Inverted index
Indexes in prometheus tsdb are organized as inverted index es:
Assign 1 id to each series
- Query series with seriesId, which is the forward index. Query time complexity = O(1);
Construct index of label
- If seriesId={2,5,10,29} contains label: app='nginx ';
- Then, for app='nginx", {2,5,10,29} is its inverted index;
For example, for seriesId=5:
// seriesId=5
{
__name__ = "request_total",
pod="nginx-1",
path="/api/v1/status",
status="200",
method="GET"
}Then, for:
- status="200": its inverted index = {1,2,5,...}
- method="GET": its inverted index = {2,3,4,5,6,9,...}
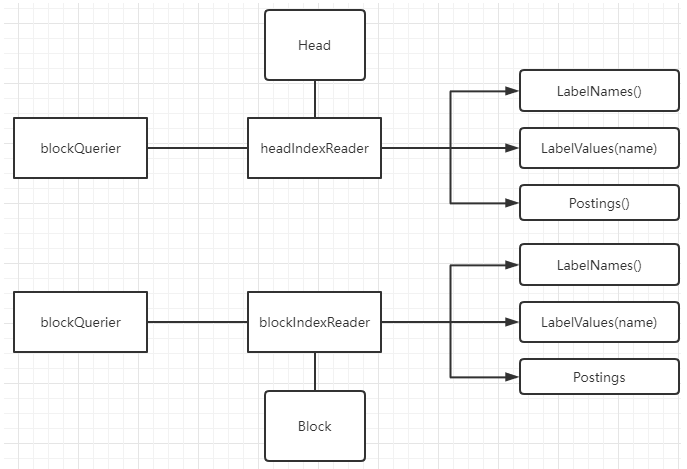
Overall source code framework
In memory, use headIndexReader to organize label s in memory block into inverted indexes;
In block, use blockIndexReader to read the index file in the block directory and organize the label s in it into inverted indexes;
headIndexReader and blockIndexReader inherit from indexReader and provide:
- LabelNames(): query all label keys;
- LabelValues(name): query the values corresponding to the label key;
- Postings(): query the [] seriesId corresponding to label key/value;
The blockquery constructs different indexreaders according to different blocks to read the Label index; Blockquery uses Postings() to get [] seriesId, and then uses chunkReader to finally read the timing data (t/v).
Inverted index in memory
Data structure:
// tsdb/index/postings.go
type MemPostings struct {
mtx sync.RWMutex
// label key --> []labelValue
values map[string]stringset // Label names to possible values.
// map[labelName]map[labelValue]postingsList
// labelName --> labelValue --> []posting
m map[string]map[string][]uint64
ordered bool
}
// tsdb/head.go
// Head handles reads and writes of time series data within a time window.
type Head struct {
......
postings *index.MemPostings // Postings lists for terms.
}1 - insertion of memory inverted index
The entry is to insert timing data:
- If lset is already in the series, it returns directly;
Otherwise, get a seriesId:
- Insert label key/value into h.values;
- Insert label key/value and seriesId into h.posts (large map);
// tsdb/head.go
func (a *headAppender) Add(lset labels.Labels, t int64, v float64) (uint64, error) {
......
s, created, err := a.head.getOrCreate(lset.Hash(), lset)
......
}
func (h *Head) getOrCreate(hash uint64, lset labels.Labels) (*memSeries, bool, error) {
s := h.series.getByHash(hash, lset)
// Already, go straight back
if s != nil {
return s, false, nil
}
id := atomic.AddUint64(&h.lastSeriesID, 1)
return h.getOrCreateWithID(id, hash, lset)
}Insert into h.values and h.postings:
// tsdb/head.go
func (h *Head) getOrCreateWithID(id, hash uint64, lset labels.Labels) (*memSeries, bool, error) {
s := newMemSeries(lset, id, h.chunkRange, &h.memChunkPool)
......
// Insert label key/value into h.values
for _, l := range lset {
valset, ok := h.values[l.Name]
if !ok {
valset = stringset{}
h.values[l.Name] = valset
}
// Insert key,value
valset.set(l.Value)
......
}
// id=seriesId
// Insert key/value/seriesId into h.postings
h.postings.Add(id, lset)
return s, true, nil
}2 - query of memory inverted index
Mainly in headIndexReader:
- Query all lablenames through LableNames();
- Query the labelValues corresponding to labelName through LabelValues(name);
- Query the [] seriesId corresponding to key and value through postings, and finally use seriesId+chunkReader to query the final timing data (t/v);
Both LableNames() and LabelValues(name) use head values:
// tsdb/head.go
func (h *headIndexReader) LabelNames() ([]string, error) {
labelNames := make([]string, 0, len(h.head.values))
// Read h.head values
for name := range h.head.values {
if name == "" {
continue
}
labelNames = append(labelNames, name)
}
sort.Strings(labelNames)
return labelNames, nil
}// tsdb/head.go
func (h *headIndexReader) LabelValues(name string) ([]string, error) {
sl := make([]string, 0, len(h.head.values[name]))
// Read h.head values
for s := range h.head.values[name] {
sl = append(sl, s)
}
return sl, nil
}Postings() provides the function of querying the [] seriesId corresponding to key/values:
// tsdb/head.go
// Postings returns the postings list iterator for the label pairs.
func (h *headIndexReader) Postings(name string, values ...string) (index.Postings, error) {
res := make([]index.Postings, 0, len(values))
for _, value := range values {
res = append(res, h.head.postings.Get(name, value))
}
return index.Merge(res...), nil
}Inverted index in block
Data structure:
// tsdb/index/index.go
type Reader struct {
......
// labelName--> labelValue + offset
postings map[string][]postingOffset
......
}The inverted index in the block is obtained from the index file in the read disk block.
Query LabelNames():
- The specific reading is performed by the reader Lablenames() implementation;
- blockIndexReader.LabelNames() finally calls reader LabelNames();
// tsdb/index/index.go
// LabelNames returns all the unique label names present in the index.
func (r *Reader) LabelNames() ([]string, error) {
labelNames := make([]string, 0, len(r.postings))
// Read r.postings
for name := range r.postings {
......
labelNames = append(labelNames, name)
}
sort.Strings(labelNames)
return labelNames, nil
}
// tsdb/block.go
func (r blockIndexReader) LabelNames() ([]string, error) {
return r.b.LabelNames()
}Query LabelValues(name):
- The specific reading is performed by the reader Labelvalues read TOC Postingstable implementation;
- blockIndexReader.LabelValues() finally calls reader LabelValues();
// tsdb/index/index.go
// LabelValues returns value tuples that exist for the given label name.
func (r *Reader) LabelValues(name string) ([]string, error) {
......
e, ok := r.postings[name]
values := make([]string, 0, len(e)*symbolFactor)
// Read TOC PostingsTable
d := encoding.NewDecbufAt(r.b, int(r.toc.PostingsTable), nil)
d.Skip(e[0].off)
lastVal := e[len(e)-1].value
for d.Err() == nil {
......
s := yoloString(d.UvarintBytes()) //Label value.
values = append(values, s)
}
return values, nil
}
// tsdb/block.go
func (r blockIndexReader) LabelValues(name string) ([]string, error) {
st, err := r.ir.LabelValues(name)
return st, errors.Wrapf(err, "block: %s", r.b.Meta().ULID)
}Query Postings():
- The specific reading is performed by the reader Postings() read TOC Postingstable implementation;
- blockIndexReader.Postings() finally calls reader Postings();
// tsdb/index/index.go
func (r *Reader) Postings(name string, values ...string) (Postings, error) {
.....
e, ok := r.postings[name]
res := make([]Postings, 0, len(values))
for valueIndex < len(values) && values[valueIndex] < e[0].value {
// Discard values before the start.
valueIndex++
}
for valueIndex < len(values) {
value := values[valueIndex]
i := sort.Search(len(e), func(i int) bool { return e[i].value >= value })
d := encoding.NewDecbufAt(r.b, int(r.toc.PostingsTable), nil)
d.Skip(e[i].off)
for d.Err() == nil {
......
d2 := encoding.NewDecbufAt(r.b, int(postingsOff), castagnoliTable)
_, p, err := r.dec.Postings(d2.Get())
res = append(res, p)
}
}
return Merge(res...), nil
}
// tsdb/block.go
func (r blockIndexReader) Postings(name string, values ...string) (index.Postings, error) {
p, err := r.ir.Postings(name, values...)
if err != nil {
return p, errors.Wrapf(err, "block: %s", r.b.Meta().ULID)
}
return p, nil
}Postings() is used when querying
The query process of memory and block using Postings() is similar, except that different indexreaders are used.
1) Query entry: load memory block and disk block to construct blockquery
// tsdb/db.go
func (db *DB) Querier(_ context.Context, mint, maxt int64) (storage.Querier, error) {
var blocks []BlockReader
// Disk block
for _, b := range db.blocks {
if b.OverlapsClosedInterval(mint, maxt) {
blocks = append(blocks, b)
blockMetas = append(blockMetas, b.Meta())
}
}
// Memory block
if maxt >= db.head.MinTime() {
blocks = append(blocks, &RangeHead{
head: db.head,
mint: mint,
maxt: maxt,
})
}
blockQueriers := make([]storage.Querier, 0, len(blocks))
for _, b := range blocks {
q, err := NewBlockQuerier(b, mint, maxt)
if err == nil {
blockQueriers = append(blockQueriers, q)
continue
}
}
return &querier{
blocks: blockQueriers,
}, nil
}It can be seen that:
- For memory block, use RangeHead structure;
- For disk block, use block structure;
2) Construct blockquery
// tsdb/querier.go
// NewBlockQuerier returns a querier against the reader.
func NewBlockQuerier(b BlockReader, mint, maxt int64) (storage.Querier, error) {
// Construct headIndexReader
indexr, err := b.Index()
if err != nil {
return nil, errors.Wrapf(err, "open index reader")
}
chunkr, err := b.Chunks()
.....
return &blockQuerier{
mint: mint,
maxt: maxt,
index: indexr,
chunks: chunkr,
tombstones: tombsr,
}, nil
}Of the above codes, the most important ones are:
// Different indexreaders are constructed according to different block s indexr, err := b.Index()
For memory block(RangeHead): the final construction is headIndexReader
// tsdb/head.go
func (h *RangeHead) Index() (IndexReader, error) {
return h.head.indexRange(h.mint, h.maxt), nil
}
func (h *Head) indexRange(mint, maxt int64) *headIndexReader {
if hmin := h.MinTime(); hmin > mint {
mint = hmin
}
return &headIndexReader{head: h, mint: mint, maxt: maxt}
}For disk block(Block): the final construction is blockIndexReader
// tsdb/block.go
// Index returns a new IndexReader against the block data.
func (pb *Block) Index() (IndexReader, error) {
if err := pb.startRead(); err != nil {
return nil, err
}
return blockIndexReader{ir: pb.indexr, b: pb}, nil
}3) BlockQuerier uses indexReader to query postings information
Query serieset
func (q *blockQuerier) Select(sortSeries bool, hints *storage.SelectHints, ms ...*labels.Matcher) storage.SeriesSet {
......
if sortSeries {
base, err = LookupChunkSeriesSorted(q.index, q.tombstones, ms...)
} else {
base, err = LookupChunkSeries(q.index, q.tombstones, ms...)
}
......
}
func lookupChunkSeries(sorted bool, ir IndexReader, tr tombstones.Reader, ms ...*labels.Matcher) (storage.DeprecatedChunkSeriesSet, error) {
......
// Indexreader. Will eventually be called Postings()
p, err := PostingsForMatchers(ir, ms...)
......
}PostingsForMatchers will eventually call indexreader Postings().