handle_mm_fault is an architecture independent page fault processing part, which is mainly processed according to the virtual address of page fault, the corresponding vma found in the above steps and the specific error type of flag after error code conversion. It is the core function of the kernel to process page fault. Its interface is as follows:
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address, unsigned int flags)
Parameters:
- struct vm_area_struct *vma: vma corresponding to pag fault address
- unsigned long address: the address where the page fault is generated
- unsigned int flags: convert the error code returned by the hardware into the corresponding flag process for processing.
Return value:
- vm_fault_t: The processing page fault value returned by the function. If it is 0 and the processing is successful, other non-zero value codes and various error messages
vm_fault_t and flags information can be obtained from page fault (AMD64 Architecture) (user space) (2) Specific understanding.
handle_mm_fault function calling relationship
handle_ mm_ The fault function deals with replication and needs to deal with various scenarios. It can be said that it is a relatively complex process of the kernel. The 2.4 kernel version code used in understanding linux virtual memory has many features that were not involved in version 2.4 at that time. The following is the update of the calling relationship combined with the kernel code of version 5.8.10, as follows:
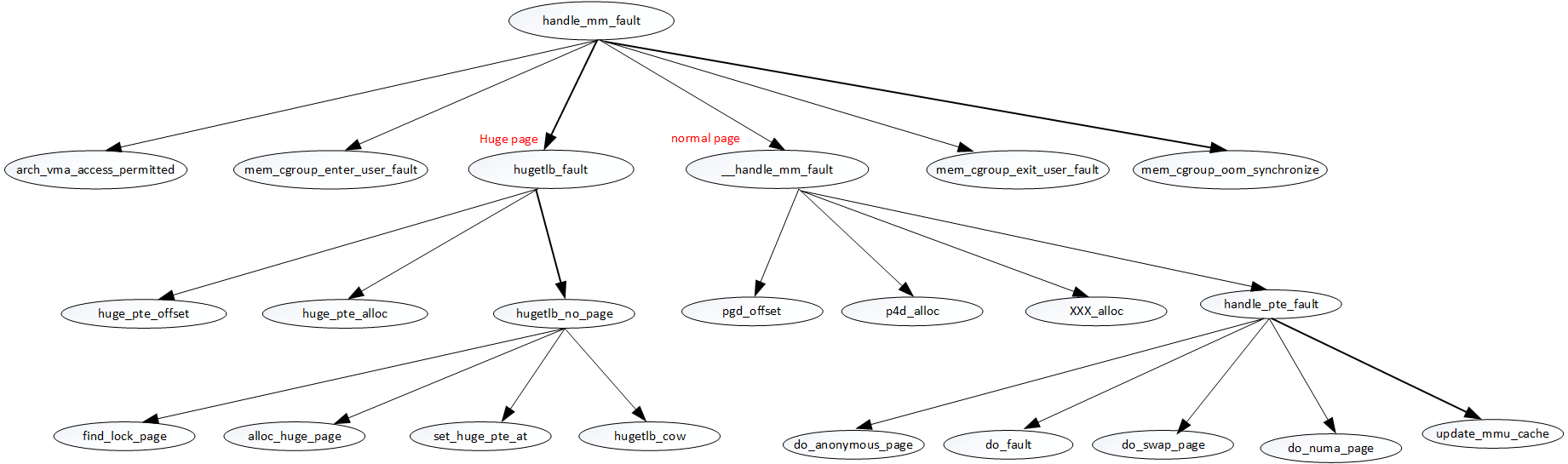
handle_mm_fault
handle_ mm_ The source code of fault is as follows:
/*
* By the time we get here, we already hold the mm semaphore
*
* The mmap_lock may have been released depending on flags and our
* return value. See filemap_fault() and __lock_page_or_retry().
*/
vm_fault_t handle_mm_fault(struct vm_area_struct *vma, unsigned long address,
unsigned int flags)
{
vm_fault_t ret;
__set_current_state(TASK_RUNNING);
count_vm_event(PGFAULT);
count_memcg_event_mm(vma->vm_mm, PGFAULT);
/* do counter updates before entering really critical section. */
check_sync_rss_stat(current);
if (!arch_vma_access_permitted(vma, flags & FAULT_FLAG_WRITE,
flags & FAULT_FLAG_INSTRUCTION,
flags & FAULT_FLAG_REMOTE))
return VM_FAULT_SIGSEGV;
/*
* Enable the memcg OOM handling for faults triggered in user
* space. Kernel faults are handled more gracefully.
*/
if (flags & FAULT_FLAG_USER)
mem_cgroup_enter_user_fault();
if (unlikely(is_vm_hugetlb_page(vma)))
ret = hugetlb_fault(vma->vm_mm, vma, address, flags);
else
ret = __handle_mm_fault(vma, address, flags);
if (flags & FAULT_FLAG_USER) {
mem_cgroup_exit_user_fault();
/*
* The task may have entered a memcg OOM situation but
* if the allocation error was handled gracefully (no
* VM_FAULT_OOM), there is no need to kill anything.
* Just clean up the OOM state peacefully.
*/
if (task_in_memcg_oom(current) && !(ret & VM_FAULT_OOM))
mem_cgroup_oom_synchronize(false);
}
return ret;
}
- Activate the current process in RUNNING state
- Count the number of page fault s
- check_sync_rss_stat: multi-core spin lock feature. When the cpu is multi-core, the spin lock has been owned by another cpu core lock, and the core will not be able to own and obtain the lock, which is in the spin waiting state. In order to improve performance, multiple locks can be used for multi-core scenarios to reduce the waiting state. Allow user configurable CONFIG_SPLIT_PTLOCK_CPUS and actual physical core CONFIG_NR_CPUS is not completely consistent, and users can configure it as needed. Now you need to check that the usage exceeds the limit for synchronization
- User space exception, set in_user_fault is 1 to prevent the memory or process of this process from being killed when OOM occurs
- According to VMA > VM_ Flags set VM_HUGETLB to judge whether it is huget page
- If it is a huge page, enter hugetlb_fault processing
- Non huge page, call__ handle_mm_fault processing
- After processing, put in_ user_ If fault is set to 0, this process can also be processed by OOM
- If the current process, it will also be processed by OOM and MEM will be called_ cgroup_ OOM_ Synchronize completes the OOM processing of this process.
__handle_mm_fault
__ handle_mm_fault is a further processing function of page fault for processing normal pages, including most processing logic:
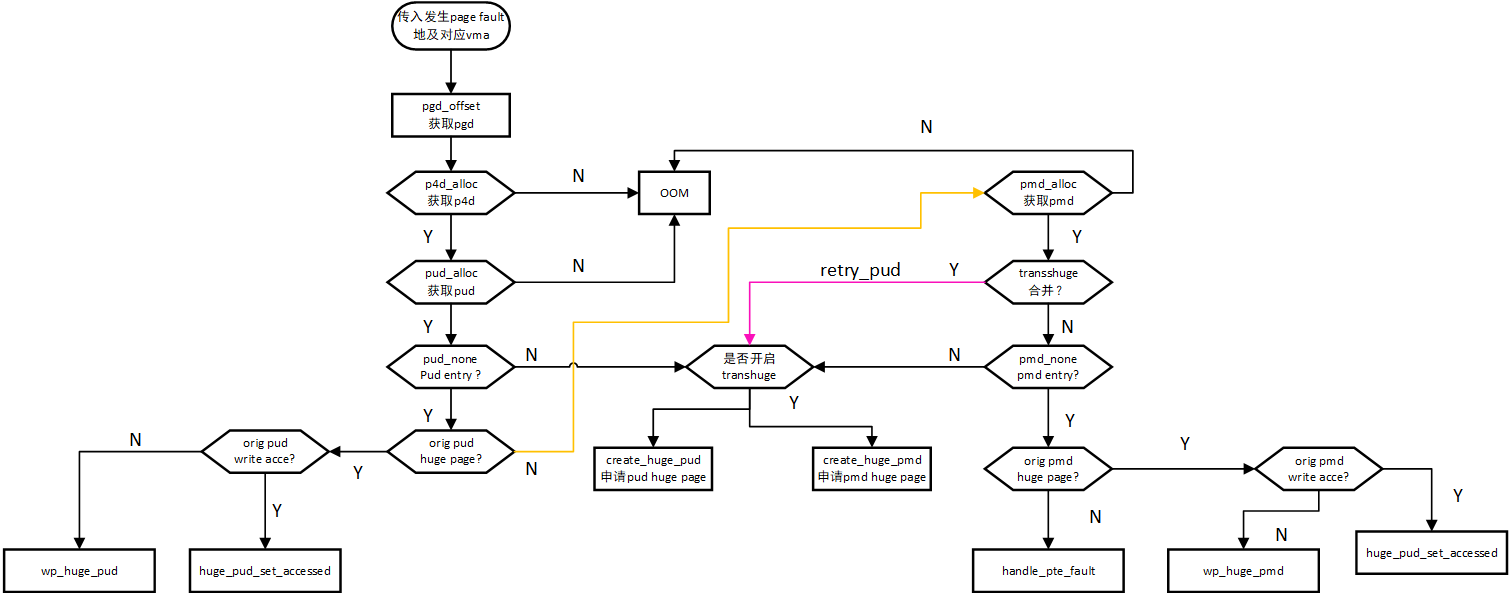
The processing logic is basically processed according to the five level conversion page table:
- pgd_offset: get the PGD table according to the address.
- p4d_alloc: get the p4d table according to pgd and address. If the p4d table does not exist, call__ p4d_alloc requests a new p4d table from physical memory.
- pud_alloc: get the PUD table according to p4d and address. If the PUD table does not exist, call__ pud_alloc requests a new p4d table from physical memory.
- At this time, check whether the transport huge page feature is enabled. If it is enabled and pud_none means that there is no pud entry. According to the vma, you can apply for a pud level huge page, and pud_none means that there is no pud entry, then call create_huge_pud directly applies for huge page processing.
- pud_ If none already exists, get whether the pud entry attribute is huge page and check the permission. If the flags require write permission, but the pud entry does not have write permission, call WP_ huge_ For example, when the parent-child processes inherit the memory PUD in the scenario, only the parent-child processes will inherit the memory PUD in the scenario (for example, when the parent-child processes inherit the memory PUD in the scenario).
- transport huge page is not opened and PUD_ If none exists and is a normal page, continue with the normal walk page table and enter pmd.
- pmd_alloc, if the PMD table does not exist, apply for a new one.
- At this time, check the pmd attribute to see if it can be merged with pud level huge page and reduce the number of page table s. If it can be merged, enter retry_pud processing.
- Can not be merged, and pmd_ If none does not exist and the transport huge page is opened, then create is called directly_ huge_ pmd carries out pmd level huge page processing.
- If pmd entry exists, check its attributes. If pmd huge page, flag requires write permission and pmd does not have write permission, enter wp_huge_pmd processing
- If the pmd entry check is not a huge page, proceed to the next step and enter the handle normally_ pte_ Fault processing.
- handle_pte_fault will be processed separately according to different vma attributes.
struct vm_fault
__ handle_ mm_ In addition to handling the transport huge page feature and huge page in the walk page table, the fault function also plays an important role in filling the struct vm_fault structure, which is the necessary information for the subsequent processing of page fault organization. Subsequently, a processing result will also be filled into struct VM_ In fault, the structure is defined as follows:
/*
* vm_fault is filled by the the pagefault handler and passed to the vma's
* ->fault function. The vma's ->fault is responsible for returning a bitmask
* of VM_FAULT_xxx flags that give details about how the fault was handled.
*
* MM layer fills up gfp_mask for page allocations but fault handler might
* alter it if its implementation requires a different allocation context.
*
* pgoff should be used in favour of virtual_address, if possible.
*/
struct vm_fault {
struct vm_area_struct *vma; /* Target VMA */
unsigned int flags; /* FAULT_FLAG_xxx flags */
gfp_t gfp_mask; /* gfp mask to be used for allocations */
pgoff_t pgoff; /* Logical page offset based on vma */
unsigned long address; /* Faulting virtual address */
pmd_t *pmd; /* Pointer to pmd entry matching
* the 'address' */
pud_t *pud; /* Pointer to pud entry matching
* the 'address'
*/
pte_t orig_pte; /* Value of PTE at the time of fault */
struct page *cow_page; /* Page handler may use for COW fault */
struct page *page; /* ->fault handlers should return a
* page here, unless VM_FAULT_NOPAGE
* is set (which is also implied by
* VM_FAULT_ERROR).
*/
/* These three entries are valid only while holding ptl lock */
pte_t *pte; /* Pointer to pte entry matching
* the 'address'. NULL if the page
* table hasn't been allocated.
*/
spinlock_t *ptl; /* Page table lock.
* Protects pte page table if 'pte'
* is not NULL, otherwise pmd.
*/
pgtable_t prealloc_pte; /* Pre-allocated pte page table.
* vm_ops->map_pages() calls
* alloc_set_pte() from atomic context.
* do_fault_around() pre-allocates
* page table to avoid allocation from
* atomic context.
*/
};
- struct vm_area_struct *vma: the vma structure to which addr belongs.
- unsigned int flags: FAULT_FLAG_xxx flags, in do_ user_ addr_ The fault function is converted from hard error code( page fault (AMD64 Architecture) (user space) (2)
- gfp_t gfp_mask: flag used to apply for memory__ handle_mm_fault function can be called_ get_fault_gfp_mask(vma), which is obtained from vma and transcoded into corresponding gfp_mask.
- pgoff_t pgoff: page offset in vma.
- unsigned long address: the virtual address where the page fault occurs.
- pmd_t *pmd: find the address of PMD table.
- pud_t *pud: PUD table address.
- pte_t orig_pte: the original PTE found by address.
- struct page *cow_pag: COW page fault processing.
- struct page *page: the physical page requested after page fault processing.
- pte_t *pte: Processed PTE.
- spinlock_t *ptl: page table lock.
- pgtable_t prealloc_pte: pre applied pte.
__ handle_ mm_ Struct VM in fault function_ Fault structure initialization:
static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
struct vm_fault vmf = {
.vma = vma,
.address = address & PAGE_MASK,
.flags = flags,
.pgoff = linear_page_index(vma, address),
.gfp_mask = __get_fault_gfp_mask(vma),
};
... ...
}
handle_pte_fault
handle_ pte_ The fault function is the last level of processing in the walk page table in page fault. It is mainly used for further processing in different usage scenarios according to the PTE finally found and various memory usage flag s marked in vma. The main processing logic is as follows:
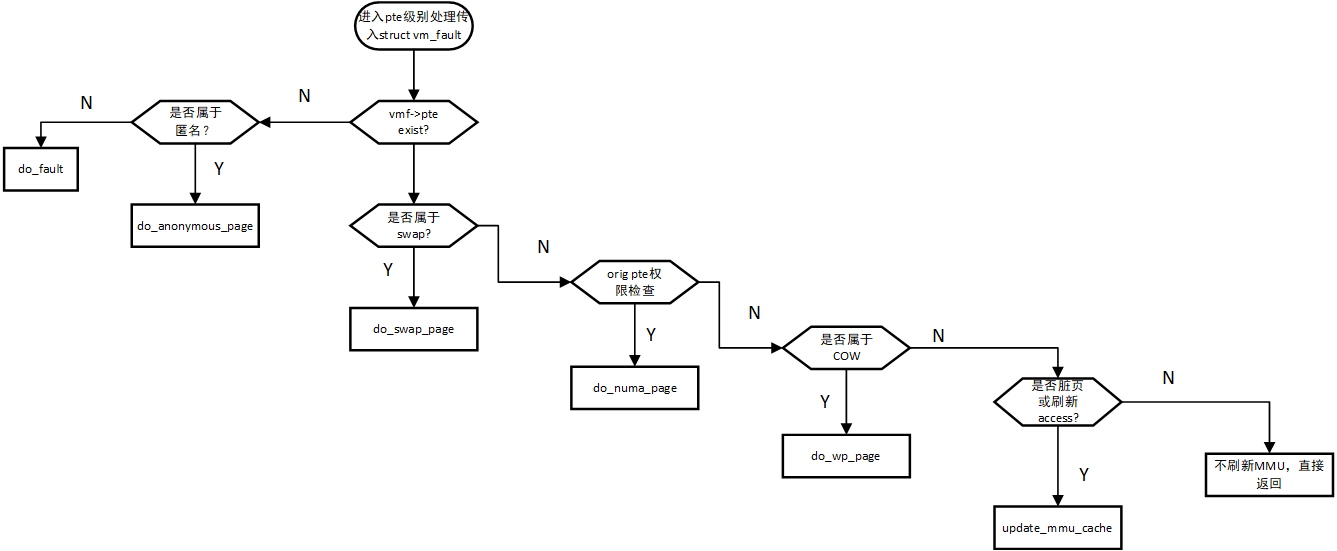
It needs to be further explained in combination with the code:
/*
* These routines also need to handle stuff like marking pages dirty
* and/or accessed for architectures that don't do it in hardware (most
* RISC architectures). The early dirtying is also good on the i386.
*
* There is also a hook called "update_mmu_cache()" that architectures
* with external mmu caches can use to update those (ie the Sparc or
* PowerPC hashed page tables that act as extended TLBs).
*
* We enter with non-exclusive mmap_lock (to exclude vma changes, but allow
* concurrent faults).
*
* The mmap_lock may have been released depending on flags and our return value.
* See filemap_fault() and __lock_page_or_retry().
*/
static vm_fault_t handle_pte_fault(struct vm_fault *vmf)
{
pte_t entry;
if (unlikely(pmd_none(*vmf->pmd))) {
/*
* Leave __pte_alloc() until later: because vm_ops->fault may
* want to allocate huge page, and if we expose page table
* for an instant, it will be difficult to retract from
* concurrent faults and from rmap lookups.
*/
vmf->pte = NULL;
} else {
/* See comment in pte_alloc_one_map() */
if (pmd_devmap_trans_unstable(vmf->pmd))
return 0;
/*
* A regular pmd is established and it can't morph into a huge
* pmd from under us anymore at this point because we hold the
* mmap_lock read mode and khugepaged takes it in write mode.
* So now it's safe to run pte_offset_map().
*/
vmf->pte = pte_offset_map(vmf->pmd, vmf->address);
vmf->orig_pte = *vmf->pte;
/*
* some architectures can have larger ptes than wordsize,
* e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and
* CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic
* accesses. The code below just needs a consistent view
* for the ifs and we later double check anyway with the
* ptl lock held. So here a barrier will do.
*/
barrier();
if (pte_none(vmf->orig_pte)) {
pte_unmap(vmf->pte);
vmf->pte = NULL;
}
}
if (!vmf->pte) {
if (vma_is_anonymous(vmf->vma))
return do_anonymous_page(vmf);
else
return do_fault(vmf);
}
if (!pte_present(vmf->orig_pte))
return do_swap_page(vmf);
if (pte_protnone(vmf->orig_pte) && vma_is_accessible(vmf->vma))
return do_numa_page(vmf);
vmf->ptl = pte_lockptr(vmf->vma->vm_mm, vmf->pmd);
spin_lock(vmf->ptl);
entry = vmf->orig_pte;
if (unlikely(!pte_same(*vmf->pte, entry))) {
update_mmu_tlb(vmf->vma, vmf->address, vmf->pte);
goto unlock;
}
if (vmf->flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(vmf);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
if (ptep_set_access_flags(vmf->vma, vmf->address, vmf->pte, entry,
vmf->flags & FAULT_FLAG_WRITE)) {
update_mmu_cache(vmf->vma, vmf->address, vmf->pte);
} else {
/* Skip spurious TLB flush for retried page fault */
if (vmf->flags & FAULT_FLAG_TRIED)
goto unlock;
/*
* This is needed only for protection faults but the arch code
* is not yet telling us if this is a protection fault or not.
* This still avoids useless tlb flushes for .text page faults
* with threads.
*/
if (vmf->flags & FAULT_FLAG_WRITE)
flush_tlb_fix_spurious_fault(vmf->vma, vmf->address);
}
unlock:
pte_unmap_unlock(vmf->pte, vmf->ptl);
return 0;
}
Main steps:
- Fill in VMF - > PTE and VMF - > orig_ PTE is convenient for subsequent processing
- VMF - > pte is NULL, which indicates that the virtual address has not been mapped, so pte and corresponding physical memory need to be applied
- If the mapping is anonymous, VMA - > VM_ If OPS is NULL, do is called_ anonymous_ Page and return. Generally, the memory requested through malloc or mmap anonymous mapping belongs to anonymous mapping, and most of them belong to anonymous mapping
- If VMA - > vm_ops is not NULL, that is, it is not an anonymous mapping. Call do_fault is processed and returned, and finally VMA - > VM will be called_ fault interface in ops. Non anonymous mapping, i.e. file mapping, is generally the file mapping applied through mmap, that is, with fd parameter in mmap. File mapping is generally used for a special space used by special drivers for special use. Drivers can register the corresponding VM according to their own needs_ ops. Or it can also be used as a file operation
- VMF - > pte is not empty, indicating that there is a corresponding pte in this address. Further find out whether there is a pte on the physical page in the pte_present, if it does not exist, indicates that the page may be replaced to the hard disk. It is necessary to load the content of the page from disk to memory and call do_. swap_ Page process and return.
- If VMF - > PTE is not empty and the physical page exists, you need to further check whether the actual permission of the physical page is none and check the required permission through vma. If vma sets the access permission, but the actual physical page does not have access permission none, call do_numa_page process and return.
- If none of the above conditions is true, further check whether the page fault is caused by writing memory. If the page fault is caused by writing memory and the physical page in the corresponding pte does not have write permission, it may be a COW scenario and you need to call do_wp_page for processing.
- None of the above is true. There is a corresponding physical mapping for the virtual address. Check whether the permissions in vma are consistent with the pte permissions, and set the access permissions and dirty page dirty flag as needed. This is the only case left. It is necessary to refresh update_mmu_cache, update the access permission and dirty page dirty flag in PTE entry.
reference material
c - Meaning of a piece of code in execv() system call - Stack Overflow