abstract
Computer based students are probably familiar with the word pipeline. Especially in Linux system, pipeline operator has been widely used and has brought great convenience to our transformation. The scaffold "gulp" noted in the front-end field is also famous for its pipeline operation.
Today, let's take a step-by-step look at how to design the "pipeline data flow" in the front-end field.
1, Foreword
Students with computer foundation are probably familiar with the word pipeline. Especially in Linux system, pipeline operator has been widely used and has brought great convenience to our transformation. Pipeline operation is usually divided into one-way pipeline and two-way pipeline. When the data flows from the previous pipeline to the next pipeline, our data will be processed by this pipeline, and then sent to the next pipeline, and so on. In this way, some original data can be processed continuously in the continuous pipeline flow, Finally, we get the target data we want.
In the process of our daily programming and development, we can also try to use the concept of pipeline data to optimize our program architecture to make the data flow of our program clearer, and let us be like a pipeline. Each pipeline is responsible for its own work and rough machining the data source, so as to achieve the purpose of clear responsibility and program decoupling.
2, Programming
Now we use Typescript to implement the design of a basic pipeline class. The pipeline we use today is a one-way pipeline.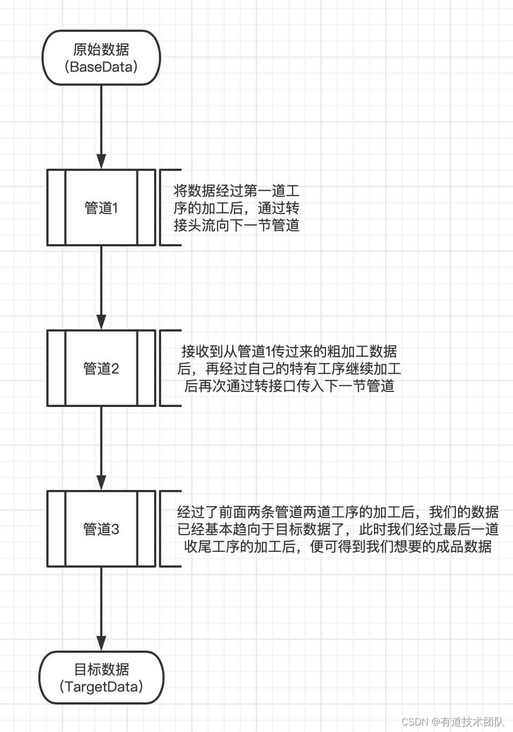
2.1 Pipe adapter
As the name suggests, the adapter is to connect different multiple pipes together to become the connection port of the whole pipe. Through this connector, we can control the flow direction of data and let the data flow to where it really should go.
First, let's design the type structure of our adapter:
type Pipeline<T = any> = {
/**
* Linking multiple pipes
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline<T>): Pipeline<T>;
};The above code describes what kind of adapter is required for a class supporting pipeline data. In programming, our adapter is actually a function to link multiple pipelines.
From the above code, we can see that for the high reuse of the program, we choose to generalize the data types transmitted in the pipeline, so that when we implement a program, we can use the types more flexibly, such as:
// Time type pipeline
type DatePipeline = Pipeline<Date>
// Pipeline of array type
type ArrayPipeLine = Pipeline<string[]>
// Pipes for custom data types
type CustomPipeLine = Pipeline<{name: string, age: number}>In addition, we pay attention to the incoming parameters and return values of this function. As can be seen from the above code, we receive data of one pipeline type and return data of another pipeline type. Among them, the next pipe is passed in the parameter, so we connect the two pipes together. The reason why we want to return data of a pipeline type is that we can call it in a chain when using it, which is more in line with the design concept of pipeline data, such as:
const app = new AppWithPipleline(); app.pipe(new WorkerPipeline1()) .pipe(new WorkerPipeline2()) .pipe(new WorkerPipeline3()) .pipe(new WorkerPipeline4())
In other words, what we return is actually the reference of the pipeline in the next section.
2.2 Push pump
With the adapter, we also need a "water pump" to continuously push our data to different pipelines and finally reach the target point.
type Pipeline<T = any> = {
/**
* The implementation of this method can transfer the data layer by layer through the pipeline
* @param data
*/
push(data: T[]): Promise<void>;
/**
* Linking multiple pipes
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline<T>): Pipeline<T>;
};In order to adapt to more scenarios, we design this water pump to accept an array of T [] type. In the first section of the pipeline, when we get the initial data source, we can use this water pump (method) to push the data out and let each subsequent processing workshop process the data.
2.3 resolveData - processing workshop
When our data is pushed to a certain section of pipeline, a processing workshop will rough process the pushed data according to different processes.
Note: each processing workshop should ensure the separation of responsibilities as far as possible. Each processing workshop is responsible for part of the work and rough machining the data, rather than putting all the work in one processing workshop, otherwise the significance of pipeline data will be lost.
type Pipeline<T = any> = {
/**
* The implementation of this method can transfer the data layer by layer through the pipeline
* @param data
*/
push(data: T[]): Promise<void>;
/**
* Linking multiple pipes
* e.g.
* const app = new BaseApp();
* app.pipe(new TestApp1()).pipe(new TestApp2()).pipe(new TestApp3()).pipe(new Output()).pipe(new End())
* @param _next
*/
pipe(_next: Pipeline<T>): Pipeline<T>;
/**
* It is used to receive the data transferred from the previous section of pipeline and can be transferred to the next section of pipeline after processing
* @param data
*/
resolveData(data: T[]): T[] | Promise<T[]>;
};The processing workshop still receives a T [] type data array. After receiving this data, process the data according to their respective processes. After processing, put it back on the conveyor belt of the assembly line (return value) and send it to the processing workshop of the next pipeline for further processing.
3, Concrete implementation
We just defined the most basic behavior that a pipeline should have. Only the class with the above behavior ability can we consider it a qualified pipeline. Then, next, let's take a look at how a pipeline class needs to be implemented.
3.1 basic pipeline model
class BaseApp<P = any> implements Pipeline<P> {
constructor(data?: P[]) {
data && this.push(data);
}
/**
* For internal use only, refer to the pipe in the next section
*/
protected next: Pipeline<P> | undefined;
/**
* After receiving the data, use resolveData processing to obtain the new data, and then push the new data to the next pipeline
* @param data
*/
async push(data: P[]): Promise<void> {
data = await this.resolveData(data);
this.next?.push(data);
}
/**
* Link pipeline
* Let the return value of pipe always be the reference of the next pipe, so that it can be called in a chain
* @param _next
* @returns
*/
pipe(_next: Pipeline<P>): Pipeline<P> {
this.next = _next;
return _next;
}
/**
* Data processing, return the latest data object
* @param data
* @returns
*/
resolveData(data: P[]): P[] | Promise<P[]> {
return data;
}
}We define a basic class that implements the Pipleline interface to describe the appearance of all pipelines. All our pipelines need to inherit from this basic class.
In the constructor, we accept an optional parameter, which represents our initial data source. Only the first pipe needs to pass in this parameter to inject initial data into the whole pipe. After we get the initial data, we will use the water pump to push the data out.
3.2 unified data object of pipeline
Usually, during program implementation, we will define a unified data object as the data flowing in the pipeline, so as to better maintain and manage.
type PipeLineData = {
datasource: {
userInfo: {
firstName: string;
lastName: string;
age: number,
}
}
}3.3 section I pipeline
Since there is no pipeline before the first section of pipeline, if we want to make the data flow, we need to use a water pump at the first section of pipeline to give the data an initial kinetic energy so that it can flow. Therefore, the implementation of the first section of pipeline will be slightly different from that of other pipelines.
export class PipelineWorker1 extends BaseApp<PipeLineData> {
constructor(data: T[]) {
super(data);
}
}The main function of the first section of the pipeline is to accept the original data source and use the water pump to send the data, so the implementation is relatively simple. We only need to inherit our base class BaseApp and submit the initial data source to the base class, and the base class can push the data out with the water pump.
3.4 other pipelines
For other pipelines, each pipeline will have a data processing workshop to process the data flowing to the current pipeline, so we also need to override the resolveData method of the base class.
export class PipelineWorker2 extends BaseApp<PipeLineData> {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise<PipeLineData[]> {
// Here we can perform some specific processing on the data
// Note that we try our best to operate on the incoming data and keep the reference
data.forEach(item => {
item.userInfo.name = `${item.userInfo.firstName} · ${item.userInfo.lastName}`
});
// Finally, we call the resolveData method of the base class to transfer the processed data,
// In this way, the processing of one process is completed
return super.resolveData(data);
}
}
export class PipelineWorker3 extends BaseApp<PipeLineData> {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise<PipeLineData[]> {
// Here we can perform some specific processing on the data
// Note that we try our best to operate on the incoming data and keep the reference
data.forEach(item => {
item.userInfo.age += 10;
});
// Finally, we call the resolveData method of the base class to transfer the processed data,
// In this way, the processing of one process is completed
return super.resolveData(data);
}
}
export class Output extends BaseApp<PipeLineData> {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise<PipeLineData[]> {
// Here we can perform some specific processing on the data
// Note that we try our best to operate on the incoming data and keep the reference
console.log(data);
// Finally, we call the resolveData method of the base class to transfer the processed data,
// In this way, the processing of one process is completed
return super.resolveData(data);
}
}
// We can also use the flexible characteristics of pipeline assembly to develop a variety of plug-ins, which can be plugged in and out at any time
export class Plugin1 extends BaseApp<PipeLineData> {
constructor() {
super();
}
resolveData(data: PipeLineData[]): PipeLineData[] | Promise<PipeLineData[]> {
// Here we can perform some specific processing on the data
// Note that we try our best to operate on the incoming data and keep the reference
console.log("This is a plug-in");
// Finally, we call the resolveData method of the base class to transfer the processed data,
// In this way, the processing of one process is completed
return super.resolveData(data);
}
}3.5 assembling pipes
We have prepared each section of pipes above. Now we need to assemble them and put them into use.
const datasource = {
userInfo: {
firstName: "kiner",
lastName: "tang",
age: 18
}
};
const app = new PipelineWorker1(datasource);
// Pipes can be combined at will
app.pipe(new Output())
.pipe(new PipelineWorker2())
.pipe(new Output())
.pipe(new PipelineWorker3())
.pipe(new Output())
.pipe(new Plugin1());
4, Conclusion
So far, we have completed the design of a pipeline architecture. Do you think that after using pipeline data, the data flow of our whole program code is clearer, the division of labor before each module is clearer, and the cooperation between modules and projects before modules is more flexible?
Using pipeline design also allows us to expand an additional plug-in library. Users can customize plug-ins that meet various business scenarios at will, making our program highly extensible.