transformer was published by Google in 2017 attention is all you need The seq2seq model mentioned in, our commonly used Bert and GPT are derived from transformer. This paper mainly refers to the work of wmathor Transformer details and PyTorch implementation of Transformer Two articles. The first one has explained the principle of transformer in detail. This paper mainly explains the code further combined with the implementation of the code and my own understanding. See for all codes My GitHub Library
Data preprocessing
Data set and Thesaurus
In terms of data preprocessing, in order to reduce the difficulty of code reading, the following code manually inputs two teams of German -- > English sentences and corresponding codes. In order to divide sentences, there are three symbols: S, E and P. the specific functions of each part are annotated in the code
'''
@author xyzhrrr
@time 2021/2/3
'''
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
'''
Data preprocessing
Instead of using a large data set, two pairs of German were entered manually→English sentences,
In addition, the index of each word is also manually hard coded, mainly to reduce the difficulty of reading the code,
Pay more attention to the part of model implementation
S: Symbol that shows starting of decoding input
E: Symbol that shows starting of decoding output
P: If the current batch data size is shorter than the time step, the symbol of the blank sequence will be filled
'''
sentences = [
# encoder input #decoder input #decoder output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
#The padding should be 0. Because it is a translation, there are two word lists in two languages
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola' : 5}
#The length of the Source thesaurus. The serial number is directly filled in here. In practice, the thesaurus should be used for query
src_vocab_size=len(src_vocab)#Input length, one hot length
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
#Target thesaurus serial number
idx2word={i: w for i,w in enumerate(tgt_vocab)}
#Table with serial number converted to this
tgt_vocab_size=len(tgt_vocab)#Output one hot length
src_len=5 #Maximum sentence length entered by encoder
tgt_le=6#Maximum sentence length of input and output of decoder
'''
Implementation of generating tensor and data set processing class
The following two functions generate data tensor generation and data set processing classes respectively, and the second one directly inherits from the implementation of torch.
-
For setence data, we know that each line corresponds to a corresponding sentence squadron in German and English, and the number of lines is the size of this batch size. By dividing them and encoding them according to thesaurus, you can get encoder input, decoder input and decoder input. Here you can refer to the following figure:
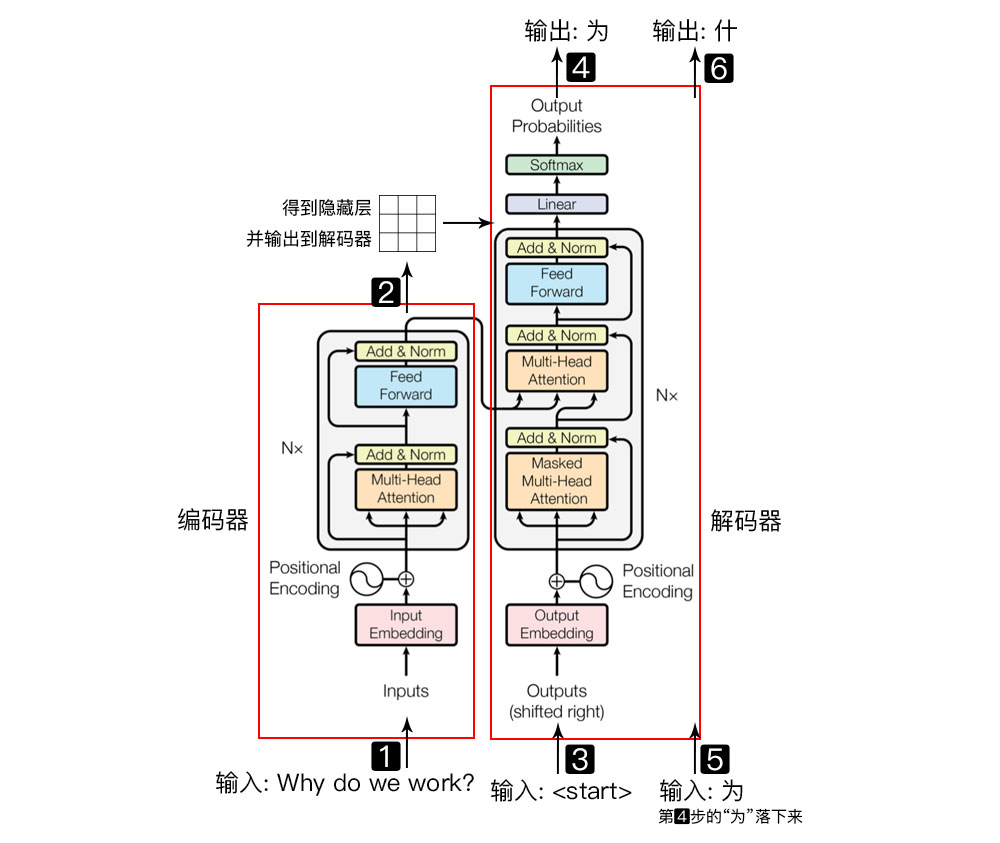
The above figure shows the Transformer model, which is mainly divided into two parts: Encoder and decoder. The Encoder is responsible for insinuating the input (language sequence) into a hidden layer (the part represented by the Jiugong grid in step 2 in the figure below), and then the decoder maps the hidden layer into a natural language sequence. For example, the example of machine translation in the figure below (when the decoder is output, a token is output only through the N-layer Decoder Layer, not through one layer Decoder Layer. The figure above only gives the layer diagram of one layer). When training, encoder_input and decoder_input is to train the model to learn data information and comparison relationship_ Output is the real data used to compare with the actual prediction output. It will modify the model by calculating the loss function of the output part of the decoder after learning two inputs. -
For class MyDataSet(), it inherits from data Dataset is to integrate the data transformed into tensor into a data set for subsequent data loading and processing. Finally, data Dataloader loads the data set. The three parameters here are the selected data set, the size of minibatch, and whether to disturb the data set.
'''
@:param sentenses data set
@:returns Tensor of data
The default data is floattensor Type, we need plastic surgery, so use longtensor
'''
def make_data(sentenses):
enc_inputs,dec_inputs,dec_outputs=[],[],[]
for i in range(len(sentenses)):
#split() takes spaces as separators, that is, removes spaces
enc_input=[[src_vocab[n] for n in sentenses[i][0].split()]]
#Read the input data and convert it into serial number representation. After adding inputs: [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input=[[tgt_vocab[n]for n in sentenses[i][1].split()]]
#[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]]
# [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
#Append multiple values from another sequence at the end of the list at one time
return torch.LongTensor(enc_inputs),torch.LongTensor(dec_inputs),torch.LongTensor(dec_outputs)
enc_inputs,dec_inputs,dec_outputs=make_data(sentences)
#Get data tensor
'''
Data processing class
'''
class MyDataSet(Data.Dataset):
def __init__(self,enc_inputs,dec_inputs,dec_outputs):
self.enc_inputs=enc_inputs
self.dec_inputs=dec_inputs
self.dec_outputs=dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
#Returns the number of rows, that is, the size of the dataset
def __getitem__(self, item):
return self.enc_inputs[item],self.dec_inputs[item],self.dec_outputs[item]
#Return the contents of corresponding data
#Load dataset
loader=Data.DataLoader(dataset=MyDataSet(enc_inputs, dec_inputs, dec_outputs),
batch_size=2, #Batch size, how much data is processed at a time
shuffle=True)
Some parameters
The meanings of the following variables are
- Word embedding & the dimension of position embedding. These two values are the same, so just use one variable
- Number of hidden neurons in FeedForward layer
- Q. The dimensions of K and V vectors, in which the dimensions of Q and K must be equal, and the dimension of V has no limit, but I set it to 64 for convenience
- Number of encoders and decoders
- Number of head s in bulls' attention
''' Transformer Parameters ''' d_model=512 #Embedding size word embedding size d_ff=2048 # FeedForward dimension d_k = d_v = 64 # dimension of K(=Q), V n_layers = 6 # number of Encoder and Decoder Layer n_heads = 8 # number of heads in Multi-Head Attention
position encoding
Since the Transformer model does not have the iterative operation of cyclic neural network, we must provide the Transformer with the position information of each word, so that it can recognize the order relationship in the language
Now define a concept of location embedding, that is, Positional Encoding. The dimension of location embedding is [max_sequence_length, embedding_dimension]. The dimension of location embedding is the same as that of word vector_ dimension. max_ sequence_ Length is a super parameter, which limits the maximum number of words in each sentence
-
Note that we generally train the Transformer model in words. First, initialize the size of the word encoding as [vocab_size, embedding_dimension], vocab_ Size is the number of all words in the font, embedding_ Dimension is the dimension of word vector, corresponding to PyTorch, which is actually NN Embedding(vocab_size, embedding_dimension)
-
In this paper, the linear transformation of sin and cos functions is used to provide the model location information:
The specific understanding of position function can refer to this article Positional Encoding in Transformer