background
Due to the needs of the company's business scenarios, we need to develop HBase platform, which mainly needs the following functions:
- Table creation management
- Authorization management
- SDK implementation
- Connect with the company's internal system
HBase version we use:
HBase 1.2.0-cdh5.16.2
Hadoop: 2.6.0-cdh5.16.2
Main application scenarios at present:
- Real time calculation of dimension tables such as commodities and merchants
- De duplication logic
- Middleware services and other monitoring data
- User portrait
Platform construction
Table creation management
1. Specify namespace
The HBase system defines two default namespace s by default:
- hbase: system built-in tables, including namespace and meta tables
- default: all tables that do not specify a namespace are created here
We need to define namespaces according to business groups to facilitate maintenance and management
2. Multiple clusters are supported. Different business groups select corresponding clusters according to their needs
3. Specify table name
4. Specify column family
Because the column family is determined when creating a table, the column name is prefixed with the column family and can be added dynamically as needed, such as cf:name, cf:age
cf is the column family, and name and age are the column names
5. Set the lifetime TTL
Once the expiration time is reached, HBase will automatically delete the row
6. Support pre partition
By default, HBase has a region when creating tables. The rowkey of this region has no boundary, that is, there is no startkey and endkey. When data is written, all data will be written to this default region. With the continuous increase of the amount of data, this region can no longer bear the increasing amount of data. It will be split into two regions. In this process, two problems arise:
- When data is written to a region, there will be write hot issues.
- region split consumes valuable cluster I/O resources.
Based on this, we can control the creation of multiple empty regions when creating tables, and determine the start and end rowkeys of each region. In this way, as long as our rowkey design can hit each region evenly, there will be no write hotspot problem. The probability of natural split will also be greatly reduced. Of course, with the continuous growth of the amount of data, the split still needs to be split. The method of creating hbase table partition in advance like this is called pre partition
For the implementation of pre partition, refer to the shell script implementation of HBase
Relevant codes:
Configuration configuration = conn.getConfiguration(); RegionSplitter.SplitAlgorithm hexStringSplit = RegionSplitter.newSplitAlgoInstance(configuration, splitaLgo); splits = hexStringSplit.split(numRegions);
Specify the segmentation algorithm and the number of pre partitions
There are three main segmentation algorithms:
- HexStringSplit: rowkey is prefixed with hexadecimal string
- Decimal stringsplit: rowkey is prefixed with a hexadecimal numeric string
- UniformSplit: rowkey prefix is completely random
Other configurations:
HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cf); //Specify the version and set it to one hColumnDescriptor.setMaxVersions(1); //Specify the expiration time of the column family. The minimum unit configured in the interface is days, and the unit of HBase TTL time is seconds Long ttl = TimeUnit.DAYS.toSeconds(expireDays); hColumnDescriptor.setTimeToLive(ttl.intValue()); //Enable compression algorithm hColumnDescriptor.setCompressionType(Compression.Algorithm.SNAPPY); //The compression algorithm is used for compression hColumnDescriptor.setCompactionCompressionType(Compression.Algorithm.SNAPPY); //Make the data block cache have higher priority in the LRU cache hColumnDescriptor.setInMemory(true); //bloom filter, filter acceleration hColumnDescriptor.setBloomFilterType(BloomType.ROW); descriptor.addFamily(hColumnDescriptor);
Finally, call admin Create table
When creating a table, pay attention to detecting the existence of a namespace, creating a namespace if it does not exist, and automatically authorizing the corresponding business group when creating a table.
The functions of table structure view, data preview and table deletion can be realized through HBase java API, which will not be introduced here
Authorization management
First, how does HBase implement authentication?
We adopt HBase ACL authentication mechanism, and the specific configuration is as follows:
<property>
<name>hbase.superuser</name>
<value>admin</value>
</property>
<property>
<name>hbase.coprocessor.region.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.hadoop.hbase.security.access.AccessController</value>
</property>
<property>
<name>hbase.security.authorization</name>
<value>true</value>
</property>Authorization to other business groups is performed using super accounts
The following is the permission cross reference table:
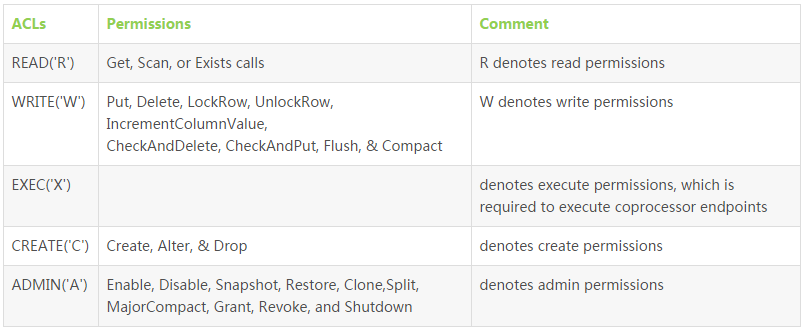
Authorization process:

How do users operate HBase and how does the platform authenticate and authenticate?
We developed a very simple SDK
SDK implementation
The main function of SDK is to authenticate and authorize, and obtain the connection information of related clusters.
Overall process:
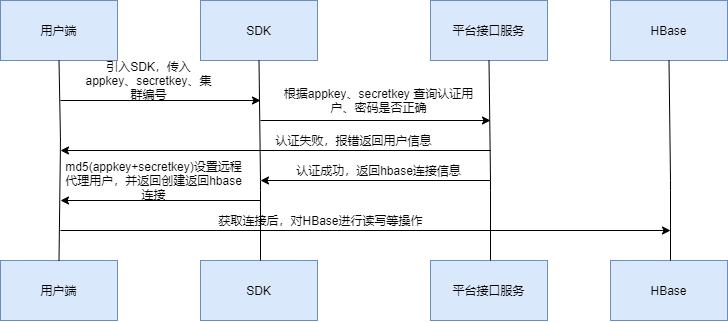
Connect with the company's internal system
The main work is to develop the platform to use HBase tasks, how to get through authentication, etc. because the tasks are submitted based on the business group, it is easy to meet the requirements
For external services to use HBase in the container, you need to configure hosts in the container before DNS forward and reverse resolution of the host name.
Cluster data migration
The main scenario is that we need to migrate the data from the old cluster to the new cluster to realize cross cluster migration.
Old cluster version: HBase: 1.2 0-cdh5. 12.0 Hadoop: 2.6. 0-cdh5. twelve
New cluster version: HBase: 1.2 0-cdh5. 16.2 Hadoop: 2.6. 0-cdh5. sixteen point two
The Distcp scheme is used. Generally, the low peak period is selected. It is necessary to ensure that the tables in the HBase cluster are static data, and the writing of the business tables needs to be stopped
Specific steps
(1) Execute the distcp command under the HDFS user in the new cluster
Execute the command on the NameNode node of the new cluster
hadoop distcp -Dmapreduce.job.queue.name=default -pug -update -skipcrccheck -m 100 hdfs://ip:8020/hbase/data/aaa/user_test /hbase/data/aaa/user_test
(2) Execute the HBase command to repair the metadata of the HBase table, such as table name, table structure, etc., and will be re registered in the Zookeeper of the new cluster.
sudo -u admin hbase hbck -fixMeta "aaa:user_test" sudo -u admin hbase hbck -fixAssignments "aaa:user_test"
(3) Validation data:
scan 'aaa:user_test' ,{LIMIT=>10}(4) Delete old cluster table:
#!/bin/bash exec sudo -u admin hbase shell <<EOF disable 'aaa:user_test' drop 'aaa:user_test' EOF
For the convenience of migration, the above commands can be encapsulated into a Shell script, such as:
#! /bin/bash for i in `cat /home/hadoop/hbase/tbl` do echo $i hadoop distcp -Dmapreduce.job.queue.name=queue_0001_01 -update -skipcrccheck -m 100 hdfs://old_hbase:9000/hbase/data/$i /hbase/data/$i done hbase hbck -repairHoles
summary
This paper mainly summarizes the practice of HBase platform construction, mainly including the implementation of attribute configuration related to the creation of HBase table, as well as the multi tenant design idea of authentication and authentication. At the same time, it summarizes the practice of HBase cross cluster table element information and data migration