Introduction
in java development, we often encounter the problem of thread safety of set classes. In the development process of Java language, from the initial thread unsafe set classes to the thread safe set classes that basically support many thread safe set classes, we don't need to pay attention to thread safety in some scenes during the development process, At that time, thread safe collection classes must be used in a concurrent scenario. Let's take a look at the thread safe collection classes commonly used in Java and their principles.
Principle of ConcurrentHashMap
ConcurrentHashMap is a thread safe and efficient HashMap collection class. Concurrency and multithreading are inevitable in the working environment. At this time, thread unsafe collection classes such as HashMap can not meet this demand. In order to meet the safe and efficient development work in multithreaded scenarios, ConcurrentHashMap appears at this time, This is provided by JDK itself.
Two questions
- 1. Why is HashMap unsafe under multithreading?
put operation of HashMap in multi-threaded environment will cause dead loop, resulting in 100% CPU utilization - 2. What causes unsafe things to happen?
when HashMap executes the put operation concurrently, the Entry linked list of HashMap forms a ring data structure, and then the next of the Entry always has a value and is always obtained downward.
it should be noted here that although HashTable has the characteristics of thread safety, the granularity of lock is relatively large. The whole array is locked. The competition is very fierce when multithreading reads and writes to the table, which will affect the performance in serious cases. Therefore, although HashTable is thread safe, it is inefficient and generally will not be used.
in jdk1 In 7, ConcurrentHashMap uses the lock segmentation technology to divide the HashMap array into segments and lock them one by one. When accessing different data segments concurrently, each thread can obtain its own lock on each segment, and the data segments do not affect each other.
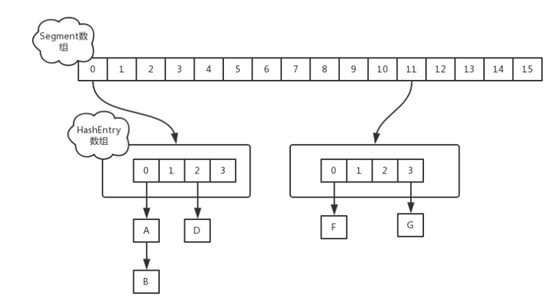
Segment array is the reentrant lock that needs to be obtained. HashEntry is the data Segment under each lock. Similar to the data structure of HashMap, it is composed of array and linked list. In this way, the segmentation lock of HashMap array is completed. Each time you want to operate on the content of data Segment, you need to obtain the corresponding reentrant lock first.
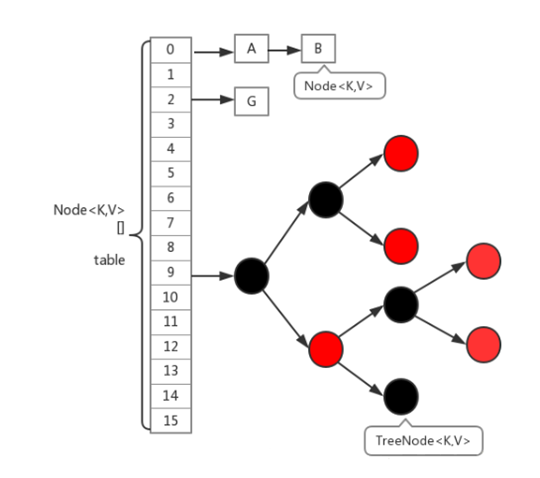
JDK1. After 8, the structure of array + linked list + red black tree is programmed. The granularity of lock is adjusted to the head node of each linked list. The Hash algorithm for locating nodes is simplified, which will increase Hash conflict. Therefore, when the number of elements in the linked list exceeds 8, the linked list is converted into red black tree for storage, and Node+CAS+Synchronized is used to ensure safe concurrency.
the initialization of ConcurrentHashMap occurs only when the first put method is executed. The initialization calls the initTable() method as follows
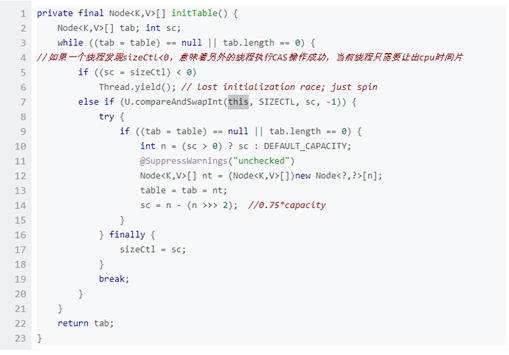
&emps; If the initialization operation is currently being performed and the initialized thread is not the current thread, the current thread will give up the time slice. If it is the current thread, a CAS security check will be performed to judge whether someone has carried out the initialization operation first. If there is no initialization operation, the initialization operation will be carried out.
put method
when executing the put method to insert data, find the corresponding position in the Node array according to the hash value of the key. The implementation is as follows


From top to bottom
- 1. If the array is empty, initialize it first
- 2. If there is no linked list in the current location, add a Node in this location by CAS
- 3. If the current Map is being expanded, first assist in the expansion, and then update the value
- 4. If there is a Hash conflict, first add synchronized to the head node causing the conflict. If the added value already exists, update the operation; If the added value does not exist, add the new value to the end of the linked list. If the linked list has been transformed into a red black tree, the properties will be added in the form of tree nodes.
- 5. If the length of the linked list is affected after adding a new value, so that the linked list reaches the threshold of converting to red black tree, use treeifyBin() method to convert the linked list.
- 6. Finally, the number of summary points is counted to see whether the capacity expansion operation is required when the threshold is reached.
Capacity expansion
when adding new nodes, two methods will trigger capacity expansion. The first is that the length of the linked list is greater than or equal to 8, the current array length is less than 64, and the array length will be expanded twice as long as the original; Twentieth, addCount() will count the number of nodes in the array. If the number of new nodes is greater than the threshold, transfer will be triggered to readjust the node position.
in the process of capacity expansion, it still supports concurrent update and concurrent insertion. Traverse the whole table. If the current Node is empty, put fwd in the current position in CAS mode. Each thread undertakes the capacity expansion of no less than 16 elements, divided into 16 from right to left. Whenever an element is migrated, the thread will lock the head Node of the element (Node linked list). If it is inserted, modified When ForwardingNode is encountered in operations such as delete and merge, the current thread will also join the expansion army, and the update operation will be carried out after the expansion is completed.
the get method is simpler than the put method. Calculate the hash value according to the key to obtain the position in the array. If the key is empty, return null, otherwise return the value.
clear method: first traverse each bucket in the table. If the current bucket is being expanded, first help to complete the expansion, then lock the current bucket, delete elements, and update the size of the map.
Principle of ConcurrentSkipListMap
to understand ConcurrentSkipListMap, first understand what SkipMap is?
SkipMap
the traditional single linked list is a linear structure. It takes O(n) time to insert a node into the linked list and O(n) time to find it.
simple example of jump table:

If we use the jump table shown in the above picture, we can shorten the lookup time to O(n/2). We can first search through the advanced pointer on each node, so that we can skip half of the nodes.
jump list is a data structure that can replace the balance tree. By default, it is in ascending order according to the key value. SkipList allows the sorted data to be distributed in the multi-layer linked list, and determines whether a data climbs upward with a random number of 0-1. Through an algorithm of "space for time", a forward pointer is added in each node, including insertion, deletion Some nodes that cannot be involved can be ignored when searching, which improves the efficiency.
ConcurrentSkipListMap
ConcurrentSkipListMap provides a sort mapping table for thread safe concurrent access. Internally, it is a SkipList structure, which can theoretically complete the search, insert and delete operations in O(log(n)) time.
in the case of non multithreading, TreeMap should be used as much as possible. In addition, for parallel programs with relatively low concurrency, you can use collection Synchronized SortedMap can also provide better efficiency by packaging TreeMap. For highly concurrent programs, you should use ConcurrentSkipListMap, which can provide efficient concurrency. Therefore, in multithreaded programs, if you need to sort the values of Map, try to use ConcurrentSkipListMap to get better concurrency.
concurrent skiplistmap mainly uses two Node storage methods: Node and Index, and realizes concurrent operation through volatile keyword.
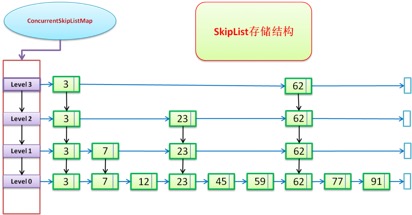
Skip table storage structure
- 1. The nodes at the bottom are arranged in ascending order of keywords (keys are ordered)
- 2. It contains multi-level indexes, and the index nodes of each level are arranged in ascending order according to the keywords of their associated data nodes.
- 3. A high-level index is a subset of its low-level indexes
- 4. If the keyword key appears in the index with level=i, all indexes with level < = I contain the key.
static final class Node<K,V> { //The lowest linked list node
final K key;
volatile Object value;//Value value
volatile Node<K,V> next;//next reference
......
}
static class Index<K,V> { //Upper level index classification
final Node<K,V> node;
final Index<K,V> down;//downy reference
volatile Index<K,V> right;//Right reference
......
}
lookup
search through SkipList
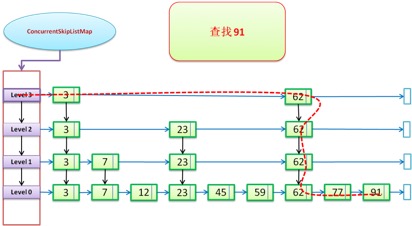
the red dotted line is the search path, the blue arrow is the right reference, and the black arrow is the down reference
first find the top layer, and the key s that are not found are found in the lower layer
public V get(Object key) {
return doGet(key);
}
doGet()
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
if (c < 0)
break outer;
b = n;
n = f;
}
}
return null;
}
doGet() obtains the node according to the key through the findPredecessor() method, and then returns the value through judgment. Here, in the concurrent scenario, after obtaining the node, it is inevitable that other threads will delete the node.
delete
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) < 0)
break outer;
if (c > 0) {
b = n;
n = f;
continue;
}
if (value != null && !value.equals(v))
break outer;
if (!n.casValue(v, null))
break;
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // retry via findNode
else {
findPredecessor(key, cmp); // clean index
if (head.right == null)
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
}
return null;
}
first set the value of the node to null, and then add a delete flag. Both steps will be regarded as node deletion. Use the unlink in the findPredecessor method to clear the nodes in the linked list. The helpdelete method will detect whether the current node adds a deletion tag. If not, add a tag. If you add a tag, point the precursor node to the next of the current node.
Put
the JDK has been updated accordingly, integrating insertIindex and addIndex into one doPut method. The general meaning is to find the appropriate location of the node less than or equal to the key through the findPredecessor method. If it is less than, the precursor node less than the key will be returned, and if it is equal to, the corresponding value will be updated. Considering concurrency, it will detect whether the value of the modified or precursor node is deleted or updated during the dead cycle. If the node value is modified to null or a deletion mark is added, the node will be cleared accordingly in the linked list. If there is a corresponding key in the linked list, use CAS to constantly update the value of the key until it succeeds. If there is no corresponding key, you need to add a new node, next point to N, and use CAS to build a linked list of B - > new node - > n.
after adding a new node, calculate the level of random level. Under the condition of meeting the original linked list structure, add a new node in the middle. In order to maintain the original appearance, the linked list structure must be adjusted. Add nodes from the bottom up and connect through down. If the level level level is lower than the current level level in the modification process, That means that other threads have finished updating the level level. The first update uses CAS to update the head node.
CopyOnWriteArrayList principle
CopyOnWriteArrayList is a thread safe ArrayList. Its modification is carried out on the underlying copy array, using the copy on write strategy. ReenTrantLock is used internally to lock the collection, ensuring that only one thread modifies the collection at the same time.
there are many reconstruction methods for adding elements. The principle is the same. Add (E), add (int index, e, e). At present, it is the add method, adding elements at the end of the list.
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
first obtain Reentrantlock, create a new array with a length 1 larger than the original array, copy the elements in the original array to the new array, add new elements at the end, set the new array as the current array, and finally release the lock.
Set method
public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
E oldValue = get(elements, index);
if (oldValue != element) {
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
newElements[index] = element;
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
in order to achieve concurrency security, an exclusive lock will be added to each modification. Judge whether the modified value is equal to the value in the corresponding position. If it is equal, there is no need to operate and return directly. If it is not equal, create a new array, and replace the modified value with a new array.
Remove method
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);
int numMoved = len - index - 1;
if (numMoved == 0)
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
if it is the last part of the array to be directly copied, and if it is in the middle, use the arrayCory method to copy from the elements array to the new array and return the deleted elements.
Get method
private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
final Object[] getArray() {
return array;
}
this method does not add any security protection mechanism, so it is thread unsafe. If the array is obtained and modified by other threads, the obtained value is not the latest, which is the weak consistency principle produced by the copy on write strategy.
this problem also exists during iterator traversal. The iterated array is out of sync with the modified array.
Principle of ConcurrentLinkedQueue
ConcurrentLinkedQueue is a thread safe unbounded queue based on linked nodes. It uses first in first out rules to sort nodes.
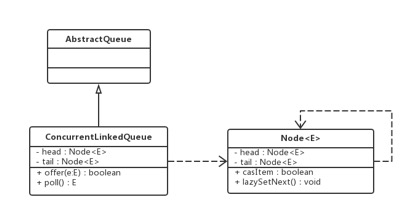
the ConcurrentLinkedQueue is constructed from a head Node and a tail Node. The head Node points to the head Node and the tail Node does not always point to the tail Node. Nodes are connected through next. By default, that is, when the Node is empty, the head and tail point to the head Node, the Node and the reference to the next Node are declared with the volatile keyword, and the methods in the Node use CAS to achieve their security.
Queue operation
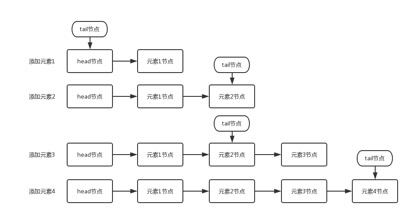
the element addition process shown in the above figure is as follows
- Add element 1: the next node of the queue update head node is element 1 node. And because the tail node is equal to the head node by default, their next nodes all point to the element 1 node.
- Add element 2: the queue first sets the next node of element 1 node as element 2 node, and then updates the tail node to point to element 2 node.
- Add element 3: set the next node of the tail node to element 3 node.
- Add element 4: set the next node of element 3 to element 4 node, and then point the tail to element 4 node.
the tail node points to the penultimate element and sometimes to the last element of the queue.
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
first create a new node and determine the position of the tail node according to the tail node. If the next of the tail node is empty, the tail node is the tail node. If the tail node is the tail node, set the newly queued node as the next node of the tail, and use CAS to cycle the setting. If it fails, try here. If the tail is not the tail node, point the tail to the new node and use CAS to set the new node as the tail node. At this time, the tail points to the tail node. Considering concurrency, here is a judgment designed if P= t. It indicates that other threads are updated successfully.
tail does not always point to the tail node to improve the efficiency of CAS and improve the efficiency of joining the team. In 1.7, douglea uses the hops variable to control and reduce the update frequency of the tail node. When the distance between the tail node and the tail node is greater than or equal to the constant, and the value of hops is equal to 1 by default, the tail node is updated. The longer the distance between the tail node and the tail node, the fewer times to update the tail node with CAS, but the longer the distance, the longer the time to locate the tail node, The loop body needs to locate the tail node more than once. In essence, it increases volatile read operations and reduces write operations. Writing is more expensive than reading, so the efficiency of joining the team will be improved. The update of tail in 1.8 is judged by whether p and t are equal. Its implementation result is the same as that in 1.7, that is, when the distance between tail node and tail node is greater than or equal to 1, the tail is updated.
Out of line operation
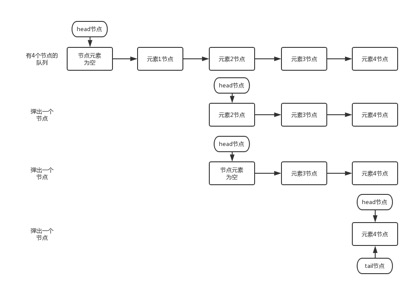
when the current head is empty, the next node of the head will pop up and the head node will be updated. When the head is not empty, the value of the current node will pop up and the node will be set to null by CAS. After CAS succeeds, the value of the head node will be returned and the head node will not be updated.
public E poll() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// If the element of the p node is not null, set the element referenced by the p node to null through CAS. If successful, return the element of the p node
if (item != null && p.casItem(item, null)) {
// Successful CAS is the linearization point
// for item to be removed from this queue.
// If P= h. Update head
if (p != h) // hop two nodes at a time
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// If the element of the head node is empty or the head node has changed, it indicates that the head node has been modified by another thread.
// Then get the next node of the p node. If the next node of the p node is null, it indicates that the queue is empty
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// p == q, restart with a new head
else if (p == q)
continue restartFromHead;
// If the next element is not empty, the next node of the head node is set as the head node
else
p = q;
}
}
}
the peek method obtains the header element of the linked list without removing the header element
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
Size method
the number of elements in the queue may be inaccurate in the concurrent process, because the acquisition process is not locked, and the addition and deletion of elements during the period will not be recorded.
Remove method
get the queue head element. If the queue head element is not empty and the value of the element is the same as the value passed in, you can set the value to NULL through CAS and adjust the next of the precursor to point to the current next; If it is not equal, get the next node and repeat the above operation.
public boolean remove(Object o) {
// The deleted element cannot be null
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// Node element is not null
if (item != null) {
// If not, get the next node to continue matching
if (!o.equals(item)) {
next = succ(p);
continue;
}
// If it matches, set the corresponding node element to null through CAS operation
removed = p.casItem(item, null);
}
// Gets the successor node of the deleted node
next = succ(p);
// Remove the deleted node from the queue
if (pred != null && next != null) // unlink
pred.casNext(p, next);
if (removed)
return true;
}
}
return false;
}