Is kafka a single message or a batch message?
How does kafka send a single message?
Is kafka sending messages in order?
Under what circumstances may producers frequently use GC?
Message sending logic
—
From God's perspective, the process of message sending.

Producer design
Consumption sending mechanism:
1) Serializer: serialized message objects are converted into byte arrays and then transmitted over the network.
2) Partition: calculate the specific partition to which the message is sent; If partition is specified, the partition manager will not be used.
3) Message buffer pool: the message buffer pool of the client. The default size is 32M. See parameter buffer memory.
4) Batch send: messages in the buffer pool will be sent in batches by batch. The default batch size is 16KB. See the parameter batch size.
Load balancing design:
Because the message topic is composed of multiple partitions, and the partitions will be evenly distributed to different brokers. Therefore, in order to make effective use of the performance of broker clusters and improve message throughput, producer can send messages to multiple partitions in a random or hash manner to achieve load balancing.
Partition policy:
-
Polling policy, default policy
-
In practice, the random strategy is inferior to the polling strategy
-
According to the message Key order preservation strategy, once the message Key is defined, you can ensure that all messages of the same Key enter the same partition, because the message processing under each partition is sequential.
KafkaProducer
—
Source code
//Client ID. When creating KafkaProducer, you can use client ID defines the clientId. If it is not specified, it defaults to producer seq. seq is incremented in the process. It is strongly recommended that the client display the specified clientId.
private final String clientId;
//Relevant storage containers for measurement, such as message body size, sending time and other indicators related to monitoring.
final Metrics metrics;
//Partition load balancing algorithm, through the parameter partition Class.
private final Partitioner partitioner;
//The maximum request size sent by calling the send method, including key and message body. The total size of the serialized message cannot exceed this value. Pass the parameter max.request Size.
private final int maxRequestSize;
//The total memory size of the producer cache, through the parameter buffer Memory settings.
private final long totalMemorySize;
//Metadata information, such as the routing information of topic, is automatically updated by KafkaProducer.
private final Metadata metadata;
//Message record accumulator
private final RecordAccumulator accumulator;
//It is used to encapsulate the logic of message sending, that is, the processing logic of sending messages to broker s.
private final Sender sender;
//The background thread used for message sending, an independent thread, internally uses the Sender to send messages to the broker.
private final Thread ioThread;
//Compression type. Compression is not enabled by default. You can use the parameter compression Type configuration. Optional values: none, gzip, snappy, lz4, zstd.
private final CompressionType compressionType;
//The error information collector is used as a metric for monitoring.
private final Sensor errors;
//Used to obtain system time or thread sleep, etc.
private final Time time;
//Used to serialize the key of the message.
private final ExtendedSerializer<K> keySerializer;
//Serializer< V> valueSerializer
private final ExtendedSerializer<V> valueSerializer;
//Configuration information of the producer.
private final ProducerConfig producerConfig;
//Maximum blocking time: when the cache used by the producer has reached the specified value, the message sending will be blocked through the parameter max.block MS to set the maximum waiting time.
private final long maxBlockTimeMs;
//The configuration controls the maximum time the client waits for a request response. If no response is received before the timeout, the client will resend the request when needed, or fail the request when the retry runs out.
private final int requestTimeoutMs;
//The interceptor on the producer side performs some customized processing before sending the message.
private final ProducerInterceptors<K, V> interceptors;
//Maintain meta information related to api version. This class can only be used inside kafka.
private final ApiVersions apiVersions;
//kafka message transaction manager.
private final TransactionManager transactionManager;
//kafka producer transaction context initial results.
private TransactionalRequestResult initTransactionsResult;
KafkaProducer has the following characteristics:
-
Kafka producer is thread safe and can be cross used by multiple threads.
-
KafkaProducer contains a cache pool to store messages to be sent, that is, the ProducerRecord queue. At the same time, an IO thread will be started to send the ProducerRecord object to Kafka cluster.
-
The message sending API send method of KafkaProducer is asynchronous. It is only responsible for sending the message ProducerRecord to be sent to the cache, returning it immediately and returning a result voucher Future.
Role of acks parameter
KafkaProducer provides a core parameter acks, which is used to define the condition (standard) of "submitted" message, that is, the condition that the Broker side undertakes to submit to the client. The optional values are as follows:
-
0: it is considered successful as long as the send method of KafkaProducer is called and returned
-
All or - 1: indicates that the message not only needs the Leader node to store the message, but also requires all its copies (specifically, the nodes in the ISR) to be stored before it is considered submitted, and then the submission success is returned to the client. This is the most stringent persistence guarantee, and of course, the lowest performance.
-
1: It means that the message can be returned to the client after being written to the Leader node.
Function of retries parameter
Another core attribute provided by kafka on the production side is used to control the number of retries of messages after sending failure. Setting it to 0 means no retry. Retry may cause duplication of messages at the sending side. From the message sending interface:
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
As can be seen from the above API, when sending messages using KafkaProducer, users first need to encapsulate the messages to be sent into ProducerRecord, and return a Future object, a typical Future design pattern.
Kafka message append process
The send method of KafkaProducer does not send messages directly to the broker. kafka asynchronizes message sending, that is, it is divided into two steps. The function of the send method is to add messages to memory (cache queue of partitions), and then send messages in the cache to Kafka Broker asynchronously by a special send thread.
The main method is KafkaProducer#doSend
Append the message to the sending buffer of the producer. Its implementation class is RecordAccumulator. Let's take a look at Kafka# the flow chart of writing a message to memory:
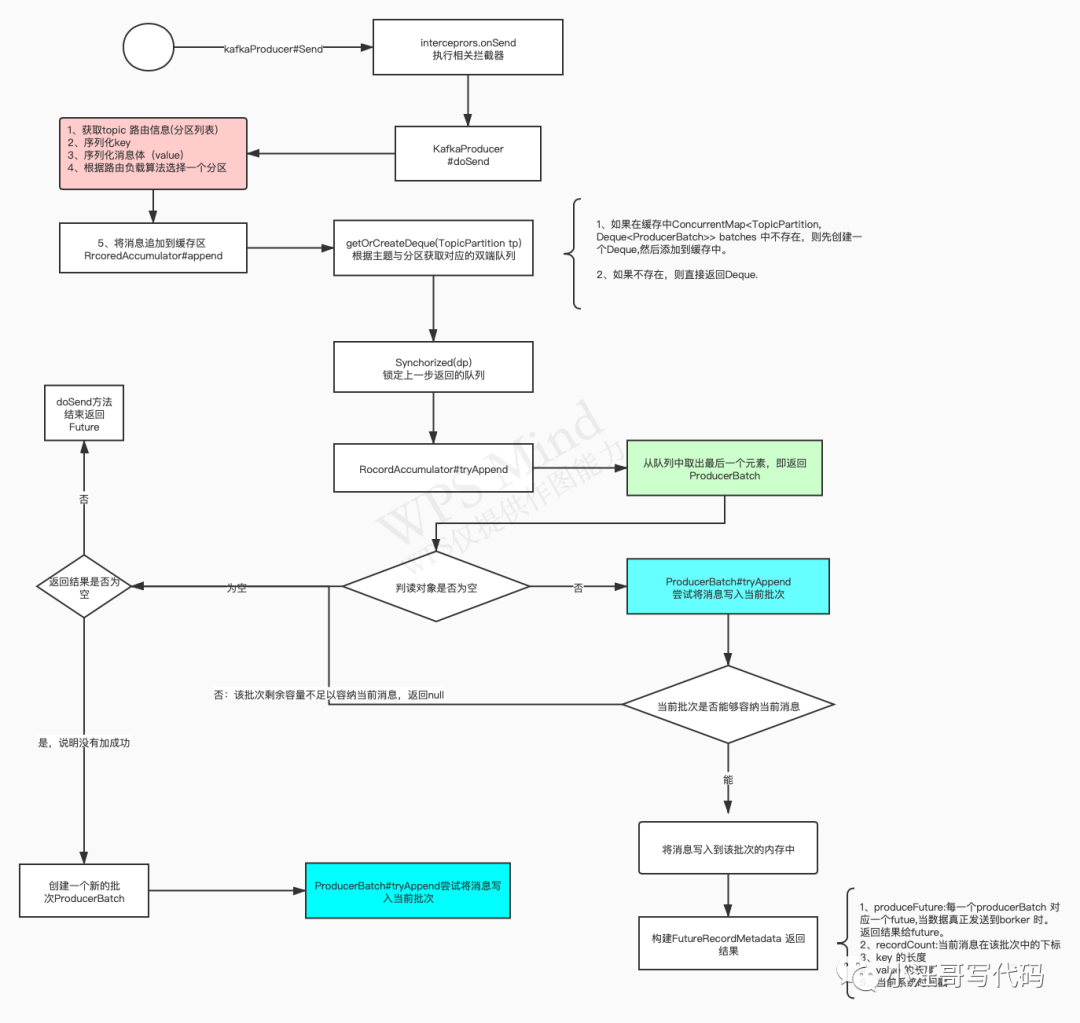
Reply to [kafka1] to obtain high-definition pictures.
Sender thread
—
So far, we can see that when we call the send method, it is only sent to the service memory of the producer client. The Broker hasn't arrived yet. The background of the Kafka producer client will start a thread to continuously poll the message batch storage area and send the message to the Broker.
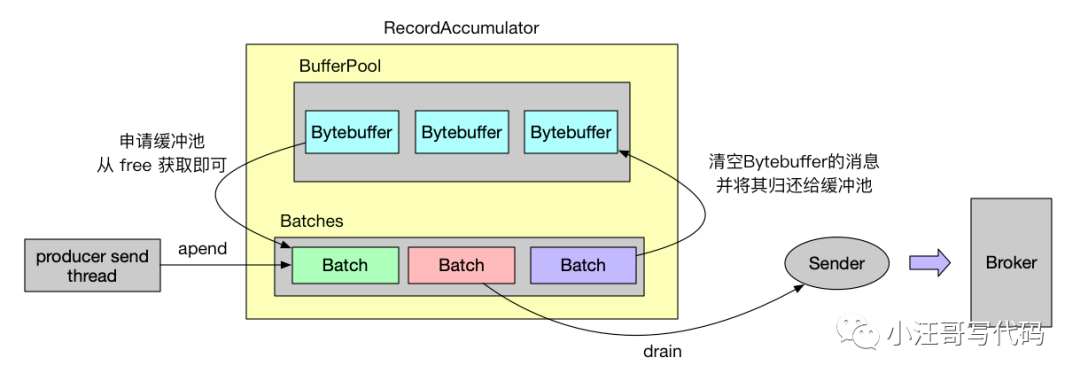
Memory structure and allocation of message batches
—
According to the above source code, we can see that each producer batch is a batch Size bytes of memory. And pool technology is used.
The memory holding class of the buffer pool is BufferPool. Let's first look at the members of BufferPool:
public class BufferPool {
// Total memory size
private final long totalMemory;
// The size of each memory block, i.e. batch size
private final int poolableSize;
// Synchronous lock of the method of applying for and returning memory
private final ReentrantLock lock;
// Free memory block
private final Deque<ByteBuffer> free;
// Events that need to wait for free memory blocks
private final Deque<Condition> waiters;
/** Total available memory is the sum of nonPooledAvailableMemory and the number of byte buffers in free * poolableSize. */
// The free memory that has not been allocated in the buffer pool. The newly applied memory block obtains the memory value from here
private long nonPooledAvailableMemory;
// ...
}
It can be seen from the members of BufferPool that the buffer pool is actually composed of bytebuffers. BufferPool holds these memory blocks and saves them in the member free. The total size of free is limited by totalMemory, while nonPooledAvailableMemory indicates how much memory remains in the buffer pool has not been allocated.
After the Batch message is sent, it will return the memory block it holds to free, so that the next Batch will not create a new ByteBuffer when applying for the memory block, and it can take it from free, so as to avoid the problem that the memory block is recycled by the JVM.
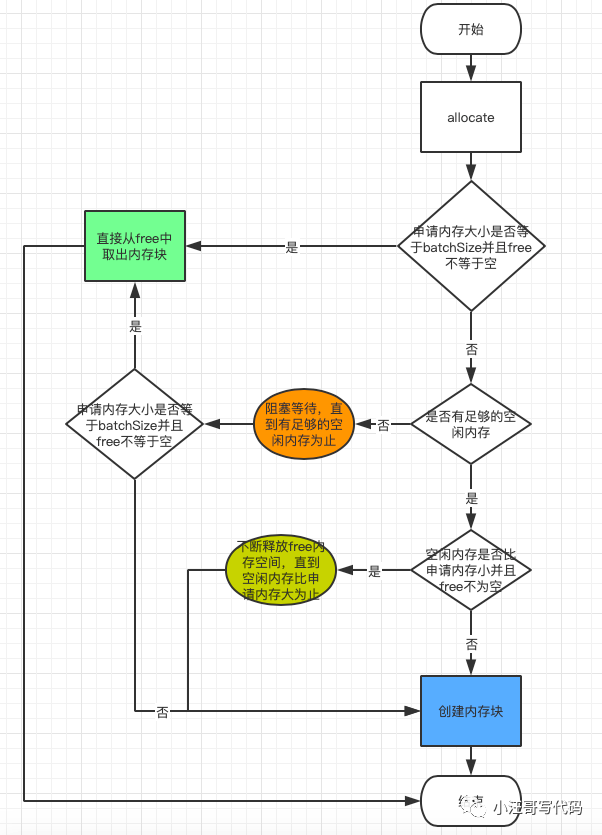
The process of creating a memory block is as follows:
Logical flow of returning memory blocks
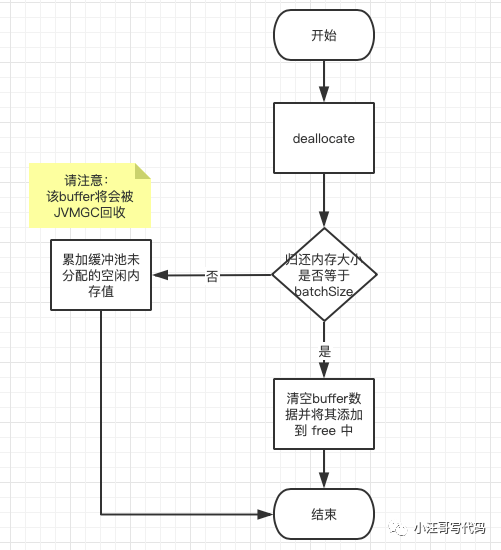
If the returned memory block size is equal to batchSize, it will be emptied and added to the free of the buffer pool, that is, it will be returned to the buffer pool to avoid the JVM GC reclaiming the memory block. If it is not equal to, you can directly add the memory size to the unallocated and free memory size value. There is no need to return the memory, wait for the JVM GC to recycle it, and finally wake up the thread waiting for free memory.
How do Java producers manage TCP connections
—
Why TCP?
All communication of Apache Kafka is based on TCP, not HTTP or other protocols. This is true for communication between producers, consumers, and brokers
From the perspective of the community, when developing the client, people can take advantage of some advanced functions provided by TCP itself, such as multiplexing requests and the ability to poll multiple connections at the same time
The multiplexing request of TCP will create several virtual connections on a physical connection, and each virtual connection is responsible for flowing its corresponding data stream. In fact, strictly speaking, TCP cannot multiplex. It only provides reliable semantic guarantee for message delivery, such as automatic retransmission of lost messages.
Moreover, the known HTTP libraries are slightly crude in many programming languages.
When to create a TCP connection?
The TCP connection is established when the KafkaProducer instance is created. When the KafkaProducer instance is created, the producer application will create and start a thread named Sender in the background. When the Sender thread starts running, it will first create a connection with the Broker
Properties properties = new Properties();
properties.put("bootstrap.servers", "localhost:9092");
properties.put("key.serializer", StringSerializer.class.getName());
properties.put("value.serializer", StringSerializer.class.getName());
// try-with-resources
// When creating a KafkaProducer instance, the Sender thread will be created and started in the background. When the Sender thread starts running, it will first create a TCP connection with the Broker
try (Producer<String, String> producer = new KafkaProducer<>(properties)) {
ProducerRecord<String, String> record = new ProducerRecord<>(TOPIC, KEY, VALUE);
Callback callback = (metadata, exception) -> {
};
producer.send(record, callback);
}
-
bootstrap.servers is one of the core parameters of Producer. It specifies the address of the Broker to connect to when the Producer starts
-
If bootstrap Servers specifies 1000 brokers. When Producer starts, it will first create TCP connections to these 1000 brokers
-
Therefore, it is not recommended to configure all Broker information in the cluster to bootstrap In servers, 3 ~ 4 servers are usually configured
- Once the Producer connects to any Broker in the cluster, it can get the Broker information (metadata request) of the whole cluster
TCP connections can also be created in two places: one after updating metadata and the other when sending messages.
- After the Producer updates the metadata of the cluster, if it finds that there is no connection with some brokers, the Producer will create a TCP connection
[scenario 1]
When the Producer attempts to send a message to a topic that does not exist, the Broker will tell the Producer that the topic does not exist. At this time, the Producer will send a metadata request to the Kafka cluster to try to obtain the latest metadata information and establish TCP connections with all brokers in the cluster.
[scenario 2]
Producer through metadata max.age. The MS parameter updates the metadata information regularly. The default value is 300000, that is, 5 minutes.
- When the Producer wants to send a message, it will also create a TCP connection if it finds that there is no connection with the target Broker (relying on the load balancing algorithm)
When to close a TCP connection?
There are two ways for the Producer to close the TCP connection: the user actively closes and Kafka automatically closes.
[user actively closes]
Active shutdown in a broad sense includes the user calling kill -9 to kill the Producer. The most recommended method is Producer close()
[Kafka auto close]
Producer side parameter connections max.idle. MS, the default value is 540000, i.e. 9 minutes
If no request passes through a TCP connection within 9 minutes, Kafka will actively close the TCP connection
connections.max.idle.ms=-1 will disable this mechanism and the TCP connection will become a permanent long connection
All Socket connections created by Kafka have keepalive enabled
The initiator of closing the TCP connection is the Kafka client, which belongs to the passive closing scenario
The consequence of passive shutdown is a large number of CLOSE_WAIT connection
The Producer or Client has no chance to explicitly observe that the TCP connection has been interrupted
summary
—
Now we can answer the first three questions.
1. Is kafka a single message or a batch message?
Normally, they are sent in batches. Encapsulated into a ProducerBatch.
2. How does Kafka send a single message?
Only single producer and single thread can be set to synchronously call the send method.
3. Is Kafka sending messages in sequence?
No, if the requirement order must be set to key, and the producer is single threaded.
4. Under what circumstances may producers frequently use GC?
If your message size is larger than the batchSize, you will not get the allocated memory block circularly from free, but create a new ByteBuffer, and the ByteBuffer will not be returned to the buffer pool (JVM GC recycling). If nonPooledAvailableMemory is smaller than the message body at this time, Free memory blocks in free will also be destroyed (JVM GC recycling), so that there is enough memory space in the buffer pool to provide users with applications. These actions will lead to frequent GC problems.
Therefore, it is necessary to adjust batch.com appropriately according to the size of business messages Size to avoid frequent GC.