brief introduction
Last article Playing Hudi Docker Demo based on Ubuntu (2) -- writing test data to Kafka Describes how to write test data to fkaka cluster.
This article describes how to use Spark to consume Kafka data and write the data to HDFS. Hudi is introduced into Spark in the form of Jar package.
Types of Hudi tables and queries
| Table type | Supported query types |
|---|---|
| Copy On Write | Support snapshot query and incremental query |
| Merge On Read | Support snapshot query, incremental query and read optimization query |
1. Table type
- Copy On Write (cow): store data in e.g. parquet format, and merge historical data synchronously when writing data.
- Merge On Read (mor): store data in combination with column storage (e.g parquet) and row storage (e.g avro). Incremental data first stores data in row storage, and then combines data in synchronous or asynchronous manner to generate column storage files.
| balance | CopyOnWrite | MergeOnRead |
|---|---|---|
| Data delay | high | low |
| Query delay | low | high |
| Renewal cost | High, the entire parquet file needs to be rewritten | Low, write incremental files in append mode |
| Write amplification | large | Small, depending on the consolidation strategy |
2. Query type
- Snapshot Queries: you can query the snapshot data that was successfully submitted or merged last time.
- Incremental Queries: you can query the data newly written to the table after the specified submission or consolidation.
- Read Optimized Queries: limited to the MergeOnRead table, you can query the data of the listed file.
For the MergeOnRead table, the following trade-offs need to be made to select the query type:
| balance | Snapshot Queries | Read Optimized Queries |
|---|---|---|
| Data delay | low | high |
| Query delay | high | low |
Specific process
1. Enter the container ad hoc-2
sudo docker exec -it adhoc-2 /bin/bash

2. Execute spark submit
Execute the following spark submit command to start delta streamer, consume data from kafka cluster and adopt COPY_ON_WRITE mode is written to HDFS, and the table name is stock_ticks_cow
spark-submit \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer $HUDI_UTILITIES_BUNDLE \ --table-type COPY_ON_WRITE \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --source-ordering-field ts \ --target-base-path /user/hive/warehouse/stock_ticks_cow \ --target-table stock_ticks_cow --props /var/demo/config/kafka-source.properties \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
Execute the following spark submit command to start delta streamer, consume data from kafka cluster and use merge_ ON_ The read mode is written to HDFS, and the table name is stock_ticks_mor
spark-submit \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer $HUDI_UTILITIES_BUNDLE \ --table-type MERGE_ON_READ \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --source-ordering-field ts \ --target-base-path /user/hive/warehouse/stock_ticks_mor \ --target-table stock_ticks_mor \ --props /var/demo/config/kafka-source.properties \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \ --disable-compaction
3. View hdfs file
stock_ticks_cow
stock_ticks_cow is partitioned by date. There is a metadata file and parquet format data file under the partition directory.
Yes You can see the commit information in the hoodle directory.

stock_ticks_mor

4. Synchronize to Hive metadata
/var/hoodie/ws/hudi-sync/hudi-hive-sync/run_sync_tool.sh \ --jdbc-url jdbc:hive2://hiveserver:10000 \ --user hive \ --pass hive \ --partitioned-by dt \ --base-path /user/hive/warehouse/stock_ticks_cow \ --database default \ --table stock_ticks_cow /var/hoodie/ws/hudi-sync/hudi-hive-sync/run_sync_tool.sh \ --jdbc-url jdbc:hive2://hiveserver:10000 \ --user hive \ --pass hive \ --partitioned-by dt \ --base-path /user/hive/warehouse/stock_ticks_mor \ --database default \ --table stock_ticks_mor
4. Spark SQL query
Enter spark shell:
$SPARK_INSTALL/bin/spark-shell \ --jars $HUDI_SPARK_BUNDLE \ --master local[2] \ --driver-class-path $HADOOP_CONF_DIR \ --conf spark.sql.hive.convertMetastoreParquet=false \ --deploy-mode client \ --driver-memory 1G \ --executor-memory 3G \ --num-executors 1 \ --packages org.apache.spark:spark-avro_2.11:2.4.4
- stock_ticks_cow is the CopyOnWrite table
- stock_ticks_mor_ro is the MergeOnRead table, which is used to read optimized queries
- stock_ticks_mor_rt is the MergeOnRead table, which is used for snapshot query
Spark context Web UI available at http://adhoc-2:4040
Spark context available as 'sc' (master = local[2], app id = local-1644547729231).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.sql("show tables").show(100, false)
+--------+------------------+-----------+
|database|tableName |isTemporary|
+--------+------------------+-----------+
|default |stock_ticks_cow |false |
|default |stock_ticks_mor_ro|false |
|default |stock_ticks_mor_rt|false |
+--------+------------------+-----------+
## Run max timestamp query against COW table
scala> spark.sql("select symbol, max(ts) from stock_ticks_cow group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:29:00|
+------+-------------------+
## Projection Query
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_cow where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211022538859 |GOOG |2018-08-31 10:29:00|3391 |1230.1899|1230.085|
+-------------------+------+-------------------+------+---------+--------+
# Merge-On-Read Queries:
# Run ReadOptimized Query. Notice that the latest timestamp is 10:29
scala> spark.sql("select symbol, max(ts) from stock_ticks_mor_ro group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:29:00|
+------+-------------------+
# Run Snapshot Query. Notice that the latest timestamp is again 10:29
scala> spark.sql("select symbol, max(ts) from stock_ticks_mor_rt group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:29:00|
+------+-------------------+
# Run Read Optimized and Snapshot project queries
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_mor_ro where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022707523 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211022707523 |GOOG |2018-08-31 10:29:00|3391 |1230.1899|1230.085|
+-------------------+------+-------------------+------+---------+--------+
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_mor_rt where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022707523 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211022707523 |GOOG |2018-08-31 10:29:00|3391 |1230.1899|1230.085|
+-------------------+------+-------------------+------+---------+--------+
5. Write the second batch of data to kafka
Exit the docker container and execute it on the Ubuntu command line
cat docker/demo/data/batch_2.json | kafkacat -b kafkabroker -t stock_ticks -P

6. Enter the container ad hoc-2 and execute spark submit to write the second batch of data to the Hudi table
Enter container ad hoc-2
sudo docker exec -it adhoc-2 /bin/bash
The second batch of data to Hudi CopyOnWrite table
spark-submit \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer $HUDI_UTILITIES_BUNDLE \ --table-type COPY_ON_WRITE \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --source-ordering-field ts \ --target-base-path /user/hive/warehouse/stock_ticks_cow \ --target-table stock_ticks_cow \ --props /var/demo/config/kafka-source.properties \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider
View hdfs Directory:
hdfs dfs -ls -R /user/hive/warehouse/stock_ticks_cow
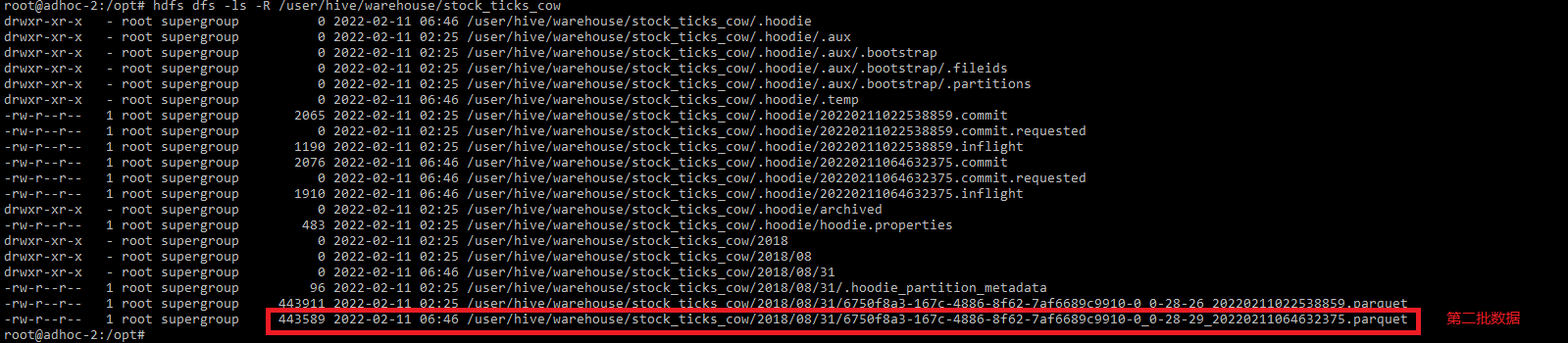
The second batch of data to Hudi MergeOnRead table
spark-submit \ --class org.apache.hudi.utilities.deltastreamer.HoodieDeltaStreamer $HUDI_UTILITIES_BUNDLE \ --table-type MERGE_ON_READ \ --source-class org.apache.hudi.utilities.sources.JsonKafkaSource \ --source-ordering-field ts \ --target-base-path /user/hive/warehouse/stock_ticks_mor \ --target-table stock_ticks_mor \ --props /var/demo/config/kafka-source.properties \ --schemaprovider-class org.apache.hudi.utilities.schema.FilebasedSchemaProvider \ --disable-compaction
View hdfs Directory:
hdfs dfs -ls -R /user/hive/warehouse/stock_ticks_mor
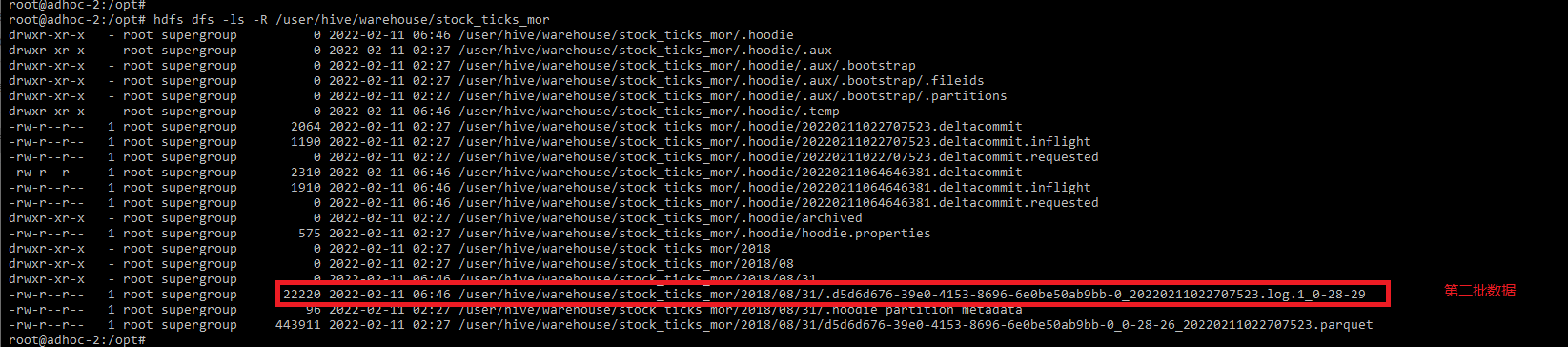
7. Spark SQL query
Enter spark shell:
$SPARK_INSTALL/bin/spark-shell \ --jars $HUDI_SPARK_BUNDLE \ --master local[2] \ --driver-class-path $HADOOP_CONF_DIR \ --conf spark.sql.hive.convertMetastoreParquet=false \ --deploy-mode client \ --driver-memory 1G \ --executor-memory 3G \ --num-executors 1 \ --packages org.apache.spark:spark-avro_2.11:2.4.4
Spark context Web UI available at http://adhoc-2:4040
Spark context available as 'sc' (master = local[2], app id = local-1644571477181).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.4
/_/
Using Scala version 2.11.12 (OpenJDK 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
# 1. Query CopyOnWrite table in snapshot mode
scala> spark.sql("select symbol, max(ts) from stock_ticks_cow group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:59:00|
+------+-------------------+
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_cow where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211064632375 |GOOG |2018-08-31 10:59:00|9021 |1227.1993|1227.215|
+-------------------+------+-------------------+------+---------+--------+
# 2. Query CopyOnWrite table in incremental mode
scala> import org.apache.hudi.DataSourceReadOptions
scala> val hoodieIncViewDF = spark.read.format("org.apache.hudi").option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL).option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "20220211064632000").load("/user/hive/warehouse/stock_ticks_cow")
scala> hoodieIncViewDF.registerTempTable("stock_ticks_cow_incr_tmp1")
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_cow_incr_tmp1 where symbol = 'GOOG'").show(100, false);
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211064632375 |GOOG |2018-08-31 10:59:00|9021 |1227.1993|1227.215|
+-------------------+------+-------------------+------+---------+--------+
# 3. Query MergeOnRead table by reading optimization method
scala> spark.sql("select symbol, max(ts) from stock_ticks_mor_ro group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:29:00|
+------+-------------------+
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_mor_ro where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211022538859 |GOOG |2018-08-31 10:29:00|3391 |1230.1899|1230.085|
+-------------------+------+-------------------+------+---------+--------+
# 4. Query MergeOnRead table in snapshot mode
scala> spark.sql("select symbol, max(ts) from stock_ticks_mor_rt group by symbol HAVING symbol = 'GOOG'").show(100, false)
+------+-------------------+
|symbol|max(ts) |
+------+-------------------+
|GOOG |2018-08-31 10:59:00|
+------+-------------------+
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_mor_rt where symbol = 'GOOG'").show(100, false)
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 |
|20220211064632375 |GOOG |2018-08-31 10:59:00|9021 |1227.1993|1227.215|
+-------------------+------+-------------------+------+---------+--------+
# 5. Query MergeOnRead table in incremental mode
scala> val hoodieIncViewDF = spark.read.format("org.apache.hudi").option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL).option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "20220211064632000").load("/user/hive/warehouse/stock_ticks_mor")
scala> hoodieIncViewDF.registerTempTable("stock_ticks_mor_incr_tmp1")
scala> spark.sql("select `_hoodie_commit_time`, symbol, ts, volume, open, close from stock_ticks_mor_incr_tmp1 where symbol = 'GOOG'").show(100, false);
+-------------------+------+-------------------+------+---------+--------+
|_hoodie_commit_time|symbol|ts |volume|open |close |
+-------------------+------+-------------------+------+---------+--------+
|20220211064632375 |GOOG |2018-08-31 10:59:00|9021 |1227.1993|1227.215|
+-------------------+------+-------------------+------+---------+--------+
Among them, for the MergeOnRead table, the results of read optimization query and snapshot query are different.
Read optimization query:
+-------------------+------+-------------------+------+---------+--------+ |_hoodie_commit_time|symbol|ts |volume|open |close | +-------------------+------+-------------------+------+---------+--------+ |20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 | |20220211022538859 |GOOG |2018-08-31 10:29:00|3391 |1230.1899|1230.085| <<<<<<<<<<<<<<<<<< +-------------------+------+-------------------+------+---------+--------+
Snapshot query:
+-------------------+------+-------------------+------+---------+--------+ |_hoodie_commit_time|symbol|ts |volume|open |close | +-------------------+------+-------------------+------+---------+--------+ |20220211022538859 |GOOG |2018-08-31 09:59:00|6330 |1230.5 |1230.02 | |20220211064632375 |GOOG |2018-08-31 10:59:00|9021 |1227.1993|1227.215| <<<<<<<<<<<<<<<<<< +-------------------+------+-------------------+------+---------+--------+
This shows the difference between read optimized query and snapshot query.