Background
After a specific file is opened, the kernel will create a struct inode structure for it in memory (the inode structure will also be referenced in the corresponding file structure), in which i_ The mapping field points to an address_space structure. Such a file corresponds to an address_space structure; address_space object is the core data structure of in memory page cache in file system.
Page cache
Page cache is a disk cache that operates on complete data pages, that is, the data blocks of the disk are cached in the page cache. And address_space manages the page cache. Almost all file read and write operations in linux depend on page cache. Only in o_ An exception occurs when the direct flag is set to: at this time, the transmission of I/O data bypasses the page cache and uses the buffer of the process user state address space; In addition, a small number of database software use o in order to adopt their own disk cache algorithm_ Direct flag.
why design page cache?
- Quickly locate owner related data pages (base tree)
- Different read and write operations to distinguish different owner pages, such as ordinary files, block device files and swap area files. Reading a data page must be implemented in different ways, so the kernel performs different operations according to different owners of the page.
ps: a physical page may contain multiple discontinuous physical blocks. Due to the discontinuity of the blocks constituting each page, it becomes more difficult to check the page cache to see whether some data has been cached. Therefore, it is not possible to index the data in the page cache only with the device name and block number, otherwise this will be the simplest solution.
For example, on x86 architecture, the size of physical pages is 4KB, while disk blocks on most file systems can be as small as 512 bytes. Therefore, a page may contain 8 blocks. Blocks do not have to be contiguous because the file itself may be laid out on the entire disk
Generally, when a user process calls mmap(), it only adds a buffer of corresponding size in the process space and sets the corresponding access ID, but does not establish the mapping from the process space to the physical page. Therefore, when the space is accessed for the first time, a page missing exception will be thrown. In the case of shared memory mapping, the missing page exception handler first looks for the target page (the physical page conforming to address_space and offset) in the swap cache. If it is found, it will directly return the address; If it is not found, judge whether the page is in the swap area. If it is, perform a swap in operation; If neither of the above conditions is satisfied, the handler allocates a new physical page and inserts it into the page cache. The process will eventually update the process page table. Note: for the case of mapping ordinary files (non shared mapping), the missing page exception handler will first use the address in the page cache_ Space and data offset to find the corresponding page. If it is not found, it indicates that the file data has not been read into the memory, and the handler will read the corresponding page from the disk and return the corresponding address. At the same time, the process page table will be updated.
/* It is used to manage some parts of a file (struct inode) mapped to a memory page (struct page). In fact, each file has such a structure, Bind the data corresponding to this file in the file system with the memory corresponding to this file; Corresponding to it, address_space_operations is used to Operate the file to map to the page in memory, such as writing the changes in memory back to the file, reading data from the file to the page buffer, etc. file There is an address in both the inode structure and the inode structure_ Space structure pointer, in fact, file - > F_ Mapping is from the corresponding inode - > I_ From mapping, inode->i_mapping->a_ops It is given by the corresponding file system type when generating this inode. */ struct address_space { struct inode *host; /* owner: inode, block_device The node that owns it */ struct radix_tree_root page_tree; /* radix tree of all pages Radio tree containing all pages */ spinlock_t tree_lock; /* and lock protecting it Protect page_ Spin lock of tree*/ atomic_t i_mmap_writable;/* count VM_SHARED mappings Number of shared mappings VM_SHARED counting*/ struct rb_root i_mmap; /* tree of private and shared mappings The root of the priority search tree*/ struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list Protection I_ Semaphore of MMAP*/ /* Protected by tree_lock together with the radix tree */ unsigned long nrpages; /* number of total pages Total pages */ unsigned long nrshadows; /* number of shadow entries */ pgoff_t writeback_index;/* writeback starts here Start offset of writeback */ const struct address_space_operations *a_ops; /* methods Operation function table*/ unsigned long flags; /* error bits/gfp mask gfp_mask Mask and error identification */ spinlock_t private_lock; /* for use by the address_space Private address_space lock */ struct list_head private_list; /* ditto Private address_space linked list */ void *private_data; /* ditto Related buffer*/ } __attribute__((aligned(sizeof(long))));
address_ One of the functions of the space structure is the page cache used to store files. The functions of various fields are described below:
- host: points to the current address_ The inode object of the file to which the space object belongs (each file is represented by an inode object).
- page_tree: the page cache used to store the current file.
- tree_lock: used to prevent concurrent access to the page_ Resource competition caused by tree.
From address_ As can be seen from the definition of the space object, the page cache of the file uses a radius tree to store.
Radius tree: also known as cardinality tree, it uses key value pairs to save data, and can quickly find its corresponding value through keys. The kernel takes the data offset in the file read-write operation as the key and the page cache where the data offset is located as the value, which is stored in address_ Page of space structure_ In the tree field.
address_space object
Each owner (which can be understood as a specific file, a file pointed to by an inode) corresponds to an address_ Space object, multiple pages of the page cache may belong to one owner, so they can be linked to an address_ Space object. So how does a page match an address_ What about space? Each page descriptor includes two fields mapping and index that link the page to the page cache. Mapping points to the address of the inode that owns the page_ Space object (inode structure has an i_mapping object pointing to the corresponding address_space object), and the index field represents the offset in page size in the owner's address space, that is, the position of data in the page in the owner's disk image. address_ There is a host field in space, which points to the inode to which it belongs, that is, address_ The host field in space is the same as the I field in the corresponding inode_ The data fields form a pointing relationship with each other. If it is a normal file, the inode node and address_ The pointing relationship of the corresponding pointers of the space structure is shown in the following figure:
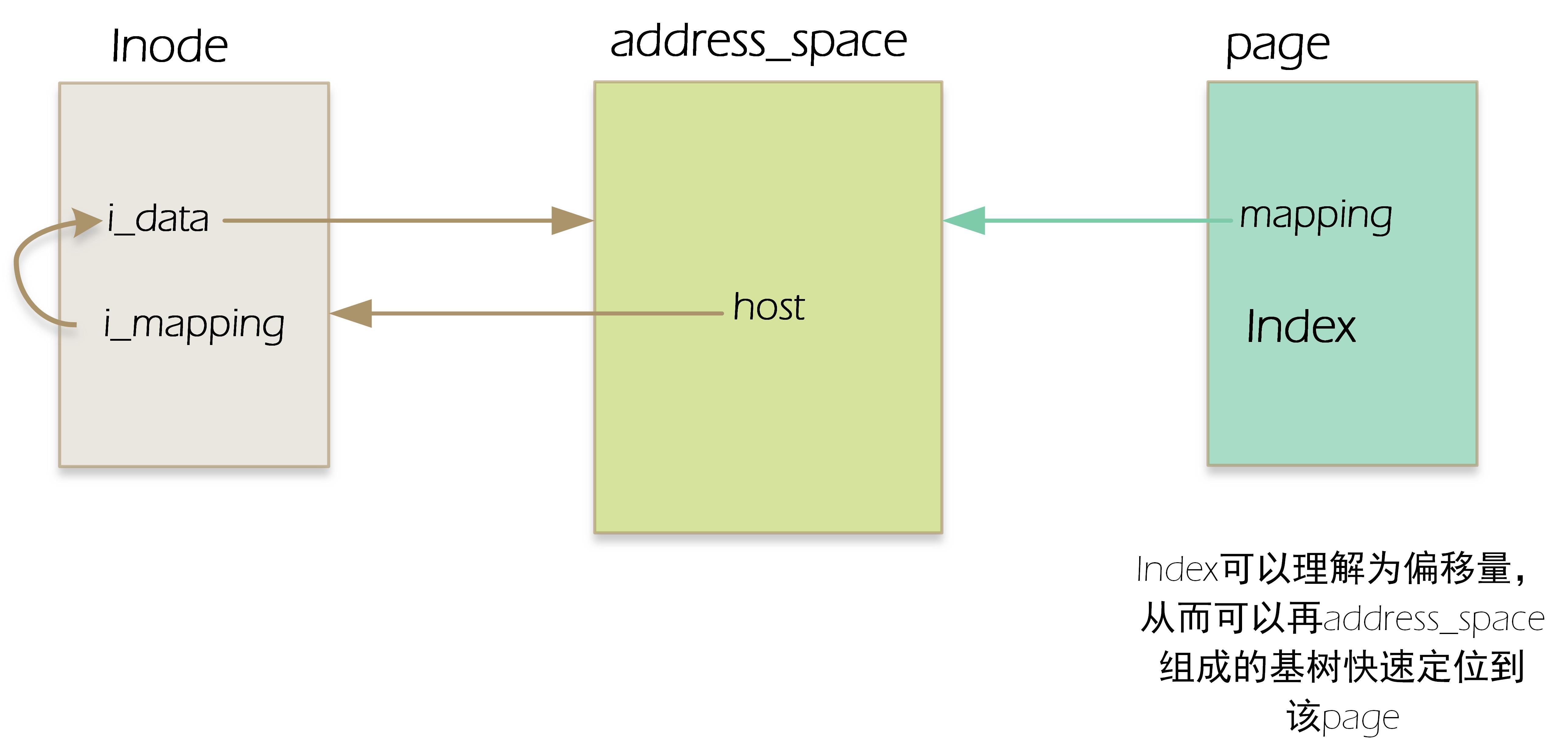
/* * Keep mostly read-only and often accessed (especially for * the RCU path lookup and 'stat' data) fields at the beginning * of the 'struct inode' inode There are two types: one is the inode of VFS and the other is the inode of specific file system. The former is in memory and the latter is on disk. So every time, you actually call inodes in the disk into inodes that fill the memory, This is the disk file inode used. inode Relationship with files: when a file is created, an inode is assigned to the file. An inode only corresponds to one actual file, and a file will have only one inode. inodes The maximum number is the maximum number of files. */ struct inode { umode_t i_mode;//File type and access rights unsigned short i_opflags; kuid_t i_uid;//File owner label kgid_t i_gid;//Group label of the file unsigned int i_flags; const struct inode_operations *i_op;//Set of inode operation functions struct super_block *i_sb;//inode Superblock pointer to the owning file system struct address_space *i_mapping;//Indicates who the page is requested from and describes the page in the page cache /* Stat data, not accessed from path walking */ unsigned long i_ino;//Inode number, each inode Are unique
struct address_space i_data;//--------------------------------------> void *i_private; /* fs or device private pointer */ };
struct file { ... struct address_space *f_mapping; };
4 base tree
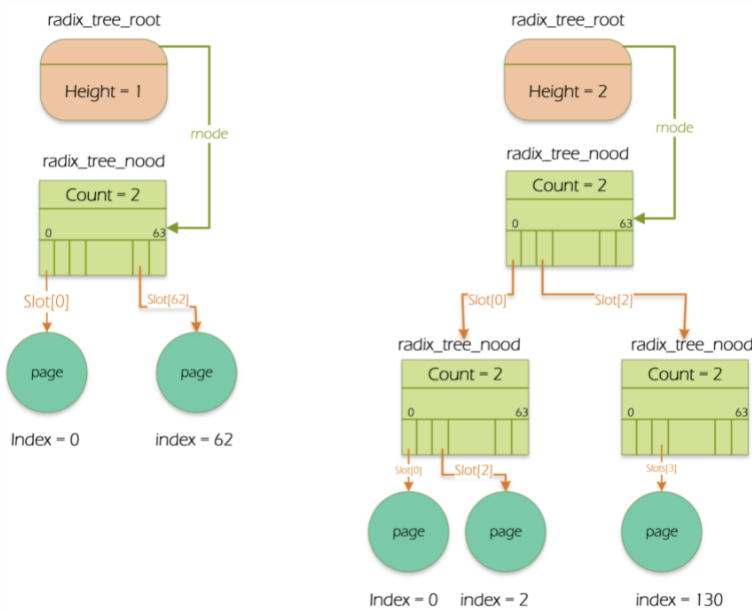
linux supports terabyte files, and ext4 even supports petabyte files. When accessing large files, there are too many pages about the file in the cache, so the base tree structure is designed to speed up the search. An address_ The space object corresponds to a base tree.
address_ A field (page_tree) in space points to the root of the base tree (radius_tree_root). The rnode in the root of the base tree points to the highest level node (radio_tree_node) of the base tree. All base tree nodes are radio_ tree_ Node structure. All stored in the node are pointers. The pointer of the leaf node points to the page descriptor, and the upper node points to the pointer of other nodes. Generally a radio_ tree_ Node can have up to 64 pointers, and the field count represents the radius_ tree_ Node number of used nodes.
How to quickly find the position of the required page in the base tree?
--->How does the paging system use the page table to realize the conversion from linear address to physical address? The highest 20 bits of the linear address are divided into two 10 fields: the first field is the offset of the page directory, and the second field is the offset of the table pointed to by the page directory.
A similar approach is used in the base tree. The page index is equivalent to a linear address, but the number of fields to be considered in the page index depends on the depth of the base tree. If the depth of the base tree is 1, it can only represent indexes ranging from 0 to 63. Therefore, the lower 6 bits of the page index are interpreted as the subscripts of the slots array, and each subscript corresponds to a node in the first layer. If the depth of the base tree is 2, it can represent the index from 0 to 4095. The lower 12 bits of the page index are divided into two 6-bit fields. The high-order field is used to represent the subscript of the first layer node array, and the low-order field is used to represent the subscript of the second layer array.
Read file operation
Now let's analyze the process of reading file data. Users can read the data in the file by calling the read system call. The call chain is as follows:
read()
└→ sys_read()
└→ vfs_read()
└→ do_sync_read()
└→ generic_file_aio_read()
└→ do_generic_file_read()
Disk cache. It includes Page Cache (disk cache that operates on complete data pages) + directory item cache (directory item object describing file system pathname) + inode cache (Buffer Cache, which stores inode objects describing disk index nodes). This paper mainly discusses Page Cache. With Page Cache, The kernel code and data structures do not have to be read from or written to disk. Page caching can be seen as part of a particular file system layer
The read system call will eventually call do_generic_file_read function to read the data in the file. Its implementation is as follows:
void do_generic_file_read(struct address_space *mapping, struct file_ra_state *_ra, struct file *filp, loff_t *ppos, read_descriptor_t *desc, read_actor_t actor) { struct inode *inode = mapping->host; unsigned long index; struct page *cached_page; ... cached_page = NULL; index = *ppos >> PAGE_CACHE_SHIFT; ... for (;;) { struct page *page; ... find_page: // 1. Find whether the page cache where the file offset is located exists page = find_get_page(mapping, index); if (!page) { ... // 2. If the page cache does not exist, So jump to no_cached_page Process goto no_cached_page; } ... page_ok: ... // 3. If page cache exists, Then copy the page cache data to the memory of the user application ret = actor(desc, page, offset, nr); ... if (ret == nr && desc->count) continue; goto out; ... readpage: // 4. Read data from file to page cache error = mapping->a_ops->readpage(filp, page); ... goto page_ok; ... no_cached_page: if (!cached_page) { // 5. Request a memory page as a page cache cached_page = page_cache_alloc_cold(mapping); ... } // 6. Add the newly requested page cache to the file page cache error = add_to_page_cache_lru(cached_page, mapping, index, GFP_KERNEL); ... page = cached_page; cached_page = NULL; goto readpage; } out: ... }
do_ generic_ mapping_ The implementation of the read function is complex. After simplification, only the most important logic is left in the above code, which can be summarized into the following steps:
- By calling find_ get_ The page function finds out whether the page cache corresponding to the file offset to be read exists. If so, copy the data in the page cache to the memory of the application.
- Otherwise, call page_ cache_ alloc_ The cold function requests a free memory page as a new page cache and calls add_ to_ page_ cache_ The LRU function adds the newly applied page cache to the file page cache and LRU queue (described later).
- Read the data from the file to the page cache by calling the readpage interface, and copy the data from the page cache to the memory of the application.
As can be seen from the above code, when the page cache does not exist, a free memory page will be applied as the page cache and added by calling add_ to_ page_ cache_ The LRU function adds it to the page cache and LRU queue of the file. Let's look at add_ to_ page_ cache_ Implementation of LRU function:
int add_to_page_cache_lru(struct page *page, struct address_space *mapping, pgoff_t offset, gfp_t gfp_mask) { // 1. Add page cache to file page cache int ret = add_to_page_cache(page, mapping, offset, gfp_mask); if (ret == 0) lru_cache_add(page); // 2. Add page cache to LRU In queue return ret; }
add_to_page_cache_lru function mainly completes two tasks:
- By calling add_ to_ page_ The cache function adds the page cache to the file page cache, that is, to address_ Page of space structure_ In the tree field.
- By calling LRU_ cache_ The add function adds the page cache to the LRU queue. The LRU queue is used to clean up the page cache when the system memory is insufficient.
PS: I remember a memory problem:
When Linux was first introduced, i386 4G process space was typically divided into 3G user + 1G kernel, which is said in textbooks. According to the previous linear method, 1g kernel space can only map 1g physical address space, which is too restrictive for the kernel. Therefore, the compromise solution is that the Linux kernel only linearly maps the first 896 MB of 1G kernel space according to the above method, and the remaining 128 MB kernel space adopts the way of dynamic mapping [1], that is, on-demand mapping. In this way, there is more access space in the kernel state. In the 64 bit era, the kernel space is greatly increased, and this limitation is gone. The kernel space can be completely linearly mapped. However, for the sake of [1], dynamic mapping is still retained.
Dynamic mapping is not complete so that the kernel space can access more physical memory. There is another important reason: when the kernel needs continuous multi page space, if the kernel space is fully linear mapping, the kernel space may be fragmented and can not meet the needs of so many continuous page allocation. Based on this, part of the kernel space must also be nonlinear mapping. Therefore, on this fragmented physical address space, the page table is used to construct a continuous virtual address space, which is the so-called vmalloc space.