Convolutional Neural Network (CNN) has made great progress in the field of computer vision, but in addition, CNN has gradually gained ground in the field of Natural Language Processing (NLP). Taking text categorization as an example, this paper introduces a basic method of using convolutional neural network in the field of NLP.
0. Text categorization
The so-called text categorization is the use of computers to classify a text into a or b categories, which belongs to a classification problem, but also a more common task in NLP.
I. Word Vector
When it comes to the application of in-depth learning in NLP, word vectors have to be mentioned, and word vectors (Distributed Representation) are often translated into word embedding and so on.
The so-called word vector is to train the language model through the neural network and generate a set of vectors in the training process clock, which represent each word as an n-dimensional vector. For example, if we want to express "Beijing" as a two-dimensional vector, one possible result is Beijing= (1.1, 2.2), where the word "Beijing" is expressed as a two-dimensional vector. But besides expressing words as vectors, word vectors also need to ensure that the spatial distances of words with similar semantics should be similar in the method of word vector representation. such as 'China'-'Beijing' -'Britain'-'London'. The above conditions can be satisfied when the vectors of the following words are distributed,'Beijing'= (1.1, 2.2),'China'= (1.2, 2.3),'London'= (1.5, 2.4),'Britain'= (1.6, 2.5). The general training word vector can use the google open source word2vec program.
II. Combination of Convolutional Neural Networks and Word Vectors
Convolutional neural networks are usually used to process two-dimensional (regardless of rgb) matrices such as images. For example, a picture can usually be represented as a two-dimensional array such as 255*255, which means that the picture is 255 pixels wide and 255 pixels high. So how to apply CNN to text? The answer is word vector.
We've just introduced the concept of word vector. Here's how to convert text into an image-like format by word vector. Generally speaking, a text can be regarded as a combination of a lexical sequence, such as a text content that is'writing code, changing the world'. It can be converted into a text sequence ('writing','code','change','world'), which is obviously a one-dimensional vector and cannot be processed directly with cnn.
But if we use word vectors to expand it, assuming that in a word vector,'write'= (1.1, 2.1),'code'= (1.5, 2.9),'change'= (2.7, 3.1),'world'= (2.9, 3.5), then ('write','code','change','world') the sequence can be rewritten as ((1.1, 2.1), (1.5, 2.9), (2.9, 3.5), (2.5), (2.9, 3.5), (obviously) the original sequence. The first text sequence is a vector of 4*1, and the rewritten text can be represented as a matrix of 4*2.
Generally speaking, any text sequence can be expressed as an array of m*d, the number of words in the m-dimensional text sequence, and the dimension of the d-dimensional word vector.
III. Design of Neural Network Structure for Text Classification
In this paper, the concepts of word vector and convolution neural network are introduced. It is proposed that the text can be transformed into a two-dimensional matrix nested by word sequence and word vector, and processed by CNN. The following example illustrates how to design the style of the neural network with the task of text categorization.
3.1 Process of Text Preprocessing
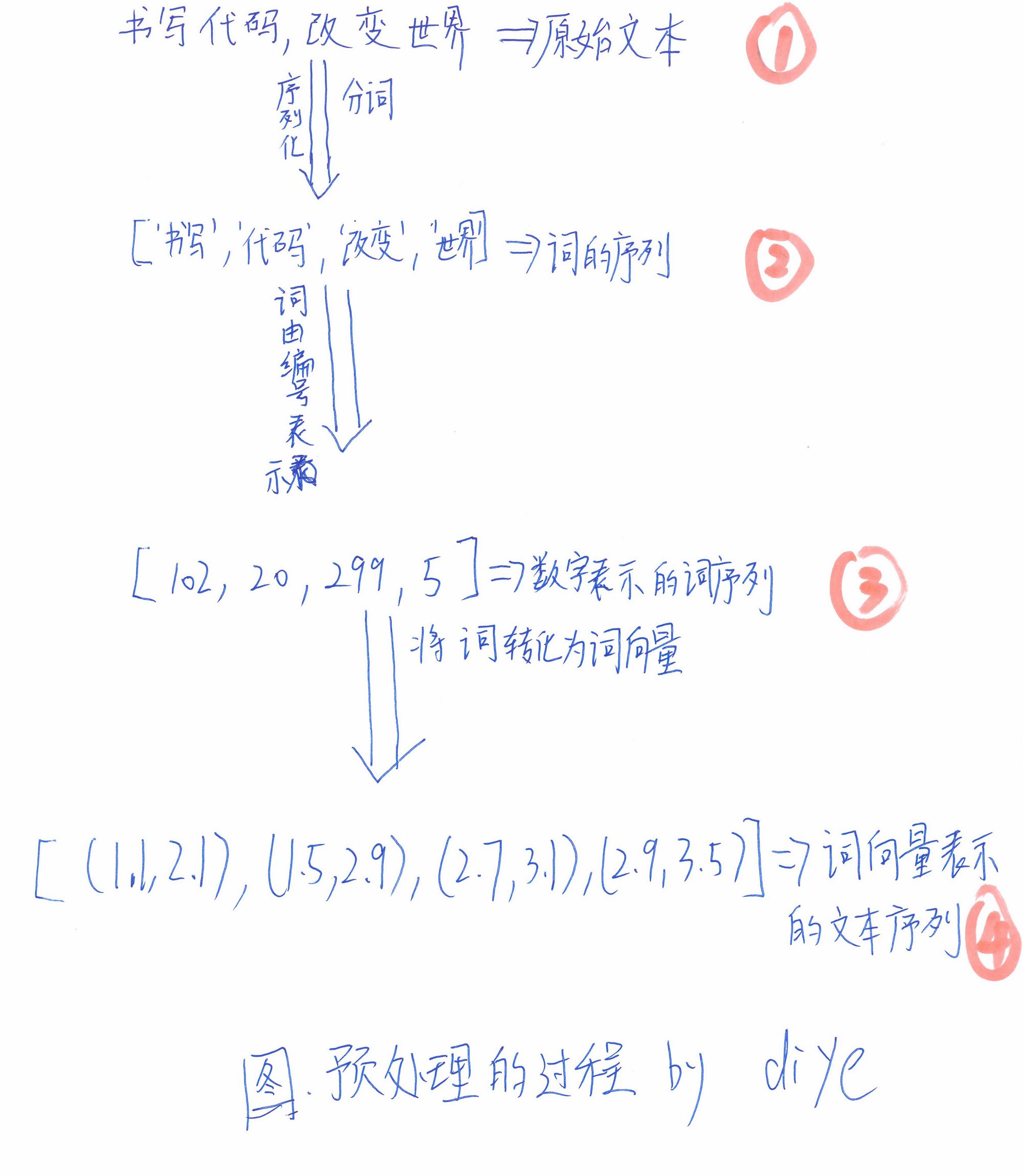
This part consists of three steps and four states.
1. Segmenting the original text and converting it into a sequence of words.
2. Converting word sequences into sequences with word numbers (each word in a glossary has a unique number) as elements
3. Expand each element (a word) in the sequence of word numbers into the form of word vectors. The following is a picture. (I draw a sketch by hand.) To represent this process, as shown in the following figure:
Design of 3.2 Neural Network Module
The idea of neural network design in this paper comes from the following blog posts:
Http://www.wildml.com/2015/12/implementation-a-cnn-for-text-classification-in-tensorflow/ Because this article is pure English, some readers may not be accustomed to reading this kind of literature. I will illustrate the neural network used in this paper by combining a neural network design diagram, the specific design diagram (also a hand-drawn, _) is as follows:
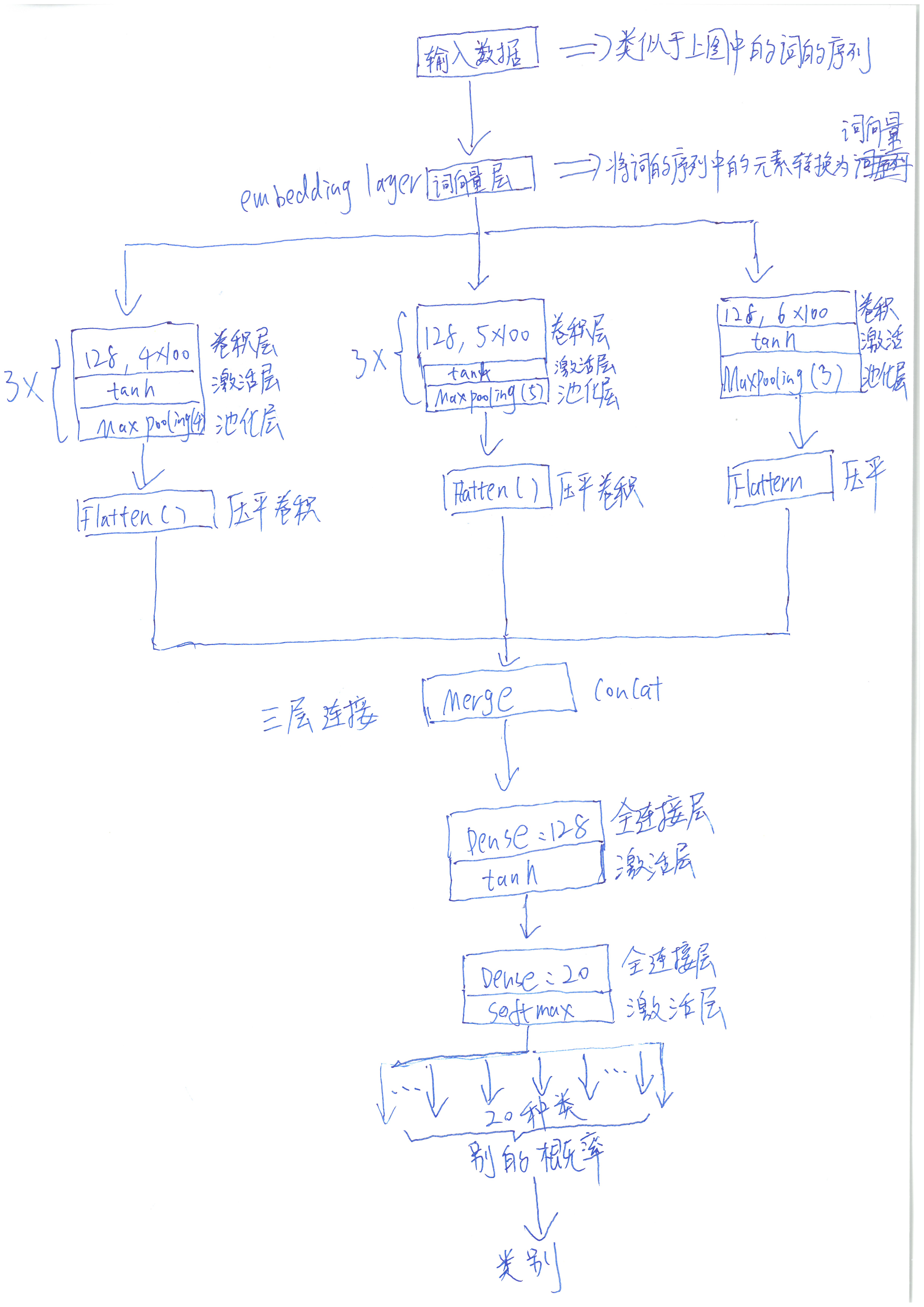
In the first layer, the text sequence is expanded into a sequence of word vectors. Then the convolution layer, the activation layer and the pooling layer are connected. Because of the different size of the convolution window, three convolution layers are placed in parallel and three in vertical direction (the combination of convolution layer, activation layer and pooling layer). Then connect the whole face layer and the activation layer. The activation layer uses soft Max and outputs the probability that the text belongs to a certain class.
3.3 Framework and Data Set for Programming Implementation
3.3.1 Framework: This paper uses keras framework to write neural network. For the introduction of keras, please refer to the Chinese document of keras translated by Moyan Dashen: http://keras-cn.readthedocs.io/en/latest/.
3.3.2 Data Set: Text Training Set is from 20_news group, which includes 20 news texts. The download address is as follows: http://www.qwone.com/~jason/20News groups./
3.3.3 Word Vector: Although the keras framework already has embedding layer, this paper uses glove word vector as the pre-training word vector. The introduction and download address of glove are as follows (opening will be slower):
http://nlp.stanford.edu/projects/glove/
3.4 Code and Relevant Annotations
In Part 3.2, the design part of the neural network has been introduced through a graph, but considering the lack of intuition, the code used here is listed as follows. With keras programming, the key parts have been listed and annotated. Some of the code is from the example directory in the keras document:
pretrained_word_embeddings.py, but there are some bug s that I can't train when I run the program, so I have made many changes. The most important thing is that I changed the activation layer from relu to tanh, and the overall design structure has also changed fundamentally. For those interested in keras original demo, see:
http://keras-cn.readthedocs.io/en/latest/blog/word_embedding/
Following is the text categorization code used in this article:
'''This program will train a 20-class text classifier, the data source is 20 Newsgroup dataset
GloVe The download address of the word vector is as follows:
http://nlp.stanford.edu/data/glove.6B.zip
20 Newsgroup Data sets come from:
http://www.cs.cmu.edu/afs/cs.cmu.edu/project/theo-20/www/data/news20.html
'''
from __future__ import print_function
import os
import numpy as np
np.random.seed(1337)
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils.np_utils import to_categorical
from keras.layers import Dense, Input, Flatten
from keras.layers import Conv1D, MaxPooling1D, Embedding
from keras.models import Model
from keras.optimizers import *
from keras.models import Sequential
from keras.layers import Merge
import sys
BASE_DIR = '.' # Here is the current directory
GLOVE_DIR = BASE_DIR + '/glove.6B/' # Change according to actual directory name
TEXT_DATA_DIR = BASE_DIR + '/20_newsgroup/' # Change according to actual directory name
MAX_SEQUENCE_LENGTH = 1000 # The longest length of each text can be selected, and shorter text can be set shorter.
MAX_NB_WORDS = 20000 # In the dictionary of the whole lexicon, the number of words can be slightly increased or reduced.
EMBEDDING_DIM = 50 # The dimension of word vector can be used according to the actual situation. If you don't understand it, don't change it for the time being.
VALIDATION_SPLIT = 0.4 # This is used as the proportion of the test set, and the word itself means the verification set.
# first, build index mapping words in the embeddings set
# The phrase to their embedding vector refers to the establishment of an index between a word and a word vector, such as the word vector corresponding to peking may be (0.1, 0, 32,... 0.35, 0.5) and so on.
print('Indexing word vectors.')
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, '../data/glove.6B.50d.txt')) # Read a 50-dimensional word vector file and change it to 100-dimensional or something.
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
print('Found %s word vectors.' % len(embeddings_index))
# second, prepare text samples and their labels
print('Processing text dataset') # The main function of this code is to read in the training sample, read in the corresponding label, and assign a number to each word that appears, such as the word peking corresponding number 100.
texts = [] # list for storing training samples
labels_index = {} # A dictionary from word to word number, such as peking corresponding to 100
labels = [] # Store training samples, text with category number, e.g. article a belongs to category 1
for name in sorted(os.listdir(TEXT_DATA_DIR)):
path = os.path.join(TEXT_DATA_DIR, name)
if os.path.isdir(path):
label_id = len(labels_index)
labels_index[name] = label_id
for fname in sorted(os.listdir(path)):
if fname.isdigit():
fpath = os.path.join(path, fname)
if sys.version_info < (3,):
f = open(fpath)
else:
f = open(fpath, encoding='latin-1')
texts.append(f.read())
f.close()
labels.append(label_id)
print('Found %s texts.' % len(texts)) # Number of training samples output
# finally, vectorize the text samples into a 2D integer tensor. The following code mainly converts the text into a text sequence, such as the text'I love China'into ['I love China','China'], then converts it into [101,231], and finally expands these numbers into word vectors, so that each text is a 2-dimensional matrix, which can participate in'II. Convolutional nerve' of this paper. A Chapter on the Combination of Network and Word Vector
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
labels = to_categorical(np.asarray(labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels.shape)
# split the data into a training set and a validation set. The following code mainly divides the data into training set and test set.
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels = labels[indices]
nb_validation_samples = int(VALIDATION_SPLIT * data.shape[0])
x_train = data[:-nb_validation_samples] # training set
y_train = labels[:-nb_validation_samples]# Label of training set
x_val = data[-nb_validation_samples:] # Test Set, originally intended as Verification Set in English
y_val = labels[-nb_validation_samples:] # Label of Test Set
print('Preparing embedding matrix.')
# The main part of preparing embedding matrix is to create a word vector matrix so that each word has its corresponding word vector.
nb_words = min(MAX_NB_WORDS, len(word_index))
embedding_matrix = np.zeros((nb_words + 1, EMBEDDING_DIM))
for word, i in word_index.items():
if i > MAX_NB_WORDS:
continue
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector # word_index to word_embedding_vector ,<20000(nb_words)
# load pre-trained word embeddings into an Embedding layer
# The first layer of the neural network, the word vector layer, uses the pre-trained glove word vector, which can be set as False.
embedding_layer = Embedding(nb_words + 1,
EMBEDDING_DIM,
input_length=MAX_SEQUENCE_LENGTH,
weights=[embedding_matrix],
trainable=True)
print('Training model.')
# train a 1D convnet with global maxpoolinnb_wordsg
#The first neural network of left model, convolution window is 5*50 (50 is word vector dimension)
model_left = Sequential()
#model.add(Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32'))
model_left.add(embedding_layer)
model_left.add(Conv1D(128, 5, activation='tanh'))
model_left.add(MaxPooling1D(5))
model_left.add(Conv1D(128, 5, activation='tanh'))
model_left.add(MaxPooling1D(5))
model_left.add(Conv1D(128, 5, activation='tanh'))
model_left.add(MaxPooling1D(35))
model_left.add(Flatten())
#The second neural network of right model, convolution window is 4*50
model_right = Sequential()
model_right.add(embedding_layer)
model_right.add(Conv1D(128, 4, activation='tanh'))
model_right.add(MaxPooling1D(4))
model_right.add(Conv1D(128, 4, activation='tanh'))
model_right.add(MaxPooling1D(4))
model_right.add(Conv1D(128, 4, activation='tanh'))
model_right.add(MaxPooling1D(28))
model_right.add(Flatten())
#The third model is the third neural network. The convolution window is 6*50.
model_3 = Sequential()
model_3.add(embedding_layer)
model_3.add(Conv1D(128, 6, activation='tanh'))
model_3.add(MaxPooling1D(3))
model_3.add(Conv1D(128, 6, activation='tanh'))
model_3.add(MaxPooling1D(3))
model_3.add(Conv1D(128, 6, activation='tanh'))
model_3.add(MaxPooling1D(30))
model_3.add(Flatten())
merged = Merge([model_left, model_right,model_3], mode='concat') # Connecting the convolution layers of three different convolution windows together, of course, can only use one of the three model s, which can achieve good results. This paper only uses the structure design in the paper.
model = Sequential()
model.add(merged) # add merge
model.add(Dense(128, activation='tanh')) # Full Connection Layer
model.add(Dense(len(labels_index), activation='softmax')) # softmax, the probability that the output text belongs to each of the 20 categories
# Optimizer I use adadelta here, but I can use other methods as well.
model.compile(loss='categorical_crossentropy',
optimizer='Adadelta',
metrics=['accuracy'])
# = Now start training, nb_epoch is the number of iterations, can be higher, the training effect will be better, but the training will slow down.
model.fit(x_train, y_train,nb_epoch=3)
score = model.evaluate(x_train, y_train, verbose=0) # The accuracy of the evaluation model in training concentration is about 99%.
print('train score:', score[0])
print('train accuracy:', score[1])
score = model.evaluate(x_val, y_val, verbose=0) # The accuracy of the evaluation model in the test set is about 97%, and the number of iterations will be increased further.
print('Test score:', score[0])
print('Test accuracy:', score[1])