brief introduction
Pandas provides many powerful functions of merging Series and Dataframe, which can facilitate data analysis. This article will explain in detail how to use pandas to merge Series and Dataframe.
Using concat
The most commonly used method is DF concat. Let's look at the following:
pd.concat(objs, axis=0, join='outer', ignore_index=False, keys=None,
levels=None, names=None, verify_integrity=False, copy=True)
Let's take a look at some parameters we often use:
objs is a Series or Series sequence or mapping.
Axis specifies the axis of the connection.
join: {inner ','outer'}, connection method, how to deal with the index of other axes. Outer means merge and inner means intersection.
ignore_index: ignore the original index value and use 0,1,... n-1 instead.
Copy: whether to copy.
keys: Specifies the index of the outermost multi-level structure.
Let's first define several DFS, and then see how to use concat to connect these DFS:
In [1]: df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
...: 'B': ['B0', 'B1', 'B2', 'B3'],
...: 'C': ['C0', 'C1', 'C2', 'C3'],
...: 'D': ['D0', 'D1', 'D2', 'D3']},
...: index=[0, 1, 2, 3])
...:
In [2]: df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],
...: 'B': ['B4', 'B5', 'B6', 'B7'],
...: 'C': ['C4', 'C5', 'C6', 'C7'],
...: 'D': ['D4', 'D5', 'D6', 'D7']},
...: index=[4, 5, 6, 7])
...:
In [3]: df3 = pd.DataFrame({'A': ['A8', 'A9', 'A10', 'A11'],
...: 'B': ['B8', 'B9', 'B10', 'B11'],
...: 'C': ['C8', 'C9', 'C10', 'C11'],
...: 'D': ['D8', 'D9', 'D10', 'D11']},
...: index=[8, 9, 10, 11])
...:
In [4]: frames = [df1, df2, df3]
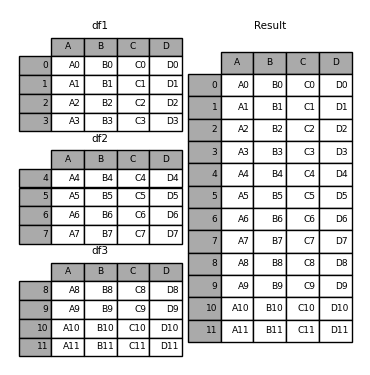
In [5]: result = pd.concat(frames)
DF1, df2 and DF3 define the same column names and different index es, and then put them in frames to form a list of DFS. You can merge DFS by passing them into concat as parameters.
Take a multi-level example:
In [6]: result = pd.concat(frames, keys=['x', 'y', 'z'])
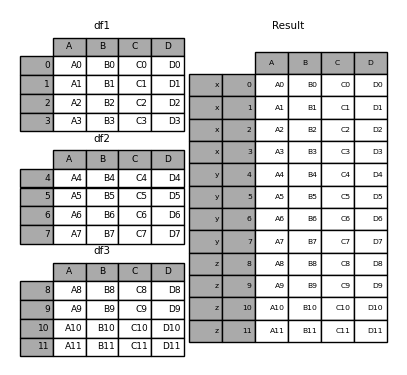
Using keys, you can specify the keys of different frames in frames.
When using, we can return a specific frame by selecting an external key:
In [7]: result.loc['y']
Out[7]:
A B C D
4 A4 B4 C4 D4
5 A5 B5 C5 D5
6 A6 B6 C6 D6
7 A7 B7 C7 D7
The axis of the above example is 0 by default, that is, it is connected by row. Let's take a look at an example of connecting by column. If you want to connect by column, you can specify axis=1:
In [8]: df4 = pd.DataFrame({'B': ['B2', 'B3', 'B6', 'B7'],
...: 'D': ['D2', 'D3', 'D6', 'D7'],
...: 'F': ['F2', 'F3', 'F6', 'F7']},
...: index=[2, 3, 6, 7])
...:
In [9]: result = pd.concat([df1, df4], axis=1, sort=False)
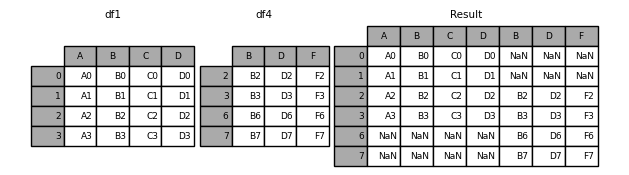
The default join='outer ', after merging, the non-existent index will be filled in as NaN.
Let's take a look at the situation of join='inner ':
In [10]: result = pd.concat([df1, df4], axis=1, join='inner')

join = 'inner' will only select the same index for display.
If we only want to save the data related to the index of the original frame after merging, we can use reindex:
In [11]: result = pd.concat([df1, df4], axis=1).reindex(df1.index)
Or this:
In [12]: pd.concat([df1, df4.reindex(df1.index)], axis=1)
Out[12]:
A B C D B D F
0 A0 B0 C0 D0 NaN NaN NaN
1 A1 B1 C1 D1 NaN NaN NaN
2 A2 B2 C2 D2 B2 D2 F2
3 A3 B3 C3 D3 B3 D3 F3
Look at the results:

DF and Series can be combined:
In [18]: s1 = pd.Series(['X0', 'X1', 'X2', 'X3'], name='X') In [19]: result = pd.concat([df1, s1], axis=1)
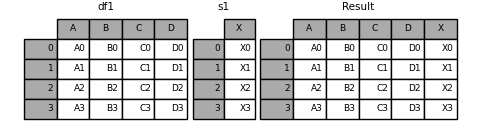
If there are multiple Series, use concat to specify the column name:
In [23]: s3 = pd.Series([0, 1, 2, 3], name='foo') In [24]: s4 = pd.Series([0, 1, 2, 3]) In [25]: s5 = pd.Series([0, 1, 4, 5])
In [27]: pd.concat([s3, s4, s5], axis=1, keys=['red', 'blue', 'yellow']) Out[27]: red blue yellow 0 0 0 0 1 1 1 1 2 2 2 4 3 3 3 5
Use append
append can be regarded as a simplified version of concat, which concatenates along axis=0:
In [13]: result = df1.append(df2)
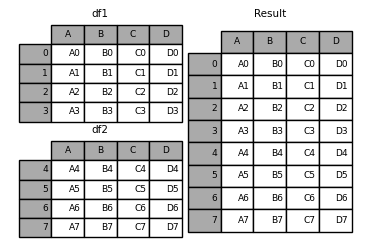
If the two DF columns of append are different, the NaN will be completed automatically:
In [14]: result = df1.append(df4, sort=False)
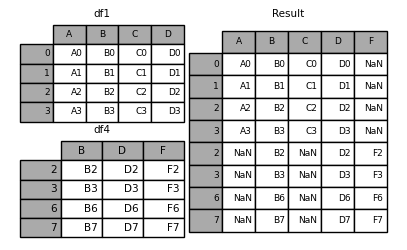
If ignore is set_ Index = true, you can ignore the original index and rewrite the allocation index:
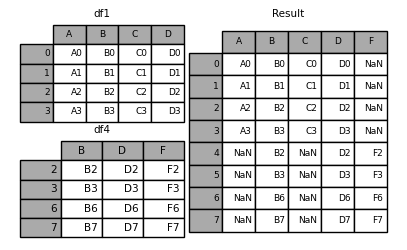
In [17]: result = df1.append(df4, ignore_index=True, sort=False)
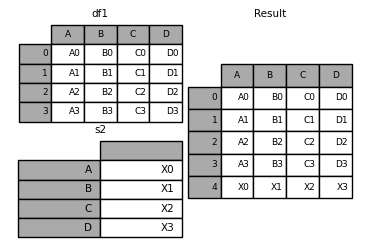
Attach a Series to DF:
In [35]: s2 = pd.Series(['X0', 'X1', 'X2', 'X3'], index=['A', 'B', 'C', 'D']) In [36]: result = df1.append(s2, ignore_index=True)
Using merge
The most similar to DF is the table of the database. You can use merge to perform DF merging operations similar to database operations.
Let's first look at the definition of merge:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
Left and right are two DF or Series to be merged.
on represents the column or index name of the join.
left_on: left connection
right_on: right connection
left_index: after connecting, select index or column on the left.
right_index: after connecting, select index or column on the right.
how: connection method, 'left', 'right', 'outer', 'inner' Default inner
Sort: whether to sort.
suffixes: handle duplicate columns.
Copy: copy data
Let's take a simple merge example:
In [39]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [40]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [41]: result = pd.merge(left, right, on='key')
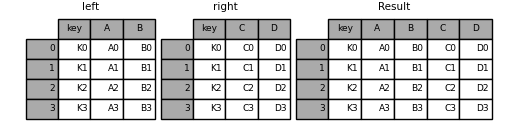
The above two DF S are connected by key.
Take another example of multiple key connections:
In [42]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [43]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [44]: result = pd.merge(left, right, on=['key1', 'key2'])

How can specify the merge mode. Like the database, it can specify internal connection, external connection, etc
| Merging method | SQL method |
|---|---|
| left | LEFT OUTER JOIN |
| right | RIGHT OUTER JOIN |
| outer | FULL OUTER JOIN |
| inner | INNER JOIN |
In [45]: result = pd.merge(left, right, how='left', on=['key1', 'key2'])
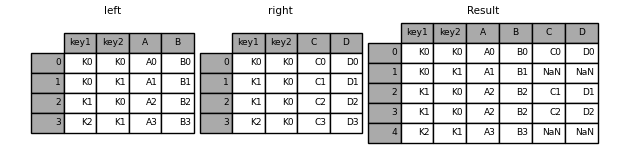
Specify indicator=True to indicate the connection method of specific lines:
In [60]: df1 = pd.DataFrame({'col1': [0, 1], 'col_left': ['a', 'b']})
In [61]: df2 = pd.DataFrame({'col1': [1, 2, 2], 'col_right': [2, 2, 2]})
In [62]: pd.merge(df1, df2, on='col1', how='outer', indicator=True)
Out[62]:
col1 col_left col_right _merge
0 0 a NaN left_only
1 1 b 2.0 both
2 2 NaN 2.0 right_only
3 2 NaN 2.0 right_only
If you pass in a string to the indicator, the name of the indicator column will be renamed:
In [63]: pd.merge(df1, df2, on='col1', how='outer', indicator='indicator_column') Out[63]: col1 col_left col_right indicator_column 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only
Merge multiple index es:
In [112]: leftindex = pd.MultiIndex.from_tuples([('K0', 'X0'), ('K0', 'X1'),
.....: ('K1', 'X2')],
.....: names=['key', 'X'])
.....:
In [113]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=leftindex)
.....:
In [114]: rightindex = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [115]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=rightindex)
.....:
In [116]: result = pd.merge(left.reset_index(), right.reset_index(),
.....: on=['key'], how='inner').set_index(['key', 'X', 'Y'])
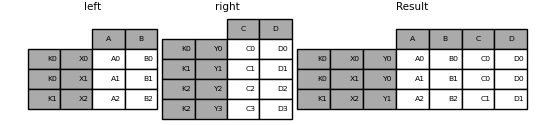
Support the merging of multiple columns:
In [117]: left_index = pd.Index(['K0', 'K0', 'K1', 'K2'], name='key1')
In [118]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
.....: 'B': ['B0', 'B1', 'B2', 'B3'],
.....: 'key2': ['K0', 'K1', 'K0', 'K1']},
.....: index=left_index)
.....:
In [119]: right_index = pd.Index(['K0', 'K1', 'K2', 'K2'], name='key1')
In [120]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3'],
.....: 'key2': ['K0', 'K0', 'K0', 'K1']},
.....: index=right_index)
.....:
In [121]: result = left.merge(right, on=['key1', 'key2'])
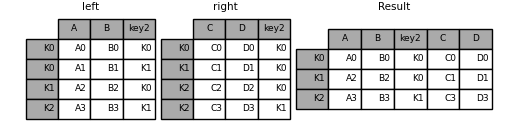
Using join
join combines two DF S with different index es into one. It can be regarded as the abbreviation of merge.
In [84]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
....: 'B': ['B0', 'B1', 'B2']},
....: index=['K0', 'K1', 'K2'])
....:
In [85]: right = pd.DataFrame({'C': ['C0', 'C2', 'C3'],
....: 'D': ['D0', 'D2', 'D3']},
....: index=['K0', 'K2', 'K3'])
....:
In [86]: result = left.join(right)
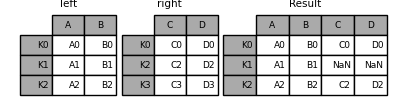
You can specify how to connect:
In [87]: result = left.join(right, how='outer')
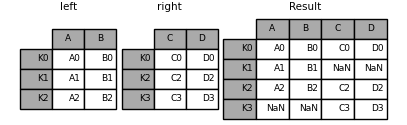
The default join is to connect by index.
You can also connect by column:
In [91]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3'],
....: 'key': ['K0', 'K1', 'K0', 'K1']})
....:
In [92]: right = pd.DataFrame({'C': ['C0', 'C1'],
....: 'D': ['D0', 'D1']},
....: index=['K0', 'K1'])
....:
In [93]: result = left.join(right, on='key')
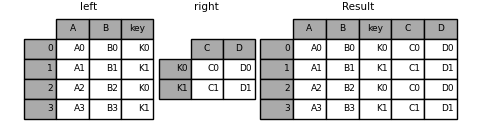
join a single index and multiple indexes:
In [100]: left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
.....: 'B': ['B0', 'B1', 'B2']},
.....: index=pd.Index(['K0', 'K1', 'K2'], name='key'))
.....:
In [101]: index = pd.MultiIndex.from_tuples([('K0', 'Y0'), ('K1', 'Y1'),
.....: ('K2', 'Y2'), ('K2', 'Y3')],
.....: names=['key', 'Y'])
.....:
In [102]: right = pd.DataFrame({'C': ['C0', 'C1', 'C2', 'C3'],
.....: 'D': ['D0', 'D1', 'D2', 'D3']},
.....: index=index)
.....:
In [103]: result = left.join(right, how='inner')
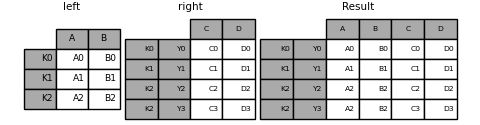
Duplicate column names:
In [122]: left = pd.DataFrame({'k': ['K0', 'K1', 'K2'], 'v': [1, 2, 3]})
In [123]: right = pd.DataFrame({'k': ['K0', 'K0', 'K3'], 'v': [4, 5, 6]})
In [124]: result = pd.merge(left, right, on='k')
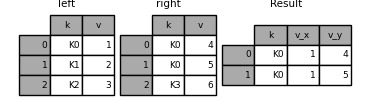
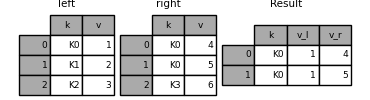
You can customize the naming rules for duplicate column names:
In [125]: result = pd.merge(left, right, on='k', suffixes=('_l', '_r'))
Overlay data
Sometimes we need to use DF2 data to fill DF1 data. At this time, we can use combine_first:
In [131]: df1 = pd.DataFrame([[np.nan, 3., 5.], [-4.6, np.nan, np.nan], .....: [np.nan, 7., np.nan]]) .....: In [132]: df2 = pd.DataFrame([[-42.6, np.nan, -8.2], [-5., 1.6, 4]], .....: index=[1, 2]) .....:
In [133]: result = df1.combine_first(df2)
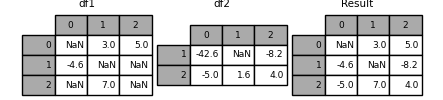
Or use update:
In [134]: df1.update(df2)
This article has been included in http://www.flydean.com/04-python-pandas-merge/
The most popular interpretation, the most profound dry goods, the most concise tutorial, and many tips you don't know are waiting for you to find!
Welcome to my official account: "those things in procedure", understand technology, know you better!