function flow
ExecScan
ExecScanFetch
IndexNext[Top level loop function]
[1]index_beginscan: (scandesc = index_beginscan generate scandesc (yes)
index_beginscan_internal[getr]
btbeginscan: initialization IndexScanDesc and BTScanOpaque
IndexScanDesc scan = ...
BTScanOpaque so = ...
scan->opaque = so
return scan
[2]index_rescan
btrescan
[3]index_getnext(scandesc, direction)
index_getnext_tid : Start index traversal and get a qualified index ctid(found = ...->amgettuple(scan, direction)
Actual implementation btgettuple return true Indicates that a qualified was found ctid)
btgettuple : call_bt_first Get the first qualified one and call it again_bt_next Qualified after sequential scanning
_bt_first[setr]:[[key analysis]
index_fetch_heap
[3]index_getnext(scandesc, direction)
index_getnext_tid : Start index traversal and get a qualified index ctid(found = ...->amgettuple(scan, direction)
Actual implementation btgettuple return true Indicates that a qualified was found ctid)
btgettuple : call_bt_first Get the first qualified one and call it again_bt_next Qualified after sequential scanning
_bt_next[setr]:[[key analysis]
_bt_steppage
_bt_readnextpage
index_endscan
2 point check case
Take the split index in the figure as an example. It is an index with level=2, with branch nodes and leaf nodes.
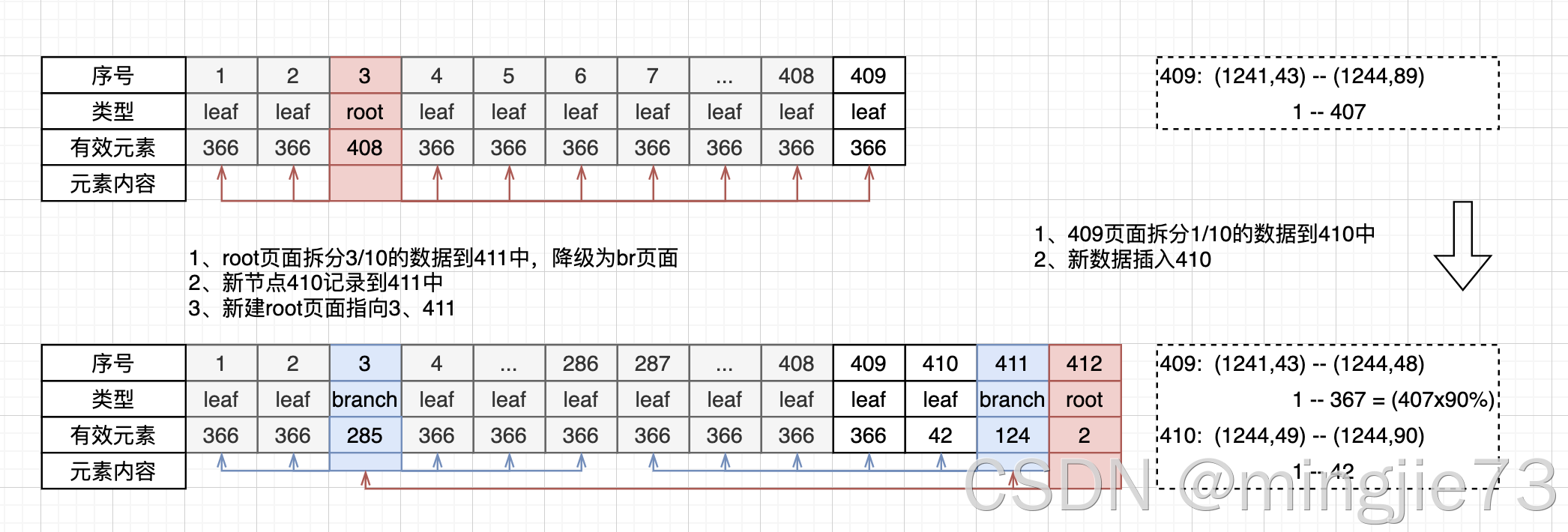
data
postgres=# select * from t8 limit 10; id | info ----+---------------------------------- 1 | 0dc60cfa723e1b809c45bdb31dfc698e 2 | 99863eeb157c1fc246d4109c469cf2d6 3 | 82a08a276210c48d8216f09e207f8f9c 4 | cb8f3c118a48c13e9be54585ca804b9f 5 | 4dcbfbf43c397b61076d3b638d7ae4f2 6 | 396881e5fc07b4156bfe31480a1adf8f 7 | 9c95a4f04931f4cae8ed6e451b9f12f2 8 | 90571ab1bcb3b22ccb6e03aadee103de 9 | 9ac75d7b5342b0021294779f3c4e8028 10 | 6e61f764b610594004651f188dcc78a0
Let's start to query a piece of data in leaf page 4-6:
select * from bt_page_items('t8_pkey', 4);
itemoffset | ctid | itemlen | nulls | vars | data
------------+---------+---------+-------+------+-------------------------
1 | (9,19) | 16 | f | f | 4b 04 00 00 00 00 00 00
2 | (6,13) | 16 | f | f | dd 02 00 00 00 00 00 00
3 | (6,14) | 16 | f | f | de 02 00 00 00 00 00 00
4 | (6,15) | 16 | f | f | df 02 00 00 00 00 00 00
...
select * from bt_page_items('t8_pkey', 6);
itemoffset | ctid | itemlen | nulls | vars | data
------------+----------+---------+-------+------+-------------------------
1 | (15,31) | 16 | f | f | 27 07 00 00 00 00 00 00
2 | (12,25) | 16 | f | f | b9 05 00 00 00 00 00 00
3 | (12,26) | 16 | f | f | ba 05 00 00 00 00 00 00
4 | (12,27) | 16 | f | f | bb 05 00 00 00 00 00 00
5 | (12,28) | 16 | f | f | bc 05 00 00 00 00 00 00
6 | (12,29) | 16 | f | f | bd 05 00 00 00 00 00 00
7 | (12,30) | 16 | f | f | be 05 00 00 00 00 00 00
8 | (12,31) | 16 | f | f | bf 05 00 00 00 00 00 00
9 | (12,32) | 16 | f | f | c0 05 00 00 00 00 00 00
10 | (12,33) | 16 | f | f | c1 05 00 00 00 00 00 00
...
postgres=# select * from t8 where ctid='(6,15)';
id | info
-----+----------------------------------
735 | 9a0a17271e0f8331f6d18ac8a0d99992
postgres=# select * from t8 where ctid='(12,27)';
id | info
------+----------------------------------
1467 | b0994a3ab67d39f0a651ca0e34cf8c52
Let's analyze the query process
select * from t8 where id>735 and id<1467 and id>500 and id<2000; id | info ------+---------------------------------- 736 | 193a511bacc34d12956b3c74cdcc18e7 737 | f64a6019fa7ef376f750c22881e0e75e 738 | 35837c259964bcef7ebf50f11f30ccda 739 | 8a66aea4f98f6cff1134b86d8b580925 740 | 72e70c6f57e80cf74dd92699c4bd9940 ... 1462 | 62fa0351c94047c3d5ed64149aafe50a 1463 | 1abed4413570355d624762db49d88541 1464 | 2c8b8e624e15b4147110480311b6b5ae 1465 | 0ea46790a9180bd0254f673a8cb90275 1466 | 86e2ad07cbb0b4fca0cadd234387f52f
2.1 index_getnext_tid
Use the amgettuple function to get the ctid and index the scan entry.
- Found: return ctid
- Not found: NULL returned for lock release
ItemPointer
index_getnext_tid(IndexScanDesc scan, ScanDirection direction)
{
bool found;
...
found = scan->indexRelation->rd_amroutine->amgettuple(scan, direction);
...
/* If we're out of index entries, we're done */
if (!found)
{
/* ... but first, release any held pin on a heap page */
if (BufferIsValid(scan->xs_cbuf))
{
ReleaseBuffer(scan->xs_cbuf);
scan->xs_cbuf = InvalidBuffer;
}
return NULL;
}
...
return &scan->xs_ctup.t_self;
}
2.2 btgettuple
- Use_ bt_first, get the first qualified position and record it to so - > currpos
- Continue the cycle_ bt_next get the qualified position in the back
bool
btgettuple(IndexScanDesc scan, ScanDirection dir)
{
BTScanOpaque so = (BTScanOpaque) scan->opaque;
bool res;
...
do
{
if (!BTScanPosIsValid(so->currPos))
res = _bt_first(scan, dir);
else
{
....
res = _bt_next(scan, dir);
}
/* If we have a tuple, return it ... */
if (res)
break;
/* ... otherwise see if we have more array keys to deal with */
} while (so->numArrayKeys && _bt_advance_array_keys(scan, dir));
return res;
}
2.3 _bt_first
The function is very long, and the intermediate segment analysis:
/* * _bt_first() -- Find the first item in a scan. * * We need to be clever about the direction of scan, the search * conditions, and the tree ordering. We find the first item (or, * if backwards scan, the last item) in the tree that satisfies the * qualifications in the scan key. On success exit, the page containing * the current index tuple is pinned but not locked, and data about * the matching tuple(s) on the page has been loaded into so->currPos. * scan->xs_ctup.t_self is set to the heap TID of the current tuple, * and if requested, scan->xs_itup points to a copy of the index tuple. * * If there are no matching items in the index, we return FALSE, with no * pins or locks held. * * Note that scan->keyData[], and the so->keyData[] scankey built from it, * are both search-type scankeys (see nbtree/README for more about this). * Within this routine, we build a temporary insertion-type scankey to use * in locating the scan start position. */
Function: find the first item that meets the search criteria.
- Record position to so - > currpos
- Record tid to scan - > XS_ ctup. t_ self
- If necessary, scan - > XS_ Itup points to a copy of the index tuple.
Failed to find a satisfied item. false was returned.
bool
_bt_first(IndexScanDesc scan, ScanDirection dir)
{
Relation rel = scan->indexRelation;
BTScanOpaque so = (BTScanOpaque) scan->opaque;
Buffer buf;
BTStack stack;
OffsetNumber offnum;
StrategyNumber strat;
bool nextkey;
bool goback;
ScanKey startKeys[INDEX_MAX_KEYS];
ScanKeyData scankeys[INDEX_MAX_KEYS];
ScanKeyData notnullkeys[INDEX_MAX_KEYS];
int keysCount = 0;
int i;
bool status = true;
StrategyNumber strat_total;
BTScanPosItem *currItem;
BlockNumber blkno;
Assert(!BTScanPosIsValid(so->currPos));
pgstat_count_index_scan(rel);
/*
* Examine the scan keys and eliminate any redundant keys; also mark the
* keys that must be matched to continue the scan.
*/
_bt_preprocess_keys(scan);
Step 1:_ bt_ preprocess_ Record the redundancy result in key s
(gdb) p scan->numberOfKeys
$3 = 4
(gdb) p scan->keyData[0]
$4 = {sk_flags = 0, sk_attno = 1, sk_strategy = 5, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f65ac <int4gt>,
fn_oid = 147, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 735}
(gdb) p scan->keyData[1]
$5 = {sk_flags = 0, sk_attno = 1, sk_strategy = 1, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f6544 <int4lt>,
fn_oid = 66, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 1467}
(gdb) p scan->keyData[2]
$6 = {sk_flags = 0, sk_attno = 1, sk_strategy = 5, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f65ac <int4gt>,
fn_oid = 147, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 500}
(gdb) p scan->keyData[3]
$7 = {sk_flags = 0, sk_attno = 1, sk_strategy = 1, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f6544 <int4lt>,
fn_oid = 66, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 2000}
The function traverses four scankeys in turn, adding one for each different column and saving it in xform. If repeated conditions of columns are encountered, call_ bt_compare_scankey_args reserves a stricter key
A process similar to this
for(Four conditions)
if (xform[j] == NULL) // j is the column ID
xform[j] = cur;
else
if (_bt_compare_scankey_args(...))
// Replace with a smaller, more restrictive key
_ bt_ compare_ scankey_ The args function will find a suitable comparison function (the data type may be arbitrary) and judge which is more strict according to the operator (enter left scan key and right scan key, and output true and false).
_ bt_ preprocess_ After the keys function is executed, there are only two scankeys left.
Note: when the scan key contains a cross type operator_ bt_preprocess_keys may not eliminate redundant keys.
(gdb) p ((BTScanOpaque)scan->opaque)->numberOfKeys
$18 = 2
(gdb) p ((BTScanOpaque)scan->opaque)->keyData[0]
$19 = {sk_flags = 131072, sk_attno = 1, sk_strategy = 5, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f65ac <int4gt>,
fn_oid = 147, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 735}
(gdb) p ((BTScanOpaque)scan->opaque)->keyData[1]
$20 = {sk_flags = 65536, sk_attno = 1, sk_strategy = 1, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f6544 <int4lt>,
fn_oid = 66, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 1467}```
Note: sk_argument saves the specific value, which is > 735 and < 1467
Note: the new scankey is updated to so, and the keydata in scan is old.
/*
* Quit now if _bt_preprocess_keys() discovered that the scan keys can
* never be satisfied (eg, x == 1 AND x > 2).
*/
if (!so->qual_ok)
{
/* Notify any other workers that we're done with this scan key. */
_bt_parallel_done(scan);
return false;
}
/*
* For parallel scans, get the starting page from shared state. If the
* scan has not started, proceed to find out first leaf page in the usual
* way while keeping other participating processes waiting. If the scan
* has already begun, use the page number from the shared structure.
*/
if (scan->parallel_scan != NULL)
{
status = _bt_parallel_seize(scan, &blkno);
if (!status)
return false;
else if (blkno == P_NONE)
{
_bt_parallel_done(scan);
return false;
}
else if (blkno != InvalidBlockNumber)
{
if (!_bt_parallel_readpage(scan, blkno, dir))
return false;
goto readcomplete;
}
}
Step 2: start to construct startKeys (scankey array) (find the available scankey)
Now the value of so - > numberofkeys is 2, and keyData has two data:
Original: (where id > 735 and ID < 1467 and ID > 500 and ID < 2000)
Now: (where id > 735 and ID < 1467)
The inner loop for (cur = so - > keydata, I = 0;; cur + +, I + +) traverses each key:
First key: where id > 735
(1)switch (cur->sk_strategy) (2)BTGreaterStrategyNumber (3)chosen = cur
The second key: ID < 1467
(1)switch (cur->sk_strategy)
(2)BTLessEqualStrategyNumber
(3)break;
if (chosen == NULL)
{
if (ScanDirectionIsBackward(dir))
chosen = cur;
else
impliesNN = cur;
}
else
{
(Take this branch)break;
}
From the above logic:
(1) In the case of > the key can be used as the initial search key, that is, chosen=cur current scankey.
(2) In the case of < and reverse scanning, it can be used as the starting search key, but not in the case of forward search.
Intuitively, it is also easier to understand. You can start the search in the case of >, and the case of < can only be used as the end point, not the starting point.
strat_total = BTEqualStrategyNumber;
if (so->numberOfKeys > 0)
{
AttrNumber curattr;
ScanKey chosen;
ScanKey impliesNN;
ScanKey cur;
/*
* chosen is the so-far-chosen key for the current attribute, if any.
* We don't cast the decision in stone until we reach keys for the
* next attribute.
*/
curattr = 1;
chosen = NULL;
/* Also remember any scankey that implies a NOT NULL constraint */
impliesNN = NULL;
/*
* Loop iterates from 0 to numberOfKeys inclusive; we use the last
* pass to handle after-last-key processing. Actual exit from the
* loop is at one of the "break" statements below.
*/
for (cur = so->keyData, i = 0;; cur++, i++)
{
if (i >= so->numberOfKeys || cur->sk_attno != curattr)
{
/*
* Done looking at keys for curattr. If we didn't find a
* usable boundary key, see if we can deduce a NOT NULL key.
*/
if (chosen == NULL && impliesNN != NULL &&
((impliesNN->sk_flags & SK_BT_NULLS_FIRST) ?
ScanDirectionIsForward(dir) :
ScanDirectionIsBackward(dir)))
{
/* Yes, so build the key in notnullkeys[keysCount] */
chosen = ¬nullkeys[keysCount];
ScanKeyEntryInitialize(chosen,
(SK_SEARCHNOTNULL | SK_ISNULL |
(impliesNN->sk_flags &
(SK_BT_DESC | SK_BT_NULLS_FIRST))),
curattr,
((impliesNN->sk_flags & SK_BT_NULLS_FIRST) ?
BTGreaterStrategyNumber :
BTLessStrategyNumber),
InvalidOid,
InvalidOid,
InvalidOid,
(Datum) 0);
}
/*
* If we still didn't find a usable boundary key, quit; else
* save the boundary key pointer in startKeys.
*/
if (chosen == NULL)
break;
startKeys[keysCount++] = chosen;
/*
* Adjust strat_total, and quit if we have stored a > or <
* key.
*/
strat = chosen->sk_strategy;
if (strat != BTEqualStrategyNumber)
{
strat_total = strat;
if (strat == BTGreaterStrategyNumber ||
strat == BTLessStrategyNumber)
break;
}
/*
* Done if that was the last attribute, or if next key is not
* in sequence (implying no boundary key is available for the
* next attribute).
*/
if (i >= so->numberOfKeys ||
cur->sk_attno != curattr + 1)
break;
/*
* Reset for next attr.
*/
curattr = cur->sk_attno;
chosen = NULL;
impliesNN = NULL;
}
/*
* Can we use this key as a starting boundary for this attr?
*
* If not, does it imply a NOT NULL constraint? (Because
* SK_SEARCHNULL keys are always assigned BTEqualStrategyNumber,
* *any* inequality key works for that; we need not test.)
*/
switch (cur->sk_strategy)
{
case BTLessStrategyNumber:
case BTLessEqualStrategyNumber:
if (chosen == NULL)
{
if (ScanDirectionIsBackward(dir))
chosen = cur;
else
impliesNN = cur;
}
break;
case BTEqualStrategyNumber:
/* override any non-equality choice */
chosen = cur;
break;
case BTGreaterEqualStrategyNumber:
case BTGreaterStrategyNumber:
if (chosen == NULL)
{
if (ScanDirectionIsForward(dir))
chosen = cur;
else
impliesNN = cur;
}
break;
}
}
}
/*
* If we found no usable boundary keys, we have to start from one end of
* the tree. Walk down that edge to the first or last key, and scan from
* there.
*/
if (keysCount == 0)
{
bool match;
match = _bt_endpoint(scan, dir);
if (!match)
{
/* No match, so mark (parallel) scan finished */
_bt_parallel_done(scan);
}
return match;
}
Here, the startKeys array records a start search key:
(gdb) p *startKeys[0]
$39 = {sk_flags = 131072, sk_attno = 1, sk_strategy = 5, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f65ac <int4gt>,
fn_oid = 147, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 735}
The condition ID > 735
Step 3: convert the comparison function into general row comparisons
For example: the above generated startKeys only records the condition of ID > 735. You can directly use the single value to compare the size in the later binary search and comparison.
But consider this: create index x on tbl(a,b). Data: (1,1), (1,5), (2,1), (2,2), (2,10)
In this case, if you use binary search for comparison, it is obviously unreasonable to use single column comparison. So we need to convert the comparison function into a more general way.
Step 3 Comparison before and after conversion: sk_func and fn_oid has changed.
(gdb) p startKeys[0]
$39 = {sk_flags = 131072, sk_attno = 1, sk_strategy = 5, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x8f65ac <int4gt>,
fn_oid = 147, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 735}
(gdb) p scankeys[0]
$52 = {sk_flags = 131072, sk_attno = 1, sk_strategy = 0, sk_subtype = 23, sk_collation = 0, sk_func = {fn_addr = 0x4f2f5d <btint4cmp>,
fn_oid = 351, fn_nargs = 2, fn_strict = 1 '\001', fn_retset = 0 '\000', fn_stats = 2 '\002', fn_extra = 0x0, fn_mcxt = 0x17cec40,
fn_expr = 0x0}, sk_argument = 735}
A note is added here to explain the problem here:
/* * About row comparisons: * * The ScanKey data structure also supports row comparisons, that is ordered * tuple comparisons like (x, y) > (c1, c2), having the SQL-spec semantics * "x > c1 OR (x = c1 AND y > c2)". Note that this is currently only * implemented for btree index searches, not for heapscans or any other index * type. A row comparison is represented by a "header" ScanKey entry plus * a separate array of ScanKeys, one for each column of the row comparison. * The header entry has these properties: * sk_flags = SK_ROW_HEADER * sk_attno = index column number for leading column of row comparison * sk_strategy = btree strategy code for semantics of row comparison * (ie, < <= > or >=) * sk_subtype, sk_collation, sk_func: not used * sk_argument: pointer to subsidiary ScanKey array * If the header is part of a ScanKey array that's sorted by attno, it * must be sorted according to the leading column number. * * The subsidiary ScanKey array appears in logical column order of the row * comparison, which may be different from index column order. The array * elements are like a normal ScanKey array except that: * sk_flags must include SK_ROW_MEMBER, plus SK_ROW_END in the last * element (needed since row header does not include a count) * sk_func points to the btree comparison support function for the * opclass, NOT the operator's implementation function. * sk_strategy must be the same in all elements of the subsidiary array, * that is, the same as in the header entry. * SK_SEARCHARRAY, SK_SEARCHNULL, SK_SEARCHNOTNULL cannot be used here. */ /* * ScanKeyData sk_flags * * sk_flags bits 0-15 are reserved for system-wide use (symbols for those * bits should be defined here). Bits 16-31 are reserved for use within * individual index access methods. */ #define SK_ISNULL 0x0001 /* sk_argument is NULL */ #define SK_UNARY 0x0002 /* unary operator (not supported!) */ #define SK_ROW_HEADER 0x0004 /* row comparison header (see above) */ #define SK_ROW_MEMBER 0x0008 /* row comparison member (see above) */ #define SK_ROW_END 0x0010 /* last row comparison member */ #define SK_SEARCHARRAY 0x0020 /* scankey represents ScalarArrayOp */ #define SK_SEARCHNULL 0x0040 /* scankey represents "col IS NULL" */ #define SK_SEARCHNOTNULL 0x0080 /* scankey represents "col IS NOT NULL" */ #define SK_ORDER_BY 0x0100 /* scankey is for ORDER BY op */
Next, we will find a suitable comparison function in proc for comparison.
/*
* We want to start the scan somewhere within the index. Set up an
* insertion scankey we can use to search for the boundary point we
* identified above. The insertion scankey is built in the local
* scankeys[] array, using the keys identified by startKeys[].
*/
Assert(keysCount <= INDEX_MAX_KEYS);
for (i = 0; i < keysCount; i++)
{
ScanKey cur = startKeys[i];
Assert(cur->sk_attno == i + 1);
if (cur->sk_flags & SK_ROW_HEADER)
{
/*
* Row comparison header: look to the first row member instead.
*
* The member scankeys are already in insertion format (ie, they
* have sk_func = 3-way-comparison function), but we have to watch
* out for nulls, which _bt_preprocess_keys didn't check. A null
* in the first row member makes the condition unmatchable, just
* like qual_ok = false.
*/
ScanKey subkey = (ScanKey) DatumGetPointer(cur->sk_argument);
Assert(subkey->sk_flags & SK_ROW_MEMBER);
if (subkey->sk_flags & SK_ISNULL)
{
_bt_parallel_done(scan);
return false;
}
memcpy(scankeys + i, subkey, sizeof(ScanKeyData));
/*
* If the row comparison is the last positioning key we accepted,
* try to add additional keys from the lower-order row members.
* (If we accepted independent conditions on additional index
* columns, we use those instead --- doesn't seem worth trying to
* determine which is more restrictive.) Note that this is OK
* even if the row comparison is of ">" or "<" type, because the
* condition applied to all but the last row member is effectively
* ">=" or "<=", and so the extra keys don't break the positioning
* scheme. But, by the same token, if we aren't able to use all
* the row members, then the part of the row comparison that we
* did use has to be treated as just a ">=" or "<=" condition, and
* so we'd better adjust strat_total accordingly.
*/
if (i == keysCount - 1)
{
bool used_all_subkeys = false;
Assert(!(subkey->sk_flags & SK_ROW_END));
for (;;)
{
subkey++;
Assert(subkey->sk_flags & SK_ROW_MEMBER);
if (subkey->sk_attno != keysCount + 1)
break; /* out-of-sequence, can't use it */
if (subkey->sk_strategy != cur->sk_strategy)
break; /* wrong direction, can't use it */
if (subkey->sk_flags & SK_ISNULL)
break; /* can't use null keys */
Assert(keysCount < INDEX_MAX_KEYS);
memcpy(scankeys + keysCount, subkey, sizeof(ScanKeyData));
keysCount++;
if (subkey->sk_flags & SK_ROW_END)
{
used_all_subkeys = true;
break;
}
}
if (!used_all_subkeys)
{
switch (strat_total)
{
case BTLessStrategyNumber:
strat_total = BTLessEqualStrategyNumber;
break;
case BTGreaterStrategyNumber:
strat_total = BTGreaterEqualStrategyNumber;
break;
}
}
break; /* done with outer loop */
}
}
else
{
/*
* Ordinary comparison key. Transform the search-style scan key
* to an insertion scan key by replacing the sk_func with the
* appropriate btree comparison function.
*
* If scankey operator is not a cross-type comparison, we can use
* the cached comparison function; otherwise gotta look it up in
* the catalogs. (That can't lead to infinite recursion, since no
* indexscan initiated by syscache lookup will use cross-data-type
* operators.)
*
* We support the convention that sk_subtype == InvalidOid means
* the opclass input type; this is a hack to simplify life for
* ScanKeyInit().
*/
if (cur->sk_subtype == rel->rd_opcintype[i] ||
cur->sk_subtype == InvalidOid)
{
FmgrInfo *procinfo;
procinfo = index_getprocinfo(rel, cur->sk_attno, BTORDER_PROC);
ScanKeyEntryInitializeWithInfo(scankeys + i,
cur->sk_flags,
cur->sk_attno,
InvalidStrategy,
cur->sk_subtype,
cur->sk_collation,
procinfo,
cur->sk_argument);
}
else
{
RegProcedure cmp_proc;
cmp_proc = get_opfamily_proc(rel->rd_opfamily[i],
rel->rd_opcintype[i],
cur->sk_subtype,
BTORDER_PROC);
if (!RegProcedureIsValid(cmp_proc))
elog(ERROR, "missing support function %d(%u,%u) for attribute %d of index \"%s\"",
BTORDER_PROC, rel->rd_opcintype[i], cur->sk_subtype,
cur->sk_attno, RelationGetRelationName(rel));
ScanKeyEntryInitialize(scankeys + i,
cur->sk_flags,
cur->sk_attno,
InvalidStrategy,
cur->sk_subtype,
cur->sk_collation,
cmp_proc,
cur->sk_argument);
}
}
}
Step 4: determine the critical value judgment rules
nextkey = false: take the first item > = scan key
nextkey = true: take the first item > scan key
goback = true: start scanning from the previous one
goback = false: start scanning from the current one
For the current case:
strat_total=BTGreaterStrategyNumber,The initial positioning conditions are: id>735 nextkey = true; goback = false;
/*----------
* Examine the selected initial-positioning strategy to determine exactly
* where we need to start the scan, and set flag variables to control the
* code below.
*
* If nextkey = false, _bt_search and _bt_binsrch will locate the first
* item >= scan key. If nextkey = true, they will locate the first
* item > scan key.
*
* If goback = true, we will then step back one item, while if
* goback = false, we will start the scan on the located item.
*----------
*/
switch (strat_total)
{
case BTLessStrategyNumber:
/*
* Find first item >= scankey, then back up one to arrive at last
* item < scankey. (Note: this positioning strategy is only used
* for a backward scan, so that is always the correct starting
* position.)
*/
nextkey = false;
goback = true;
break;
case BTLessEqualStrategyNumber:
/*
* Find first item > scankey, then back up one to arrive at last
* item <= scankey. (Note: this positioning strategy is only used
* for a backward scan, so that is always the correct starting
* position.)
*/
nextkey = true;
goback = true;
break;
case BTEqualStrategyNumber:
/*
* If a backward scan was specified, need to start with last equal
* item not first one.
*/
if (ScanDirectionIsBackward(dir))
{
/*
* This is the same as the <= strategy. We will check at the
* end whether the found item is actually =.
*/
nextkey = true;
goback = true;
}
else
{
/*
* This is the same as the >= strategy. We will check at the
* end whether the found item is actually =.
*/
nextkey = false;
goback = false;
}
break;
case BTGreaterEqualStrategyNumber:
/*
* Find first item >= scankey. (This is only used for forward
* scans.)
*/
nextkey = false;
goback = false;
break;
case BTGreaterStrategyNumber:
/*
* Find first item > scankey. (This is only used for forward
* scans.)
*/
nextkey = true;
goback = false;
break;
default:
/* can't get here, but keep compiler quiet */
elog(ERROR, "unrecognized strat_total: %d", (int) strat_total);
return false;
}
Step 5: scankeys& boundary rules are ready and start scanning
The next article (34) continues the analysis:
This involves locking. The next article will focus on the process of locking the buffer
/*
* Use the manufactured insertion scan key to descend the tree and
* position ourselves on the target leaf page.
*/
stack = _bt_search(rel, keysCount, scankeys, nextkey, &buf, BT_READ,
scan->xs_snapshot);
/* don't need to keep the stack around... */
_bt_freestack(stack);
if (!BufferIsValid(buf))
{
/*
* We only get here if the index is completely empty. Lock relation
* because nothing finer to lock exists.
*/
PredicateLockRelation(rel, scan->xs_snapshot);
/*
* mark parallel scan as done, so that all the workers can finish
* their scan
*/
_bt_parallel_done(scan);
BTScanPosInvalidate(so->currPos);
return false;
}
else
PredicateLockPage(rel, BufferGetBlockNumber(buf),
scan->xs_snapshot);
_bt_initialize_more_data(so, dir);
/* position to the precise item on the page */
offnum = _bt_binsrch(rel, buf, keysCount, scankeys, nextkey);
/*
* If nextkey = false, we are positioned at the first item >= scan key, or
* possibly at the end of a page on which all the existing items are less
* than the scan key and we know that everything on later pages is greater
* than or equal to scan key.
*
* If nextkey = true, we are positioned at the first item > scan key, or
* possibly at the end of a page on which all the existing items are less
* than or equal to the scan key and we know that everything on later
* pages is greater than scan key.
*
* The actually desired starting point is either this item or the prior
* one, or in the end-of-page case it's the first item on the next page or
* the last item on this page. Adjust the starting offset if needed. (If
* this results in an offset before the first item or after the last one,
* _bt_readpage will report no items found, and then we'll step to the
* next page as needed.)
*/
if (goback)
offnum = OffsetNumberPrev(offnum);
/* remember which buffer we have pinned, if any */
Assert(!BTScanPosIsValid(so->currPos));
so->currPos.buf = buf;
/*
* Now load data from the first page of the scan.
*/
if (!_bt_readpage(scan, dir, offnum))
{
/*
* There's no actually-matching data on this page. Try to advance to
* the next page. Return false if there's no matching data at all.
*/
LockBuffer(so->currPos.buf, BUFFER_LOCK_UNLOCK);
if (!_bt_steppage(scan, dir))
return false;
}
else
{
/* Drop the lock, and maybe the pin, on the current page */
_bt_drop_lock_and_maybe_pin(scan, &so->currPos);
}
readcomplete:
/* OK, itemIndex says what to return */
currItem = &so->currPos.items[so->currPos.itemIndex];
scan->xs_ctup.t_self = currItem->heapTid;
if (scan->xs_want_itup)
scan->xs_itup = (IndexTuple) (so->currTuples + currItem->tupleOffset);
return true;
}
2.4 _bt_next
The next article (34) continues the analysis