1. General
1.1 how does the decision tree work?
Decision Tree is a nonparametric supervised learning method. It can summarize decision rules from a series of characteristic and labeled data, and present these rules with the structure of tree view to solve the problems of classification and regression. Decision Tree algorithm is easy to understand, suitable for all kinds of data, and has good performance in solving all kinds of problems. In particular, various integration algorithms with tree model as the core are widely used in various industries and fields.
The essence of decision tree algorithm is a graph structure. We only need to ask a series of questions to classify the data. For example, let's take a look at the following data set, which is the data of a series of known species and their categories:
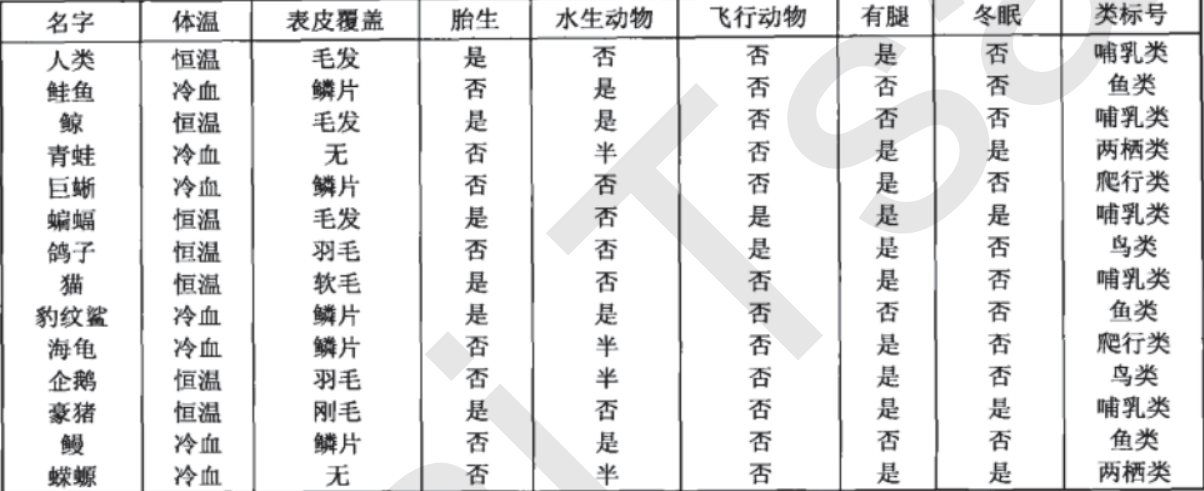
The goal is to divide animals into mammals and non mammals. According to the collected data, the decision tree algorithm calculates the following decision tree for us:
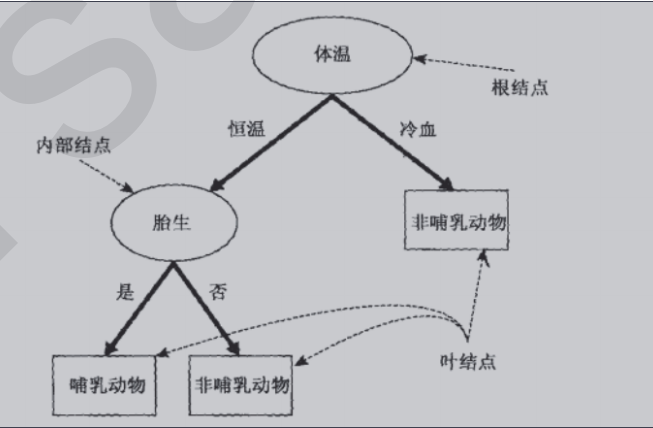
If we now find a new species Python, which is cold-blooded, with scales on its body surface, and is not viviparous, we can judge its category through this decision tree.
The core of decision tree algorithm is to solve two problems:
1) How to find the best node and branch from the data table?
2) How to stop the growth of decision tree and prevent over fitting?
1.2 decision tree in sklearn
The classes of the decision tree in sklearn are contained in the tree module, which includes five classes:
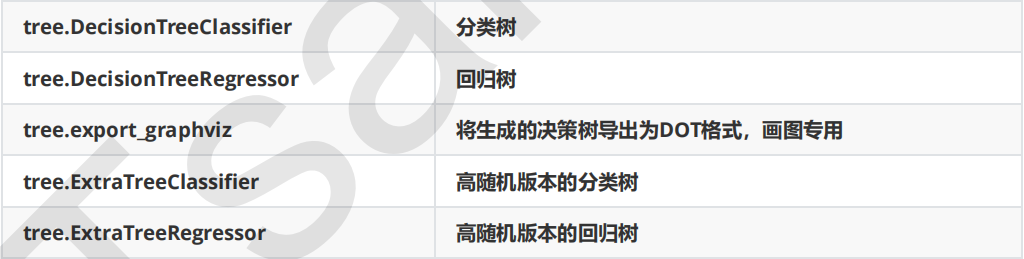
Main explanation: DecisionTreeClassifier
sklearn's modeling process:
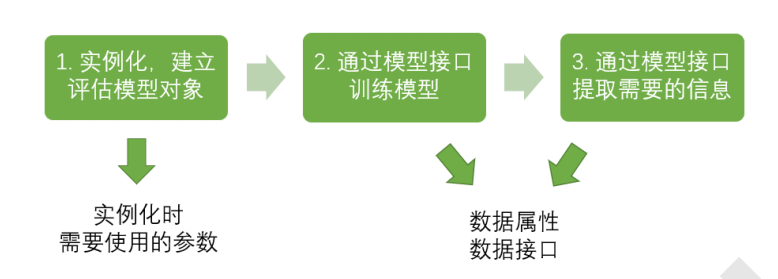
The corresponding codes are as follows:
from sklearn import tree #Import required modules clf = tree.DecisionTreeClassifier() #instantiation clf = clf.fit(X_train,y_train) #Training model with training set data result = clf.score(X_test,y_test)
2.DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier ( criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False )
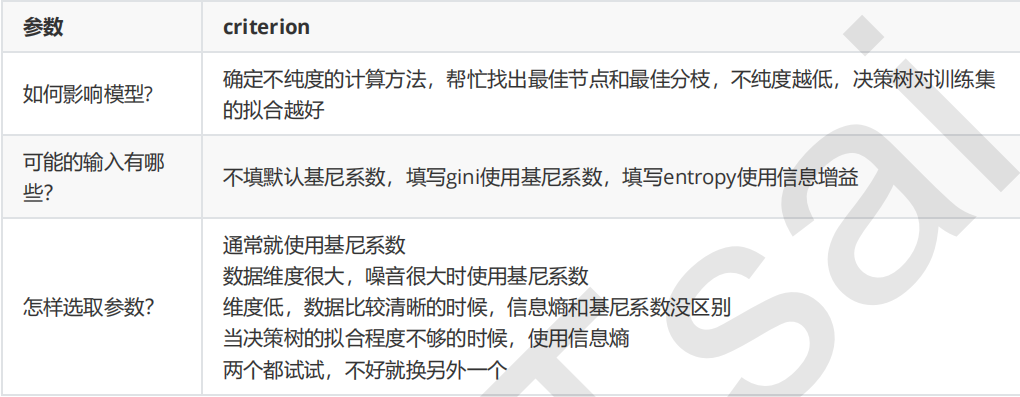
Important parameter: criterion
In order to transform the table into a tree, the decision tree needs to find the best node and the best branching method. For the classification tree, the index to measure this "best" is called "impure". Generally speaking, the lower the purity, the better the fitting of the decision tree to the training set. The core of the decision tree algorithm used now in the branching method is mostly around the optimization of a certain impurity related index.
Impure is calculated based on nodes. Each node in the tree will have an impure, and the impure of child nodes must be lower than that of parent nodes, that is, on the same decision tree, the impure of leaf nodes must be the lowest.
The Criterion parameter is used to determine the calculation method of impurity. sklearn offers two options:
- Enter "entropy" to use information entropy
- Enter "gini" to use gini impulse
Using sklearn to realize decision tree:
1. Import the required algorithm library and modules
from sklearn import tree from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split
2. Explore data
#Load data wine = load_wine() x = pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1) wine.feature_names
['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
3. Divide training set and test set
#It is divided into training set and test set x_train,x_test,y_train,y_test = train_test_split(wine.data,wine.target,test_size=0.3) #Model building clf = tree.DecisionTreeClassifier(criterion="entropy") clf = clf.fit(x_train,y_train) score = clf.score(x_test,y_test)
After testing, the accuracy of the model is as follows:
0.9629629629629629
4. View important features and corresponding weights
clf.feature_importances_ [*zip(wine.feature_names,clf.feature_importances_)]
[('alcohol', 0.018448661796409117),
('malic_acid', 0.0),
('ash', 0.0),
('alcalinity_of_ash', 0.0),
('magnesium', 0.0),
('total_phenols', 0.0),
('flavanoids', 0.43259590886482413),
('nonflavanoid_phenols', 0.0),
('proanthocyanins', 0.0),
('color_intensity', 0.20507049195022564),
('hue', 0.016757599408700523),
('od280/od315_of_diluted_wines', 0.0),
('proline', 0.32712733797984056)]
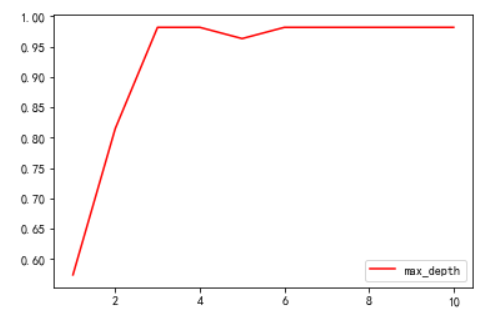
5. Set criterion = "entry", random_state=30, splitter = "random", change max_depth, observe the change of accuracy
import matplotlib.pyplot as plt
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(x_train, y_train)
score = clf.score(x_test, y_test)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
For the relevant knowledge of decision tree pruning, refer to the following documents:
Link: https://pan.baidu.com/s/1kL8S5r55ozqyZgdV6U6fKg
Extraction code: 1b3r
Come on a