What is distributed lock?
Control the access priority of multiple modules in distributed architecture
To introduce distributed lock, we should first mention that thread lock and process lock correspond to distributed lock.
Thread Lock: mainly used to Lock methods and code blocks. When a method or code uses a Lock, only one thread executes the method or code segment at the same time. Thread Lock is only effective in the same JVM, because the implementation of thread Lock basically depends on the shared memory between threads. For example, synchronized is the shared object header, and the display Lock shares a variable (state).
Process lock: in order to control multiple processes in the same operating system to access a shared resource, because processes are independent, each process cannot access the resources of other processes, so process lock cannot be realized through synchronized and other thread locks.
Distributed lock: when multiple processes are not in the same system, the distributed lock is used to control the access of multiple processes to resources.
When do distributed locks need to be used
For example:
For example, for inventory, distributed locks are needed for shared resources. If distributed locks are not used, it is likely to cause oversold.
Distributed locks are also locks
-
In a single application, if multiple threads want to access shared resources, we usually use the locking mechanism between threads. At a certain time, only one thread can operate on this resource, and other threads need to wait for the release of the lock. There are also some locking mechanisms in Java, such as synchronized.
-
In the distributed environment, when a resource can be accessed and used by multiple systems, in order to ensure the consistency of data access, it is required that it can only be used by one system at the same time. At this time, the locking mechanism between threads cannot work, because in the distributed environment, the system will be deployed to different machines, Then you need [distributed lock].
When do I need to use distributed locks
To sum up, when multiple clients need to access and operate the same resource and maintain the consistency of the resource, they need to use distributed lock to make multiple clients mutually exclusive to access the shared resources.
Take an example to illustrate:
- There are multiple batch tasks, and two machines process them at the same time. If there is no control, it is likely that the same batch will be processed by two machines respectively; If a distributed lock is used, a task will only be received by one machine when receiving a task, so it will not cause repeated execution of the task;
-
Think more. If machine A receives task 1 from machine A and machine B for processing, and machine A hangs up halfway through the processing, the batch task will not be executed smoothly unless machine A can be restored.
At this time, you can know what the distributed lock needs to do
- Exclusivity: only one client can obtain the lock at the same time, and other clients cannot obtain it at the same time;
- Avoid deadlock: the lock is valid for a period of time and will be released after that time (normal release or abnormal release);
- High availability: the mechanism for obtaining or releasing locks must be highly available and have good performance.
Usage scenario
When your back-end services exist in the form of clusters, you must need distributed locks. Cluster is different from distributed, and the distributed and distributed locks here are not the same thing. Cluster can mean that multiple servers meet the same requirements. For example, there are three Tomcat servers, all of which are responsible for the query module; Distributed refers to the different function points of multiple servers. The integration of multiple functions is a complete service. For example, one Tomcat is responsible for query and one is responsible for ordering.
Back to the cluster, when the back-end cluster wants to access the same resource, it needs to lock the resource to ensure that only one object can modify the resource data at the same time. What will happen if it is not locked?
For example:
Two threads (T1 and T2 respectively) do the same thing, get A resource called A, and then + 1 it. Since threads do not communicate with each other, the following situations may occur:
T1 gets A and reads it into memory. At this time, the value of A is t;
T2 gets A and reads it into memory. At this time, the value of A is t;
T1 performs + 1 operation. At this time, the actual value of A is T+1;
T2 performs + 1 operation. At this time, the actual value of A is still T+1;
However, at this time, A performs + 1 operation through two threads, which should be T+2. Therefore, it can be seen that if there is no distributed lock, there will be data inconsistency. If the above simple calculation is OK, if it is your bank account without distributed lock, two people give you money at this time. As A result, only one person's money has arrived, and the other's money has been confiscated by the bank as ownerless money, it must not be possible.
Therefore, ensuring data consistency and accuracy is the importance of distributed locks.
Distributed solutions
For the implementation of distributed lock, the following schemes are commonly used:
1: realize distributed lock based on Database
2: implement distributed locking based on redis (redis, memcached, tail)
3: implement distributed lock based on Zookeeper
Before analyzing these implementation schemes, let's think about what kind of distributed locks we need? (take the method lock as an example, and the resource lock is the same.)
- It can ensure that in the distributed application cluster, the same method can only be executed by one thread on one machine at the same time.
- If this lock is a reentrant lock (avoid deadlock)
- This lock is preferably a blocking lock (consider whether to use this one according to business requirements)
- It has highly available lock acquisition and release functions
- The performance of acquiring and releasing locks is better
Implementation of distributed lock based on Database
Based on database table
The simplest way to implement distributed locks is to create a lock table directly and then operate the data in the table.
When we want to lock a method or resource, we add a record to the table. When we want to release the lock, we delete the record.
To create a database table:
CREATE TABLE `database_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT 'Locked resources',
`description` varchar(1024) NOT NULL DEFAULT "" COMMENT 'describe',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Database distributed lock table';When we want to obtain a lock, we can insert a piece of data:
INSERT INTO database_lock(resource, description) VALUES (1, 'lock');
Note: in the table database_ In lock, the resource field has a uniqueness constraint, so that if multiple requests are submitted to the database at the same time, the database can ensure that only one operation can succeed (others will report an error: ERROR 1062 (23000): Duplicate entry '1' for key 'uiq_idx_resource '), then we can think that the request with successful operation has obtained the lock.
When you need to release the lock, you can delete this data:
DELETE FROM database_lock WHERE resource=1;
This implementation method is very simple, but you should pay attention to the following points:
(1) This kind of lock has no expiration time. Once the operation of releasing the lock fails, the lock record will always be in the database, and other threads cannot obtain the lock. This defect is also easy to solve. For example, you can do a regular task to clean up regularly.
(2) The reliability of this lock depends on the database. It is recommended to set up a standby database to avoid single point and further improve reliability.
(3) This lock is non blocking, because an error will be reported directly after the failure of inserting data. If you want to obtain the lock, you need to operate again. If you need blocking, you can get a for loop or a while loop until INSERT succeeds.
(4) This lock is also non reentrant, because the same thread cannot obtain the lock again before releasing the lock, because the same record already exists in the database. If you want to realize the reentrant lock, you can add some fields in the database, such as the host information and thread information (5) of the lock. When you obtain the lock again, you can query the data first. If the current host information and thread information can be found, you can directly assign the lock to it.
Optimistic lock
As the name suggests, the system believes that the update of data will not produce conflict in most cases, and the conflict detection of data will be carried out only when the database update operation is submitted. If the detection result is inconsistent with the expected data, the failure information is returned.
Optimistic locks are mostly implemented based on the recording mechanism of data version. What is the data version number? That is, add a version ID to the data. In the version solution based on the database table, generally add a "version" field to the database table to read out the data. When reading out the data, read out the version number together, and then add 1 to this version number when updating. During the update process, the version number will be compared. If it is consistent and there is no change, the operation will be performed successfully; If the version numbers are inconsistent, the update fails.
In order to better understand the use of database optimistic lock in actual projects, here is a typical example of e-commerce inventory. An e-commerce platform will have an inventory of goods. When users buy, they will operate the inventory (inventory minus 1 means one has been sold). We use this inventory model with the following table optimal_ Lock, refer to the following:
CREATE TABLE `optimistic_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT 'Locked resources',
`version` int NOT NULL COMMENT 'Version information',
`created_at` datetime COMMENT 'Creation time',
`updated_at` datetime COMMENT 'Update time',
`deleted_at` datetime COMMENT 'Delete time',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='Database distributed lock table';Where: id represents the primary key; resource refers to the resources for specific operations, which refers specifically to inventory; Version indicates the version number.
Before using optimistic lock, ensure that there are corresponding data in the table, such as:
INSERT INTO optimistic_lock(resource, version, created_at, updated_at) VALUES(20, 1, CURTIME(), CURTIME());
If only one thread operates, the database itself can ensure the correctness of the operation. The main steps are as follows:
STEP1 - Get resources: SELECT resource FROM optimistic_lock WHERE id = 1 STEP2 - Execute business logic STEP3 - Update resources: UPDATE optimistic_lock SET resource = resource -1 WHERE id = 1
However, in the case of concurrency, some unexpected problems will arise: for example, when two threads purchase a commodity at the same time, the actual operation at the database level should be to reduce the inventory by 2. However, due to the high concurrency, after the first thread executes (STEP1 and STEP2 are executed but STEP3 is not completed), The second thread is purchasing the same goods (execute step 1). At this time, the queried inventory does not complete the action of reducing 1, so the inventory of the goods purchased by the two threads will be reduced by 1.
After introducing the version field, the specific operation will evolve into the following contents:
STEP1 - Get resources: SELECT resource, version FROM optimistic_lock WHERE id = 1 STEP2 - Execute business logic STEP3 - Update resources: UPDATE optimistic_lock SET resource = resource -1, version = version + 1 WHERE id = 1 AND version = oldVersion
In fact, optimistic locking can also be realized with the help of updated_at, which is similar to the way of using version field: the update operation front line obtains the current update time of the record, and when submitting the update, it detects whether the current update time is equal to the update timestamp obtained at the beginning of the update.
Optimistic locking has obvious advantages. Because it does not rely on the locking mechanism of the database itself when detecting data conflicts, it will not affect the performance of requests. When concurrency occurs and the amount of concurrency is small, only a small number of requests will fail. The disadvantage is that additional fields need to be added to the table design, which increases the redundancy of the database. In addition, when the application concurrency is high, the version value changes frequently, which will lead to a large number of request failures and affect the availability of the system. Through the above sql statements, we can also see that database locks all act on the same row of data records, which leads to an obvious disadvantage. In some special scenarios, such as big promotion, second kill and other activities, a large number of requests for row locks of the same record at the same time will have a great write pressure on the database. Therefore, combining the advantages and disadvantages of optimistic locking in database, optimistic locking is more suitable for scenarios with low concurrency and infrequent write operations.
Pessimistic lock
In addition to adding and deleting the records in the database table, we can also realize distributed locks with the help of the built-in locks in the database. Add FOR UPDATE after the query statement, and the database will add pessimistic lock, also known as exclusive lock, to the database table during the query. When a record is pessimistic locked, other threads can no longer add pessimistic locks to the line.
Pessimistic lock, contrary to optimistic lock, always assumes the worst case. It believes that the update of data will conflict in most cases.
While using pessimistic locks, we need to pay attention to the level of locks. MySQL InnoDB causes that when locking, only those who explicitly specify the primary key (or index) will execute row locking (only lock the selected data), otherwise MySQL will execute table locking (lock the whole data form).
When using pessimistic lock, we must turn off the automatic submission property of MySQL database (refer to the following example), because MySQL uses autocommit mode by default, that is, when you perform an update operation, MySQL will submit the results immediately.
mysql> SET AUTOCOMMIT = 0; Query OK, 0 rows affected (0.00 sec)
In this way, after using FOR UPDATE to obtain the lock, you can execute the corresponding business logic, and then use COMMIT to release the lock.
We might as well follow the previous database_lock table to express the usage. Suppose A thread A needs to obtain A lock and perform corresponding operations, its specific steps are as follows:
STEP1 - acquire lock: SELECT * FROM database_lock WHERE id = 1 FOR UPDATE;.
STEP2 - execute business logic.
STEP3 - release lock: COMMIT.
If another thread B executes STEP1 before thread A releases the lock, it will be blocked until thread A releases the lock. Note that if thread A does not release the lock for A long time, thread B will report an error. Refer to the following (lock wait time can be configured through innodb_lock_wait_timeout):
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
The above example demonstrates the process of specifying the primary key and querying the data (triggering row lock). If the data is not found, there is no "lock".
If the primary key (or index) is not specified and the data can be queried, the table lock will be triggered. For example, step 1 is changed to execution (the version here is only used as a common field, which has nothing to do with the optimistic lock above):
SELECT * FROM database_lock WHERE description='lock' FOR UPDATE;
Or if the primary key is not clear, the table lock will be triggered. For example, step 1 is changed to execute:
SELECT * FROM database_lock WHERE id>0 FOR UPDATE;
Note that although we can display the use of row level locks (specify the primary key or index that can be queried), MySQL will optimize the query. Even if the index field is used in the condition, whether to use the index to retrieve data is determined by MySQL by judging the cost of different execution plans. If MySQL thinks that the efficiency of full table scanning is higher, For example, for some small tables, it may not use indexes. In this case, InnoDB will use table locks instead of row locks.
In a pessimistic lock, every access to row data is exclusive. Only after the request transaction that is accessing the row data is committed can other requests access the data in turn, otherwise it will block the acquisition of the waiting lock. Pessimistic lock can strictly ensure the security of data access. However, the disadvantages are also obvious, that is, each request will incur additional locking overhead, and the request that does not obtain the lock will block the acquisition of the waiting lock. In the high concurrency environment, it is easy to cause a large number of request blocking and affect the system availability. In addition, improper use of pessimistic locks may also lead to deadlock.
Another problem is that we need to use exclusive locks to lock distributed locks. If an exclusive lock is not submitted for a long time, it will occupy the database connection. Once there are more similar connections, the database connection pool may explode
summary
Summarize the methods of using database to realize distributed lock. Both methods rely on a table of database. One is to determine whether there is a lock through the existence of records in the table, and the other is to realize distributed lock through exclusive lock of database.
Advantages of distributed locking in database
With the help of database directly, it is easy to understand.
Disadvantages of implementing distributed lock in database
There will be all kinds of problems, which will make the whole scheme more and more complex in the process of solving the problem.
Operating the database requires some overhead, and the performance needs to be considered.
Using row level locks in the database is not necessarily reliable, especially when our lock table is not large.
II. Implementation of distributed lock based on Zookeeper
ZooKeeper is an open source component that provides consistency services for distributed applications. It has a hierarchical file system directory tree structure, which stipulates that there can only be one unique file name in the same directory. The steps of implementing distributed lock based on ZooKeeper are as follows:
(1) Create a directory mylock;
(2) If thread A wants to obtain the lock, it creates A temporary sequence node in the mylock directory;
(3) Obtain all child nodes under the mylock directory, and then obtain sibling nodes smaller than yourself. If they do not exist, it indicates that the current thread sequence number is the smallest and the lock is obtained;
(4) Thread B obtains all nodes, judges that it is not the smallest node, and sets the node smaller than itself to listen to;
(5) After processing, thread A deletes its own node. Thread B monitors the change event and determines whether it is the smallest node. If so, it obtains A lock.
You can directly use the cursor client of the zookeeper third-party library, which encapsulates a reentrant lock service.

InterProcessMutex provided by cursor is the implementation of distributed lock. The acquire method is used to obtain the lock from the user, and the release method is used to release the lock.
The distributed lock implemented with ZK seems to fully meet all our expectations for a distributed lock at the beginning of this article. However, it is not. The distributed lock implemented by Zookeeper actually has a disadvantage, that is, the performance may not be as high as the cache service. Because every time in the process of creating and releasing a lock, it is necessary to dynamically create and destroy instantaneous nodes to realize the lock function. The creation and deletion of nodes in ZK can only be performed through the Leader server, and then the data can not be distributed to all Follower machines.
In fact, using Zookeeper may also cause concurrency problems, but it is not common. Considering this situation, due to the network jitter, the session connection of the client ZK cluster is disconnected. Then ZK will delete the temporary node if it thinks the client is hung. At this time, other clients can obtain the distributed lock. Concurrency problems may arise. This problem is not common because ZK has a retry mechanism. Once the ZK cluster cannot detect the heartbeat of the client, it will retry. The cursor client supports a variety of retry strategies. The temporary node will not be deleted until it fails after multiple retries. (therefore, it is also important to choose an appropriate retry strategy. We should find a balance between lock granularity and concurrency.)
You can also create temporary nodes to implement distributed locks, for example:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
public class ZooKeeperLock implements Watcher {
private ZooKeeper zk = null;
private String rootLockNode; // Lock root node locks
private String lockName; // Compete for resources to generate the child node name test1
private String currentLock; // Current lock
private String waitLock; // Waiting lock (previous lock)
private CountDownLatch countDownLatch; // Counter (used to block the locking thread when locking fails)
private int sessionTimeout = 30000; // Timeout
// 1. Create ZK link in the constructor and create the root node of the lock
public ZooKeeperLock(String zkAddress, String rootLockNode, String lockName) {
this.rootLockNode = rootLockNode;
this.lockName = lockName;
try {
// Create a connection. The zkAddress format is: IP:PORT
zk = new ZooKeeper(zkAddress,this.sessionTimeout,this);
// Check whether the root node of the lock exists. If it does not exist, create it
Stat stat = zk.exists(rootLockNode,false);
if (null == stat) {
zk.create(rootLockNode, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
}
}
// 2. Locking method: try to lock first. If you can't lock, wait for the release of the previous lock
public boolean lock() {
if (this.tryLock()) {
System.out.println("Thread[" + Thread.currentThread().getName() + "]Lock(" + this.currentLock + ")success!");
return true;
} else {
return waitOtherLock(this.waitLock, this.sessionTimeout);
}
}
public boolean tryLock() {
// Separator
String split = "_lock_";
if (this.lockName.contains("_lock_")) {
throw new RuntimeException("lockName can't contains '_lock_' ");
}
try {
// Create lock node (temporary ordered node)
this.currentLock = zk.create(this.rootLockNode + "/" + this.lockName + split, new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println("Thread[" + Thread.currentThread().getName()
+ "]Create lock node(" + this.currentLock + ")Success, start competition...");
// Take all child nodes
List<String> nodes = zk.getChildren(this.rootLockNode, false);
// Take the locks of all competing locknames
List<String> lockNodes = new ArrayList<String>();
for (String nodeName : nodes) {
if (nodeName.split(split)[0].equals(this.lockName)) {
lockNodes.add(nodeName);
}
}
Collections.sort(lockNodes);
// Compare the minimum node with the current lock node to lock
String currentLockPath = this.rootLockNode + "/" + lockNodes.get(0);
if (this.currentLock.equals(currentLockPath)) {
return true;
}
// Locking failed. Set the previous node as the node waiting for locking
String currentLockNode = this.currentLock.substring(this.currentLock.lastIndexOf("/") + 1);
int preNodeIndex = Collections.binarySearch(lockNodes, currentLockNode) - 1;
this.waitLock = lockNodes.get(preNodeIndex);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
private boolean waitOtherLock(String waitLock, int sessionTimeout) {
boolean islock = false;
try {
// Listening for lock waiting nodes
String waitLockNode = this.rootLockNode + "/" + waitLock;
Stat stat = zk.exists(waitLockNode,true); // watcher waiting node
if (null != stat) {
System.out.println("Thread[" + Thread.currentThread().getName()
+ "]Lock(" + this.currentLock + ")Failed to lock, waiting for lock(" + waitLockNode + ")release...");
// Set the counter and block the thread with the counter
this.countDownLatch = new CountDownLatch(1);
islock = this.countDownLatch.await(sessionTimeout,TimeUnit.MILLISECONDS);
this.countDownLatch = null;
if (islock) {
System.out.println("Thread[" + Thread.currentThread().getName() + "]Lock("
+ this.currentLock + ")Lock successfully, lock(" + waitLockNode + ")Released");
} else {
System.out.println("Thread[" + Thread.currentThread().getName() + "]Lock("
+ this.currentLock + ")Locking failed...");
}
} else {
islock = true;
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
return islock;
}
// 3. Release the lock
public void unlock() throws InterruptedException {
try {
Stat stat = zk.exists(this.currentLock,false);
if (null != stat) {
System.out.println("Thread[" + Thread.currentThread().getName() + "]Release lock " + this.currentLock);
zk.delete(this.currentLock, -1);
this.currentLock = null;
}
} catch (InterruptedException e) {
e.printStackTrace();
} catch (KeeperException e) {
e.printStackTrace();
} finally {
zk.close();
}
}
// 4. Listener callback
@Override
public void process(WatchedEvent watchedEvent) {
if (null != this.countDownLatch && watchedEvent.getType() == Event.EventType.NodeDeleted) {
// The counter is decremented by one to resume thread operation
this.countDownLatch.countDown();
}
}
}public class Test {
public static void doSomething() {
System.out.println("Thread[" + Thread.currentThread().getName() + "]Running...");
}
public static void main(String[] args) {
Runnable runnable = new Runnable() {
public void run() {
ZooKeeperLock lock = null;
lock = new ZooKeeperLock("127.0.0.1:2181","/locks", "test1");
if (lock.lock()) { // Get the node lock of zookeeper
doSomething();
try {
Thread.sleep(1000);
lock.unlock();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
for (int i = 0; i < 10; i++) {
Thread t = new Thread(runnable);
t.start();
}
}
}console result:
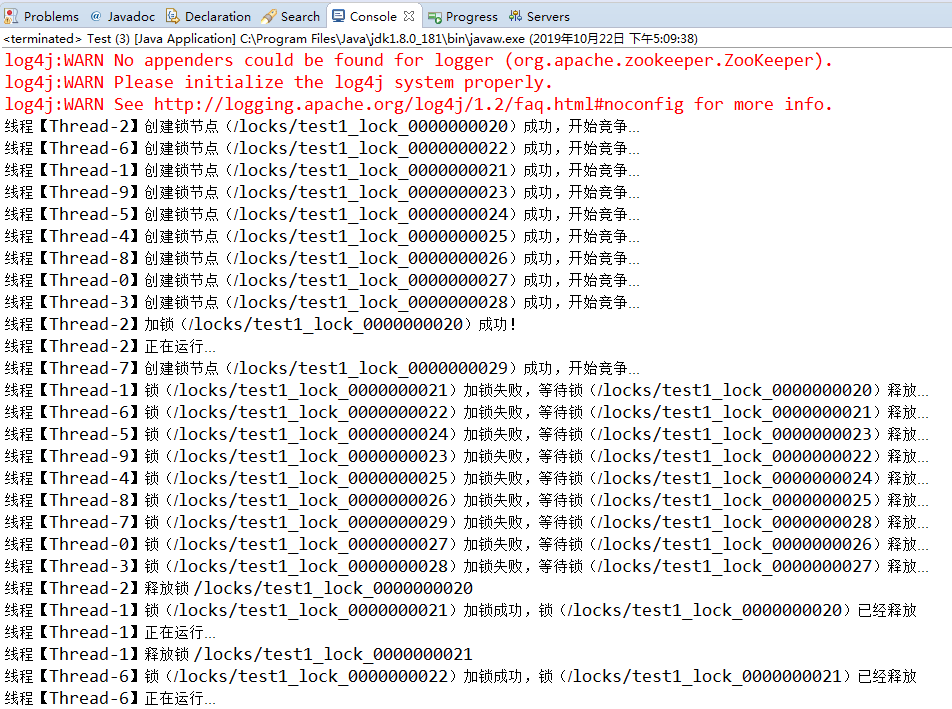
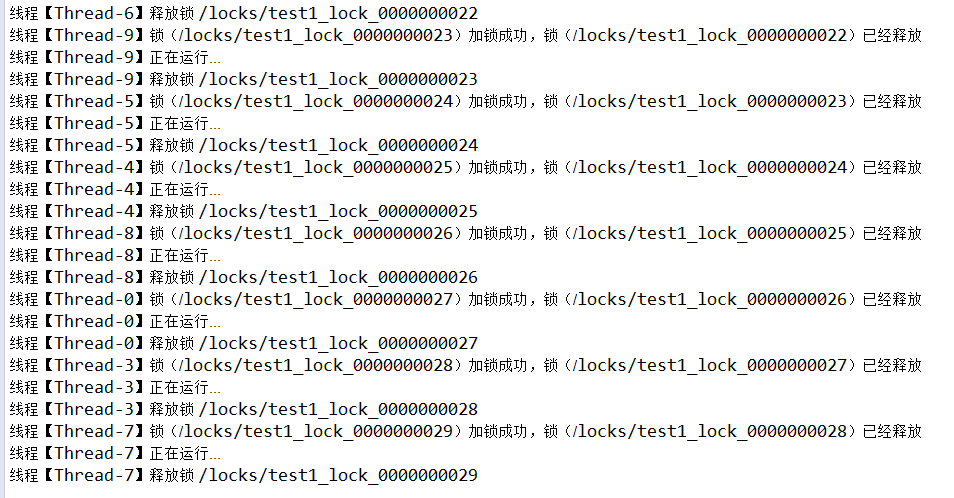
Third: implement distributed lock based on cache
Compared with the scheme of distributed locking based on database, the implementation based on cache will perform better in terms of performance. Moreover, many caches can be deployed in clusters, which can solve the single point problem.
At present, there are many mature cache products, including Redis, memcached and Tair in our company.
Take Tair as an example to analyze the scheme of using cache to realize distributed lock. There are many related articles about Redis and memcached on the network, and there are also some mature frameworks and algorithms that can be used directly.
The implementation of distributed locks based on Tair is actually similar to Redis. The main implementation method is to use tairmanager Put method.

There are also several problems in the above implementation methods:
1. This lock has no expiration time. Once the unlocking operation fails, the lock record will always be in the tail, and other threads can no longer obtain the lock.
2. This lock can only be non blocking, and will be returned directly regardless of success or failure.
3. This lock is non reentrant. After a thread obtains the lock, it cannot obtain the lock again before releasing the lock, because the key used already exists in the tail. No more put operations can be performed.
Of course, there are also ways to solve it.
- No expiration time? The put method of tail supports the input of expiration time, and the data will be deleted automatically after the arrival time.
- Non blocking? while is repeated.
- Non reentrant? After a thread obtains the lock, it saves the current host information and thread information. Before obtaining the lock next time, it checks whether it is the owner of the current lock.
However, how long should I set the expiration time? How to set the expiration time is too short, and the lock is automatically released before the method is executed, which will lead to concurrency problems. If the setting time is too long, other threads that obtain locks may have to wait for a long time. This problem also exists when using database to realize distributed lock
summary
Cache can be used instead of database to realize distributed locking, which can provide better performance. At the same time, many cache services are deployed in clusters, which can avoid single point problems. And many cache services provide methods that can be used to implement distributed locks, such as Tair's put method, redis's setnx method, etc. Moreover, these caching services also provide support for automatic deletion of expired data. You can directly set the timeout to control the release of locks.
Advantages of using cache to implement distributed locks
Good performance and easy to implement.
Disadvantages of using cache to realize distributed lock
It is not very reliable to control the failure time of the lock through the timeout time.
Comparison of three schemes
None of the above methods can be perfect. Just like CAP, it cannot meet the requirements of complexity, reliability and performance at the same time. Therefore, it is the king to choose the most suitable one according to different application scenarios.
From the perspective of difficulty of understanding (from low to high)
Database > cache > zookeeper
From the perspective of implementation complexity (from low to high)
Zookeeper > = cache > Database
From the perspective of performance (from high to low)
Cache > zookeeper > = database
From the perspective of reliability (from high to low)
Zookeeper > cache > Database
