The implementation and explanation of PointPillars' paper and training code have been analyzed in detail in the previous article. Please refer to the previous blog: PointPillars paper analysis and OpenPCDet code analysis_ Nnnathan blog - CSDN blog.
This blog will analyze the reasoning code of PointPillars model in OpenPCDet in detail and test the effect of reasoning.
Readers can download OpenPCDet and read and understand it according to the article.
Due to my lack of knowledge, there will inevitably be deficiencies in the analysis. You are welcome to correct and discuss. If you have good suggestions or opinions, you can leave a message in the comment area. Thank you!
PointPillars' paper address is:
https://arxiv.org/pdf/1812.05784.pdf
Parsing reference code:
https://github.com/open-mmlab/OpenPCDet
Detailed comments: the code has been placed in my github warehouse:
GitHub - nathansong / openpcddet Annotated: code analysis of openpcddet model
1, PointPillars network structure and data preprocessing
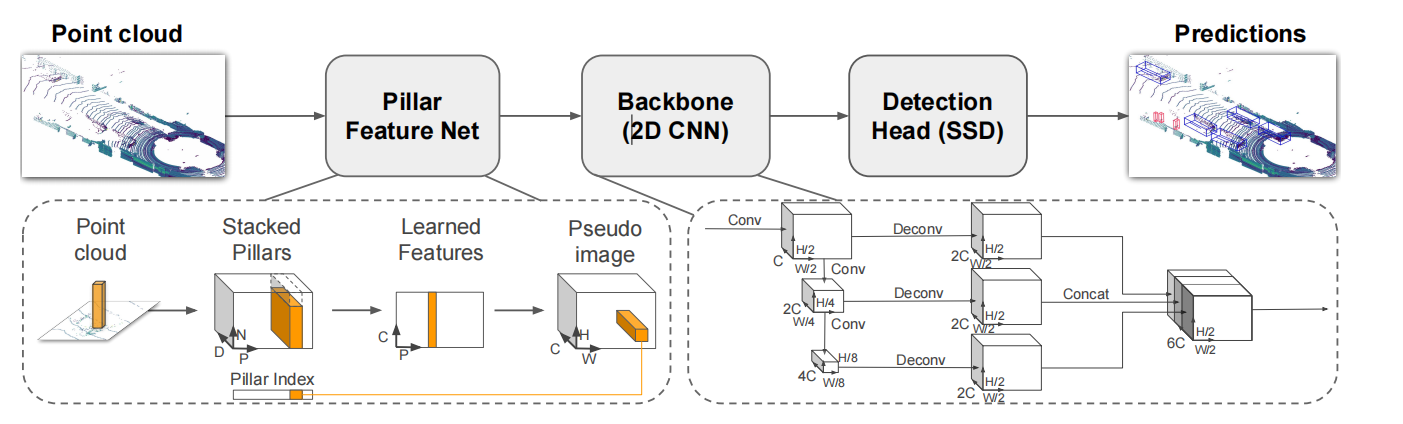
The network structure has been introduced in detail in the previous training structure. Here, we will skip this part and directly connect it to the parsing and reasoning implementation in the previous detection header implementation code.
Before reasoning, it is necessary to preprocess the original point cloud data; The point cloud outside the specified range needs to be removed, and VoxelGeneratorWrapper needs to be used to generate a pixel from the point cloud. See the training blog for details.
2, Network reasoning results
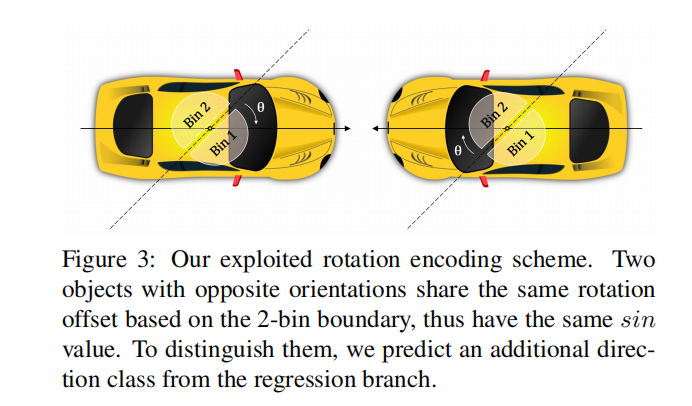
In the final results of PointPillars, we get three results: each anchor on the characteristic graph and each anchor predicts seven regression parameters, one category and one direction classification. Where 7 regression parameters (x, y, z, w, l, h, θ); x. Y and z predict the offset value from the target center point to the upper left vertex of the anchor, and w, l and H predict the adjustment coefficient based on the length, width and height of the anchor, θ The rotation angle and direction category of the box are predicted, and the orientation of the box is predicted. The relationship between the two directions is as follows (the deviation from the x-axis in the radar coordinate system is 45 degrees. The reason can be seen in this issue: https://github.com/open-mmlab/OpenPCDet/issues/80).
The following figure is from FCOS3D: https://arxiv.org/pdf/2104.10956.pdf
The code is in pcdet / Models / deny_ heads/anchor_ head_ single. py
import numpy as np
import torch.nn as nn
from .anchor_head_template import AnchorHeadTemplate
class AnchorHeadSingle(AnchorHeadTemplate):
"""
Args:
model_cfg: AnchorHeadSingle Configuration of
input_channels: 384 Number of input channels
num_class: 3
class_names: ['Car','Pedestrian','Cyclist']
grid_size: (432, 496, 1)
point_cloud_range: (0, -39.68, -3, 69.12, 39.68, 1)
predict_boxes_when_training: False
"""
def __init__(self, model_cfg, input_channels, num_class, class_names, grid_size, point_cloud_range,
predict_boxes_when_training=True, **kwargs):
super().__init__(
model_cfg=model_cfg, num_class=num_class, class_names=class_names, grid_size=grid_size,
point_cloud_range=point_cloud_range,
predict_boxes_when_training=predict_boxes_when_training
)
# Each point has a priori box of 3 scales, and each priori box has two directions (0 degrees, 90 degrees) num_anchors_per_location:[2, 2, 2]
self.num_anchors_per_location = sum(self.num_anchors_per_location) # sum([2, 2, 2])
# Conv2d(512,18,kernel_size=(1,1),stride=(1,1))
self.conv_cls = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.num_class,
kernel_size=1
)
# Conv2d(512,42,kernel_size=(1,1),stride=(1,1))
self.conv_box = nn.Conv2d(
input_channels, self.num_anchors_per_location * self.box_coder.code_size,
kernel_size=1
)
# If there is directional loss, add directional convolution layer conv2d (512,12, kernel_size = (1,1), stripe = (1,1))
if self.model_cfg.get('USE_DIRECTION_CLASSIFIER', None) is not None:
self.conv_dir_cls = nn.Conv2d(
input_channels,
self.num_anchors_per_location * self.model_cfg.NUM_DIR_BINS,
kernel_size=1
)
else:
self.conv_dir_cls = None
self.init_weights()
# Initialization parameters
def init_weights(self):
pi = 0.01
# Initialize classification convolution offset
nn.init.constant_(self.conv_cls.bias, -np.log((1 - pi) / pi))
# Initialize classification convolution weight
nn.init.normal_(self.conv_box.weight, mean=0, std=0.001)
def forward(self, data_dict):
# Extract the information processed by backbone from the dictionary
# spatial_ features_ Size, 216, 2D
spatial_features_2d = data_dict['spatial_features_2d']
# Category prediction of 6 a priori boxes above each coordinate point -- > (batch_size, 18, 200, 176)
cls_preds = self.conv_cls(spatial_features_2d)
# Parameter prediction of 6 a priori boxes above each coordinate point -- > (batch_size, 42, 200, 176), in which each a priori box needs to predict 7 parameters, namely (x, y, z, w, l, h, θ)
box_preds = self.conv_box(spatial_features_2d)
# Dimension adjustment: place the category in the last dimension [n, h, W, C] -- > (batch_size, 200, 176, 18)
cls_preds = cls_preds.permute(0, 2, 3, 1).contiguous()
# Dimension adjustment: place the a priori box adjustment parameters in the last dimension [n, h, W, C] -- > (batch_size, 200, 176, 42)
box_preds = box_preds.permute(0, 2, 3, 1).contiguous()
# Put the category and a priori box adjustment prediction results into the forward propagation dictionary
self.forward_ret_dict['cls_preds'] = cls_preds
self.forward_ret_dict['box_preds'] = box_preds
# Direction classification prediction
if self.conv_dir_cls is not None:
# # Each a priori box is predicted to be one of two directions -- > (batch_size, 12, 200, 176)
dir_cls_preds = self.conv_dir_cls(spatial_features_2d)
# Put the category and a priori box direction prediction results into the last dimension [n, h, W, C] -- > (batch_size, 248, 216, 12)
dir_cls_preds = dir_cls_preds.permute(0, 2, 3, 1).contiguous()
# Put the direction prediction result into the forward propagation dictionary
self.forward_ret_dict['dir_cls_preds'] = dir_cls_preds
else:
dir_cls_preds = None
"""
If it is in training mode, each a priori box needs to be assigned GT To calculate loss
"""
if self.training:
# targets_dict = {
# 'box_cls_labels': cls_labels, # (4,211200)
# 'box_reg_targets': bbox_targets, # (4,211200, 7)
# 'reg_weights': reg_weights # (4,211200)
# }
targets_dict = self.assign_targets(
gt_boxes=data_dict['gt_boxes'] # (4,39,8)
)
# Put the GT allocation result into the forward propagation dictionary
self.forward_ret_dict.update(targets_dict)
# If it is not the training mode, the prediction for box is generated directly
if not self.training or self.predict_boxes_when_training:
# Decode and generate the final result according to the prediction result
batch_cls_preds, batch_box_preds = self.generate_predicted_boxes(
batch_size=data_dict['batch_size'],
cls_preds=cls_preds, box_preds=box_preds, dir_cls_preds=dir_cls_preds
)
data_dict['batch_cls_preds'] = batch_cls_preds # (1, 211200, 3) 70400*3=211200
data_dict['batch_box_preds'] = batch_box_preds # (1, 211200, 7)
data_dict['cls_preds_normalized'] = False
return data_dictAfter head prediction, three tensors can be obtained, which are:
Category prediction of each anchor: (batch_size, 248, 216, 18)
Prediction of 7 regression parameters of each anchor: (batch_size, 248, 216, 42)
Direction classification of each anchor: (batch_size, 248, 216, 12)
Among them, 18 can be regarded as 6 anchors, and each anchor predicts 3 categories;
Among them, 42 can be regarded as 6 anchors, and each anchor predicts 7 regression parameters;
Among them, 12 can be regarded as 6 anchors, and each anchor predicts 2 directions;
Note: batch is the default for reasoning_ Size is 1.
Next, generate the prediction results:
Code: pcdet / Models / deny_ heads/anchor_ head_ template. py
def generate_predicted_boxes(self, batch_size, cls_preds, box_preds, dir_cls_preds=None):
"""
Args:
batch_size:
cls_preds: (N, H, W, C1)
box_preds: (N, H, W, C2)
dir_cls_preds: (N, H, W, C3)
Returns:
batch_cls_preds: (B, num_boxes, num_classes)
batch_box_preds: (B, num_boxes, 7+C)
"""
if isinstance(self.anchors, list):
# Whether to use long forecast. No by default
if self.use_multihead:
anchors = torch.cat([anchor.permute(3, 4, 0, 1, 2, 5).contiguous().view(-1, anchor.shape[-1])
for anchor in self.anchors], dim=0)
else:
"""
Each category anchor Generation of:
[(Z, Y, X, anchor scale, This scale anchor direction, 7 Regression parameters)
(Z, Y, X, anchor scale, This scale anchor direction, 7 Regression parameters)
(Z, Y, X, anchor scale, This scale anchor direction, 7 Regression parameters)]
Splice in the penultimate dimension
anchors dimension (Z, Y, X, 3 individual anchor scale, Two directions per scale, 7)
(1, 248, 216, 3, 2, 7)
"""
anchors = torch.cat(self.anchors, dim=-3)
else:
anchors = self.anchors
# Calculate the total number of anchors Z * y * x * num_ of_ anchor_ scale*anchor_ rot
num_anchors = anchors.view(-1, anchors.shape[-1]).shape[0]
# (batch_size, Z*Y*X*num_of_anchor_scale*anchor_rot, 7)
batch_anchors = anchors.view(1, -1, anchors.shape[-1]).repeat(batch_size, 1, 1)
# The prediction results are flatten as one-dimensional
# (batch_size, Z*Y*X*num_of_anchor_scale*anchor_rot, 3)
batch_cls_preds = cls_preds.view(batch_size, num_anchors, -1).float() \
if not isinstance(cls_preds,
list) else cls_preds
# (batch_size, Z*Y*X*num_of_anchor_scale*anchor_rot, 7)
batch_box_preds = box_preds.view(batch_size, num_anchors, -1) if not isinstance(box_preds, list) \
else torch.cat(box_preds, dim=1).view(batch_size, num_anchors, -1)
# Decode the seven predicted box parameters
batch_box_preds = self.box_coder.decode_torch(batch_box_preds, batch_anchors)
# Direction prediction of each anchor
if dir_cls_preds is not None:
# 0.78539 direction offset
dir_offset = self.model_cfg.DIR_OFFSET
# 0
dir_limit_offset = self.model_cfg.DIR_LIMIT_OFFSET # 0
# Set the direction prediction result flat to one-dimensional (batch_size, Z*Y*X*num_of_anchor_scale*anchor_rot, 2)
dir_cls_preds = dir_cls_preds.view(batch_size, num_anchors, -1) if not isinstance(dir_cls_preds, list) \
else torch.cat(dir_cls_preds, dim=1).view(batch_size, num_anchors, -1) # (1, 321408, 2)
# (batch_size, Z*Y*X*num_of_anchor_scale*anchor_rot)
# Take out the direction classification of all anchor s: forward and reverse
dir_labels = torch.max(dir_cls_preds, dim=-1)[1]
# pi
period = (2 * np.pi / self.model_cfg.NUM_DIR_BINS)
# Set the angle between 0 and pi. In OpenPCDet, the coordinates use the unified standard coordinates, x forward, y left and z up
# Referring to the reasons for training, now rotate the angle counterclockwise along the x axis by 45 degrees to get dir_rot
dir_rot = common_utils.limit_period(
batch_box_preds[..., 6] - dir_offset, dir_limit_offset, period
)
"""
Rotate the angle back to the lidar coordinate system, so you need to add back the 45 degrees you subtracted before,
If dir_labels If it is 1, it indicates that the direction is 180 degrees, so it is necessary to add 180 degrees to the predicted angle information,
Otherwise, the prediction angle is the obtained angle
"""
batch_box_preds[..., 6] = dir_rot + dir_offset + period * dir_labels.to(batch_box_preds.dtype)
# This item is not available in PointPillars
if isinstance(self.box_coder, box_coder_utils.PreviousResidualDecoder):
batch_box_preds[..., 6] = common_utils.limit_period(
-(batch_box_preds[..., 6] + np.pi / 2), offset=0.5, period=np.pi * 2
)
return batch_cls_preds, batch_box_predsThe box decoding operation in the above code, that is, the inverse operation of coding:
Code: pcdet/utils/box_coder_utils.py
def decode_torch(self, box_encodings, anchors):
"""
Args:
box_encodings: (B, N, 7 + C) or (N, 7 + C) [x, y, z, dx, dy, dz, heading or *[cos, sin], ...]
anchors: (B, N, 7 + C) or (N, 7 + C) [x, y, z, dx, dy, dz, heading, ...]
Returns:
"""
# This means torch The second parameter of split is torch split(tensor, split_size, dim=) split_ Size is the size of each piece after segmentation, not the number of pieces!, Redundant parameters are received with * cags
xa, ya, za, dxa, dya, dza, ra, *cas = torch.split(anchors, 1, dim=-1)
# box PointPillar after split coding is False
if not self.encode_angle_by_sincos:
xt, yt, zt, dxt, dyt, dzt, rt, *cts = torch.split(box_encodings, 1, dim=-1)
else:
xt, yt, zt, dxt, dyt, dzt, cost, sint, *cts = torch.split(box_encodings, 1, dim=-1)
# Calculate the length of anchor diagonal
diagonal = torch.sqrt(dxa ** 2 + dya ** 2) # (B, N, 1)-->(1, 321408, 1)
# Operation of anchor and GT code in loss calculation: g represents GT and a represents anchor
# ∆x = (x^gt − xa^da)/diagonal --> x^gt = ∆x * diagonal + x^da
# The same below
xg = xt * diagonal + xa
yg = yt * diagonal + ya
zg = zt * dza + za
# ∆ L = inverse operation of log (L ^ GT / L ^ a -- > L ^ GT = exp (∆ l) * l^a
# The same below
dxg = torch.exp(dxt) * dxa
dyg = torch.exp(dyt) * dya
dzg = torch.exp(dzt) * dza
# If the angle is cos and sin coding, the new decoding method PointPillar is False
if self.encode_angle_by_sincos:
rg_cos = cost + torch.cos(ra)
rg_sin = sint + torch.sin(ra)
rg = torch.atan2(rg_sin, rg_cos)
else:
# rts = [rg - ra] inverse of angle
rg = rt + ra
# PointPillar has no such item
cgs = [t + a for t, a in zip(cts, cas)]
return torch.cat([xg, yg, zg, dxg, dyg, dzg, rg, *cgs], dim=-1)3, Reasoning result post-processing
Here, the nms operation without category is carried out for all the prediction results, and the final prediction results are obtained.
Code: pcdet/models/detectors/detector3d_template.py
def post_processing(self, batch_dict):
"""
Args:
batch_dict:
batch_size:
batch_cls_preds: (B, num_boxes, num_classes | 1) or (N1+N2+..., num_classes | 1)
or [(B, num_boxes, num_class1), (B, num_boxes, num_class2) ...]
multihead_label_mapping: [(num_class1), (num_class2), ...]
batch_box_preds: (B, num_boxes, 7+C) or (N1+N2+..., 7+C)
cls_preds_normalized: indicate whether batch_cls_preds is normalized
batch_index: optional (N1+N2+...)
has_class_labels: True/False
roi_labels: (B, num_rois) 1 .. num_classes
batch_pred_labels: (B, num_boxes, 1)
Returns:
"""
# post_process_cfg post-processing parameters, including nms type, threshold, equipment used, results retained at most after nms, confidence of output, etc
post_process_cfg = self.model_cfg.POST_PROCESSING
# Reasoning defaults to 1
batch_size = batch_dict['batch_size']
# Keep the dictionary for calculating recall
recall_dict = {}
# The prediction results are stored here
pred_dicts = []
# Frame by frame processing
for index in range(batch_size):
if batch_dict.get('batch_index', None) is not None:
assert batch_dict['batch_box_preds'].shape.__len__() == 2
batch_mask = (batch_dict['batch_index'] == index)
else:
assert batch_dict['batch_box_preds'].shape.__len__() == 3
# Which frame is currently being processed
batch_mask = index
# box_preds shape (number of all anchor s, 7)
box_preds = batch_dict['batch_box_preds'][batch_mask]
# After copying, it is used for recall calculation
src_box_preds = box_preds
if not isinstance(batch_dict['batch_cls_preds'], list):
# (number of all anchor s, 3)
cls_preds = batch_dict['batch_cls_preds'][batch_mask]
# ditto
src_cls_preds = cls_preds
assert cls_preds.shape[1] in [1, self.num_class]
if not batch_dict['cls_preds_normalized']:
# The BCE used in the loss function calculation, so the sigmoid activation function is used here to obtain the category probability
cls_preds = torch.sigmoid(cls_preds)
else:
cls_preds = [x[batch_mask] for x in batch_dict['batch_cls_preds']]
src_cls_preds = cls_preds
if not batch_dict['cls_preds_normalized']:
cls_preds = [torch.sigmoid(x) for x in cls_preds]
# Whether to use multi category NMS calculation, No.
if post_process_cfg.NMS_CONFIG.MULTI_CLASSES_NMS:
if not isinstance(cls_preds, list):
cls_preds = [cls_preds]
multihead_label_mapping = [torch.arange(1, self.num_class, device=cls_preds[0].device)]
else:
multihead_label_mapping = batch_dict['multihead_label_mapping']
cur_start_idx = 0
pred_scores, pred_labels, pred_boxes = [], [], []
for cur_cls_preds, cur_label_mapping in zip(cls_preds, multihead_label_mapping):
assert cur_cls_preds.shape[1] == len(cur_label_mapping)
cur_box_preds = box_preds[cur_start_idx: cur_start_idx + cur_cls_preds.shape[0]]
cur_pred_scores, cur_pred_labels, cur_pred_boxes = model_nms_utils.multi_classes_nms(
cls_scores=cur_cls_preds, box_preds=cur_box_preds,
nms_config=post_process_cfg.NMS_CONFIG,
score_thresh=post_process_cfg.SCORE_THRESH
)
cur_pred_labels = cur_label_mapping[cur_pred_labels]
pred_scores.append(cur_pred_scores)
pred_labels.append(cur_pred_labels)
pred_boxes.append(cur_pred_boxes)
cur_start_idx += cur_cls_preds.shape[0]
final_scores = torch.cat(pred_scores, dim=0)
final_labels = torch.cat(pred_labels, dim=0)
final_boxes = torch.cat(pred_boxes, dim=0)
else:
# Get the maximum probability of category prediction and the corresponding index value
cls_preds, label_preds = torch.max(cls_preds, dim=-1)
if batch_dict.get('has_class_labels', False):
label_key = 'roi_labels' if 'roi_labels' in batch_dict else 'batch_pred_labels'
label_preds = batch_dict[label_key][index]
else:
# Category forecast plus 1
label_preds = label_preds + 1
# Classless NMS operation
# selected: returns the anchor index left behind
# selected_scores: returns the confidence score of the anchor left behind
selected, selected_scores = model_nms_utils.class_agnostic_nms(
# Category prediction probability and anchor regression parameters of each anchor
box_scores=cls_preds, box_preds=box_preds,
nms_config=post_process_cfg.NMS_CONFIG,
score_thresh=post_process_cfg.SCORE_THRESH
)
# None
if post_process_cfg.OUTPUT_RAW_SCORE:
max_cls_preds, _ = torch.max(src_cls_preds, dim=-1)
selected_scores = max_cls_preds[selected]
# Get the score of the final category prediction
final_scores = selected_scores
# Get the final category prediction result according to the selected
final_labels = label_preds[selected]
# The final box regression result is obtained according to the selected
final_boxes = box_preds[selected]
# If there is no GT label in batch_ In dict, the recall value will not be calculated
recall_dict = self.generate_recall_record(
box_preds=final_boxes if 'rois' not in batch_dict else src_box_preds,
recall_dict=recall_dict, batch_index=index, data_dict=batch_dict,
thresh_list=post_process_cfg.RECALL_THRESH_LIST
)
# Generate the result Dictionary of the final forecast
record_dict = {
'pred_boxes': final_boxes,
'pred_scores': final_scores,
'pred_labels': final_labels
}
pred_dicts.append(record_dict)
return pred_dicts, recall_dictNo category nms operation
Code: pcdet/models/model_utils/model_nms_utils.py
def class_agnostic_nms(box_scores, box_preds, nms_config, score_thresh=None):
# 1. Firstly, according to the confidence threshold, the filtering unit filters out most box es with low confidence to speed up the subsequent nms operation
src_box_scores = box_scores
if score_thresh is not None:
# The prediction probability of the obtained category is greater than score_ mask of thresh
scores_mask = (box_scores >= score_thresh)
# According to the mask, which anchor categories are predicted to be greater than the score_ Thresh -- > anchor category
box_scores = box_scores[scores_mask]
# According to the mask, which anchor categories are predicted to be greater than the score_ Seven parameters of thresh -- > anchor regression
box_preds = box_preds[scores_mask]
# Initialize the empty list to store the anchor retained after nms
selected = []
# If the category prediction of anchor is greater than score_ nms is performed only if thresh is used; otherwise, null is returned
if box_scores.shape[0] > 0:
# Here, only the maximum K anchor confidence levels are reserved for nms operation,
# k is the minimum value of min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0])
box_scores_nms, indices = torch.topk(box_scores, k=min(nms_config.NMS_PRE_MAXSIZE, box_scores.shape[0]))
# box_scores_nms only gets the update result of the category;
# Here, update the prediction results of boxes and update the prediction results of boxes according to the results re selected by tokK and sorted from large to small
boxes_for_nms = box_preds[indices]
# Call iou3d_ nms_ NMS of utils_ The GPU function performs NMS,
# Returns the index of the reserved box, selected_scores = None
# Find the box index value according to the returned index
keep_idx, selected_scores = getattr(iou3d_nms_utils, nms_config.NMS_TYPE)(
boxes_for_nms[:, 0:7], box_scores_nms, nms_config.NMS_THRESH, **nms_config
)
selected = indices[keep_idx[:nms_config.NMS_POST_MAXSIZE]]
if score_thresh is not None:
# If there is a confidence threshold, scores_mask is box_scores in SRC_ box_ The index in scores is the original index
original_idxs = scores_mask.nonzero().view(-1)
# Box represented by selected_ The selected index of scores. After this index,
# Selected indicates src_box_scores the selected box index
selected = original_idxs[selected]
return selected, src_box_scores[selected]nms_gpu
Code: pcdet/ops/iou3d_nms/iou3d_nms_utils.py
def nms_gpu(boxes, scores, thresh, pre_maxsize=None, **kwargs):
"""
:param boxes: Screened anchor Seven regression prediction results(N, 7) [x, y, z, dx, dy, dz, heading]
:param scores: Screened anchor Category of, and boxes One to one correspondence(N)
:param thresh:
:return:
"""
assert boxes.shape[1] == 7
# Sort the scores in descending order (from large to small) and take out the corresponding index
# dim=0 sort by column, dim=1 sort by row, default dim=1
# Because the incoming scores have been sorted before, the order is [0, 1, 2, 3,...]
order = scores.sort(0, descending=True)[1]
# If there is the maximum number of boxes before NMS (4096), take out the first 4096 box indexes
if pre_maxsize is not None:
order = order[:pre_maxsize]
# Take out the box before NMS. It has been ordered before, and there is no change here
boxes = boxes[order].contiguous()
# Construct a boxes Vector PPP of size dimension
keep = torch.LongTensor(boxes.size(0))
# Call cuda function for acceleration
# keep: the subscript of the record retention target box
# num_out: returns the number of reserved
num_out = iou3d_nms_cuda.nms_gpu(boxes, keep, thresh)
# After iou3d_ nms_ After CUDA, the reason is to take the first num_ The reason for the number of out is that the maximum length of keep initialization is 4096
return order[keep[:num_out].cuda()].contiguous(), None4, Visualization
Visual code running:
1. Weight file: https://drive.google.com/file/d/1wMxWTpU1qUoY3DsCH31WJmvJxcjFXKlm/view https://drive.google.com/file/d/1wMxWTpU1qUoY3DsCH31WJmvJxcjFXKlm/view
https://drive.google.com/file/d/1wMxWTpU1qUoY3DsCH31WJmvJxcjFXKlm/view
2. kitti dataset: The KITTI Vision Benchmark Suitehttp://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d
The code is in: Tools / demo py
import argparse
import glob
from pathlib import Path
try:
import open3d
from visual_utils import open3d_vis_utils as V
OPEN3D_FLAG = True
except:
import mayavi.mlab as mlab
from visual_utils import visualize_utils as V
OPEN3D_FLAG = False
import numpy as np
import torch
from pcdet.config import cfg, cfg_from_yaml_file
from pcdet.datasets import DatasetTemplate
from pcdet.models import build_network, load_data_to_gpu
from pcdet.utils import common_utils
class DemoDataset(DatasetTemplate):
def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None, ext='.bin'):
"""
Args:
root_path:
dataset_cfg:
class_names:
training:
logger:
"""
super().__init__(
dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger
)
self.root_path = root_path
self.ext = ext
data_file_list = glob.glob(str(root_path / f'*{self.ext}')) if self.root_path.is_dir() else [self.root_path]
data_file_list.sort()
self.sample_file_list = data_file_list
def __len__(self):
return len(self.sample_file_list)
def __getitem__(self, index):
if self.ext == '.bin':
points = np.fromfile(self.sample_file_list[index], dtype=np.float32).reshape(-1, 4)
elif self.ext == '.npy':
points = np.load(self.sample_file_list[index])
else:
raise NotImplementedError
input_dict = {
'points': points,
'frame_id': index,
}
data_dict = self.prepare_data(data_dict=input_dict)
return data_dict
def parse_config():
parser = argparse.ArgumentParser(description='arg parser')
parser.add_argument('--cfg_file', type=str, default='cfgs/kitti_models/pointpillar.yaml',
help='specify the config for demo')
parser.add_argument('--data_path', type=str, default='/home/nathan/OpenPCDet/data/kitti/training/velodyne',
help='specify the point cloud data file or directory')
parser.add_argument('--ckpt', type=str,
default="/home/nathan/OpenPCDet/output/kitti_models/pointpillar/default/ckpt/checkpoint_epoch_79.pth", help='specify the pretrained model')
parser.add_argument('--ext', type=str, default='.bin', help='specify the extension of your point cloud data file')
args = parser.parse_args()
cfg_from_yaml_file(args.cfg_file, cfg)
return args, cfg
def main():
args, cfg = parse_config()
logger = common_utils.create_logger()
logger.info('-----------------Quick Demo of OpenPCDet-------------------------')
demo_dataset = DemoDataset(
dataset_cfg=cfg.DATA_CONFIG, class_names=cfg.CLASS_NAMES, training=False,
root_path=Path(args.data_path), ext=args.ext, logger=logger
)
logger.info(f'Total number of samples: \t{len(demo_dataset)}')
model = build_network(model_cfg=cfg.MODEL, num_class=len(cfg.CLASS_NAMES), dataset=demo_dataset)
model.load_params_from_file(filename=args.ckpt, logger=logger, to_cpu=True)
model.cuda()
model.eval()
with torch.no_grad():
for idx, data_dict in enumerate(demo_dataset):
logger.info(f'Visualized sample index: \t{idx + 1}')
data_dict = demo_dataset.collate_batch([data_dict])
load_data_to_gpu(data_dict)
pred_dicts, _ = model.forward(data_dict)
V.draw_scenes(
points=data_dict['points'][:, 1:], ref_boxes=pred_dicts[0]['pred_boxes'],
ref_scores=pred_dicts[0]['pred_scores'], ref_labels=pred_dicts[0]['pred_labels']
)
if not OPEN3D_FLAG:
mlab.show(stop=True)
logger.info('Demo done.')
if __name__ == '__main__':
main()
Result 1:
Color camera 2:

Point cloud detection results:

Result 2
Color camera 2


References:
1,https://github.com/open-mmlab/OpenPCDet/
2,https://github.com/jjw-DL/OpenPCDet-Noted
3,Coordinate conversion using KITTI data set - Zhihu
4,[3D target detection] PointPillars paper and code analysis - Zhihu
5,[3D target detection] SECOND algorithm analysis - Zhihu
6,https://arxiv.org/abs/1812.05784
7,Sensors | Free Full-Text | SECOND: Sparsely Embedded Convolutional Detection
8,https://arxiv.org/abs/1711.06396
9,https://arxiv.org/abs/1612.00593
12,The KITTI Vision Benchmark Suite
13,kitti dataset -- parameters_ Blog of cuichuanchen 3307 - CSDN blog_ kitti