In the era of big data, people use the database system to process more and more data, and the requests are more and more complex, which puts forward higher requirements for the big data processing capacity and mixed load capacity of the database system. As the most advanced open source database in the world, PostgreSQL has done a lot of work in big data processing, such as parallelism and partitioning.
PostgreSQL has supported parallelism since 9.6 released in 2016. Before that, PostgreSQL can only use one process to process user requests, can not make full use of resources, and can not well meet the performance requirements under large amount of data and complex queries. PostgreSQL 11 released in October 2018 has done a lot of work in parallel, supporting parallel hash connection, parallel Append and parallel index creation. For partitioned tables, it supports partition wise join.
This article introduces the parallel query feature of PostgreSQL from the following three aspects:
- The basic components of parallel query include Background Work Process, Dynamic Shared Memory, communication mechanism and message passing mechanism between background work processes
- Implementation of parallel execution operators, including parallel sequential scanning, parallel index scanning and other parallel scanning operators, parallel execution of three connection modes and parallel Append
- Parallel query optimization introduces two plan nodes introduced by parallel query, and calculates the number of background work processes and cost estimation based on rules
for instance
First, let's have a macro understanding of PostgreSQL's parallel query and parallel planning through an example. Query as follows: the number of people participating in 2018 PostgreSQL conference in the statistics table: SELECT COUNT(*) FROM people WHERE inpgconn2018 = 'Y';
When there is no parallel (max_parallel_workers_per_gather=0), the query plan is as follows:
Aggregate (cost=169324.73..169324.74 rows=1 width=8) (actual time=983.729..983.730 rows=1 loops=1)
-> Seq Scan on people (cost=0.00..169307.23 rows=7001 width=0) (actual time=981.723..983.051 rows=9999 loops=1)
Filter: (atpgconn2018 = 'Y'::bpchar)
Rows Removed by Filter: 9990001
Planning Time: 0.066 ms
Execution Time: 983.760 ms
When parallelism is enabled (max_parallel_workers_per_gather=2), the query plan is as follows:
Finalize Aggregate (cost=97389.77..97389.78 rows=1 width=8) (actual time=384.848..384.848 rows=1 loops=1)
-> Gather (cost=97389.55..97389.76 rows=2 width=8) (actual time=384.708..386.486 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=96389.55..96389.56 rows=1 width=8) (actual time=379.597..379.597 rows=1 loops=3)
-> Parallel Seq Scan on people (cost=0.00..96382.26 rows=2917 width=0)
(actual time=378.831..379.341 rows=3333 loops=3)
Filter: (atpgconn2018 = 'Y'::bpchar)
Rows Removed by Filter: 3330000
Planning Time: 0.063 ms
Execution Time: 386.532 ms
max_ parallel_ workers_ per_ The gather parameter controls the maximum number of parallel processes at the execution node. It can be seen from the above parallel plan that after parallel is enabled, two worker processes (i.e. Workers Launched: 2) will be started for parallel execution, and the Execution Time is only 40% of that without parallel. The parallel plan can be represented by the following figure:
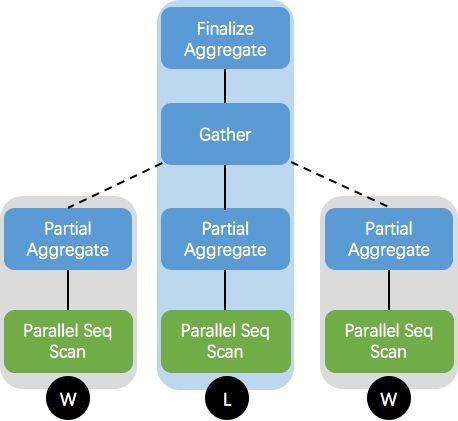
In the parallel query plan, we call the backend process that processes user requests as the master process (leader), and the process dynamically generated during execution as the worker process. Each worker executes a copy of the following plan of the Gather node. The leader node is mainly responsible for handling the operations of the Gather and its above nodes. Depending on the number of workers, the leader may also execute a copy of the following plan of the Gather node.
principle
Parallelization of PostgreSQL includes three important components: the process itself (leader process), gather, and workers. When parallelization is not enabled, the process itself processes all data; Once the planner decides that a query or part of a query can use parallelism, it will add a gather node in the parallelization part of the query and take the gather node as the root node of the sub query tree.
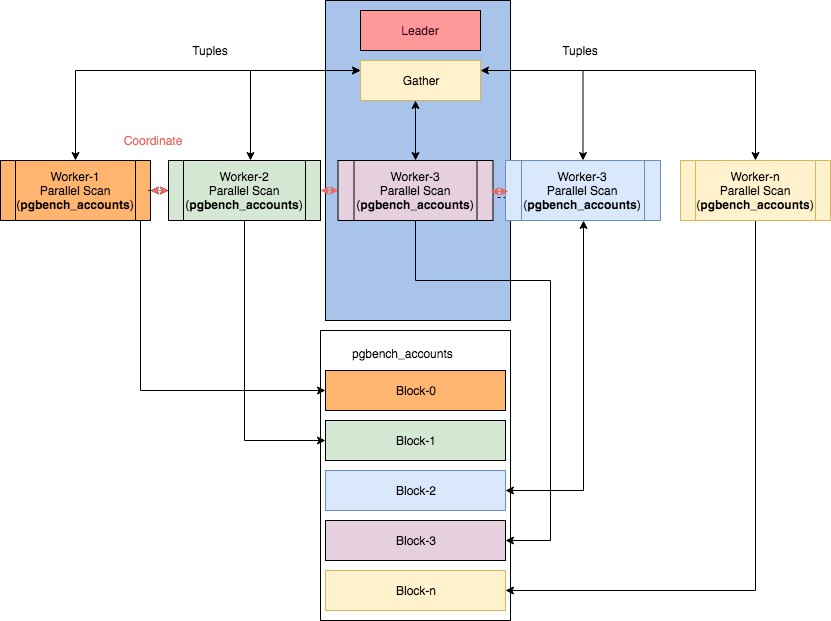
Query execution starts from the leader process. Once parallelism is enabled or partially supported in queries, a gather node and multiple worker threads are allocated. The related blocks are divided among worker threads. The number of workers is controlled by the configuration parameter of postgresql. Workers use shared memory to coordinate and communicate with each other. Once the worker completes his work, the result is passed to the leader process.
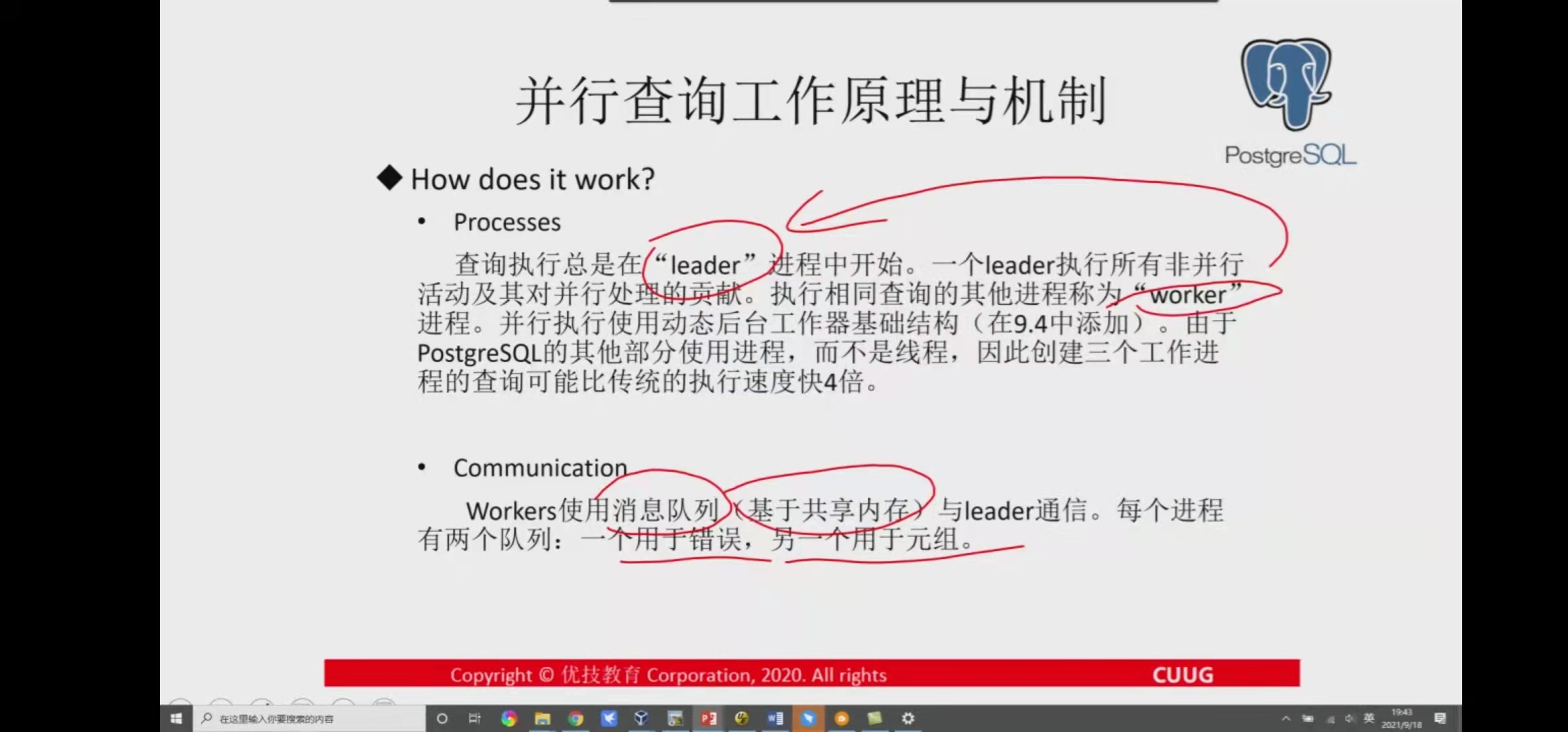
workers and leader processes communicate using message queues (which rely on shared memory). Each process has two queues: one is the error queue; One is the tuples queue.
Background Worker Process
PostgreSQL is a multi process architecture, which mainly includes the following types of processes:
- The daemon, commonly known as the postmaster process, receives the user's connection and fork s a child process to process the user's request
- The backend process is the process created by postmaster to process user requests. Each connection corresponds to a backend process
- Auxiliary process, which is used to perform checkpoint, background cleaning and other operations
- Background worker process, which is used to execute specific tasks and start dynamically, such as the worker process mentioned above
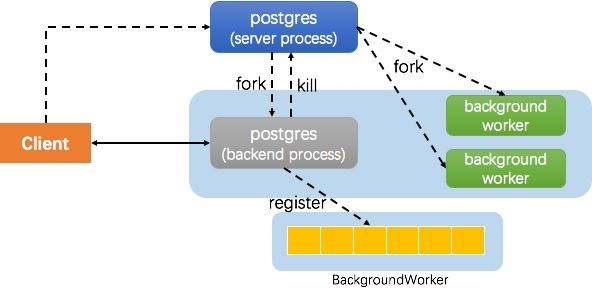
In the figure above, the server process is the postmaster process. In the kernel, both postmaster and backend processes are postgres processes, but their roles are different. For a parallel query, the general process of creating a worker process is as follows: - The client creates a connection, and the postmaster fork s a backend process for it to process the request
- backend receives user requests and generates parallel query plans
- The executor registers the worker process with the background worker (it is not started)
- The executor notifies (kill) the postmaster to start the worker process
- The worker process executes in coordination with the leader process and returns the result to the client
src/backend/access/transam/README.parallel
PG provides some simple facilities for writing parallel algorithms more easily. Using the ParallelContext data structure, you can arrange to start background worker processes, initialize their states, and run complex code that can run on the user's back end or parallel workers through dynamic shared memory communication.
/* List of active parallel contexts. */
static dlist_head pcxt_list = DLIST_STATIC_INIT(pcxt_list);
typedef struct ParallelContext {
dlist_node node;
SubTransactionId subid; // Call GetCurrentSubTransactionId to get the sub transaction ID
int nworkers; // Number of worker s
int nworkers_launched;
char *library_name; // Library name
char *function_name;// Function name
ErrorContextCallback *error_context_stack; //Error context stack
shm_toc_estimator estimator;
dsm_segment *seg;
void *private_memory;
shm_toc *toc;
ParallelWorkerInfo *worker;
int nknown_attached_workers;
bool *known_attached_workers;
} ParallelContext;
Parallel context linked list pcxt_list, which is used to store the parallel context of the activity. The node in the ParallelContext structure is used to insert into the parallel context linked list pcxt_list.
Implementation routine: invoke EnterParallelMode before entering parallel operation, and then call ExitParallelMode after parallel operation is completed. ParallelContext is used to parallelize the corresponding operations. Ideally, after the waitforparallelworkerstofish call, the ParallelContext can be reset so that the worker can start with the same parallel context. In order to achieve this effect, you need to call ReinitializeParallelDSM to reinitialize the state managed by the parallel context state machine, then perform necessary reset operations, and finally call LaunchParallelWorkers again.
EnterParallelMode(); /* prohibit unsafe state changes */ // Increment the parallelModeLevel in the current transaction state structure
pcxt = CreateParallelContext("library_name", "function_name", nworkers);
/* Allow space for application-specific data here. */
shm_toc_estimate_chunk(&pcxt->estimator, size);
shm_toc_estimate_keys(&pcxt->estimator, keys);
InitializeParallelDSM(pcxt); /* create DSM and copy state to it */
/* Store the data for which we reserved space. */
space = shm_toc_allocate(pcxt->toc, size);
shm_toc_insert(pcxt->toc, key, space);
LaunchParallelWorkers(pcxt);
/* do parallel stuff */
WaitForParallelWorkersToFinish(pcxt);
/* read any final results from dynamic shared memory */
DestroyParallelContext(pcxt);
ExitParallelMode();
CreateParallelContext
The IsInParallelMode function determines whether it is in parallel mode
bool IsInParallelMode(void) {
return CurrentTransactionState->parallelModeLevel != 0;
}
The CreateParallelContext function creates a new parallel context, enters the parallel mode, and calls the function. The parallel context needs to be released before exiting the current sub transaction.
ParallelContext *CreateParallelContext(const char *library_name, const char *function_name, int nworkers) {
MemoryContext oldcontext;
ParallelContext *pcxt;
/* It is unsafe to create a parallel context if not in parallel mode. */
Assert(IsInParallelMode());
/* Number of workers should be non-negative. */
Assert(nworkers >= 0);
/* We might be running in a short-lived memory context. */
oldcontext = MemoryContextSwitchTo(TopTransactionContext);
/* Initialize a new ParallelContext. */
pcxt = palloc0(sizeof(ParallelContext));
pcxt->subid = GetCurrentSubTransactionId(); //Call GetCurrentSubTransactionId to get the sub transaction ID
pcxt->nworkers = nworkers;
pcxt->library_name = pstrdup(library_name);
pcxt->function_name = pstrdup(function_name);
pcxt->error_context_stack = error_context_stack; //Error context stack
shm_toc_initialize_estimator(&pcxt->estimator); //Allow space for application-specific data
dlist_push_head(&pcxt_list, &pcxt->node);
/* Restore previous memory context. */
MemoryContextSwitchTo(oldcontext);
return pcxt;
}
PCXT - > subID = GetCurrentSubTransactionId() call GetCurrentSubTransactionId() to get the sub transaction ID. the parallel context needs to be released before exiting the current sub transaction.
Search the source code of PG12.6. There are two places where the CreateParallelContext function is called: 1. nbsort.c_ bt_begin_parallel function2. ExecInitParallelPlan function of execparallel. C. Let's take the ExecInitParallelPlan function as an example to see its call chain.
ExecGather (nodeGather.c) --> ExecInitParallelPlan
ExecGatherMerge (nodeGatherMerge.c) --> ExecInitParallelPlan
ExecGather
ExecGather scans the relationship table through multiple worker s and returns the next tuple:
- During the first execution, the parallel context and worker process are initialized. Because a large amount of dynamic shared memory needs to be allocated, lazy loading is an effective strategy to alleviate the resource shortage.
- Share status required to initialize or reinitialize worker node - > Pei
- LaunchParallelWorkers(pcxt)
- Create tuples message queue to read tuples execparallelcreatereaders (node - > PEI)
- Whether the tuple gather is obtained from the worker or the process itself_ getnext(node)
static TupleTableSlot *ExecGather(PlanState *pstate) {
GatherState *node = castNode(GatherState, pstate);
TupleTableSlot *slot;
ExprContext *econtext;
CHECK_FOR_INTERRUPTS();
/* Initialize the parallel context and workers on first execution. We do this on first execution rather than during node initialization, as it needs to allocate a large dynamic segment, so it is better to do it only if it is really needed. */
if (!node->initialized) {
EState *estate = node->ps.state;
Gather *gather = (Gather *) node->ps.plan;
/* Sometimes we might have to run without parallelism; but if parallel mode is active then we can try to fire up some workers. */
if (gather->num_workers > 0 && estate->es_use_parallel_mode) {
ParallelContext *pcxt;
/* Initialize, or re-initialize, shared state needed by workers. */
if (!node->pei)
node->pei = ExecInitParallelPlan(node->ps.lefttree,estate,gather->initParam,gather->num_workers,node->tuples_needed);
else
ExecParallelReinitialize(node->ps.lefttree,node->pei,gather->initParam);
/* Register backend workers. We might not get as many as we requested, or indeed any at all. */
pcxt = node->pei->pcxt;
LaunchParallelWorkers(pcxt);
/* We save # workers launched for the benefit of EXPLAIN */
node->nworkers_launched = pcxt->nworkers_launched;
/* Set up tuple queue readers to read the results. */
if (pcxt->nworkers_launched > 0) {
ExecParallelCreateReaders(node->pei);
/* Make a working array showing the active readers */
node->nreaders = pcxt->nworkers_launched;
node->reader = (TupleQueueReader **)palloc(node->nreaders * sizeof(TupleQueueReader *));
memcpy(node->reader, node->pei->reader,node->nreaders * sizeof(TupleQueueReader *));
}else{
/* No workers? Then never mind. */
node->nreaders = 0;
node->reader = NULL;
}
node->nextreader = 0;
}
/* Run plan locally if no workers or enabled and not single-copy. */
node->need_to_scan_locally = (node->nreaders == 0) || (!gather->single_copy && parallel_leader_participation);
node->initialized = true;
}
/* Reset per-tuple memory context to free any expression evaluation storage allocated in the previous tuple cycle. */
econtext = node->ps.ps_ExprContext;
ResetExprContext(econtext);
/* Get next tuple, either from one of our workers, or by running the plan ourselves. */
slot = gather_getnext(node);
if (TupIsNull(slot))
return NULL;
/* If no projection is required, we're done. */
if (node->ps.ps_ProjInfo == NULL)
return slot;
/* Form the result tuple using ExecProject(), and return it. */
econtext->ecxt_outertuple = slot;
return ExecProject(node->ps.ps_ProjInfo);
}
ExecGatherMerge
Dynamic Shared Memory and IPC
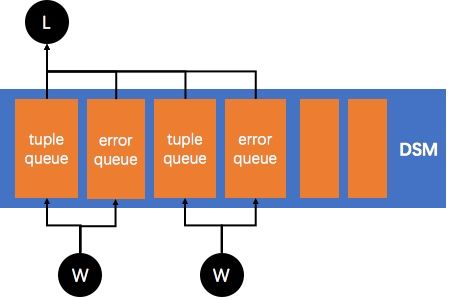
PostgreSQL is a multi process architecture. Inter process communication is often realized by sharing memory and semaphores. For parallel query, the worker process and leader process created during execution also realize data interaction through shared memory. However, this part of memory cannot be pre allocated at system startup like ordinary shared memory. After all, it is not known how many worker processes there are and how much memory needs to be allocated until it is actually executed. PostgreSQL implements dynamic shared memory, that is, it is created dynamically during execution, used for communication between leaders and workers, and released after execution. Dynamic shared memory based queues are used to pass tuples and error messages between processes.
As shown in the following figure, each worker has a corresponding tuple queue and error queue in the dynamic shared memory. The worker puts the execution results into the queue, and the leader will obtain tuples from the corresponding queue and return them to the upper operator. The specific implementation principles and details of dynamic shared memory are not expanded here.
InitializeParallelDSM
The initializepalleldsm function is used to create dynamic shared memory, copy status, and other information required by bookkeeping worker s.
void InitializeParallelDSM(ParallelContext *pcxt) {
MemoryContext oldcontext;
Size library_len = 0;
Size guc_len = 0;
Size combocidlen = 0;
Size tsnaplen = 0;
Size asnaplen = 0;
Size tstatelen = 0;
Size reindexlen = 0;
Size relmapperlen = 0;
Size enumblacklistlen = 0;
Size segsize = 0;
int i;
FixedParallelState *fps;
dsm_handle session_dsm_handle = DSM_HANDLE_INVALID;
Snapshot transaction_snapshot = GetTransactionSnapshot();
Snapshot active_snapshot = GetActiveSnapshot();
/* We might be running in a very short-lived memory context. */
oldcontext = MemoryContextSwitchTo(TopTransactionContext);
/* Allow space to store the fixed-size parallel state. */
shm_toc_estimate_chunk(&pcxt->estimator, sizeof(FixedParallelState));
shm_toc_estimate_keys(&pcxt->estimator, 1);
/* Normally, the user will have requested at least one worker process, but if by chance they have not, we can skip a bunch of things here. */
if (pcxt->nworkers > 0) {
/* Get (or create) the per-session DSM segment's handle. */
session_dsm_handle = GetSessionDsmHandle();
/* If we weren't able to create a per-session DSM segment, then we can
* continue but we can't safely launch any workers because their
* record typmods would be incompatible so they couldn't exchange
* tuples. */
if (session_dsm_handle == DSM_HANDLE_INVALID)
pcxt->nworkers = 0;
}
if (pcxt->nworkers > 0) {
/* Estimate space for various kinds of state sharing. */
library_len = EstimateLibraryStateSpace();
shm_toc_estimate_chunk(&pcxt->estimator, library_len);
guc_len = EstimateGUCStateSpace();
shm_toc_estimate_chunk(&pcxt->estimator, guc_len);
combocidlen = EstimateComboCIDStateSpace();
shm_toc_estimate_chunk(&pcxt->estimator, combocidlen);
tsnaplen = EstimateSnapshotSpace(transaction_snapshot);
shm_toc_estimate_chunk(&pcxt->estimator, tsnaplen);
asnaplen = EstimateSnapshotSpace(active_snapshot);
shm_toc_estimate_chunk(&pcxt->estimator, asnaplen);
tstatelen = EstimateTransactionStateSpace();
shm_toc_estimate_chunk(&pcxt->estimator, tstatelen);
shm_toc_estimate_chunk(&pcxt->estimator, sizeof(dsm_handle));
reindexlen = EstimateReindexStateSpace();
shm_toc_estimate_chunk(&pcxt->estimator, reindexlen);
relmapperlen = EstimateRelationMapSpace();
shm_toc_estimate_chunk(&pcxt->estimator, relmapperlen);
enumblacklistlen = EstimateEnumBlacklistSpace();
shm_toc_estimate_chunk(&pcxt->estimator, enumblacklistlen);
/* If you add more chunks here, you probably need to add keys. */
shm_toc_estimate_keys(&pcxt->estimator, 10);
/* Estimate space need for error queues. */
StaticAssertStmt(BUFFERALIGN(PARALLEL_ERROR_QUEUE_SIZE) == PARALLEL_ERROR_QUEUE_SIZE, "parallel error queue size not buffer-aligned");
shm_toc_estimate_chunk(&pcxt->estimator, mul_size(PARALLEL_ERROR_QUEUE_SIZE, pcxt->nworkers));
shm_toc_estimate_keys(&pcxt->estimator, 1);
/* Estimate how much we'll need for the entrypoint info. */
shm_toc_estimate_chunk(&pcxt->estimator, strlen(pcxt->library_name) + strlen(pcxt->function_name) + 2);
shm_toc_estimate_keys(&pcxt->estimator, 1);
}
/* Create DSM and initialize with new table of contents. But if the user
* didn't request any workers, then don't bother creating a dynamic shared
* memory segment; instead, just use backend-private memory.
* Also, if we can't create a dynamic shared memory segment because the
* maximum number of segments have already been created, then fall back to
* backend-private memory, and plan not to use any workers. We hope this
* won't happen very often, but it's better to abandon the use of
* parallelism than to fail outright.
*/
segsize = shm_toc_estimate(&pcxt->estimator);
if (pcxt->nworkers > 0)
pcxt->seg = dsm_create(segsize, DSM_CREATE_NULL_IF_MAXSEGMENTS);
if (pcxt->seg != NULL)
pcxt->toc = shm_toc_create(PARALLEL_MAGIC, dsm_segment_address(pcxt->seg), segsize);
else {
pcxt->nworkers = 0;
pcxt->private_memory = MemoryContextAlloc(TopMemoryContext, segsize);
pcxt->toc = shm_toc_create(PARALLEL_MAGIC, pcxt->private_memory, segsize);
}
/* Initialize fixed-size state in shared memory. */
fps = (FixedParallelState *)shm_toc_allocate(pcxt->toc, sizeof(FixedParallelState));
fps->database_id = MyDatabaseId;
fps->authenticated_user_id = GetAuthenticatedUserId();
fps->outer_user_id = GetCurrentRoleId();
fps->is_superuser = session_auth_is_superuser;
GetUserIdAndSecContext(&fps->current_user_id, &fps->sec_context);
GetTempNamespaceState(&fps->temp_namespace_id,&fps->temp_toast_namespace_id);
fps->parallel_master_pgproc = MyProc;
fps->parallel_master_pid = MyProcPid;
fps->parallel_master_backend_id = MyBackendId;
fps->xact_ts = GetCurrentTransactionStartTimestamp();
fps->stmt_ts = GetCurrentStatementStartTimestamp();
fps->serializable_xact_handle = ShareSerializableXact();
SpinLockInit(&fps->mutex);
fps->last_xlog_end = 0;
shm_toc_insert(pcxt->toc, PARALLEL_KEY_FIXED, fps);
/* We can skip the rest of this if we're not budgeting for any workers. */
if (pcxt->nworkers > 0){
char *libraryspace;
char *gucspace;
char *combocidspace;
char *tsnapspace;
char *asnapspace;
char *tstatespace;
char *reindexspace;
char *relmapperspace;
char *error_queue_space;
char *session_dsm_handle_space;
char *entrypointstate;
char *enumblacklistspace;
Size lnamelen;
/* Serialize shared libraries we have loaded. */
libraryspace = shm_toc_allocate(pcxt->toc, library_len);
SerializeLibraryState(library_len, libraryspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_LIBRARY, libraryspace);
/* Serialize GUC settings. */
gucspace = shm_toc_allocate(pcxt->toc, guc_len);
SerializeGUCState(guc_len, gucspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_GUC, gucspace);
/* Serialize combo CID state. */
combocidspace = shm_toc_allocate(pcxt->toc, combocidlen);
SerializeComboCIDState(combocidlen, combocidspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_COMBO_CID, combocidspace);
/* Serialize transaction snapshot and active snapshot. */
tsnapspace = shm_toc_allocate(pcxt->toc, tsnaplen);
SerializeSnapshot(transaction_snapshot, tsnapspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_TRANSACTION_SNAPSHOT, tsnapspace);
asnapspace = shm_toc_allocate(pcxt->toc, asnaplen);
SerializeSnapshot(active_snapshot, asnapspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_ACTIVE_SNAPSHOT, asnapspace);
/* Provide the handle for per-session segment. */
session_dsm_handle_space = shm_toc_allocate(pcxt->toc,sizeof(dsm_handle));
*(dsm_handle *) session_dsm_handle_space = session_dsm_handle;
shm_toc_insert(pcxt->toc, PARALLEL_KEY_SESSION_DSM,session_dsm_handle_space);
/* Serialize transaction state. */
tstatespace = shm_toc_allocate(pcxt->toc, tstatelen);
SerializeTransactionState(tstatelen, tstatespace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_TRANSACTION_STATE, tstatespace);
/* Serialize reindex state. */
reindexspace = shm_toc_allocate(pcxt->toc, reindexlen);
SerializeReindexState(reindexlen, reindexspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_REINDEX_STATE, reindexspace);
/* Serialize relmapper state. */
relmapperspace = shm_toc_allocate(pcxt->toc, relmapperlen);
SerializeRelationMap(relmapperlen, relmapperspace);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_RELMAPPER_STATE,relmapperspace);
/* Serialize enum blacklist state. */
enumblacklistspace = shm_toc_allocate(pcxt->toc, enumblacklistlen);
SerializeEnumBlacklist(enumblacklistspace, enumblacklistlen);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_ENUMBLACKLIST,enumblacklistspace);
/* Allocate space for worker information. */
pcxt->worker = palloc0(sizeof(ParallelWorkerInfo) * pcxt->nworkers);
/* Establish error queues in dynamic shared memory.
* These queues should be used only for transmitting ErrorResponse,
* NoticeResponse, and NotifyResponse protocol messages. Tuple data
* should be transmitted via separate (possibly larger?) queues. */
error_queue_space =shm_toc_allocate(pcxt->toc,mul_size(PARALLEL_ERROR_QUEUE_SIZE,pcxt->nworkers));
for (i = 0; i < pcxt->nworkers; ++i){
char *start;
shm_mq *mq;
start = error_queue_space + i * PARALLEL_ERROR_QUEUE_SIZE;
mq = shm_mq_create(start, PARALLEL_ERROR_QUEUE_SIZE);
shm_mq_set_receiver(mq, MyProc);
pcxt->worker[i].error_mqh = shm_mq_attach(mq, pcxt->seg, NULL);
}
shm_toc_insert(pcxt->toc, PARALLEL_KEY_ERROR_QUEUE, error_queue_space);
/* Serialize entrypoint information. It's unsafe to pass function
* pointers across processes, as the function pointer may be different
* in each process in EXEC_BACKEND builds, so we always pass library
* and function name. (We use library name "postgres" for functions
* in the core backend.) */
lnamelen = strlen(pcxt->library_name);
entrypointstate = shm_toc_allocate(pcxt->toc, lnamelen + strlen(pcxt->function_name) + 2);
strcpy(entrypointstate, pcxt->library_name);
strcpy(entrypointstate + lnamelen + 1, pcxt->function_name);
shm_toc_insert(pcxt->toc, PARALLEL_KEY_ENTRYPOINT, entrypointstate);
}
/* Restore previous memory context. */
MemoryContextSwitchTo(oldcontext);
}
LaunchParallelWorkers
src/backend/access/transam/parallel.c Infrastructure for launching parallel workers
src/backend/executor/execParallel.c Support routines for parallel execution
Parallel support operator
The above briefly introduces two important basic components of parallel query dependency: background worker process and dynamic shared memory. The former is used to dynamically create workers to execute sub query plans in parallel; The latter is used for communication and data interaction between leader and worker. This section describes the implementation principles of operators currently supported by PostgreSQL for parallel execution, including:
Parallel scanning, such as parallel sequential scanning, parallel index scanning, etc
Parallel connection, such as parallel hash connection, parallel NestLoop connection, etc
Parallel Append
Parallel sequential scan
In PostgreSQL 9.6, support for parallel sequential scanning has been added. A sequential scan is a scan performed on a table in which blocks are evaluated sequentially one after another. In essence, sequential scanning allows parallelization. In this way, the entire table will be scanned sequentially between multiple worker threads.
Parallel sequential scanning is fast not because it can be read in parallel, but because it distributes the data to multiple CPUs.
abce=# explain analyze select work_hour from hh_adds_static_day where create_time <= date '20201010'-interval '10' day;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Seq Scan on hh_adds_static_day (cost=0.00..261864.36 rows=4241981 width=4) (actual time=0.012..1407.214 rows=4228109 loops=1)
Filter: (create_time <= '2020-09-30 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 735600
Planning Time: 0.108 ms
Execution Time: 1585.835 ms
(5 rows)
Sequential scanning produces a large number of rows, but aggregation functions are not used. Therefore, the query uses a single cpu core.
After adding a sum function, it is obvious that two working threads are used to speed up the query:
abce=# explain analyze select sum(work_hour) from hh_adds_static_day where create_time <= date '20201010'-interval '10' day;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=231089.60..231089.61 rows=1 width=4) (actual time=749.998..751.529 rows=1 loops=1)
-> Gather (cost=231089.38..231089.59 rows=2 width=4) (actual time=749.867..751.515 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=230089.38..230089.39 rows=1 width=4) (actual time=746.463..746.464 rows=1 loops=3)
-> Parallel Seq Scan on hh_adds_static_day (cost=0.00..225670.65 rows=1767492 width=4) (actual time=0.032..489.501 rows=1409370 loops=3)
Filter: (create_time <= '2020-09-30 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 245200
Planning Time: 0.112 ms
Execution Time: 751.611 ms
(10 rows)
Parallel aggregation
Computing aggregation is a very expensive operation in a database. If executed as a single process, this will take quite a long time. In PostgreSQL 9.6, the ability of parallel computing is increased by simply dividing them into multiple blocks (divide and conquer strategy). Multiple worker threads execute the aggregated part, and then the leader calculates the final result based on their results.
Technically, the Partial Aggregate node is added to the plan tree, and each Partial Aggregate node contains the output of a worker thread. These outputs are then sent to the Finalize Aggregate node, which merges aggregations from multiple (all) Partial Aggregate nodes. Such an effective parallel part plan includes a Finalize Aggregate node at the root and a Gather node with a Partial Aggregate node as a child node.
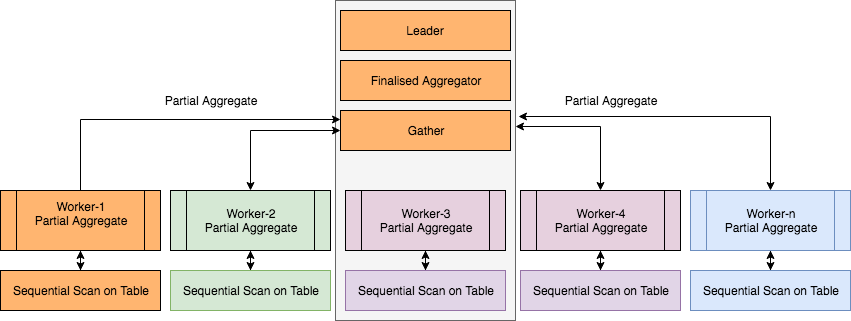
The 'Parallel Seq Scan' node generates rows for partial aggregation ('Partial Aggregate ').
The 'Partial Aggregate' node uses the SUM() function to reduce these rows. Finally, the 'Gather' node collects the total count of each worker.
The 'Finalize Aggregate' node calculates the final sum. If you use your own aggregate function, don't forget to mark it as' parallel safe '.
Number of worker s
You can dynamically adjust the number of worker s:
abce=# show max_parallel_workers_per_gather;
max_parallel_workers_per_gather
---------------------------------
2
(1 row)
abce=# alter system set max_parallel_workers_per_gather=4;
ALTER SYSTEM
abce=# select * from pg_reload_conf();
pg_reload_conf
----------------
t
(1 row)
abce=# explain analyze select sum(work_hour) from hh_adds_static_day where create_time <= date '20201010'-interval '10' day;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=218981.25..218981.26 rows=1 width=4) (actual time=473.424..475.156 rows=1 loops=1)
-> Gather (cost=218980.83..218981.24 rows=4 width=4) (actual time=473.314..475.144 rows=5 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial Aggregate (cost=217980.83..217980.84 rows=1 width=4) (actual time=468.769..468.770 rows=1 loops=5)
-> Parallel Seq Scan on hh_adds_static_day (cost=0.00..215329.59 rows=1060495 width=4) (actual time=0.036..306.854 rows=845622 loops=5)
Filter: (create_time <= '2020-09-30 00:00:00'::timestamp without time zone)
Rows Removed by Filter: 147120
Planning Time: 0.150 ms
Execution Time: 475.218 ms
(10 rows)
We changed the number from 2 to 4.
How many worker processes are used
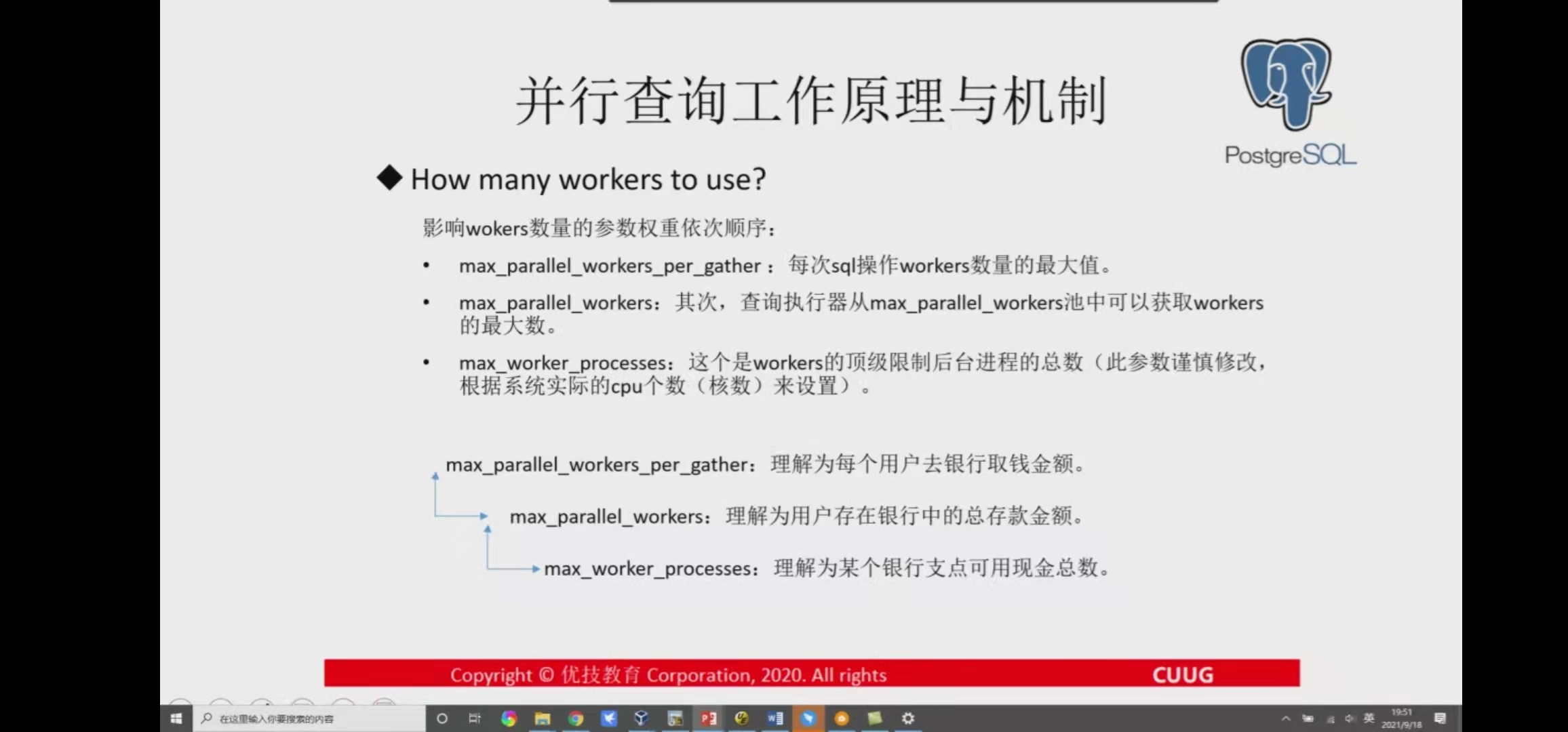
First, max_ parallel_ workers_ per_ The gather parameter defines the minimum number of workers.
Secondly, the number of workers obtained by the query executor from the pool is limited by max_ parallel_ The value of workers.
Finally, the top limit is max_worker_processes, which defines the total number of background worker processes.
If the allocation of worker process fails, it will switch to single process execution.
The query planner will consider reducing the number of worker processes according to the size of the table or index. Affected parameter min_parallel_table_scan_size,min_parallel_index_scan_size impact.
Default settings for parameters:
abce=# show min_parallel_table_scan_size; min_parallel_table_scan_size ------------------------------ 8MB (1 row) abce=# show min_parallel_index_scan_size ; min_parallel_index_scan_size ------------------------------ 512kB (1 row)
Influence relationship:
set min_parallel_table_scan_size='8MB' 8MB table => 1 worker 24MB table => 2 workers 72MB table => 3 workers x => log(x / min_parallel_table_scan_size) / log(3) + 1 worker
Whenever the size of the table is min_ parallel(index|table)scan_ Three times the size, postgresql will add a worker process. The number of worker processes is not cost based.
In practice, these rules are not always followed. You can set the alter table... set (parallel_workers=N) for a specific table.
Why is parallel execution not used?
In addition to some limitations of parallel execution, postgresql also checks the cost:
·parallel_setup_cost avoids parallel execution of small queries. It models the time used for memory setup, process startup, and initial communication
·parallel_tuple_cost: the communication between the leader process and the worker process takes a long time. The time is proportional to the number of tuples sent by the worker. This parameter models the communication cost.
Nested loop joins
Since version 9.6, postgresql supports parallel operations on "Nested loop":
explain (costs off) select c_custkey, count(o_orderkey)
from customer left outer join orders on
c_custkey = o_custkey and o_comment not like '%special%deposits%'
group by c_custkey;
QUERY PLAN
--------------------------------------------------------------------------------------
Finalize GroupAggregate
Group Key: customer.c_custkey
-> Gather Merge
Workers Planned: 4
-> Partial GroupAggregate
Group Key: customer.c_custkey
-> Nested Loop Left Join
-> Parallel Index Only Scan using customer_pkey on customer
-> Index Scan using idx_orders_custkey on orders
Index Cond: (customer.c_custkey = o_custkey)
Filter: ((o_comment)::text !~~ '%special%deposits%'::text)
gather occurs in the final stage, so "Nested Loop Left Join" is a parallel operation. Parallel Index Only Scan is available from version 10. Its behavior is similar to parallel sequential scanning. Condition c_custkey = o_custkey reads an order for each customer line. Therefore, it is not parallel.
Hash join
Before PostgreSQL 11, each worker built its own hash table. Therefore, more than four workers processes cannot improve performance. The new implementation uses a shared hash table. Each worker can use WORK_MEM to build a hash table.
select
l_shipmode,
sum(case
when o_orderpriority = '1-URGENT'
or o_orderpriority = '2-HIGH'
then 1
else 0
end) as high_line_count,
sum(case
when o_orderpriority <> '1-URGENT'
and o_orderpriority <> '2-HIGH'
then 1
else 0
end) as low_line_count
from
orders,
lineitem
where
o_orderkey = l_orderkey
and l_shipmode in ('MAIL', 'AIR')
and l_commitdate < l_receiptdate
and l_shipdate < l_commitdate
and l_receiptdate >= date '1996-01-01'
and l_receiptdate < date '1996-01-01' + interval '1' year
group by
l_shipmode
order by
l_shipmode
LIMIT 1;
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1964755.66..1964961.44 rows=1 width=27) (actual time=7579.592..7922.997 rows=1 loops=1)
-> Finalize GroupAggregate (cost=1964755.66..1966196.11 rows=7 width=27) (actual time=7579.590..7579.591 rows=1 loops=1)
Group Key: lineitem.l_shipmode
-> Gather Merge (cost=1964755.66..1966195.83 rows=28 width=27) (actual time=7559.593..7922.319 rows=6 loops=1)
Workers Planned: 4
Workers Launched: 4
-> Partial GroupAggregate (cost=1963755.61..1965192.44 rows=7 width=27) (actual time=7548.103..7564.592 rows=2 loops=5)
Group Key: lineitem.l_shipmode
-> Sort (cost=1963755.61..1963935.20 rows=71838 width=27) (actual time=7530.280..7539.688 rows=62519 loops=5)
Sort Key: lineitem.l_shipmode
Sort Method: external merge Disk: 2304kB
Worker 0: Sort Method: external merge Disk: 2064kB
Worker 1: Sort Method: external merge Disk: 2384kB
Worker 2: Sort Method: external merge Disk: 2264kB
Worker 3: Sort Method: external merge Disk: 2336kB
-> Parallel Hash Join (cost=382571.01..1957960.99 rows=71838 width=27) (actual time=7036.917..7499.692 rows=62519 loops=5)
Hash Cond: (lineitem.l_orderkey = orders.o_orderkey)
-> Parallel Seq Scan on lineitem (cost=0.00..1552386.40 rows=71838 width=19) (actual time=0.583..4901.063 rows=62519 loops=5)
Filter: ((l_shipmode = ANY ('{MAIL,AIR}'::bpchar[])) AND (l_commitdate < l_receiptdate) AND (l_shipdate < l_commitdate) AND (l_receiptdate >= '1996-01-01'::date) AND (l_receiptdate < '1997-01-01 00:00:00'::timestamp without time zone))
Rows Removed by Filter: 11934691
-> Parallel Hash (cost=313722.45..313722.45 rows=3750045 width=20) (actual time=2011.518..2011.518 rows=3000000 loops=5)
Buckets: 65536 Batches: 256 Memory Usage: 3840kB
-> Parallel Seq Scan on orders (cost=0.00..313722.45 rows=3750045 width=20) (actual time=0.029..995.948 rows=3000000 loops=5)
Planning Time: 0.977 ms
Execution Time: 7923.770 ms
Here, each worker helps build a shared hash table.
Merge join
Due to the characteristics of merge join, it does not support parallel query. If merge join is the last stage of query execution - you can still see parallel execution.
-- Query 2 from TPC-H
explain (costs off) select s_acctbal, s_name, n_name, p_partkey, p_mfgr, s_address, s_phone, s_comment
from part, supplier, partsupp, nation, region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and p_size = 36
and p_type like '%BRASS'
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AMERICA'
and ps_supplycost = (
select
min(ps_supplycost)
from partsupp, supplier, nation, region
where
p_partkey = ps_partkey
and s_suppkey = ps_suppkey
and s_nationkey = n_nationkey
and n_regionkey = r_regionkey
and r_name = 'AMERICA'
)
order by s_acctbal desc, n_name, s_name, p_partkey
LIMIT 100;
QUERY PLAN
----------------------------------------------------------------------------------------------------------
Limit
-> Sort
Sort Key: supplier.s_acctbal DESC, nation.n_name, supplier.s_name, part.p_partkey
-> Merge Join
Merge Cond: (part.p_partkey = partsupp.ps_partkey)
Join Filter: (partsupp.ps_supplycost = (SubPlan 1))
-> Gather Merge
Workers Planned: 4
-> Parallel Index Scan using <strong>part_pkey</strong> on part
Filter: (((p_type)::text ~~ '%BRASS'::text) AND (p_size = 36))
-> Materialize
-> Sort
Sort Key: partsupp.ps_partkey
-> Nested Loop
-> Nested Loop
Join Filter: (nation.n_regionkey = region.r_regionkey)
-> Seq Scan on region
Filter: (r_name = 'AMERICA'::bpchar)
-> Hash Join
Hash Cond: (supplier.s_nationkey = nation.n_nationkey)
-> Seq Scan on supplier
-> Hash
-> Seq Scan on nation
-> Index Scan using idx_partsupp_suppkey on partsupp
Index Cond: (ps_suppkey = supplier.s_suppkey)
SubPlan 1
-> Aggregate
-> Nested Loop
Join Filter: (nation_1.n_regionkey = region_1.r_regionkey)
-> Seq Scan on region region_1
Filter: (r_name = 'AMERICA'::bpchar)
-> Nested Loop
-> Nested Loop
-> Index Scan using idx_partsupp_partkey on partsupp partsupp_1
Index Cond: (part.p_partkey = ps_partkey)
-> Index Scan using supplier_pkey on supplier supplier_1
Index Cond: (s_suppkey = partsupp_1.ps_suppkey)
-> Index Scan using nation_pkey on nation nation_1
Index Cond: (n_nationkey = supplier_1.s_nationkey)
The Merge Join node is above the Gather Merge. Therefore, merging does not use parallel execution. However, the Parallel Index Scan node still helps with part_pkey.
Partition wise join
PostgreSQL 11 disables the partition wise join function by default. The planning cost of zoning smart connectivity is high. Tables with similar partitions can be joined on a partition by partition basis. This allows postgres to use a smaller hash table. Each partition join operation can be performed in parallel.
tpch=# set enable_partitionwise_join=t;
tpch=# explain (costs off) select * from prt1 t1, prt2 t2
where t1.a = t2.b and t1.b = 0 and t2.b between 0 and 10000;
QUERY PLAN
---------------------------------------------------
Append
-> Hash Join
Hash Cond: (t2.b = t1.a)
-> Seq Scan on prt2_p1 t2
Filter: ((b >= 0) AND (b <= 10000))
-> Hash
-> Seq Scan on prt1_p1 t1
Filter: (b = 0)
-> Hash Join
Hash Cond: (t2_1.b = t1_1.a)
-> Seq Scan on prt2_p2 t2_1
Filter: ((b >= 0) AND (b <= 10000))
-> Hash
-> Seq Scan on prt1_p2 t1_1
Filter: (b = 0)
tpch=# set parallel_setup_cost = 1;
tpch=# set parallel_tuple_cost = 0.01;
tpch=# explain (costs off) select * from prt1 t1, prt2 t2
where t1.a = t2.b and t1.b = 0 and t2.b between 0 and 10000;
QUERY PLAN
-----------------------------------------------------------
Gather
Workers Planned: 4
-> Parallel Append
-> Parallel Hash Join
Hash Cond: (t2_1.b = t1_1.a)
-> Parallel Seq Scan on prt2_p2 t2_1
Filter: ((b >= 0) AND (b <= 10000))
-> Parallel Hash
-> Parallel Seq Scan on prt1_p2 t1_1
Filter: (b = 0)
-> Parallel Hash Join
Hash Cond: (t2.b = t1.a)
-> Parallel Seq Scan on prt2_p1 t2
Filter: ((b >= 0) AND (b <= 10000))
-> Parallel Hash
-> Parallel Seq Scan on prt1_p1 t1
Filter: (b = 0)
Most importantly, partition smart joins can use parallel execution only if the partition is large enough.
Parallel append
You can usually see this in a UNION ALL query. The disadvantage is poor parallelism, because each work eventually works for a single query.
Even if four worker s are enabled, only two are started.
tpch=# explain (costs off) select sum(l_quantity) as sum_qty from lineitem where l_shipdate <= date '1998-12-01' - interval '105' day union all select sum(l_quantity) as sum_qty from lineitem where l_shipdate <= date '2000-12-01' - interval '105' day;
QUERY PLAN
------------------------------------------------------------------------------------------------
Gather
Workers Planned: 2
-> Parallel Append
-> Aggregate
-> Seq Scan on lineitem
Filter: (l_shipdate <= '2000-08-18 00:00:00'::timestamp without time zone)
-> Aggregate
-> Seq Scan on lineitem lineitem_1
Filter: (l_shipdate <= '1998-08-18 00:00:00'::timestamp without time zone)
Important variables
·work_mem
·max_parallel_workers_per_gather: the number of workers allocated by the executor for each plan node executed in parallel
·max_worker_processes
·max_parallel_workers
In version 9.6, parallel query execution is introduced;
In version 10, parallel execution is enabled by default;
On oltp systems with heavy loads, it is recommended to turn off parallel execution.
https://zhuanlan.zhihu.com/p/413491023