If the cost of creating objects is relatively large, and there is little difference between different objects of the same class (most fields are the same), in this case, we can create new objects by copying (or copying) existing objects (prototypes), so as to save creation time. This method of creating objects based on prototypes is called Prototype Design Pattern, which is called prototype pattern for short.
What is "the creation cost of objects is relatively large"?
In fact, it takes too much time for the system to create a variable, or it doesn't take too much time for the system to assign a value to the member. Applying a complex pattern can only get a little performance improvement. This is the so-called over design. The gain is not worth the loss.
However, if the data in the object needs to be obtained through complex calculation (such as sorting and calculating hash value), or it needs to be read from very slow IO such as RPC, network, database and file system, in this case, we can use the prototype mode to directly copy it from other existing objects instead of creating a new object every time, Repeat these time-consuming operations.
So it's still a comparative theory. Next, let's explain this passage through an example.
Suppose that about 100000 pieces of "search keyword" information are stored in the database, and each piece of information includes keywords, the number of times keywords are searched, and the time when the information has been updated recently. When system A starts, it will load this data into memory to deal with some other business requirements. In order to find the information corresponding to A keyword conveniently and quickly, we establish A hash table index for the keyword.
If you are familiar with the Java language, you can directly use the HashMap container provided in the language to implement it. Among them, the key of HashMap is the search keyword, and the value is the keyword details (such as search times). We just need to read the data from the database and put it into HashMap.
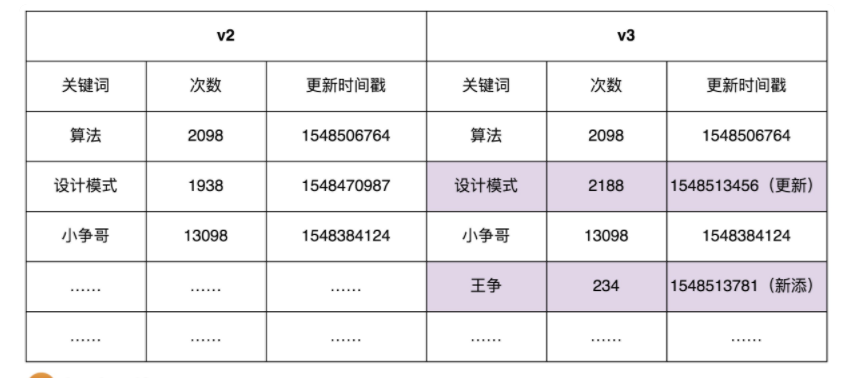
However, we also have another system B, which is specially used to analyze the search log, update the data in the database regularly (for example, every 10 minutes) and mark it as a new data version. For example, in the following example figure, we update the data of v2 version to get the data of v3 version. Here, we assume that there are only updates and new keywords, and there is no behavior of deleting keywords.
In order to ensure the real-time performance of the data in system A (not necessarily very real-time, but the data can not be too old), system A needs to regularly update the index and data in memory according to the data in the database.
How can we achieve this requirement? In fact, it's not difficult.
We only need to record the update time Ta corresponding to the version Va of the current data in system A, and retrieve all search keywords with an update time greater than Ta from the database, that is, find the "difference set" between the Va version and the latest version of the data, and then process each keyword in the difference set. If it already exists in the hash table, we will update the corresponding search times, update time and other information; If it does not exist in the hash table, we insert it into the hash table.
According to this design idea, the example code I give is as follows
public class Demo {
private ConcurrentHashMap<String, SearchWord> currentKeywords = new ConcurrentHashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// Take out the data with update time > lastupdatetime from the database and put it into currentKeywords
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (currentKeywords.containsKey(searchWord.getKeyword())) {
currentKeywords.replace(searchWord.getKeyword(), searchWord);
} else {
currentKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: fetch the data with update time > lastupdatetime from the database
return null;
}
}
However, now, we have a special requirement: at any time, all data in system a must be the same version, either version a or version b. there can be neither version a nor version b. The just updated method can't meet this requirement. In addition, we also require that when updating memory data, system a cannot be unavailable, that is, it cannot be stopped to update data.
How can we realize the current demand? In fact, it's not difficult. We define the version of the data we are using as "service version". When we want to update the data in memory, we do not update it directly on the service version (assuming version a data), but re create another version of data (assuming version b data). After the new version of data is built, Switch the service version from version a to version b again. This not only ensures that the data is always available, but also avoids the existence of intermediate states.
According to this design idea, the example code I give is as follows:
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
public void refresh() {
HashMap<String, SearchWord> newKeywords = new LinkedHashMap<>();
// Take out all the data from the database and put it into newKeywords
List<SearchWord> toBeUpdatedSearchWords = getSearchWords();
for (SearchWord searchWord : toBeUpdatedSearchWords) {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords() {
// TODO: fetch all data from the database
return null;
}
}
However, in the above code implementation, the cost of building newKeywords is relatively high. We need to read the 100000 pieces of data from the database, then calculate the hash value and build newKeywords. This process is obviously time-consuming. In order to improve efficiency, the prototype model comes in handy.
We copy the data of currentKeywords into newKeywords, and then extract only new or updated keywords from the database and update them into newKeywords. Compared with 100000 data, the number of keywords added or updated each time is relatively small. Therefore, this strategy greatly improves the efficiency of data update.
According to this design idea, the example code I give is as follows:
public class Demo {
private HashMap<String, SearchWord> currentKeywords=new HashMap<>();
private long lastUpdateTime = -1;
public void refresh() {
// The prototype mode is as simple as copying the data of existing objects and updating a small amount of difference
HashMap<String, SearchWord> newKeywords = (HashMap<String, SearchWord>) currentKeywords.clone();
// Take the data with update time > lastupdatetime from the database and put it into newKeywords
List<SearchWord> toBeUpdatedSearchWords = getSearchWords(lastUpdateTime);
long maxNewUpdatedTime = lastUpdateTime;
for (SearchWord searchWord : toBeUpdatedSearchWords) {
if (searchWord.getLastUpdateTime() > maxNewUpdatedTime) {
maxNewUpdatedTime = searchWord.getLastUpdateTime();
}
if (newKeywords.containsKey(searchWord.getKeyword())) {
SearchWord oldSearchWord = newKeywords.get(searchWord.getKeyword());
oldSearchWord.setCount(searchWord.getCount());
oldSearchWord.setLastUpdateTime(searchWord.getLastUpdateTime());
} else {
newKeywords.put(searchWord.getKeyword(), searchWord);
}
}
lastUpdateTime = maxNewUpdatedTime;
currentKeywords = newKeywords;
}
private List<SearchWord> getSearchWords(long lastUpdateTime) {
// TODO: fetch the data with update time > lastupdatetime from the database
return null;
}
}
Here we use the clone() syntax in Java to copy an object. If the language you are familiar with does not have this syntax, it is acceptable to take the data from currentKeywords one by one, and then recalculate the hash value and put it into newKeywords. After all, the most time-consuming operation is the operation of fetching data from the database. Compared with the IO operation of the database, the time-consuming of memory operation and CPU calculation can be ignored. However, I don't know if you have found it. In fact, there is a problem with the code implementation just now.
To figure out what the problem is, we need to understand two other concepts: Deep Copy and Shallow Copy.
summary
- Prototype pattern is to create objects by copying
reflection
- Why use prototype mode?
- When do I need to use prototype patterns?
- What is deep copy? What is shallow copy?
reference resources
47 | prototype mode: how to clone a HashMap hash table most quickly?