Introduction to service discovery
For the monitoring system, the on-demand resource usage in cloud native and container scenarios means that there is no fixed monitoring target and all monitoring objects (infrastructure, applications and services)
Service) are changing dynamically, which brings challenges to the traditional monitoring software based on Push mode.
For Prometheus, a monitoring system based on Pull mode, it is obvious that it cannot continue to use static_ Configure statically defines monitoring targets. And for
For Prometheus, its solution is to introduce an intermediate agent (service registry), which holds the access information of all current monitoring targets,
Prometheus only needs to ask the agent what monitoring targets are controlled. This model is called service discovery.
Through service discovery, the administrator can dynamically discover the Target instance information to be monitored without restarting the Prometheus service.
Prometheus exposes an endpoint for the server to capture for each controlled target. There are many ways to know these endpoints. The simplest is to configure them statically in the configuration file,
There are also many ways based on k8s, consul t, dns, etc. file based service discovery is a flexible and common way.
Prometheus uses pull mode to pull monitoring data, which requires real-time perception of changes in the monitored service (Target). Service discovery supports a variety of service discovery systems,
These systems can dynamically perceive the changes of the monitored service (Target) and convert the changed monitored service (Target) into targetgroup The structure of a group, which sends a message through the pipe up
Service discovery. Version v2 27 as an example, the types of service discovery systems currently supported by service discovery are as follows:
// Package install has the side-effect of registering all builtin // service discovery config types. package install import ( _ "github.com/prometheus/prometheus/discovery/aws" // register aws _ "github.com/prometheus/prometheus/discovery/azure" // register azure _ "github.com/prometheus/prometheus/discovery/consul" // register consul _ "github.com/prometheus/prometheus/discovery/digitalocean" // register digitalocean _ "github.com/prometheus/prometheus/discovery/dns" // register dns _ "github.com/prometheus/prometheus/discovery/eureka" // register eureka _ "github.com/prometheus/prometheus/discovery/file" // register file _ "github.com/prometheus/prometheus/discovery/gce" // register gce _ "github.com/prometheus/prometheus/discovery/hetzner" // register hetzner _ "github.com/prometheus/prometheus/discovery/kubernetes" // register kubernetes _ "github.com/prometheus/prometheus/discovery/marathon" // register marathon _ "github.com/prometheus/prometheus/discovery/moby" // register moby _ "github.com/prometheus/prometheus/discovery/openstack" // register openstack _ "github.com/prometheus/prometheus/discovery/scaleway" // register scaleway _ "github.com/prometheus/prometheus/discovery/triton" // register triton _ "github.com/prometheus/prometheus/discovery/zookeeper" // register zookeeper )
Service Discovery Interface
In order to realize the unified management of the above service discovery systems, service discovery provides a Discoverer interface, which is implemented by each service discovery system
The online service (Target) is sent to service discovery through the up pipeline
prometheus/discovery/manager.go
type Discoverer interface {
// Run hands a channel to the discovery provider (Consul, DNS etc) through which it can send
// updated target groups.
// Must returns if the context gets canceled. It should not close the update
// channel on returning.
Run(ctx context.Context, up chan<- []*targetgroup.Group)
}
prometheus/discovery/targetgroup/targetgroup.go
// Group is a set of targets with a common label set(production , test, staging etc.).
type Group struct {
// Targets is a list of targets identified by a label set. Each target is
// uniquely identifiable in the group by its address label.
Targets []model.LabelSet //The main tag of the service (Target), such as ip + port, for example: "__ address": "localhost:9100"
// Labels is a set of labels that is common across all targets in the group.
Labels model.LabelSet //Other tags of service (Target), which can be empty:
// Source is an identifier that describes a group of targets.
Source string //Globally unique ID, example: Source: "0"
}
Group An example of:
(dlv) p tg
*github.com/prometheus/prometheus/discovery/targetgroup.Group {
Targets: []github.com/prometheus/common/model.LabelSet len: 1, cap: 1, [
[
"__address__": "localhost:9100",
],
]
],
Labels: github.com/prometheus/common/model.LabelSet nil,
Source: "0",}
In addition to the static service discovery system (StaticConfigs) in Prometheus / discovery / manager Go implements the above interfaces. Other dynamic service discovery systems
prometheus/discovery / are implemented in their own directories.
Service discovery configuration
Sample configuration file: Prometheus yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
scrape_interval: 5s
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 10s
static_configs:
- targets: ['localhost:9100']
-
Profile initialization
prometheus/cmd/prometheus/main.go //discovery. Name ("scratch") is used to distinguish notify discoveryManagerScrape = discovery.NewManager(ctxScrape, log.With(logger, "component", "discovery manager scrape"), discovery.Name("scrape")) -
Call the NewManager method to instantiate the Manager structure
prometheus/discovery/manager.go // NewManager is the Discovery Manager constructor. func NewManager(ctx context.Context, logger log.Logger, options ...func(*Manager)) *Manager { if logger == nil { logger = log.NewNopLogger() } mgr := &Manager{ logger: logger, syncCh: make(chan map[string][]*targetgroup.Group), targets: make(map[poolKey]map[string]*targetgroup.Group), discoverCancel: []context.CancelFunc{}, ctx: ctx, updatert: 5 * time.Second, triggerSend: make(chan struct{}, 1), } for _, option := range options { option(mgr) } return mgr }Structure Manager is defined as follows
prometheus/discovery/manager.go // Manager maintains a set of discovery providers and sends each update to a map channel. // Targets are grouped by the target set name. type Manager struct { logger log.Logger //journal name string // It is used to distinguish between srape and notify because they use the same discovery / manager go mtx sync.RWMutex //Synchronous read-write lock ctx context.Context //Collaborative control, such as system exit discoverCancel []context.CancelFunc // Processing service offline // Some Discoverers(eg. k8s) send only the updates for a given target group // so we use map[tg.Source]*targetgroup.Group to know which group to update. targets map[poolKey]map[string]*targetgroup.Group //Discovered services (Targets) // providers keeps track of SD providers. providers []*provider // providers can be divided into kubernetes, DNS, etc // The sync channel sends the updates as a map where the key is the job value from the scrape config. // key is the job of the prometheus configuration file_ Name and value are the corresponding targetgroup // Notify the discovered service targets to the scrapeManager in the form of pipeline syncCh chan map[string][]*targetgroup.Group // How long to wait before sending updates to the channel. The variable // should only be modified in unit tests. updatert time.Duration // The triggerSend channel signals to the manager that new updates have been received from providers. // This is a channel used to notify the manager that a provider has been updated triggerSend chan struct{} }The more important member is targets, which holds the full amount of targets. poolKey is a structure, which is composed of job_name and provider_name composition
prometheus/discovery/manager.go // poolKey defines the source of each discovered service type poolKey struct { setName string //Corresponding system name / index value, such as: string / 0 (static service discovery), DNS / 1 (dynamic service discovery) provider string //Corresponding job_name }Through m.registerProviders, you can see that setName is "file" / "dns" / "consumption"..., and provider is the name field of the provider object, which is "file" / "dns"/
"Consumption"... Followed by the number of discovery files of the m.provider, such as file_SD_discovrer is configured with three yml files, and the provider field of poolKey is displayed
Is "file/3"
-
Load Prometheus. Through anonymous functions YML's scratch_ Corresponding configuration under configs
prometheus/cmd/prometheus/main.go func(cfg *config.Config) error { c := make(map[string]sd_config.ServiceDiscoveryConfig) for _, v := range cfg.ScrapeConfigs { c[v.JobName] = v.ServiceDiscoveryConfig } return discoveryManagerScrape.ApplyConfig(c) },Take the example configuration file prometheus YML, for example, contains two jobs, job_name is prometheus and node respectively. Each job can contain multiple targets_ Name: node as an example, the anonymous function variable v output is as follows:
(dlv) p v *github.com/prometheus/prometheus/config.ScrapeConfig { JobName: "node", HonorLabels: false, Params: net/url.Values nil, ScrapeInterval: 10000000000, ScrapeTimeout: 10000000000, MetricsPath: "/metrics", Scheme: "http", SampleLimit: 0, ServiceDiscoveryConfig: github.com/prometheus/prometheus/discovery/config.ServiceDiscoveryConfig { StaticConfigs: []*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [ *(*"github.com/prometheus/prometheus/discovery/targetgroup.Group")(0xc0018a27b0), ], DNSSDConfigs: []*github.com/prometheus/prometheus/discovery/dns.SDConfig len: 0, cap: 0, nil, FileSDConfigs: []*github.com/prometheus/prometheus/discovery/file.SDConfig len: 0, cap: 0, nil, ...... ...... ...... AzureSDConfigs: []*github.com/prometheus/prometheus/discovery/azure.SDConfig len: 0, cap: 0, nil, TritonSDConfigs: []*github.com/prometheus/prometheus/discovery/triton.SDConfig len: 0, cap: 0, nil,}, HTTPClientConfig: github.com/prometheus/common/config.HTTPClientConfig { BasicAuth: *github.com/prometheus/common/config.BasicAuth nil, BearerToken: "", BearerTokenFile: "", ProxyURL: (*"github.com/prometheus/common/config.URL")(0xc000458cf8), TLSConfig: (*"github.com/prometheus/common/config.TLSConfig")(0xc000458d00),}, RelabelConfigs: []*github.com/prometheus/prometheus/pkg/relabel.Config len: 0, cap: 0, nil, MetricRelabelConfigs: []*github.com/prometheus/prometheus/pkg/relabel.Config len: 0, cap: 0, nil,}From the above results, we can see that job_name: node corresponds to static service discovery system (StaticConfigs). In fact, in the configuration file Prometheus Two jobs in YML_ names
All correspond to static service discovery systems (StaticConfigs)
-
The implementation logic of ApplyConfig method is relatively clear: first implement the Discoverer interface of each job, and then start the service discovery system corresponding to the job
prometheus/discovery/manager.go // ApplyConfig removes all running discovery providers and starts new ones using the provided config. func (m *Manager) ApplyConfig(cfg map[string]sd_config.ServiceDiscoveryConfig) error { m.mtx.Lock() defer m.mtx.Unlock() for pk := range m.targets { if _, ok := cfg[pk.setName]; !ok { discoveredTargets.DeleteLabelValues(m.name, pk.setName) } } // It's easy to cancel all discoverers first. After all, the frequency of profile modification is very low, and there's no big problem // The implementation method is the manager mentioned above Discovercancel is an array of cancellation functions. Just traverse the call m.cancelDiscoverers() // Name corresponds to job_name, scfg is given the job_ Service discovery system type corresponding to name, each job_name can contain multiple service discovery system types, but it is rarely used for name, scfg := range cfg { m.registerProviders(scfg, name) discoveredTargets.WithLabelValues(m.name, name).Set(0) } for _, prov := range m.providers { //Start the corresponding service discovery system under each job m.startProvider(m.ctx, prov) } return nil }The ApplyConfig method mainly realizes the above functions by calling methods: registerProviders() and startProvider()
-
The registerProviders method judges each job first_ Name contains all service discovery system types, and then the corresponding service discovery system implements the Discoverer interface and constructs provider and TargetGroups
// registerProviders returns a number of failed SD config. func (m *Manager) registerProviders(cfgs Configs, setName string) int { var ( failed int added bool ) add := func(cfg Config) { for _, p := range m.providers { if reflect.DeepEqual(cfg, p.config) { p.subs = append(p.subs, setName) added = true return } } typ := cfg.Name() d, err := cfg.NewDiscoverer(DiscovererOptions{ Logger: log.With(m.logger, "discovery", typ), }) if err != nil { level.Error(m.logger).Log("msg", "Cannot create service discovery", "err", err, "type", typ) failed++ return } m.providers = append(m.providers, &provider{ name: fmt.Sprintf("%s/%d", typ, len(m.providers)), d: d, config: cfg, subs: []string{setName}, }) added = true } for _, cfg := range cfgs { add(cfg) } if !added { // Add an empty target group to force the refresh of the corresponding // scrape pool and to notify the receiver that this target set has no // current targets. // It can happen because the combined set of SD configurations is empty // or because we fail to instantiate all the SD configurations. add(StaticConfig{{}}) } return failed }StaticConfigs corresponds to TargetGroups, with job_name: node as an example, the corresponding output of TargetGroups is as follows:
(dlv) p setName "node" (dlv) p StaticConfigs []*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [ *{ Targets: []github.com/prometheus/common/model.LabelSet len: 1, cap: 1, [ [ "__address__": "localhost:9100", ], ], Labels: github.com/prometheus/common/model.LabelSet nil, Source: "0",}, ]Each job_name corresponds to a targetgroup, and each targetgroup can contain multiple providers, and each provider contains the Discoverer interface and job corresponding to the implementation_ Name, etc. Therefore, the corresponding relationship is: job_name - > TargetGroups - > multiple targets - > multiple providers - > multiple discoveries. Some examples are as follows:
(dlv) p m.providers []*github.com/prometheus/prometheus/discovery.provider len: 2, cap: 2, [ *{ name: "string/0", d: github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) ..., subs: []string len: 1, cap: 1, [ "prometheus", ], config: interface {}(string) *(*interface {})(0xc000536268),}, *{ name: "string/1", d: github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) ..., subs: []string len: 1, cap: 1, ["node"], config: interface {}(string) *(*interface {})(0xc000518b78),}, ] (dlv) p m.providers[0].d github.com/prometheus/prometheus/discovery.Discoverer(*github.com/prometheus/prometheus/discovery.StaticProvider) *{ TargetGroups: []*github.com/prometheus/prometheus/discovery/targetgroup.Group len: 1, cap: 1, [ *(*"github.com/prometheus/prometheus/discovery/targetgroup.Group")(0xc000ce09f0), ],} -
The startProvider method starts the job one by one_ All service discovery systems corresponding to name
prometheus/discovery/manager.go func (m *Manager) startProvider(ctx context.Context, p *provider) { level.Debug(m.logger).Log("msg", "Starting provider", "provider", p.name, "subs", fmt.Sprintf("%v", p.subs)) ctx, cancel := context.WithCancel(ctx) updates := make(chan []*targetgroup.Group) m.discoverCancel = append(m.discoverCancel, cancel) // The first collaboration starts the specific discovery service as [] * targetgroup Producer of group go p.d.Run(ctx, updates) // The second collaboration is [] * targetgroup Group consumers go m.updater(ctx, p, updates) } // Note: the call location of the Run method is in the service discovery system that implements Discoverer. For static service discovery, the Run method is in Prometheus / discovery / manager Go. If it is a dynamic service discovery system, it is implemented in the directory of the corresponding systemThe Run method takes a value from the StaticProvider of the structure and passes it to [] * targetgroup Group, as the producer of service discovery
prometheus/discovery/discovery.go type Discoverer interface { // Run hands a channel to the discovery provider (Consul, DNS, etc.) through which // it can send updated target groups. It must return when the context is canceled. // It should not close the update channel on returning. Run(ctx context.Context, up chan<- []*targetgroup.Group) } prometheus/discovery/manager.go // StaticProvider holds a list of target groups that never change. type StaticProvider struct { TargetGroups []*targetgroup.Group } // Run implements the Worker interface. func (sd *StaticProvider) Run(ctx context.Context, ch chan<- []*targetgroup.Group) { // We still have to consider that the consumer exits right away in which case // the context will be canceled. select { case ch <- sd.TargetGroups: case <-ctx.Done(): } close(ch) }The updater method is from [] * targetgroup Group obtains TargetGroups and sends it to the corresponding Targets in the structure Manager. The corresponding Targets in the Manager are of map type
prometheus/discovery/manager.go func (m *Manager) updater(ctx context.Context, p *provider, updates chan []*targetgroup.Group) { for { select { case <-ctx.Done(): //sign out return case tgs, ok := <-updates: // From [] * targetgroup Group takes TargetGroups receivedUpdates.WithLabelValues(m.name).Inc() if !ok { level.Debug(m.logger).Log("msg", "discoverer channel closed", "provider", p.name) return } // Sub corresponding job_names and p.name correspond to the system name / index value, such as string/0 for _, s := range p.subs { m.updateGroup(poolKey{setName: s, provider: p.name}, tgs) } select { case m.triggerSend <- struct{}{}: default: } } } }Update the targets corresponding to the structure Manager. key is the structure poolKey, and value is the passed TargetGroups, including targets
prometheus/discovery/manager.go func (m *Manager) updateGroup(poolKey poolKey, tgs []*targetgroup.Group) { m.mtx.Lock() defer m.mtx.Unlock() for _, tg := range tgs { if tg != nil { // Some Discoverers send nil target group so need to check for it to avoid panics. if _, ok := m.targets[poolKey]; !ok { m.targets[poolKey] = make(map[string]*targetgroup.Group) } m.targets[poolKey][tg.Source] = tg //A tg corresponds to a job. In the map type targets, the structures poolkey and tg Source can determine a tg, that is, job } } }
-
Service discovery startup
In main Start a coroutine in the go method and run the Run() method
prometheus/cmd/prometheus/main.go
{
// Scrape discovery manager.
g.Add(
func() error {
err := discoveryManagerScrape.Run()
level.Info(logger).Log("msg", "Scrape discovery manager stopped")
return err
},
func(err error) {
level.Info(logger).Log("msg", "Stopping scrape discovery manager...")
cancelScrape()
},
)
}
// Run starts the background processing
func (m *Manager) Run() error {
go m.sender()
for range m.ctx.Done() {
m.cancelDiscoverers()
return m.ctx.Err()
}
return nil
}
The Run method starts another co process and runs the sender() method. The main function of the sender method is to process the targets of map type in the structure Manager and then pass them to the structure
syncCh: syncCh Chan map [string] [] * targetgroup Group
sender uses a timer to limit the update rate, because some discoverer s may update the target too frequently. Each Run() will execute a message according to the context
Row cancels the discovery operation. The usage of cycle timer is worth learning. Pay attention to delaying shutdown after creation.
Check whether there is an updated signal in m.triggerSend every 5 seconds. If there is an updated signal, assemble map [string] [] * targetgroup Group send to
m. In syncch, because m.SyncCh is a non buffered channel, if it fails to receive, wait until the update signal is checked next time, and then try to send again. The nested select case here is not
Often worth learning
func (m *Manager) sender() {
ticker := time.NewTicker(m.updatert)
defer ticker.Stop()
for {
select {
case <-m.ctx.Done():
return
case <-ticker.C: // Some discoverers send updates too often so we throttle these with the ticker.
select {
case <-m.triggerSend:
sentUpdates.WithLabelValues(m.name).Inc()
select {
//The method allGroups is responsible for type conversion and is passed to syncCh
case m.syncCh <- m.allGroups():
default:
delayedUpdates.WithLabelValues(m.name).Inc()
level.Debug(m.logger).Log("msg", "discovery receiver's channel was full so will retry the next cycle")
select {
case m.triggerSend <- struct{}{}:
default:
}
}
default:
}
}
}
}
The allGroups() method responsible for the transformation. The m.allGroups method reads the value in its own targets member variable, assembles it into a map and returns it to the caller, which is used to send the map to its own syncCh and finally notify the scraper;
When SD finds that a target group is deleted, it will send an empty target group. The meaning of this action is explained here, and the empty target group will notify
The scraper stops grabbing these target s
func (m *Manager) allGroups() map[string][]*targetgroup.Group {
m.mtx.Lock()
defer m.mtx.Unlock()
tSets := map[string][]*targetgroup.Group{}
for pkey, tsets := range m.targets {
var n int
for _, tg := range tsets {
// Even if the target group 'tg' is empty we still need to send it to the 'Scrape manager'
// to signal that it needs to stop all scrape loops for this target set.
tSets[pkey.setName] = append(tSets[pkey.setName], tg)
n += len(tg.Targets)
}
discoveredTargets.WithLabelValues(m.name, pkey.setName).Set(float64(n))
}
return tSets
}
Service discovery and indicator collection communication
Service discovery communicates with the indicator collection Manager. The service responsible for the indicator collection listens to syncCh in the structure manager, thus realizing the communication between the two services
prometheus/cmd/prometheus/main.go
{
// Scrape manager.
g.Add(
func() error {
// When the scrape manager receives a new targets list
// it needs to read a valid config for each job.
// It depends on the config being in sync with the discovery manager so
// we wait until the config is fully loaded.
<-reloadReady.C
err := scrapeManager.Run(discoveryManagerScrape.SyncCh())
level.Info(logger).Log("msg", "Scrape manager stopped")
return err
},
func(err error) {
// Scrape manager needs to be stopped before closing the local TSDB
// so that it doesn't try to write samples to a closed storage.
level.Info(logger).Log("msg", "Stopping scrape manager...")
scrapeManager.Stop()
},
)
}
prometheus/discovery/manager.go
// SyncCh returns a read only channel used by all the clients to receive target updates.
func (m *Manager) SyncCh() <-chan map[string][]*targetgroup.Group {
//syncCh in struct Manager
return m.syncCh
}
Summary
So far, the main functions of service discovery have been sorted out
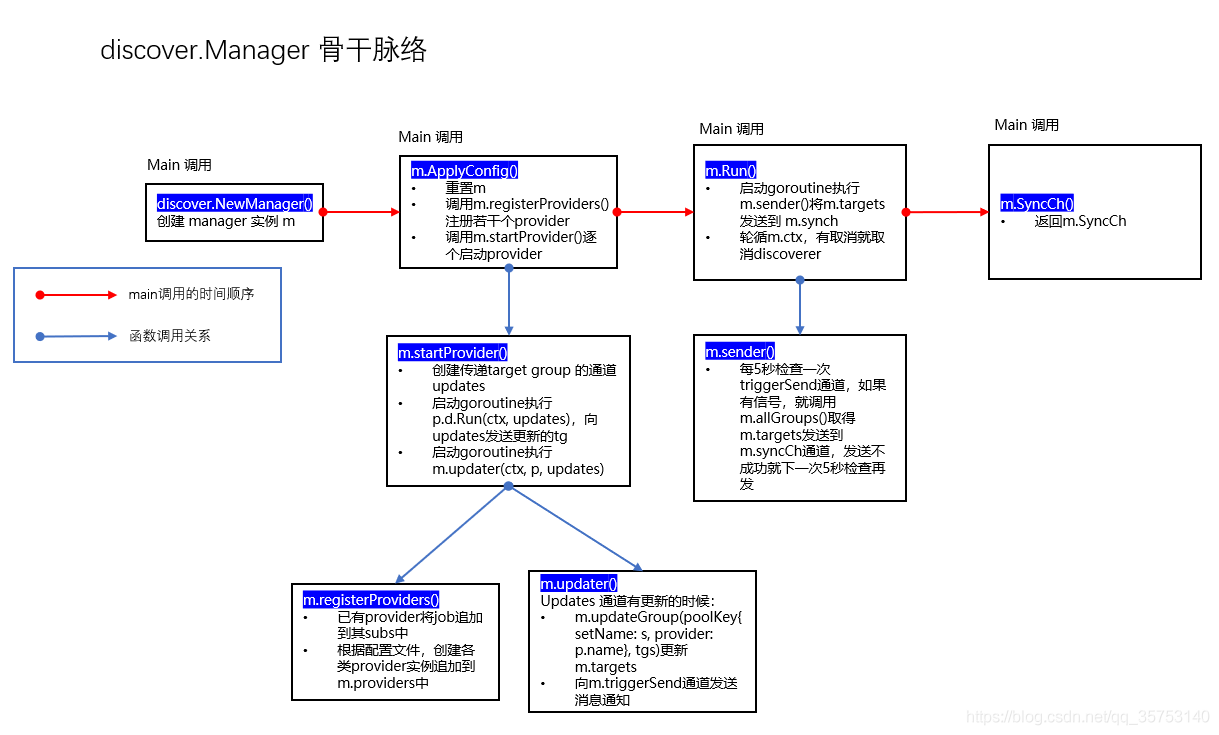
-
The main program calls the newmanager () instance
-
The main program calls m.ApplyConfig() to configure and start the Manager instance according to the configuration file. The Manager instance includes a group of providers that hold specific discoverers. The Discoverer periodically refreshes the target group when running, sends it to the Manager through the channel, saves it in m.targets, and sends a notification signal to the m.triggerSend channel
-
m.Run() checks whether there is an update signal according to the time interval set by m.updatert, and if so, sends the targets in its targets field to its m.syncCh channel
-
The main program calls the m.SyncCh() method to get the channel and get the target from it
reference resources:
https://blog.csdn.net/dengxiafubi/article/details/102741656?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162311811516780265424839%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=162311811516780265424839&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_v2~rank_v29-5-102741656.pc_v2_rank_blog_default&utm_term=Prometheus%E6%BA%90%E7%A0%81%E7%B3%BB%E5%88%97&spm=1018.2226.3001.4450
https://blog.csdn.net/qq_35753140/article/details/112999768?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162304613116780269873364%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=162304613116780269873364&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_v2~rank_v29-4-112999768.pc_v2_rank_blog_default&utm_term=Prometheus%E6%BA%90%E7%A0%81%E5%AD%A6%E4%B9%A0&spm=1018.2226.3001.4450
https://blog.csdn.net/weixin_42663840/article/details/81450705?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-13.baidujs&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-13.baidujs