
After learning the initial level of C language and the advanced level of C language, start to formally learn C + +. This paper mainly involves the introduction of C + +. The contents introduced are C + + keywords, namespaces, default parameters, IO, function overloading, inline functions, auto keywords, new for loops, nullptr and references, which lay a good foundation for object-oriented

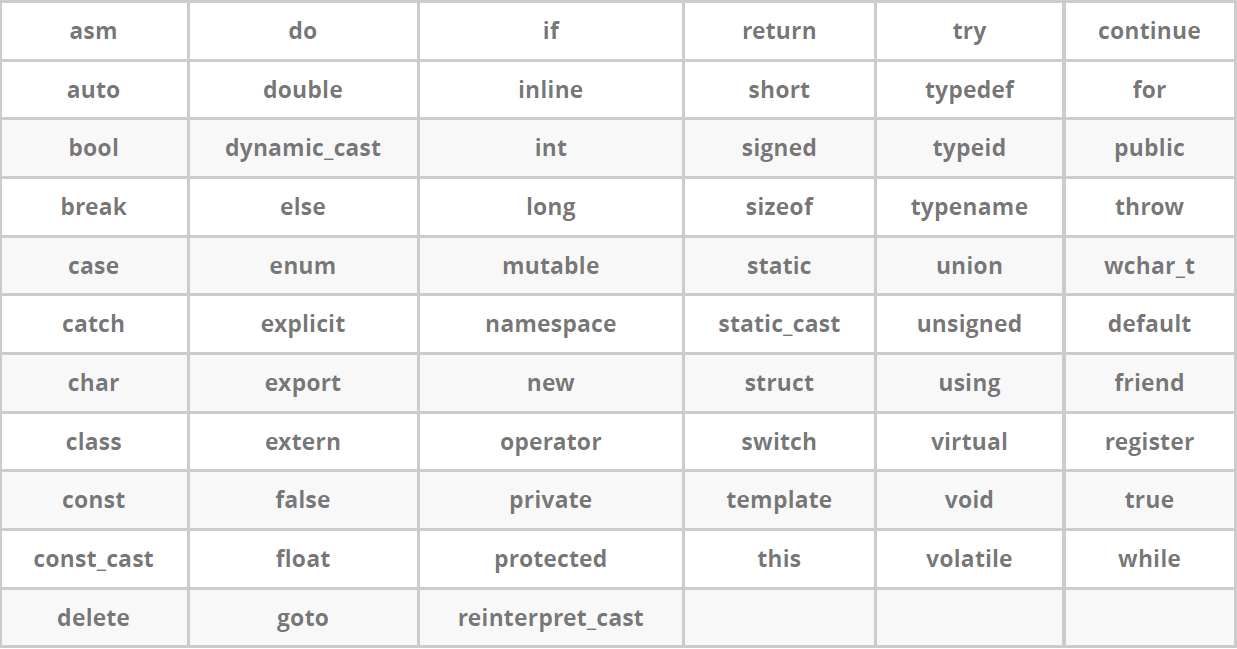
1. Keywords
Among the keywords, C + + adds and supplements the content of C language. Compared with C, C + + adds 31 keywords, reaching 63
The following are all the keywords. You can mix them here temporarily and try to understand and use them when you have a certain foundation in the future
2. Namespace
2.1 understanding namespace
C + + and Java were born to solve some defects of C language
For example, namespace defines a domain to avoid naming conflicts and naming pollution
In the C language library, there are two functions named scanf and strlen
Suppose I want to use these two names to name variables in my code
int main()
{
int scanf = 10;
int strlen = 20;
// C language can not solve the problem of conflict
scanf("%d", &scanf);
printf("%d\n", scanf);
printf("%d\n", strlen);
return 0;
}
So you can't run
C + + can solve this problem
By creating a namespace and using a domain scope such as:: to realize name isolation, for example, the following can be done
namespace allen
{
int scanf=10;
int strlen=20;
}
int main()
{
// Cpp conflict resolution
printf("%x\n", scanf);
printf("%x\n", strlen);
scanf("%d", &allen::scanf);
printf("%d\n",allen::scanf);
printf("%d\n",allen::strlen);
return 0;
}
2.2 characteristics of namespace
⚡ ⅸ general definition
namespace allen
{
int scanf=10;
int strlen=20;
}
⚡ Nesting of namespaces
namespace allen
{
int scanf = 10;
int strlen = 20;
int Add(int left, int right)
{
return left + right;
}
namespace n1
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
// You can set it again
}
}
int main()
{
allen::n1::Sub(10, 4);
return 0;
}
⚡ If there are multiple namespaces with the same name in the same project, the compiler finally combines them into one namespace
⚡ Of course, you cannot have the same name in the same domain
2.3 using namespaces
First of all, understand that in order to prevent naming conflicts, C + + libraries define everything in their own libraries in an std namespace
There are three ways to use things in the standard library
⚡ ⅸ specify namespace
std::cout << "hello world" << std::endl; std::vector<int> v; std::string s;
The problem is that it is troublesome. Every place should be specified, but it is the most standardized way
⚡ Expand the whole std, which means that everything in the library is in the global domain
namespace allen
{
int a = 20;
int b = 10;
}
using namespace allen;//The use of the keyword using expands the namespace to the global
int main()
{
printf("a The value of is:%d\n", a);
return 0;
}
It seems convenient. If our own definition conflicts with the library, there is no way to solve it. One night back before liberation, so this method is not recommended in standardized engineering projects.
⚡ Expand the contents of some commonly used libraries
using std::cout;
using std::endl;
int main()
{
cout << "hello world" << endl;
return 0;
}
For 1 and 2 compromise schemes, they are often used in projects
Finally, give another example to familiarize yourself with
int a = 0;
int main()
{
int a = 1;
printf("%d\n", a);
printf("%d\n", ::a);//Blank indicates global domain
return 0;
}
3. I/O input and output
3.1 header file and input / output function quick start
🐉 When using cout standard output (console) and cin standard output (console), the header file and std standard namespace must be included. The header file of the output input stream in cpp is < iostream >
🐉 Here are three functions related to three inputs and outputs
⚡ Global object cout of ostream type
⚡ Global object cin of type istream
⚡ Global newline symbol endl
🐉 The input format of cin is cin > > variable name, and the output format of cout is cout < < variable name
Compared with printf and scanf, the difference between cin and cout is that these two functions can automatically identify the type of data. Now there is no need to write% + data type when outputting. cin can also no longer take the address of the input value of this variable and follow the corresponding format like scanf
Use example
int a = 10; char str[10]; std::cin >> a; std::cin >> str; std::cout << a << str << std::endl;

Summary:
The output form cout is convenient to write in most cases because of automatic matching, but it is not very convenient to include the format in the output, so it can be used comprehensively, whichever is easy to use
4. Default parameters
4.1 definition of default parameters
⚡ The default parameter is to specify a default value for the parameter of the function when declaring or defining the function
⚡ ﹥ when calling a function, if no argument is specified, the default value will be adopted; otherwise, the specified argument will be used.
// Default parameters
void TestFunc(int a = 0)
{
cout << a << endl;
}
int main()
{
TestFunc(10);
TestFunc();
return 0;
}
For example, TestFunc here will output 10 when 10 is passed in, otherwise it will not output 0
4.2 classification of default parameters
4.2.1 all default parameters
We set all parameters as default parameters
// Full default
void TestFunc(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
TestFunc(1, 2, 3);
TestFunc();
TestFunc(1);
TestFunc(1,2);
return 0;
}
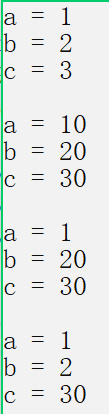
4.2.2 semi default parameters
Semi default
void TestFunc(int a, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
// What is the function of the default parameter? It is more flexible to call
int main()
{
TestFunc(1);
TestFunc(1, 2);
TestFunc(1, 2, 3);
return 0;
}
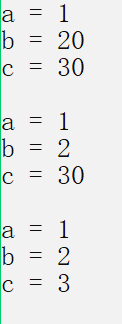
🍁 Set some parameters in the function as default parameters
4.3 practical application
When will default parameters be used in actual development?
For example, when writing data structures
void StackInit(struct Stack* ps, int InitCapacity = 4)
{
ps->a = (int*)malloc(sizeof(int) * InitCapacity);
ps->size = 0;
ps->capacity = InitCapacity;
}
// Default parameter - more flexible when calling
int main()
{
struct Stack st1;
// Suppose I know that at least 100 data must be stored in the stack
StackInit(&st1, 100);
struct Stack st2;
// Suppose I know that there are at most 10 data stored in the stack
StackInit(&st2, 10);
struct Stack st3;
// Suppose I don't know how much data may be stored in the stack
StackInit(&st2);
return 0;
}
This is something that C language can't do. C + + provides special functions. If I know how much data to save, I can change it directly, but if I don't know, I will follow the default value
4.4 precautions for default parameters
🌿 The default value must be a constant or a global variable
🌿 Semi default parameter, which must default from right to left and be continuous
🌿 Default parameters cannot appear in function definitions and declarations at the same time
//test.h
void TestFunc(int a = 5);
// test.cpp
void TestFunc(int a = 10)
{
}
🌿 C language is not supported
5. Function overloading
5.1 heavy load quick start
It has the same meaning as overloading in Java. C + + can also define functions with the same name
Function overloading is a special case of functions. C + + allows to declare several functions with the same name with similar functions in the same scope. The formal parameter list (number or type or order of parameters) of these functions with the same name must be different. It is often used to deal with the problems of similar functions and different data types
🌰
int Add(int left, int right)
{
return left + right;
}
int Add(int left = 10, int right = 20)//The default parameter is not overloaded. If this parameter is written, an error will be reported
{
return left + right;
}
char Add(char left, char right)
{
return left + right;
}
double Add(double left, double right)
{
return left + right;
}
int main()
{
cout << Add() << endl;//If the first Add is not commented out, an error will be reported
cout << Add(1, 2) << endl; // Literal shaping is a constant by default
cout << Add('1', '2') << endl;
cout << Add(1.1, 2.2) << endl;
return 0;
}
🌰🌰
void f(int a, int b, int c = 1)
{}
void f(int a, int b)
{}
int main()
{
f(1, 2, 3);
// f(1, 2);//err produces ambiguity
return 0;
}
Therefore, heavy load and default should not be used indiscriminately. Pay attention not to step on the pit
🌰🌰🌰
void swap(int* a, int* b)
{
// ...
}
void swap(double* a, double* b)
{
// ...
}
int main()
{
int x = 0, y = 1;
swap(&x, &y);
double m = 1.1, n = 2.2;
swap(&m, &n);
return 0;
}
It looks more comfortable
⚠️ Note: different return values do not constitute overloading, such as the following
short Add(short left, short right)
{
return left+right;
}
int Add(short left, short right)
{
return left+right;
}
5.1 name modification
At this point, we raise questions about function overloading
5.1.1 why does C language not support overloading? How is C + + implemented
To solve these problems, Linux is needed to assist the demonstration
⚡ Linux decoration rules
First of all, we know that in C/C + +, a program needs to go through the following stages to run: preprocessing, compiling, assembling and linking.
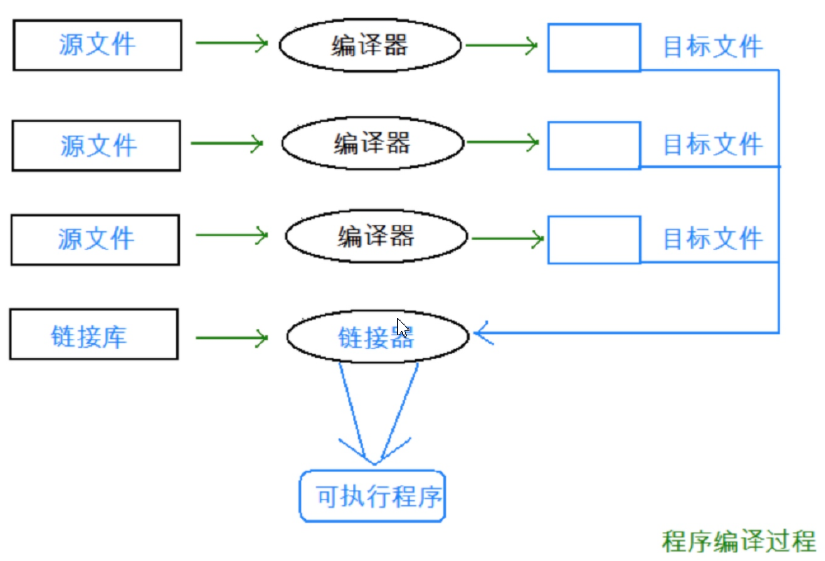

🍁 Actually, our project is usually made up of multiple header files and multiple source files. By compiling the links, we can know that when the Add function defined in b.cpp is called in the current a.cpp, there is no Add function address in the a.o's target file before the compiled link, because Add is defined in b.cpp, so Add's address is in b.o. So what?
🍁 Therefore, the link stage is dedicated to dealing with this problem. When the linker sees that a.o calls Add, but there is no address of Add, it will find the address of Add in the symbol table of b.o, and then link it together.
🍁 When linking, which name will the connector use to find the Add function? Each compiler here has its own function name modifier
Then.
🍁 Because the decoration rules of vs under Windows are too complex, while the decoration rules of gcc under Linux are simple and easy to understand
🍁 We can see from the following that the name of gcc function remains unchanged after modification. After modification, the function of g + + becomes [_Z + function length + function name + type initials].
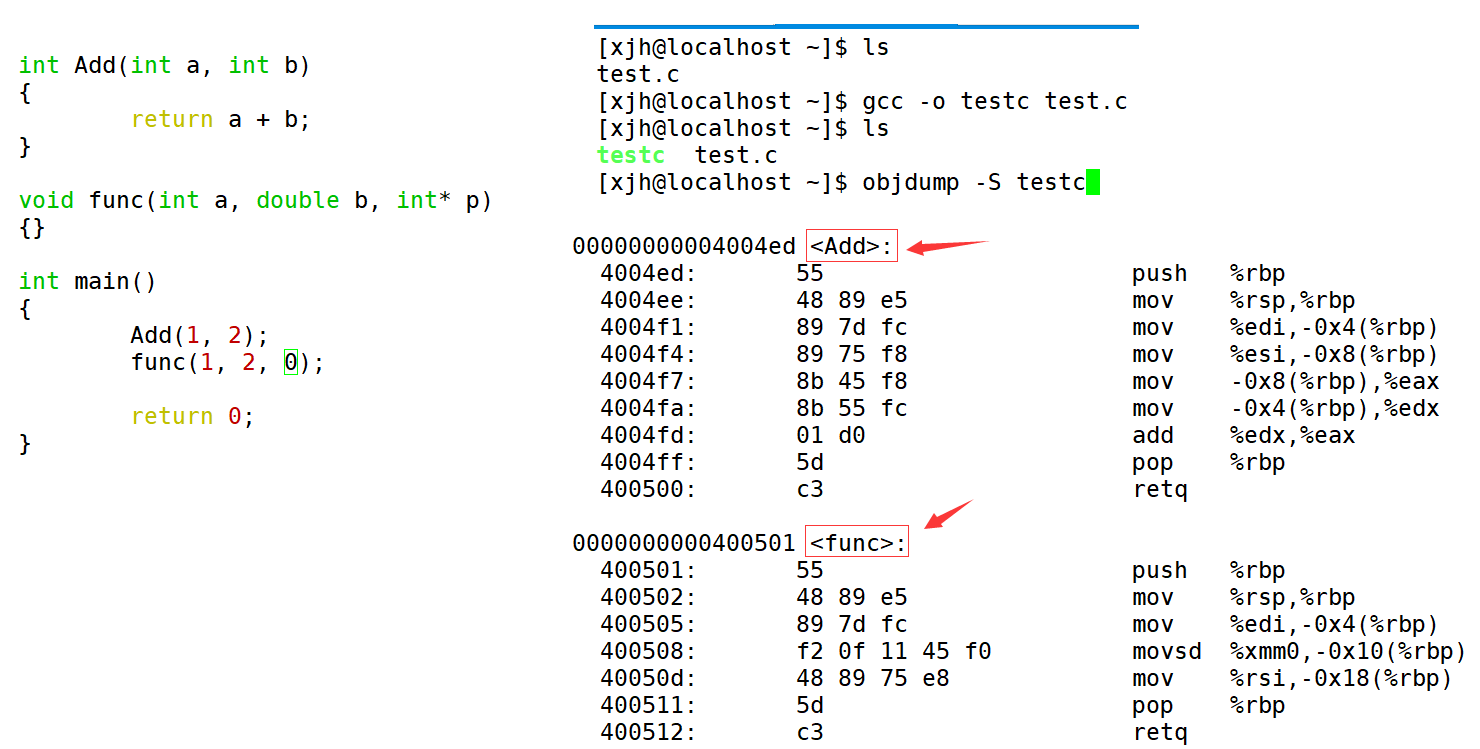
🌿 Under linux, the modification of function name has not changed after gcc compilation.
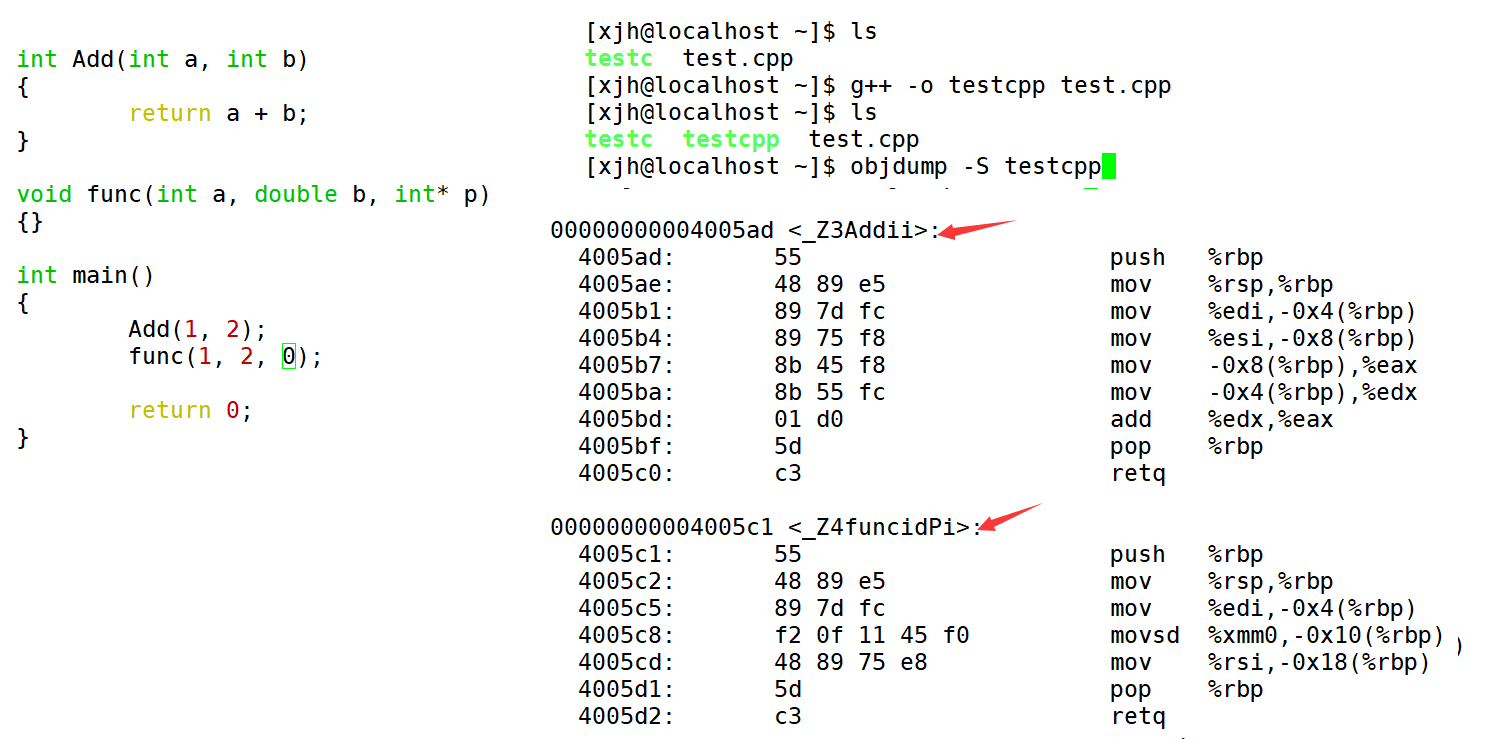
🌿 Under linux, after g + + compilation, the modification of the function name changes, and the compiler adds the function parameter type information to the modified name.
To put it simply, when linking functions, the address and name of overloaded functions are different, so functions with the same name are distinguished
⚡ Windows decoration rules
Compared with the decoration rules of Linux, Windows will be much more complex and changeable
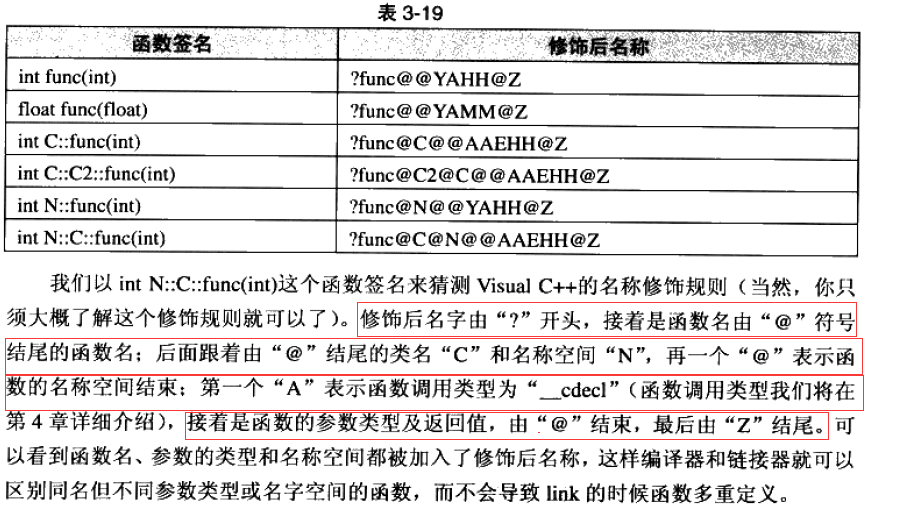
You can also refer to the following websites to learn function calling conventions and name modification rules
C + + function overloading
Calling convention of C/C + +
🍁 It is understood here that C language cannot support overloading, because functions with the same name cannot be distinguished. C + + is distinguished by function modification rules. As long as the parameters are different, the modified names are different, and overloading is supported.
🍁 In addition, we also understand why function overloading requires different parameters, which has nothing to do with the return value.
5.1.2 what is the function of extern "C"
Sometimes in C + + projects, some functions may need to be compiled in the style of C. adding extern "C" before the function means telling the compiler to compile the function according to the rules of C language.
Tcmalloc is a project implemented by google in C + +. It provides two interfaces: tcmalloc() and tcfree. These middleware programs are usually compiled into static libraries or dynamic libraries, which can be found and used by C + +. However, if they are c projects, they can't be used. They can't be found because of different decoration methods, so the solution is to use extern "C". In this way, the C program can also call this library
The solution is to have extern "C" when naming, which means that there is no name modification rule when the last link is added
C + + can also be called through extern "C", which can lead to C/C + + being called
However, this function cannot be overloaded
It does use a lot of extern "C"
6. Reference
In C + +, the newly introduced references and pointers are aligned with each other
6.1 concepts introduced
⚡ If we change the value of a, b will change accordingly
⚡ The addresses of two values are the same at the same time
How do I use references?
Type & reference variable name (object name) = reference entity;
int main()
{
int a = 10;
// b is a reference (alias) of A
int& b = a;
b = 20;
int& c = b;
c = 30;
return 0;
}
🍁 Nicknames can be taken from dolls
6.2 referenced functions
void swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void swap(int& r1, int& r2)
{
int tmp = r1;
r1 = r2;
r2 = tmp;
}
int main()
{
int a = 1, b = 2;
swap(&a, &b);
swap(a, b);
return 0;
}
Reference simplifies the effect of pointer, which can be said to be very easy to use
struct Stack
{
int* a;
int size;
int capacity;
};
void StackInit(struct Stack* ps)
{}
void StackInit(struct Stack& s)
{}
int main()
{
struct Stack st;
StackInit(&st);
StackInit(st);
return 0;
}
Sometimes references simplify the use of secondary pointers
6.3 reference characteristics
🍁 References must be initialized when defined
🍁 A variable can have multiple references
🍁 Reference once an entity is referenced, other entities cannot be referenced
🍁 The reference type must be of the same type as the reference entity
double d = 12.34; int& rd = d; // There will be errors when compiling this statement, with different types
🍁 Constant references cannot enlarge permissions, and references to constant variables must also be constant references
const int a = 10; //int& ra = a; // There will be an error when compiling this statement. A is a constant const int& ra = a;//It should be
🍁 Constant reference permissions can be reduced, but not enlarged
int& b = 10; // const int& b = 10;//Reducing permissions is acceptable const int& rd = d; }
🍁 There is an implicit type conversion in c, and now there is a strange syntax. After const, you can "implicitly convert" the reference type
int c = 10; double d = 1.11; d = c; // Implicit type conversion int c = 10; double& rc = c;//err const double& rc = c;//pass
The reason is this. The understanding of the syntax layer is that during implicit type conversion, int c will generate a temporary variable of type double, and this temporary variable is constant, so add a const
6.4 reference scenario quick start
6.4.1 making parameters
For example, Swap function
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
6.4.2 return value
Pass value return, temporary copy of returned object
Pass reference return, which returns the reference of the object
🌸 Value transfer return
int Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
const int& ret = Add(1, 2);
return 0;
}
If the return value returns int by value passing method, const should be added because it is a temporary variable, a specific space and constant
🌸 Pass reference return
Deprecated return form
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int ret = Add(1, 2);
}
It seems that there is no problem. In fact, there is a problem, because the Add function is equivalent to the function stack frame, and the stack frame is destroyed. Then this space is equivalent to the ret that does not belong to the reference value. That is to say, if you want to access again at this time, although the space has not been destroyed temporarily, it has been accessed beyond the boundary, and the result is uncertain. It's like drunk driving. If you don't report an error, it doesn't mean there is no problem

Sometimes random values are output, such as
int& Add(int a, int b)
{
int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(5, 7);
cout << ret << endl;
printf("hello world\n");
cout << ret << endl;
return 0;
}
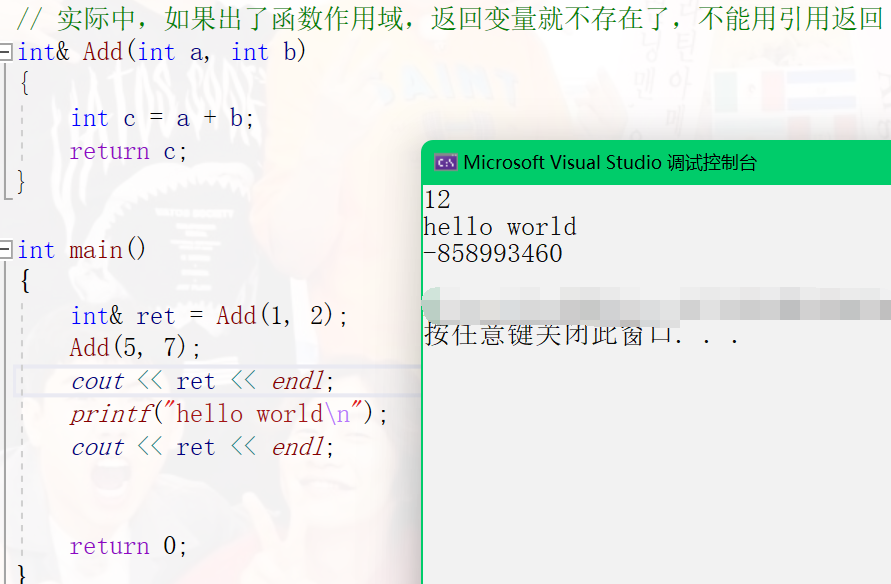
Therefore, general code cannot be returned by reference
So when can it be used? Just make the attribute static, so it won't be destroyed
int& Add(int a, int b)
{
static int c = a + b;
return c;
}
int main()
{
int& ret = Add(1, 2);
Add(5, 7);
printf("hello world\n");
cout << ret << endl;
return 0;
}
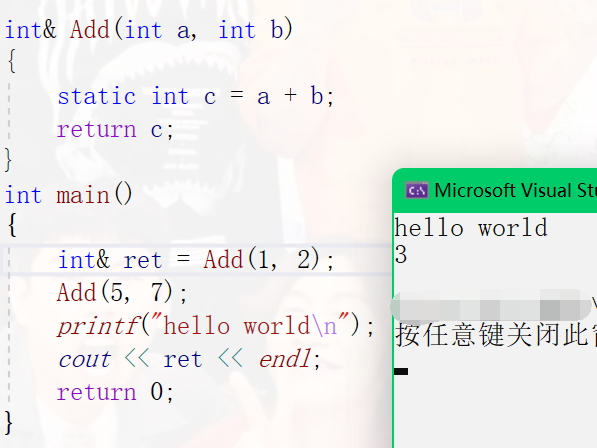
Summary:
If the scope of the function is given when the function returns, if the returned object has not been returned to the system, you can use reference return. If it has been returned
If it is returned to the system, it must be returned by value passing.
So if you want to use it, you can set the object as static attribute
6.5 comparison of value transfer and reference transfer efficiency
It's not that passing references and returning are good for nothing, but they still have advantages
Let's take a look at the case of passing references as parameters
#include <time.h>
#include<iostream>
using namespace std;
struct A{ int a[10000]; };
void TestFunc1(A a){}
void TestFunc2(A& a){}
void TestRefAndValue()
{
A aa;
// Take value as function parameter
size_t begin1 = clock();
for (size_t i = 0; i < 10000; ++i){
TestFunc1(aa);
}
size_t end1 = clock();
// Take reference as function parameter
size_t begin2 = clock();
for (size_t i = 0; i < 10000; ++i){
TestFunc2(aa);
}
size_t end2 = clock();
// Calculate the time after the two functions run respectively
cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{
TestRefAndValue();
}
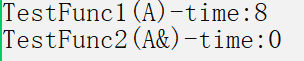
Let's look at the return value
#include <time.h>
struct A { int a[10000]; };
A a;
// Value return
A TestFunc1() { return a; }
// Reference return
A& TestFunc2() { return a; }
void TestReturnByRefOrValue()
{
// Take value as the return value type of function
size_t begin1 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc1();
size_t end1 = clock();
// Take reference as the return value type of function
size_t begin2 = clock();
for (size_t i = 0; i < 100000; ++i)
TestFunc2();
size_t end2 = clock();
// Calculate the time after the operation of two functions is completed
cout << "TestFunc1 time:" << end1 - begin1 << endl;
cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{
TestReturnByRefOrValue();
}
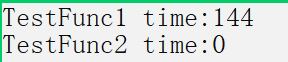
Therefore, when the parameter and return value are relatively large variables, passing reference, parameter and reference as return value can also improve efficiency. As long as the conditions are met, try to pass parameter and return value by reference to avoid some deep copies
6.6 pointer VS reference
Syntactically, a reference is an alias. There is no independent space, and it shares the same space with its reference entity.
// Grammatically, there is no new space for a int& ra = a; ra = 20; // Grammatically, a pa pointer variable is defined here, which is opened by 4 bytes to store the address of A int* pa = &a; *pa = 20;
In fact, there is space in the underlying implementation, because the reference is implemented in the form of pointer.
Compared with the assembly code of reference and pointer, the bottom layer is very similar. The only difference is that it changes an alias

6.6.1 differences between references and pointers:
🍁 Reference conceptually defines the alias of a variable, and the seed stores the address of a variable
🍁 References must be initialized when defined, and pointers are not required
🍁 After a reference references an entity during initialization, it can no longer reference other entities, and the pointer can point to any entity of the same type at any time
🍁 Cannot directly reference NULL, but has a NULL pointer
int* p = NULL; int*& rp = p; cout << rp << endl;
🍁 In sizeof, the meaning is different: the reference result is the size of the reference type, but the pointer is always the number of bytes in the address space (4 bytes in 32-bit platform)
🍁 Reference self addition means that the referenced entity increases by 1, and pointer self addition means that the pointer is offset by one type backward
🍁 There are multi-level pointers, but there are no multi-level references
🍁 The access to entities is different. The pointer needs to be explicitly dereferenced, and the reference compiler handles it by itself
🍁 References are relatively safer to use than pointers
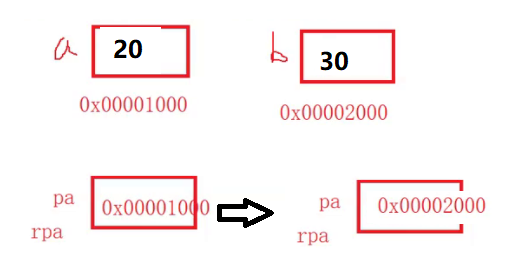
Now let's mix pointers and references to see what the following code means
int* pa = &a; *pa = 20; int b = 10; int*& rpa = pa; rpa = &b;
First, the pa pointer holds the address of a, then let rpa alias pa, and then let rpa reference the address of b. at the same time, the address of pa is also changed
7. Inline function
7.0 Intro of inline
The function decorated with inline is called inline function. During compilation, the C + + compiler will expand at the place where the inline function is called instead of opening a function stack frame. The function stack frame is a big overhead. If there is no overhead of function stack pressing, the inline function can improve the efficiency of program operation.
I still remember that C language provides macro function support to avoid stack frames for small functions, and the preprocessing stage is expanded. Since C language has been solved, why should c + + provide inline functions? (disadvantages of macro functions)
C + + recommends that small functions called frequently be defined as inline, which will be expanded at the place of call without stack frame overhead
7.1 the advantages and disadvantages of macro functions are the advantages of inline functions
😄 advantage
🛡 Enhance code reusability.
🛡 Improve performance.
😢 shortcoming
🗡 The preprocessing phase is expanded and cannot be debugged
🗡 The syntax of macros is complex and error prone
🗡 There is no type safety check
### 🌰 Write a macro function of Add
Note that it is easy to make mistakes
// #define ADD(int x, int y) return x + y // #define ADD(x, y) x+y;// Cannot have semicolon err // #define ADD(x, y) (x)+(y) //err #define ADD(x, y) ((x)+(y))
Then the disadvantage of C language macro function is the advantage of C + + inline function
What technologies do C + + have in place of macros?
- const for constant definition
- Function definitions are replaced with inline functions
7.2 getting started with inline functions
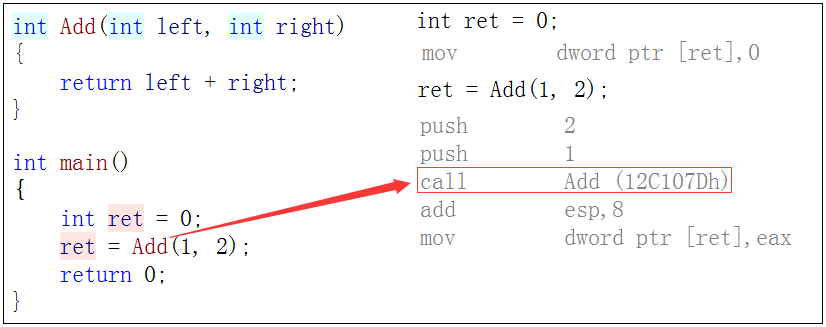
If you see a call in the assembly, you generally need to open up the function stack frame. Functions that are not inline contain a call
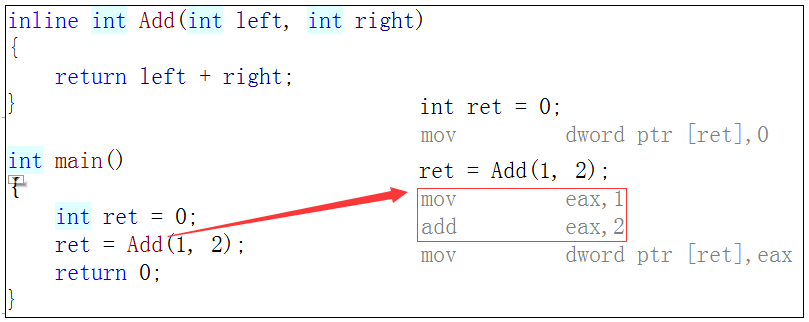
How can I see the specific assembly of inline functions? I want to change the debug version to the release version, because the debug version does not expand the inline functions for the convenience of debugging. You can see that the inline functions do not call, that is, open a function stack frame
But the following situations will still have an impact. Let's have a look

Does too many instructions mean low efficiency? No, there are too many instructions, but you don't need to open the stack frame, so it's still fast. The problem is that the inline is using space for time. Of course, the compiler also has a bottom line. Too large a function won't let you inline
7.3 features of inline functions
🍁 inline is a method of exchanging space for time, which saves the cost of calling functions. Therefore, functions with long code or circular / recursive functions are not suitable
Use as an inline function.
🍁 Inline is only a suggestion for the compiler. The compiler will automatically optimize if there is a loop / recursion in the function defined as inline
Wait, the compiler will ignore inlining when optimizing.
🍁 Inline does not recommend the separation of declaration and definition, which will lead to link errors. Because the inline is expanded, there is no function address, and the link will be expanded
can't find.
8. auto keyword
8.0 Intro of auto
In the early C/C + +, the meaning of auto is that the variable modified by auto is a local variable with automatic memory, but unfortunately it has not been used
People use it
In C++11, the standards committee gives a new meaning to auto, that is, auto is no longer a storage type indicator, but as a new type indicator to indicate the compiler. The variables declared by auto must be derived by the compiler at compile time.
When using auto to define variables, it must be initialized. In the compilation stage, the compiler needs to deduce the actual class of auto according to the initialization expression
Type. Therefore, auto is not a "type" declaration, but a "placeholder" for type declaration. The compiler will replace Auto with
The actual type of the variable.
8.1 auto quick start
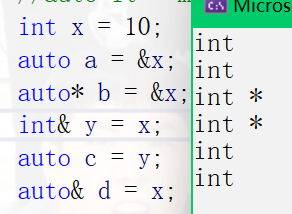
🍁 auto is used in conjunction with pointers and references
When declaring pointer type with auto, there is no difference between auto and auto *, but when declaring reference type with auto, it must be added&
int main()
{
int x = 10;
auto a = &x; // int*
auto* b = &x; // int*
int& y = x; // What is the type of y? int
auto c = y; // int
auto& d = x; // The type of d is int, but the reference that d is x is specified here
// Type of print variable
cout << typeid(x).name() << endl;
cout << typeid(y).name() << endl;
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
cout << typeid(c).name() << endl;
cout << typeid(d).name() << endl;
return 0;
}
The above auto can automatically deduce the type of declaration, which is what auto does
typeid(x).name() is used to print the type of variable
🍁 Define multiple variables on the same line
When multiple variables are declared on the same line, these variables must be of the same type, otherwise the compiler will report an error because the compiler is actually only right
The first type is derived, and then the derived type is used to define other variables.
void TestAuto()
{
auto a = 1, b = 2;
auto c = 3, d = 4.0; // This line of code will fail to compile because the initialization expression types of c and d are different
}
8.2 types that cannot be deduced by auto
🍁 auto cannot be an argument to a function
// The code here fails to compile. auto cannot be used as a formal parameter type because the compiler cannot deduce the actual type of A
void TestAuto(auto a)
{}
🍁 auto cannot be used directly to declare arrays
void TestAuto()
{
int a[] = {1,2,3};
auto b[] = {4,5,6};
}
🍁 In order to avoid confusion with auto in C++98, C++11 only retains the use of auto as a type indicator
🍁 The most common advantage of auto in practice is to use it with the new for loop provided by C++11 and lambda expression.
9 new for loop
9.1 syntax of scope for
For a set with a range, it is redundant for the programmer to explain the range of the loop, and sometimes it is easy to make mistakes. Therefore, a range based for loop is introduced in C++11. The parenthesis after the for loop is divided into two parts by the colon ":": the first part is the variable used for iteration within the range, and the second part represents the range to be iterated.
The new for loop is very similar to the foreach enhanced for loop of Java
int main()
{
for (auto& e : array)
{
e *= 2;
}
for (auto ee : array)
{
cout << ee << " ";
}
cout << endl;
return 0;
}
9.2 scope and conditions of use
🍁 The scope of the for loop iteration must be determined
For an array, it is the range of the first element and the last element in the array; For classes, methods of begin and end should be provided. Begin and end are the scope of for loop iteration.
void TestFor(int array[])//No scope, err
{//What came in has become a pointer
for(auto& e : array)
cout<< e <<endl;
}
🍁 The iterated object should realize the operations of + + and = =.
int main()
{
int array[] = { 1, 2, 3, 4, 5 };
// Scope for C++11 new syntax traversal, simpler, arrays can
// Automatic traversal, take out the elements in the array in turn and assign them to e until the end
for (auto e : array)
{
e *= 2;
}
for (auto ee : array)
{
cout << ee << " ";
}
cout << endl;
return 0;
}
Printed out is 12345 instead of 246810, indicating e *= 2;, It doesn't work because the for loop is essentially a temporary copy of the ship, so the loop changes disappear

There are the following solutions. Write the for loop for operation as a reference type
for (auto& e : array)
{
e *= 2;
}
If the use of pictures involves infringement, please contact me by private letter to delete, thank you
10. Null pointer nullptr(C++11)
10.1 nullptr quick start
In good C/C + + programming habits, when declaring a variable, it's best to give the variable an appropriate initial value, otherwise unexpected errors may occur
Errors, such as uninitialized pointers. If a pointer has no legal point, we basically initialize it in the following way:
NULL is actually a macro. In the traditional C header file (stddef.h), you can see the following code:
#ifndef NULL #ifdef __cplusplus #define NULL 0 #else #define NULL ((void *)0) #endif #endif
As you can see, NULL may be defined as a literal constant 0 or as a constant of a typeless pointer (void *). Whatever the definition, in
When using null pointers, you will inevitably encounter some trouble
NULL is considered an int, and only nullptr is considered a pointer
void f(int i)
{
cout << "f(int)" << endl;
}
void f(int* p)
{
cout << "f(int*)" << endl;
}
int main()
{
int* p1 = NULL; // int* p1 = 0;
int* p2 = nullptr;
f(0);
f(NULL);
f(nullptr);
return 0;
}
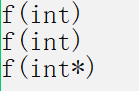
The original intention of the program is to call the pointer version of f(int *) function through f(NULL), but since NULL is defined as 0, it is contrary to the original intention of the program.
In C++98, the literal constant 0 can be either an integer number or an untyped pointer (void *) constant, but the compiler regards it as an integer constant by default. If you want to use it as a pointer, you must forcibly convert it (void *)0.
10.2 nullptr precautions
🍁 When nullptr is used to represent pointer null value, it is not necessary to include header file, because nullptr is introduced by C++11 as a new keyword.
🍁 In C++11, sizeof(nullptr) and sizeof((void*)0) occupy the same number of bytes.
🍁 In order to improve the robustness of the code, it is recommended to use nullptr in the subsequent representation of pointer null values.
Brothers are clean and sanitary