Pandas: How do I split text in a column into multiple lines?
In data processing, the following types of data are frequently encountered:
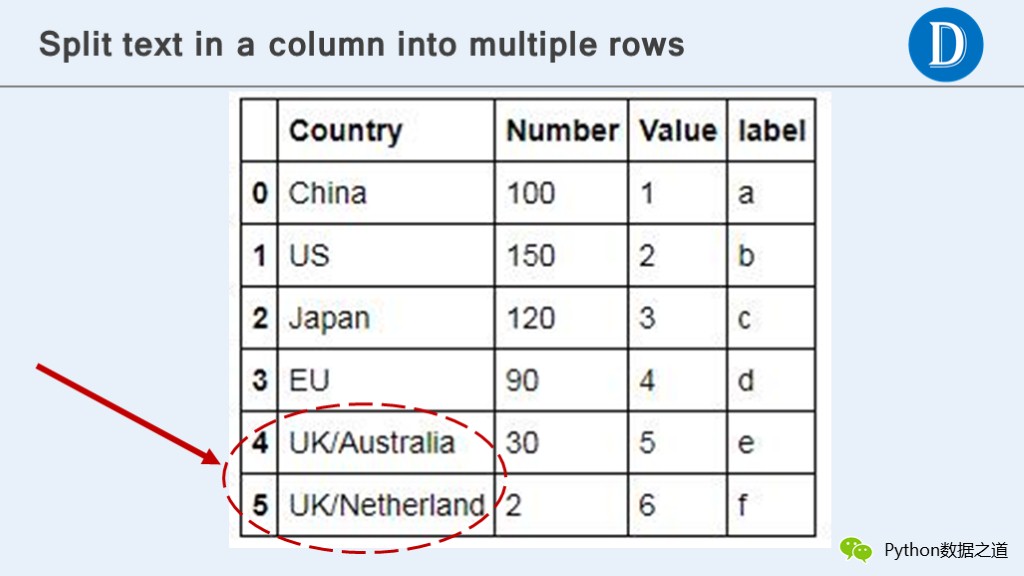
In the same column, data that should have been filled in multiple rows is filled in one row, but needs to be split into multiple rows for analysis.
In the figure above, the column is named "Country" and the index is in cells 4 and 5 with values of "UK/Australia" and "UK/Netherland".
Today, we'll show you a few ways to break up content with multiple values into multiple lines.
Loading data
PS: You can view the code by sliding left and right
import pandas as pd
df = pd.DataFrame({'Country':['China','US','Japan','EU','UK/Australia', 'UK/Netherland'],
'Number':[100, 150, 120, 90, 30, 2],
'Value': [1, 2, 3, 4, 5, 6],
'label': list('abcdef')})
df
Out[2]:
Country Number Value label
0 China 100 1 a
1 US 150 2 b
2 Japan 120 3 c
3 EU 90 4 d
4 UK/Australia 30 5 e
5 UK/Netherland 2 6 f
1 Method-1
It is divided into the following steps:
- The columns containing multiple values are split, transformed by the stack() method, and accomplished by setting the index
- Delete columns with multiple values from the DataFrame using the drop() method
- Then use the join() method to merge
df.drop('Country', axis=1).join(df['Country'].str.split('/', expand=True).stack().reset_index(level=1, drop=True).rename('Country'))
Out[3]:
Number Value label Country
0 100 1 a China
1 150 2 b US
2 120 3 c Japan
3 90 4 d EU
4 30 5 e UK
4 30 5 e Australia
5 2 6 f UK
5 2 6 f Netherland
Step-by-step process description
df['Country'].str.split('/', expand=True).stack()
Out[4]:
0 0 China
1 0 US
2 0 Japan
3 0 EU
4 0 UK
1 Australia
5 0 UK
1 Netherland
dtype: object
df['Country'].str.split('/', expand=True).stack().reset_index(level=1, drop=True)
Out[5]:
0 China
1 US
2 Japan
3 EU
4 UK
4 Australia
5 UK
5 Netherland
dtype: object
df['Country'].str.split('/', expand=True).stack().reset_index(level=1, drop=True).rename('Country')
Out[6]:
0 China
1 US
2 Japan
3 EU
4 UK
4 Australia
5 UK
5 Netherland
Name: Country, dtype: object
df.drop('Country', axis=1)
Out[7]:
Number Value label
0 100 1 a
1 150 2 b
2 120 3 c
3 90 4 d
4 30 5 e
5 2 6 f
2 Method-2
The idea of this method is basically the same as Method-1, but there are some differences in the specific details.The code is as follows:
df['Country'].str.split('/', expand=True).stack().reset_index(level=0).set_index('level_0').rename(columns={0:'Country'}).join(df.drop('Country', axis=1))
Out[8]:
Country Number Value label
0 China 100 1 a
1 US 150 2 b
2 Japan 120 3 c
3 EU 90 4 d
4 UK 30 5 e
4 Australia 30 5 e
5 UK 2 6 f
5 Netherland 2 6 f
The process is described step by step as follows:
df['Country'].str.split('/', expand=True).stack().reset_index(level=0)
Out[9]:
level_0 0
0 0 China
0 1 US
0 2 Japan
0 3 EU
0 4 UK
1 4 Australia
0 5 UK
1 5 Netherland
df['Country'].str.split('/', expand=True).stack().reset_index(level=0).set_index('level_0')
Out[10]:
0
level_0
0 China
1 US
2 Japan
3 EU
4 UK
4 Australia
5 UK
5 Netherland
df['Country'].str.split('/', expand=True).stack().reset_index(level=0).set_index('level_0').rename(columns={0:'Country'})
Out[11]:
Country
level_0
0 China
1 US
2 Japan
3 EU
4 UK
4 Australia
5 UK
5 Netherland
df.drop('Country', axis=1)
Out[12]:
Number Value label
0 100 1 a
1 150 2 b
2 120 3 c
3 90 4 d
4 30 5 e
5 2 6 f
3 Chat
Of course, there are other ways to split cells with multiple values in a column into multiple rows, so you can study ~~
Recommended reading for this issue: