This article is shared from Huawei cloud community< Huawei FusionInsight MRS actual combat - development and learning of flinkserver, a visual development platform with enhanced features of Flink >, author: Jin Hongqing.
Background description
With the development of stream computing, the challenge is no longer limited to the amount of data and computing, and the business becomes more and more complex. How to improve the efficiency of developers and reduce the threshold of stream computing is very important to promote real-time computing.
SQL is the most widely used language in data processing. It allows users to show their business logic concisely. Flink, as a streaming batch computing engine, has been running since 1.7 Version 2 began to introduce the features of Flink SQL and continued to develop. Before, users may need to write hundreds of lines of business code. After using SQL, they may only need a few lines of SQL to do it easily.
However, IT is really necessary to put Flink SQL development work into the actual production scenario. If the native API interface is used for job development, there are still problems such as high threshold, low ease of use and poor maintainability of SQL code. New requirements are submitted by business personnel to IT personnel, who schedule development. From demand to launch, the cycle is long, resulting in missing the best market time window for new business. At the same time, IT personnel have heavy work, a large number of similar Flink jobs and low sense of achievement.
Advantages of Huawei FlinkServer visual development platform:
- It provides a Web-based visual development platform, which only needs to write SQL to develop jobs, which greatly reduces the threshold of job development.
- Through the opening of the ability of the operation platform, support business personnel to write SQL development jobs by themselves, quickly respond to needs, and liberate IT personnel from the cumbersome Flink job development work;
- Support both flow jobs and batch jobs;
- Support common connectors, including Kafka, Redis, HDFS, etc
Taking kafka as an example, we will use the native API interface and FlinkServer for job development to highlight the advantages of FlinkServer
Scenario description
Refer to posted forum posts Huawei FusionInsight MRS FlinkSQL complex nested Json parsing best practices
You need to use FlinkSQL to receive and parse cdl complex nested json data from a source kafka topic, and send the parsed data to another kafka topic
The steps of developing flink sql using native API interface scheme
prerequisite
- Complete the installation and configuration of MRS Flink client
- Complete the configuration of Flink SQL native interface
Operation steps
- Start the Flink cluster first with the following command
source /opt/hadoopclient/bigdata_env kinit developuser cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t ssl/
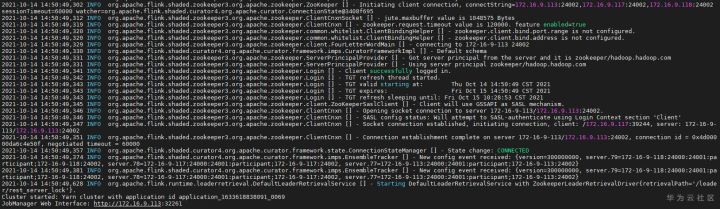
- Start Flink SQL Client with the following command
cd /opt/hadoopclient/Flink/flink/bin ./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml

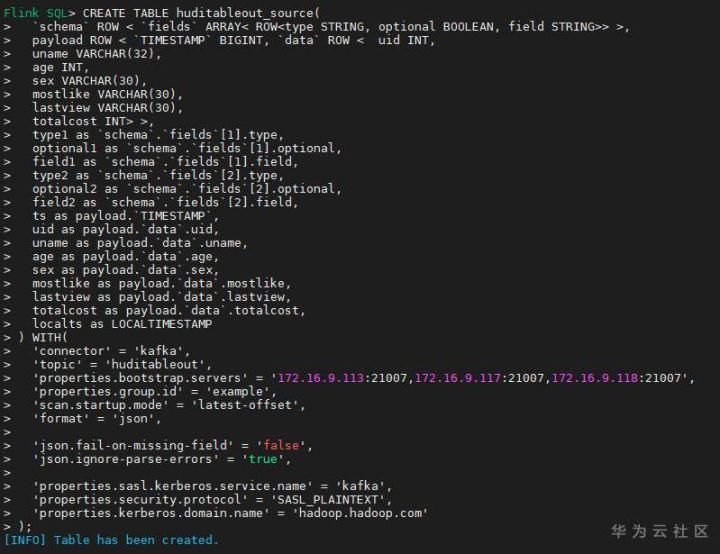
- Create the source side kafka table using the following flick SQL and extract the required information:
CREATE TABLE huditableout_source( `schema` ROW < `fields` ARRAY< ROW<type STRING, optional BOOLEAN, field STRING>> >, payload ROW < `TIMESTAMP` BIGINT, `data` ROW < uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' );
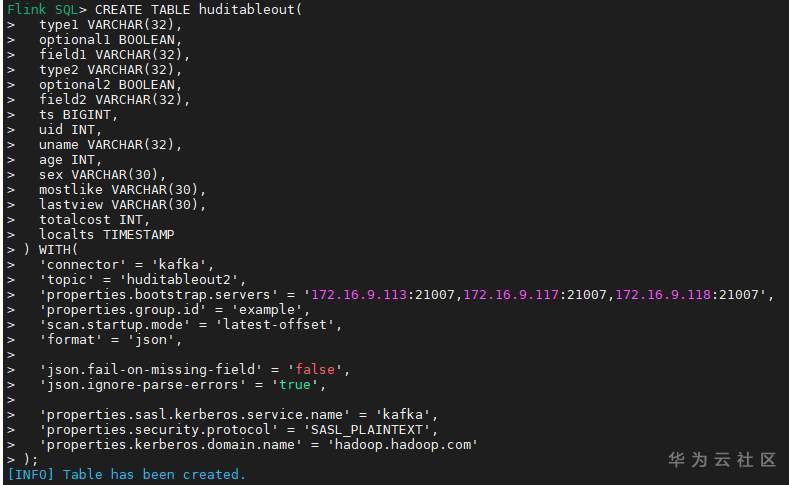
- Create the target kafka table using the following flex SQL:
CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' );
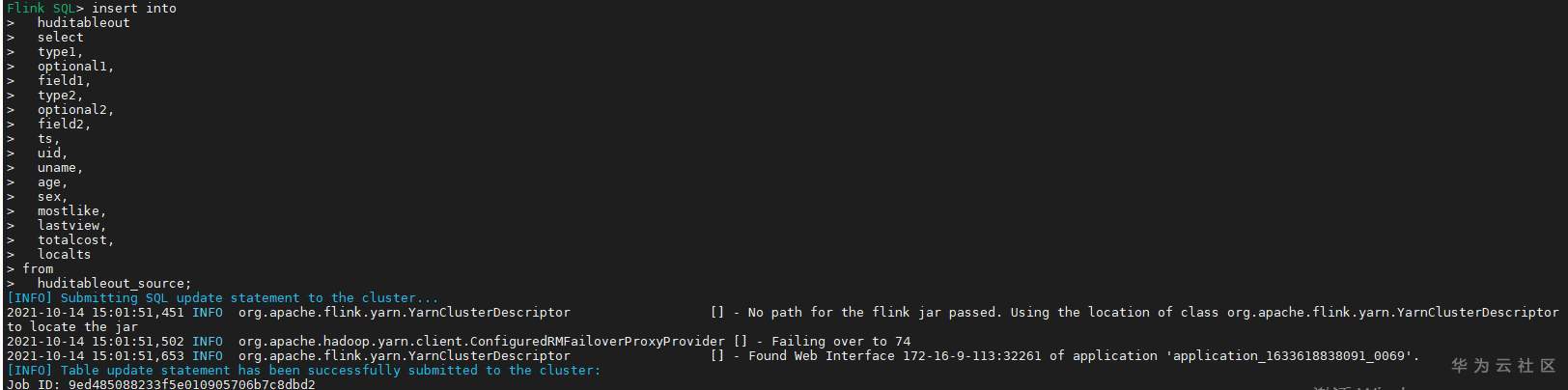
- Use the following flex SQL to write the source side kafka flow table to the target side kafka flow table
insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source;
- Check test results
Data of consumption and production source kafka topic (generated by cdl)

Consume the data parsed by kafka topic on the target side (the result generated by the flink sql task)

You can log in to the native interface of flink to view tasks
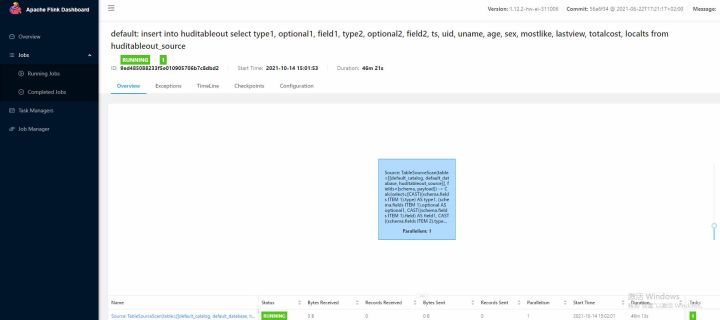
- View the results using the flick SQL client method
First, use the command set execution result-mode=tableau; The query results can be output directly to the terminal

Use flink sql to query the flow table created above
select * from huditableout

Note: because it is a kafka flow table, the query result will only display the data written into the topic after the select task is started
Operating steps for developing flink sql using FlinkServer visual development platform scheme
prerequisite
- Refer to the section "user and role based authentication" in the product document to create a user with "FlinkServer management operation permission" and use this user to access FlinkServer
Operation steps
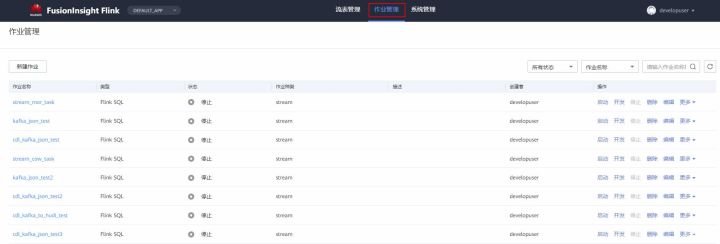
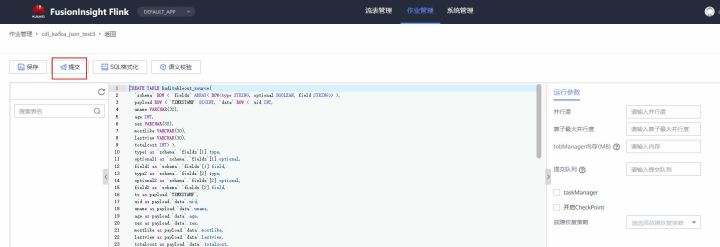
- Log in to FlinkServer and select job management
- Create task cdl_kafka_json_test3 and enter flink sql
Note: you can see that you can set the scale of the flink cluster on the FlinkServer interface when developing the flink sql task
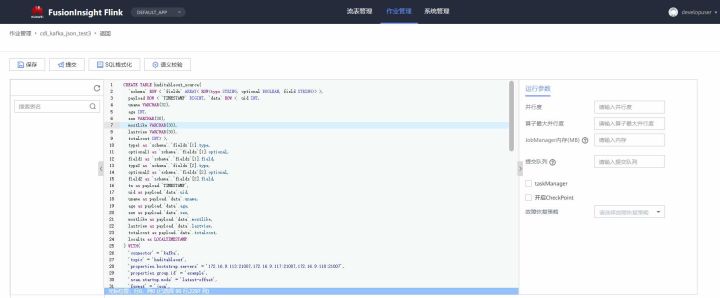
CREATE TABLE huditableout_source( `schema` ROW < `fields` ARRAY< ROW<type STRING, optional BOOLEAN, field STRING>> >, payload ROW < `TIMESTAMP` BIGINT, `data` ROW < uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source;
- Click semantic verification to ensure that the semantic verification passes
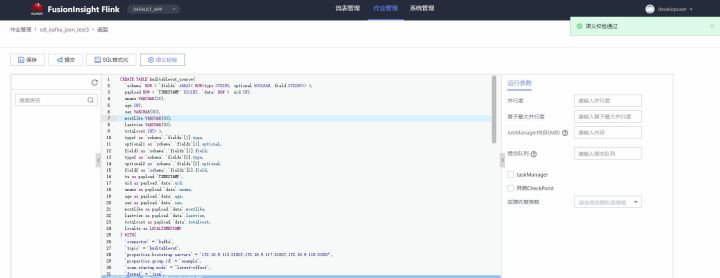
- Click Submit and start the task
- Check test results
Data of consumption and production source kafka topic (generated by cdl)
Consume the data parsed by kafka topic on the target side (the result generated by the flink sql task)
Click focus to learn about Huawei cloud's new technologies for the first time~