Hadoop data processing (sophomore training in 2020)
1, Project background
The training content is the statistical analysis of automobile sales data. Through this project, we will deepen our understanding of HDFS distributed file system and MapReduce distributed parallel computing framework, master and apply them skillfully, experience the development process of big data enterprise practical projects, and accumulate experience in actual project development.
2, Project development practice
(1) Analysis of design ideas
1. Task 7:
Statistical analysis of sales data of different models our demand is to count the total sales volume of various types of vehicles in a month. Here, we take September as an example. Then we need to filter out the total sales array of vehicles in September, then group them according to types, and finally make statistics for the data in each group. Map stage: first, write a map class to inherit from Mapper, rewrite the map method, filter out the month with "9" under the map class, use the equals() method to compare whether the data in the string is "9", and use the trim() method to remove the empty part, and then use context The write () method outputs the key and value values. In the Reduce stage: after that, the write Reduce class inherits from the Reducer, rewrites the rdreduce method, and calculates the sales quantity of cars under the Reduce class. First, define and assign a data type to store the total sales, then use for() to traverse the whole array to calculate the total, and finally output the calculation result. Job stage: create a main function, create a job object, create a new job task, set the main class of job operation, set Mapper and Reducer during job operation, set the intermediate output result of map, set the output type of job, set the input file path and output file path of job processing, and finally submit the job task.
2. Task 8:
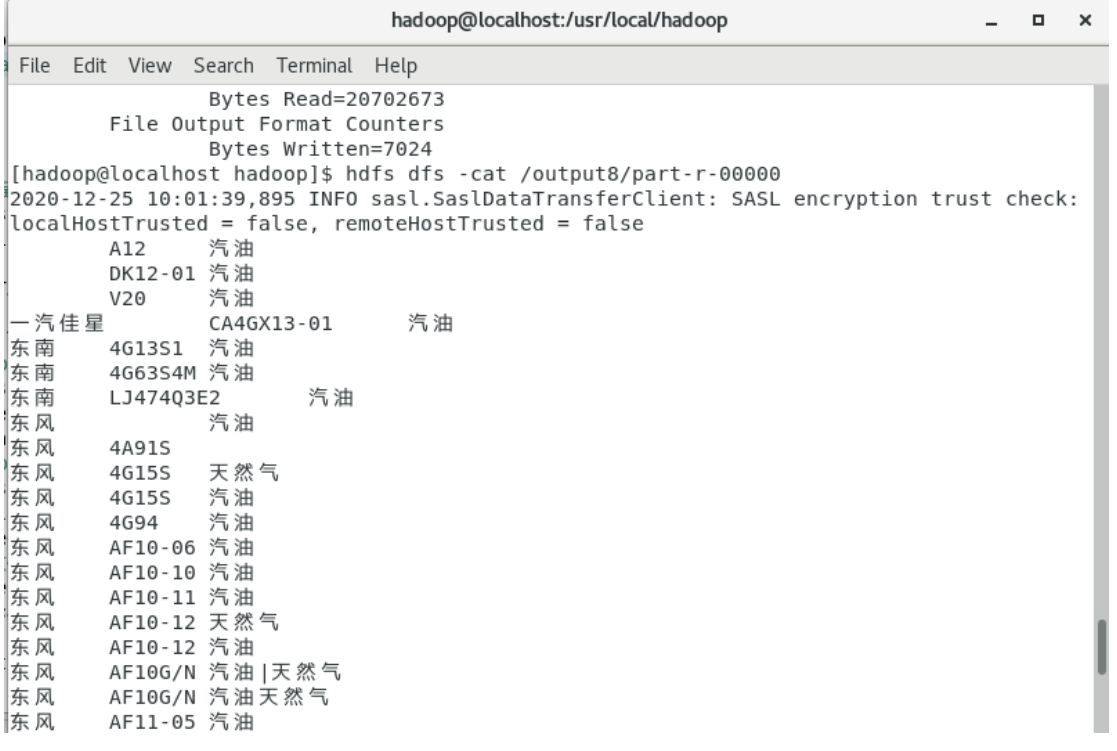
The engine models and fuel types are counted according to the sales of different types (brands). If you want to count the engine models and fuel types of vehicles of different brands, you need to group them according to brands, engine models and fuel types, and then output the contents after grouping. Map stage: in the map stage, first group according to brand, engine model and fuel type. Columns 8, 13 and 16 in the csv table represent brand, engine model and fuel type respectively. First define an array str [] of String type, and the subscript in the array starts from 0, so brand, engine model, The fuel type is represented in the array as str[7], str[12],str[15], and then the context outputs key and value values, that is, brand, engine model and fuel type. Reduce phase: reduce inherits the Reducer and rewrites the reduce method. Since this task only needs to count the engine models and fuel types under different brands and does not need to calculate the quantity, it does not need to use for() and calculation operations. It only needs to output key and value in a blank text format. Job stage: create a main function, create a job object, create a new job task, set the main class of job operation, set Mapper and Reducer during job operation, set the intermediate output result of map, set the output type of job, set the input file path and output file path of job processing, and finally submit the job task.
(2) Code design and writing
Note: / / the comments are code explanations
Task 7: statistical analysis of sales data of different models
The code part is as follows:
package com.jsnl;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//Write a Map class to inherit Mapper class
class Map extends Mapper<Object, Text, Text, IntWritable> {
//Rewrite map method
@Override
protected void map(Object key, Text value,Context context
)
throws IOException, InterruptedException {
//Word segmentation operation, write a string data, and separate the strings in the data with commas. (Note: the array subscript starts from 0)
String[] str = value.toString().split(",");
/*if Judge whether the string is not empty and whether the length is 39 lines
str[1]Month, str[7] brand, equals()
Method is used to compare whether the contents of two strings are equal, such as the array str in the second column of the table
The string with subscript 1 is "9",
trim()Remove the spaces at the beginning and end of the string*/
if(str != null && str.length == 39 && str[1].trim() != null
&& str[1].equals("9")&&str[7].trim() != null && str[11].trim() !=
null) {
//context outputs the values of key and value, that is, the values of automobile brand and automobile sales quantity in September
context.write(new Text(str[1]+","+str[7]), new
IntWritable(1));
}
}
}
//Write a class to inherit the Reducer class
class Reduce extends Reducer<Text, IntWritable, Text,
IntWritable> {
//Override reduce method
protected void reduce(Text key, Iterable<IntWritable>
value,Context context)
throws IOException, InterruptedException {
//Define a variable sum of type int to store the value of statistical quantity
int sum = 0;
//Traverse the array or collection value of IntWritable type, and then use the get() method to get the value of v
Add calculated total sum
for(IntWritable v : value) {
sum+=v.get();
}
//context outputs key and value values
context.write(key, new IntWritable(sum));
}
}
//The main() method starts the running program
public class CarSales {
public static void main(String[] args) throws Exception {
//Create job task
Job job = Job.getInstance(new Configuration());
//Specify task entry
job.setJarByClass(CarSales.class);
//Then an Exception will be generated and thrown directly
//Mapper and output of tasks
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Reducer and output of tasks
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//Specify the input and output of the task
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Perform tasks
job.waitForCompletion(true);
}
}Task 8: count engine models and fuel types
The code part is as follows:
package com.jsnl;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
//Map class inherits Mapper class
class Map extends Mapper<Object, Text, Text, IntWritable> {
//Rewrite map method
protected void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//Word segmentation operation, write a string data, and separate the strings in the data with commas. (Note: the array subscript is from 0
start)
String []str = value.toString().split(",");//str[7] brand, str[12] engine model, str
[15]Fuel type,trim()Remove the spaces at the beginning and end of the string
if(str!=null&&str.length==39&&str[7].trim()!=null&&str[12].trim()!=null&&str[15].trim()!=null) {
//context outputs key and value values, i.e. brand, engine model and fuel type
context.write(new Text(str[7]+"\t"+str[12]+"\t"+(str[15])), new IntWritable(1));
}
}
}
//The Reduce class inherits the Reducer class
class Recuce extends Reducer<Text, IntWritable, Text, Text> {
//Override reduce method
protected void reduce(Text key, Iterable<IntWritable>
value,Context context)
throws IOException, InterruptedException {
//context output key,value value, Text("") null value of text type
context.write(key, new Text(" "));
}
}
//The main class, the main() method, starts the running program
public class TypesOfStatistics {
public static void main(String[] args) throws Exception {
//Create job task
Job job = Job.getInstance(new Configuration());
//Set the main class of Job run
job.setJarByClass(TypesOfStatistics.class);
//Task Mapper and set the output type of Job
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//Task Reduce and set the output type of Job
job.setReducerClass(Recuce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//Set the input file path and output file path for Job processing
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//Perform Job tasks
job.waitForCompletion(true);
}
}(3) Display of operation results
Task 7: statistical analysis of sales of different models

III. training experience
Through a week-long Hadoop training, the training task of this week was completed under the guidance of the teacher. Through a week's training and learning, I have a general understanding of this framework and can write a simple MapReduce program by myself. On the first day of the training, the teacher gave us a task to make statistical analysis of the car sales data. The first day's task is to give a basic framework and fill in the blanks on the existing code. The next day, the third day, in a step-by-step process, less and less code is given, and more and more code needs to be written by yourself, until you don't give the code framework and write your own code. After the teacher's guidance, let us think independently for code programming, which can improve our independent thinking ability and programming ability. Because the previous experiments did not understand the principle and did not deeply analyze the meaning of the code, I began to try to analyze how to write the map and reduce function. Previously, the basic knowledge of Java in freshman was not solid and the principle of MapReduce was not familiar enough. Although relevant materials were searched, errors were still unavoidable. During the experiment, we encountered many problems based on java basic syntax, such as class inheritance, method overloading and forced type conversion. We still don't understand the principle of MapReduce in Hadoop. But finally, through the guidance of teachers, CSDN website, Baidu's reference and their own independent thinking, the problems were finally solved. Therefore, I learned a lot through this statistical analysis project of automobile sales data. Improved my ability to write java code, deepened my understanding of Hadoop related components and their principles, basically understood the HDFS distributed file system and MapReduce distributed parallel computing framework, and was able to master and apply it skillfully. I also experienced the development process of big data enterprise practical projects and accumulated experience in actual project development.