of the local cpu_ List } goto enqueue; } drop: sd->dropped++; rps_unlock(sd); local_irq_restore(flags); atomic_long_inc(&skb->dev->rx_dropped); kfree_skb(skb); return NET_RX_DROP; } -
The interrupt receives the packet and puts skb into the linked list. What should we do next? After the introduction of NAPI packet receiving method, it is natural to call NAPI in the soft interrupt_ The poll callback function registered under the instance of struct structure. Here is the poll function under the backlog implemented by the kernel. In net_ dev_ In init function:
static int __init net_dev_init(void) { int i, rc = -ENOMEM; BUG_ON(!dev_boot_phase); if (dev_proc_init()) goto out; if (netdev_kobject_init()) goto out; INIT_LIST_HEAD(&ptype_all); for (i = 0; i < PTYPE_HASH_SIZE; i++) INIT_LIST_HEAD(&ptype_base[i]); INIT_LIST_HEAD(&offload_base); if (register_pernet_subsys(&netdev_net_ops)) goto out; /* * Initialise the packet receive queues. */ for_each_possible_cpu(i) { //Finish the softnet here_ Initialization of data structure and backlog instance struct work_struct *flush = per_cpu_ptr(&flush_works, i); struct softnet_data *sd = &per_cpu(softnet_data, i); INIT_WORK(flush, flush_backlog); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); INIT_LIST_HEAD(&sd->poll_list); sd->output_queue_tailp = &sd->output_queue; #ifdef CONFIG_RPS sd->csd.func = rps_trigger_softirq; sd->csd.info = sd; sd->cpu = i; #endif sd->backlog.poll = process_backlog; //The poll function implemented by kernel is process_backlog sd->backlog.weight = weight_p; } dev_boot_phase = 0; /* The loopback device is special if any other network devices * is present in a network namespace the loopback device must * be present. Since we now dynamically allocate and free the * loopback device ensure this invariant is maintained by * keeping the loopback device as the first device on the * list of network devices. Ensuring the loopback devices * is the first device that appears and the last network device * that disappears. */ if (register_pernet_device(&loopback_net_ops)) goto out; if (register_pernet_device(&default_device_ops)) goto out; open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action); hotcpu_notifier(dev_cpu_callback, 0); dst_subsys_init(); rc = 0; out: return rc; } -
From the previous analysis, we can see that process_ The backlog function will be executed in the soft interrupt, and the input will be set in this function first_ pkt_ The members under queue are transferred to process_ Under the queue linked list, and then from process in while_ Take out skb from the queue list and pass it__ netif_receive_skb submitted to network subsystem
static int process_backlog(struct napi_struct *napi, int quota) { struct softnet_data *sd = container_of(napi, struct softnet_data, backlog); bool again = true; int work = 0; /* Check if we have pending ipi, its better to send them now, * not waiting net_rx_action() end. */ if (sd_has_rps_ipi_waiting(sd)) { local_irq_disable(); net_rps_action_and_irq_enable(sd); } napi->weight = weight_p; while (again) { struct sk_buff *skb; while ((skb = __skb_dequeue(&sd->process_queue))) { rcu_read_lock(); __netif_receive_skb(skb); rcu_read_unlock(); input_queue_head_incr(sd); if (++work >= quota) return work; } local_irq_disable(); rps_lock(sd); if (skb_queue_empty(&sd->input_pkt_queue)) { /* * Inline a custom version of __napi_complete(). * only current cpu owns and manipulates this napi, * and NAPI_STATE_SCHED is the only possible flag set * on backlog. * We can use a plain write instead of clear_bit(), * and we dont need an smp_mb() memory barrier. */ napi->state = 0; again = false; } else { skb_queue_splice_tail_init(&sd->input_pkt_queue, &sd->process_queue); } rps_unlock(sd); local_irq_enable(); } return work; }
So far, the packet receiving process of network card under kernel is introduced, and the packet receiving process of two types of network card is analyzed by function call. In order to improve the performance of the operating system, the kernel uses the polling method to receive packets (NAPI) when the network load is large, and each network card corresponds to its own napi_struct instance. For network cards that support DMA, this instance is provided by the driver. For network cards that do not support DMA, the kernel implements its own backlog instance and provides its own poll function process in order to unify the NAPI packet receiving method_ backlog.
Finally, the following figure compares two packet receiving methods: